Как обойти антиплагиат: способы обмана и его выявления

Сегодня пройти проверку на плагиат в ВКР, курсовых и иных студенческих или научных работах становится все сложнее и сложнее. Происходит это потому, что системы выявления заимствований постоянно совершенствуются, а их алгоритмы все более усложняются. В ответ на это появляются и различные способы обхода «антиплагиата». Однако подобный обман сейчас достаточно легко выявляется и может привести к некоторым весьма неприятным последствиям.
Чем грозит обход систем антиплагиата?
Самое безобидное из последствий такого обхода – вам вернут курсовую или диплом на доработку и уже в следующий раз будут относиться к вам предвзято. В худшем случае обман грозит отчислением из состава студентов, так как согласно ст. 43 Федерального закона от 29.12.2012 №273-ФЗ «Об образовании в Российской Федерации» недобросовестное освоение студентом образовательной программы может повлечь за собой отчисление. Попытка же нелегального обхода системы выявления плагиата формально как раз и является таким вот недобросовестным освоением учебного материала.
Кроме того, в отдельных высших или средних профессиональных учебных заведениях попытка обмануть антиплагиат прямо прописана в локальных нормативных актах конкретного учебного заведения (например, в уставе) как основание для отчисления. Студенты и даже преподаватели могут этого и не знать, но где гарантия, что данную норму не применят как раз в вашем случае? Ведь все мы люди, все по-разному реагируем, и если большинство преподавателей философски и даже по-доброму относятся к неуклюжим попыткам нерадивых студентов получить оценку за курсовую или ВКР «на халяву», то кто-то может посчитать это и личным оскорблением и вот тогда уже защитить работу будет очень и очень не просто.
Поэтому мы настоятельно не рекомендуем прибегать к различным способам нелегального обхода антиплагиата, тем более, что выявить его сегодня не так уж и сложно даже с помощью простого визуального анализа текста.
Основные способы обойти антиплагиат
Перефразирование при помощи программ-синонимайзеров и онлайн-переводчиков
На сегодняшний день создано довольно много программ-синонимайзеров и соответствующих онлайн-сервисов (raskruty.ru/tools/synonymizer, online-sinonim.ru, progaonline.com/synonymizer, sinoni.men, synonymizer.ru, textorobot.ru, usyn.ru/online.php и целый ряд других), которые автоматически производят замену слов синонимами.
Как и в случае с сервисами проверки на плагиат, бесплатно и без регистрации можно обработать только небольшой фрагмент текста, от нескольких сотен до нескольких тысяч знаков. Регистрация позволяет в несколько раз увеличить этот лимит, а за относительно небольшую плату сервисом разрешается пользоваться практически без ограничений. То же самое касается и программ-синонимайзеров, которые можно скачать и установить себе на компьютер: за бесплатные и свободно распространяемые по Интернету приложения разработчики вообще не несут никакой ответственности, что и сказывается на их функциональности и даже в некоторых случаях – на безопасности вашего компьютера или смартфона.
Но главное здесь то, что даже платные онлайн-сервисы и программы, имеющие в своем распоряжении базы из десятков толковых или орфографических словарей, не говоря уже про их неполноценные аналоги, очень часто после обработки выдают просто бессмысленный текст, особенно если он изобилует специальными терминами. Иногда проще и быстрее написать текст «с нуля» самому, чем откорректировать получившийся. Если же отдать научному руководителю курсовую, диплом или магистерскую после обработки синонимайзером, но без последующего редактирования вручную, то подавляющее большинство из них даже не станут проверять ее на плагиат и вернут вам переделывать, прочтя лишь первые пару абзацев. И это, как мы уже говорили выше, в лучшем случае.
Еще хуже получается результат, если использовать онлайн-переводчики в обе стороны (с русского на другой язык, а затем обратно на русский). Да, переводчиками сегодня можно пользоваться бесплатно и без ограничений, как онлайн, так и с установкой себе на компьютер или смартфон, и современные алгоритмы перевода весьма неплохи, но все же после двойного перевода текст получается, как правило, совсем уж нелепый. То есть рассмотренный способ обмана будет выявлен сразу даже при беглом прочтении работы и для этого не требуется никаких технических средств или программ.
Замена букв
Первые системы выявления заимствований можно было легко обмануть, заменяя буквы русского алфавита на одинаковые по написанию с латинскими (например, «о» или «с»). Довольно быстро этот недостаток разработчиками был устранен. Теперь осталась лишь возможность подставлять вместо русских букв греческие, опять же идентичные по написанию (скажем, русскую «о» менять на греческую «омикрон», которая выглядит точно так же), да и то не во всех сервисах. Например, система TEXT.RU прекрасно распознает подобный обман.
Да, отдельные программы поиска плагиата (например, antiplagiat.ru) обмануть таким способом пока еще можно, но если подобный текст будут читать не в распечатанном виде, а в программе MS Word, то слова с замененными буквами он будет подчеркивать красным, и то же самое происходит при замене русских букв на латинские. Иногда (в зависимости от версии Word и настроек) красным подчеркиваются замененные буквы прямо внутри слов. Естественно, если таких подчеркиваний будет много, то сразу станет понятно, что делали с этим текстом.
Использование скрытых символов и текста
Самый простой вариант здесь и он же самый ненадежный – скопировать в файл много текста белого цвета, набранного мелким шрифтом. Чуть посложнее – спрятать такой текст в графические объекты, которые тоже сделать невидимыми. Размещают это все обычно на страницах, где есть пустые места и мало текста, в конце глав и разделов, в приложениях и т.п. Но подобное может обмануть лишь неопытного пользователя, а таких среди современных преподавателей ВУЗов уже почти не осталось. Причем способов раскрыть данный вид обмана великое множество, необязательно для этого даже пользоваться антиплагиатом. Вот некоторые из них:
- Если проверка осуществляется через antiplagiat.ru, то система с большой вероятностью отметит подобные работы как подозрительные. Сколько-нибудь опытного проверяющего это сразу заставит изучить весь текст более внимательно на предмет наличия в нем посторонних символов или программного кода. А некоторые преподаватели, увидев подобное, просто без лишних разговоров возвращают работу.
- В полном отчете большинства систем обнаружения плагиата все до одного посторонние символы и, тем более, фрагменты текста будут видны. Опытный преподаватель даже при беглом просмотре отчета это заметит. Кроме того, наличие больших фрагментов скрытого текста делает аномально большим объем отчета.
- Также на присутствие скрытого текста указывает неоправданно большой объем файла или слишком большое количество символов, которое всегда можно посмотреть в Word в разделе «Статистика».
- Можно также при проверке работы на компьютере выделить весь текст и поменять цвет шрифта на автоматический черный, а вдобавок сделать его размеры и интервалы стандартными. В этом случае станут видимыми все посторонние символы, содержащиеся в основной части документа. Если же просматривать работу с выделенным текстом, то будут заметны и графические объекты.
- Если скопировать текст в обычный файл с расширением .txt, созданный, например, в «Блокноте», то при вставке в него становятся видимыми все скрытые символы (при наличии таковых).
- Небольшой фрагмент текста можно скопировать и вставить даже в строку поиска браузера и там тоже будут видны скрытые символы.
- Отдельные преподаватели, если они более продвинутые пользователи ПК (а таких сейчас немало), могут легко обнаружить скрытый текст и при помощи просмотра XML-кода проверяемого документа.
Кодирование текста
Это способ предполагает повышение уникальности текста при помощи программного кода или макросов.
Макрос – это программа, которая встраивается в файл MS Word для выполнения последовательности команд. Проще говоря, макрос может заставить «поверить» систему «антиплагиат», что оригинальность текста существенно выше, чем это есть на самом деле, причем внешне текст остается прежним и выглядит как обычно.
Сразу отметим, что для использования кодировки текста и достижения корректного результата с его помощью нужно обладать несколько более серьезными навыками работы с компьютером, нежели имеются у среднестатистического пользователя. Если у вас этих навыков нет, то придется потратить время на их освоение, которого и так обычно не хватает при подготовке курсовой и, тем более, ВКР.
Естественно, в Интернете сейчас масса предложений услуг такого рода (наподобие «Антиплагиат-Киллер» и прочих), и они не особо дорогие. На специализированных сайтах порядок цен составляет в среднем 10-15 руб. за страницу текста, а готовые макросы продают за 300-500 руб. и выше. Есть и бесплатные варианты, но, как правило, с небольшим лимитом по объему текста, если эта услуга онлайн, а готовые макросы могут не работать и/или содержать вирусы.
Но не стоят на месте и способы обнаружения программного кода и макросов. Вот некоторые из них:
- Если код старый, а проверка осуществляется через сайт antiplagiat.ru, то система отмечает содержащие его работы как подозрительные, а в полном отчете показывает символы кода, которые были использованы при его написании. Если система и ошибается, то скорее не в пользу студента. Иначе говоря, «видит» попытки обойти ее даже там, где этого и нет. Например, может отреагировать на графические объекты или формулы, созданные во внешних приложениях с функцией обновления связей при открытии.
- Как и в случае со скрытыми символами, увидеть код можно при помощи изменения параметров текста (цвета и размера шрифта, интервалов и т.д.), посредством его вставки в txt-файл или поисковую строку.
- Специализированное программное обеспечение. Например, LibreOfficeWriter и ему подобные. Это – приложения для работы с текстовыми файлами, в том числе с расширениями .doc и .docx, но минуя программы MS Office. Они основаны на несколько ином формате и имеют открытый код, поэтому сразу «видят», любые вставки, скрытые при просмотре в Word, в том числе программные коды.
Как видно, при всем многообразии способов обмануть системы обнаружения заимствований, их использование, как правило, чревато потерей времени и денег, но отнюдь не гарантирует положительный результат. Более того, последствия могут быть весьма плачевными, вплоть до отчисления из учебного заведения, хотя такое и бывает крайне редко. Поэтому все же самый лучший вариант – потратить собственные время и силы на подготовку своей работы, а при нехватке того и другого, обратиться за помощью к опытным специалистам – в Центр помощи студентам «Академик».
Подпишитесь на нас в ВК.
Публикуем полезные лайфхаки для учёбы
Как изменить код текста, чтобы обойти Антиплагиат

Студенты очень страдают при разработке научных работ, ведь им зачастую необходимо изменить код текста, чтобы обойти антиплагиат. Сделать это бывает намного сложнее, чем может показаться с первого взгляда. Но если подойти к этому процессу с умом и не давать панике охватить вас, то вы увидите, что все проще, чем могло показаться.
Очень часто этот нехитрый прием помогает повысить процент уникальности текста. Справиться с задачей под силу даже гуманитариям, не имеющим глубоких знаний в компьютерных технологиях. Здесь главное – четко следовать всплывающим подсказкам и придерживаться последовательности при выполнении команд. В случае неудачи всегда можно вернуться к первоначальной точке. Итак, разберемся, как же изменять код текста.
Меняем код в ворде
Задать текстовому документу можно не только определенный формат, но и кодировку. Для этого вам необходимо проделать следующее:
- Выбираем необходимый файл
- Нажимаем команду «Сохранить как»
- Указываем место сохранения
- Устанавливаем необходимую кодировку
- Обязательно меняем имя нового файла, чтобы сохранить оба варианта текста
Как правило, сохраняем документы в форматах docx или docx. Затем проверяем на плагиат оба варианта.
В ворде 10 смена кодировки немного отличается. Поэтому проще всего преобразовывать текст в третьем или седьмом ворде. Для этого исходный документ сохраните первоначально в этих версиях, а затем уже смените кодировку.
Меняем кодировку в блокноте
Иногда обойти антиплагиат удается с помощью переноса текста из ворда в блокнот, а затем возвращение его обратно. Для этого выполняем такие действия:
- В блокнот вставляем нужный текст
- Выбираем команду «сохранить как»
- Указываем имя файла и тип
- Выбираем необходимую кодировку
- Сохраняем
- Сохраненный файл переносим в ворд
Работаем с изображением
- Если вы попытаетесь открыть изображение в ворд, на страничке появятся непонятные символы.
- Чтобы получить читаемый документ делаем так:
- Открываем документ
- Выбираем параметры с помощью вкладки «файл»
- В строке «дополнительно» находим раздел «Общие»
- Подтверждаем преобразование файла
- Выбираем команду «Кодированный текст»
- Выбираем нужную кодировку и подтверждаем действие
Иногда при смене кодировки можно поменять шрифт, что тоже положительно скажется на качестве кодированного текста.
Заключение
Для чего же нужна смена кодировки? Текстовые процессоры в ПК автоматически выбирают кодировку, при которой документы отображаются наиболее корректно. Но ведь перед нами стоит задаче не просто удобного распознавания текста, а обход системы антиплагиат. Поэтому нам необходимо заставить эту коварную компьютерную программу отойти от привычных шаблонов и принять нашу работу за уникальную.
Алгоритм каждой версии антиплагиата работает по-своему. Но принцип, в общем-то, у всех одинаковый. Любой незнакомый программе документ она не сможет распознать, а, значит, пропустит без проверки.
Ваша главная задача при смене кодировки – сохранять все документы, присваивая им новые имена. В противном случае ранние версии текста будут утеряны. Как вы сами смогли убедиться, изменить код текста, чтобы обойти антиплагиат не так уж и сложно.
В этом процессе главное не торопиться и следовать согласно инструкции.
Скрытые символы в ворд
Чем дольше используется проверка оригинальности, тем больше появляется методов обхода антиплагиата. На что только не идут студенты — и меняют кодировки, и добавляют нечитаемые фрагменты текста, чтобы программа не распознала копирование материала. Некоторые даже добавляют белым шрифтом фрагменты, никак не относящиеся к теме. Сегодня мы хотим рассказать о скрытых символах в антиплагиате — как их можно использовать и чем они опасны.
Какие есть варианты использования скрытых символов?
Выделяют несколько основных видов применения скрытых символов в ворде для обхода антиплагиата :
1. Добавление белого текста в надпись. Отличительной особенность надписи является то, что ее не видно при выделении текста, но она копируется в проверку. Как результат — повышается оригинальность за счет фрагмента, который не видно визуально. Увидеть такие скрытые символы в ворде не получится без использования поиска по тексту, а антиплагиат их распознает. То есть, если не знать, что именно искать и где, то можно и не найти эту надпись.
2. Добавление невидимых символов в ворде , которые видит антиплагиат . Для этого могут использоваться знаки чужих алфавитов, которые в действующих кодировках текстового редактора не распознаются. Их видно как небольшие пробелы, которые меньше обычных. Такими знаками можно делить слова на части или вписывать между ними. При изменении цвета текста они остаются незамеченными, но все равно видно, что некоторые интервалы выглядят не так. Не подойдет в том случае, если текст будут вычитывать.
3. Использование еврейской точки. Это символ из иврита, который ставится над словами. Если такие точки расставить по тексту, изменив их цвет и размер, то антиплагиат увидит эти невидимые символы , а проверяющий — нет.
4. Греческий алфавит. Система проверки оригинальности научилась определять латинские буквы. Но греческие она пока не распознает. Поэтому некоторые студент заменяют часть букв в тексте на греческие, чтобы получить нужные показатели оригинальности. Такая замена символов в антиплагиате еще не значит , что работа будет оригинальной — алгоритмы постоянно дорабатываются и улучшаются.
Чем опасно применение скрытых символов
Антиплагиат может легко найти скрытые символы в ворде . И если их будет много, система просто поставит отметку “ Подозрительный документ ”. Такой документ не будет зачтен в качестве реферата, диплома или ВКР.
Убрать невидимые символы в ворде Антиплагиат не сможет. Если всё-таки придется чистить текст от таких ошибок, то надо будет либо прописывать замену символов, либо отображать их через поиск и потом удалять. Это в любом случае потребует времени.
С добавлением текста в надпись еще проще. Если руководитель откроет текст, он обнаружит большой фрагмент документа, который можно будет найти через поиск. Антиплагиат поможет ему увидеть скрытые символы в ворде и удалить их. Результат — работу придется переписывать, отношение преподавателя испортится.
Можно ли обойти антиплагиат без скрытых символов
Чтобы пройти проверку на оригинальность без использования таких методов, используйте Антиплагиат Экспресс. Он работает с документом на уровне кода и меняет его таким образом, чтобы текст оставался читаемым, но давал нужные показатели уникальности. Заказать повышение оригинальности очень просто — достаточно загрузить текст в личном кабинете и через несколько минут получить готовый к сдаче документ.
Если у вас имеются какие-то вопросы — позвоните нам, у нас круглосуточная поддержка клиентов!
8-800-550-55-87 звонок бесплатный
Загрузить работу
Сегодня 26 студентов повысили уникальность своих работ. А всего — 536520 студентов
Как очистить текст от любых способов обхода антиплагиата
Способов обойти проверку на уникальность текста, «обойти антиплагиат» — достаточно много. В сети хватает как описаний методологии, так и сайтов, которые предлагают такую обработку текста как услугу.
В этой области постоянно появляется что-то новое, так как системы проверки со временем худо-бедно учатся распознавать тот или иной способ. По моим ощущениям те, кто придумывает новые ухищрения — идут на пару шагов впереди, поэтому ситуация всегда немного не в пользу тех, кто проверят…
Однажды, размышляя об этом, я уподобился Архимеду, запрыгав вокруг компьютера восклицая «Эврика!». Я не знаю, первый я догадался до этого или нет, но способ очистить текст от приемов обхода, причем от любых, даже тех, которые еще не придуманы — оказался, как и все идеальное, простым до предела.
Изложу ход своих мыслей.
Все существующие на сегодняшний день способы обойти антиплагиат сводятся к трем направлениям
- «невидимый символ» — внутрь слов или вместо пробелов в текст вставляются специальные символы, которые Word отобразить не может, благодаря чему текст остается понятным для читателя-человека. Системы проверки символ «видят», поэтому не находят в тексте заимствований, ведь с их «точки зрения» — присыпанный такими символами текст совершенно не похож на тот же самый текст, который таких символов не содержит… Подобное описано у меня в статьях про невидимый символ и обход с пробелами.
- «спрятанный текст» — внутрь текстового файла внедряется подчас бессмысленный, но уникальный текст. При этом для читателя-человека он невидим, но при проверке учитывается. Так как объемы внедряемого текста могут быть большими, мы в итоге получаем приемлемую уникальность. Например, если взять 10 000 символов плагиата и запрятать в текстовый файл 40 000 символов уникального текста, получим общую уникальность текста 80%. Подробнее я про это писал в статьях про спрятанный текст и много позже в статье о том, как спрятанный текст найти.
- третье направление самое творческое, текст при этом, как правило, обрабатывается вручную. Это направление подразумевает припрятывание кусков уникального текста в самые различные места в файле, например за рисунки, в автофигуры, которые затем задвигаются за край страницы, или же изменение слов способом, описанным в статье про обход со спрятанными буквами и т. п.
Что общего между всеми тремя направлениями?
А общее — то, что для читателя-человека текст должен остаться неизменным. Однако для машины это должен быть другой текст, за счет тех или иных ухищрений, так или иначе упрятанных от взора читателя-человека.
И что это нам дает?
Все просто, правда? Если мы возьмем обработанный текст, кто-то один его будет диктовать, а другой вновь наберет, мы получим чистый текст не так ли? Именно так, только это слишком сложно.
А что будет, если взять и распечатать текст из файла, в котором использован тот или иной способ обхода? Я много экспериментировал, и пришел к выводу к такому выводу: ничего. То есть, при печати на бумагу выводится только интересующий нас текст, без всяких там «невидимых символов» и «спрятанного текста». Если распечатать текст, а потом распознать его, мы получим чистый текст! Да, это так, но это по-прежнему слишком сложно.
А что будет если текст не печатать, а экспортировать в PDF прямо из Word, или использовать для этого стороннее ПО (PDF Creator или The Bullzip PDF Printer). По идее второе — надежнее, но мои эксперименты показали, что, по крайней мере пока — совершенно все равно как превращать текст в PDF, тенденция сохраняется — то, что было видимым — остается видимым, а то, что было спрятанным — остается спрятанным (за редкими исключениями, об этом в конце). Если взять такой PDF-файл и распознать его какой-либо программой, например ABBY FineReader, то мы получим чистый текст! И да, это уже совсем не сложно.
Почему это работает?
Все способы обхода основаны на том, что видим мы одно, на самом деле в текстовом файле так или иначе спрятано другое. Экспорт в PDF и последующее распознавание позволяет нам, фактически, отделить то, что мы видим от всей остальной «подноготной». Ну а проверив такой текст в той или иной системе проверки мы увидим его истинный результат.
Немного тонкостей
Надо заметить, что описанный способ не дает напрямую ответа на вопрос, который многих интересует — есть ли в проверяемом тексте приемы обхода? Косвенно (но иногда — очень красноречиво) о том, что они были, может свидетельствовать различный показатель уникальности у одного и того же текста до распознавания и после. Однако, если вы видите, что до распознавания и после него процент уникальности остался прежним, это не дает гарантии того, что приемов обхода не было. Возможно, система проверки просто не нашла заимствований, которые на самом деле есть. Это может происходить по разным причинам, начиная с очевидного: текста, откуда было что-то заимствовано попросту нет в открытом доступе и базах систем проверки… И заканчивая такими экзотическими случаями, когда текст — вот он, лежит в сети, находится поисковиками, но почему-то напрочь игнорируется той или иной системой проверки. Такое тоже случается, но это уже тема для отдельной статьи.
Тесты, методика
Проверим, как это работает. Учинить проверку я предлагаю при помощи «Антиплагиата», все-таки его используют чаще всего. На всякий случай уточню — набор действий, которые будут произведены над «подопытными» файлами, не зависит от того, где и как вы их потом собираетесь проверять.
Для опытов я взял три файла с научными статьями, про которые мне точно известно, что в них используются те или иные приемы, повышающие уникальность. Все три файла выбраны из таких, которые «Антиплагиат» не помечает подозрительными.
Дальше все достаточно просто:
- я удаляю из файлов все метаданные — сведения об авторах, аннотацию, ключевые слова, список источников;
- сохраняю файлы в таком виде с названием «Исходный образец — #» используя исходный формат файла (если был DOC — сохраняю как DOC, если был DOCX — сохраняю как DOCX и т. п.);
- сохраняю (экспортирую) все три файла в PDF, используя для этого стандартные возможности MS Word;
- используя ABBY FineReader 12 я распознаю все файлы;
- в полученном после распознавания тексте надо удалить «мягкие переносы», которые очень любит расставлять FineReader — они могут влиять на точность проверки в некоторых программах. Для этого открываем инструмент поиска и замены в Word, устанавливаем курсор в верхнюю строчку, нажимаем в левом нижнем углу окна кнопку «Больше», в открывшейся части, внизу, кнопку «Специальный», выбираем из списка «Мягкий перенос», нижнюю строчку оставляем пустой и нажимаем кнопку «Заменить все» (как показано на рисунке);
- получившиеся файлы я сохраняю в формате DOCX с названием «Очищенный образец — #».
Ну а теперь настало время загрузить получившееся в «Антиплагиат»:
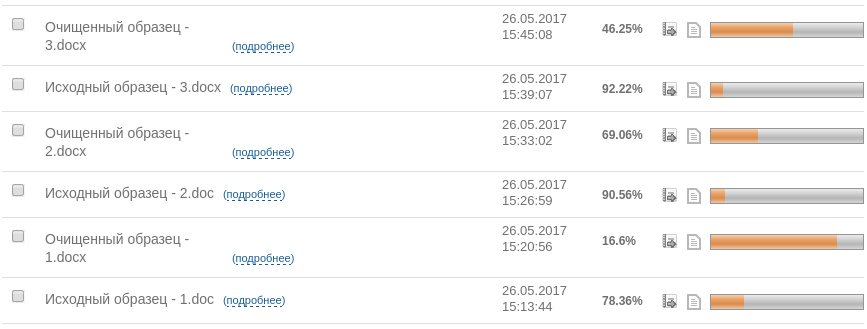
Результат проверки тестовых образцов в системе «Антиплагиат»
Результат, думается, не требует большого количества комментариев. Как видите, после распознавания текст «внезапно» получил совершенно другую оценку.
В завершении хочу добавить, что достаточно давно — около года — экспериментирую с распознаванием и последующей проверкой текстов. Совершенно определенно можно сказать, что «честным» текстам эта процедура никак не вредит, вызывая отклонение от результат исходного образца в 1 — 3%. Так же повторюсь, что совершенно все равно какой способ обхода был использован — распознавание показывает нам истинную оценку текста.
Еще немного тонкостей, или что делать, если текст плохо распознается
Да, контролировать качество распознавания текстов все-таки нужно. Всего два раза, но я сталкивался с тем, что PDF-файлы распознавались с кучей ошибок и как-то странно. Почти уверен, что это связано с приемами, влияющими на уникальность. Посудите сами — если вы делаете приличный размер шрифта, интервал между буквами, и распознаете текст из PDF, даже не выводя его на печать (то есть с точки зрения FineReader — это практически «идеальный текст»), а он распознается с ошибками… Что еще могло повлиять, особенно учитывая тот факт, что другие тексты распознаются нормально?
Столкнувшись с проблемой впервые я достаточно долго с ней провозился, пока не пришла идея конвертировать текст еще раз — из PDF в многостраничный TIFF, то есть, фактически, в изображение — связи с исходным текстом и таящихся в нем уловках не останется никакой.
Я использовал Ghostscript:
ghostscript -o file.tiff -sDEVICE=tiffgray -r720x720 -g6120x7920 -sCompression=lzw file.pdf
Можно использовать какой-либо еще конвертер, главное, чтобы он позволял вставить значение DPI. С ним можно экспериментировать, оно должно быть достаточно большим — по моим ощущениям 500 — 700. Вариант, который показался мне оптимальным для Ghostscript уже заложен в строке выше.
После этих манипуляций все распознавалось «на ура». Многостраничный TIFF можно сразу «скармливать» FineReader’у, он с ними отлично умеет работать.
Вместо заключения
Фокус с распознаванием текста добавляет уверенности в результате проверки, если есть сомнения в том, что автор «не чист на руку». За этот и прошлый год мне пришло достаточно большое количество писем с просьбой оценить тот или иной текст и попытаться найти в нем «что-нибудь этакое». Как я уже писал выше — распознавание позволяет получить «чистую» оценку на текущий момент, но не дает однозначного ответа на вопрос — были ли в тексте какие-либо приемы, повышающие уникальность?
С одной стороны это кажется достаточным — мы знаем истинную оценку текста, не все ли равно, было там что-то или нет? С другой — не так уж и редко встречаются тексты, в которых с одной стороны есть приемы, а с другой стороны — даже после чистки они выдают приличный результат.
Зачем авторы их «обрабатывали»? Ну будущее? На всякий случай? Или, может быть, когда они проверяли — что-то находилось? Варианты есть разные. Чем больше я занимаюсь проверкой текстов, тем больше убеждаюсь, что результат проверки текста на уникальность в «Антиплагиате» или любой другой системе — понятие достаточно эфемерное и не гарантирующее ровным счетом ничего, однако об этом я порассуждаю в следующий раз.