Обрезка и удаление символов из строк в .NET
Если вы анализируете предложение на отдельные слова, вы можете получить слова с пустыми пробелами (также называемыми пробелами) на обоих концах слова. В этом случае можно использовать один из методов обрезки в System.String классе , чтобы удалить любое количество пробелов или других символов из указанной позиции в строке. В следующей таблице описаны доступные методы обрезки.
| Имя метода | Использовать |
|---|---|
| String.Trim | Удаление пробелов или знаков, указанных в массиве знаков, из начала и конца строки. |
| String.TrimEnd | Удаление символов, указанных в массиве символов, в конце строки. |
| String.TrimStart | Удаление символов, указанных в массиве символов, в начале строки. |
| String.Remove | Удаление указанного количества символов в указанной позиции индекса в строке. |
Trim
Вы можете легко удалить пробелы с обоих концов строки с помощью String.Trim метода , как показано в следующем примере:
String^ MyString = " Big "; Console::WriteLine("HelloWorld!", MyString); String^ TrimString = MyString->Trim(); Console::WriteLine("HelloWorld!", TrimString); // The example displays the following output: // Hello Big World! // HelloBigWorld! string MyString = " Big "; Console.WriteLine("HelloWorld!", MyString); string TrimString = MyString.Trim(); Console.WriteLine("HelloWorld!", TrimString); // The example displays the following output: // Hello Big World! // HelloBigWorld! Dim MyString As String = " Big " Console.WriteLine("HelloWorld!", MyString) Dim TrimString As String = MyString.Trim() Console.WriteLine("HelloWorld!", TrimString) ' The example displays the following output: ' Hello Big World! ' HelloBigWorld! Кроме того, можно удалить символы, указанные в массиве знаков, из начала и конца строки. В следующем примере удаляются пробелы, точки и звездочки:
using System; public class Example < public static void Main() < String header = "* A Short String. *"; Console.WriteLine(header); Console.WriteLine(header.Trim( new Char[] < ' ', '*', '.' >)); > > // The example displays the following output: // * A Short String. * // A Short String Module Example Public Sub Main() Dim header As String = "* A Short String. *" Console.WriteLine(header) Console.WriteLine(header.Trim()) End Sub End Module ' The example displays the following output: ' * A Short String. * ' A Short String TrimEnd
Метод String.TrimEnd удаляет символы из конца строки, создавая новый строковый объект. Для указания символов, которые следует удалять, в этот метод передается массив символов. Порядок элементов в массиве символов не влияет на операцию обрезки. В случае обнаружения символа, который отсутствует в массиве, операция останавливается.
В следующем примере удаляются последние буквы строки с помощью TrimEnd метода . В этом примере положение символа ‘r’ и символа ‘W’ повернуты обратно, чтобы проиллюстрировать, что порядок символов в массиве не имеет значения. Обратите внимание, что этот код удаляет последнее слово MyString и часть первого.
String^ MyString = "Hello World!"; array^ MyChar = ; String^ NewString = MyString->TrimEnd(MyChar); Console::WriteLine(NewString); string MyString = "Hello World!"; char[] MyChar = ; string NewString = MyString.TrimEnd(MyChar); Console.WriteLine(NewString); Dim MyString As String = "Hello World!" Dim MyChar() As Char = Dim NewString As String = MyString.TrimEnd(MyChar) Console.WriteLine(NewString) Этот код выводит на консоль значение He .
В следующем примере удаляется последнее слово строки с помощью TrimEnd метода . В этом коде запятая следует за словом Hello . Так как запятая не указана в массиве символов для обрезки, обрезка заканчивается запятой.
String^ MyString = "Hello, World!"; array^ MyChar = ; String^ NewString = MyString->TrimEnd(MyChar); Console::WriteLine(NewString); string MyString = "Hello, World!"; char[] MyChar = ; string NewString = MyString.TrimEnd(MyChar); Console.WriteLine(NewString); Dim MyString As String = "Hello, World!" Dim MyChar() As Char = Dim NewString As String = MyString.TrimEnd(MyChar) Console.WriteLine(NewString) Этот код выводит на консоль значение Hello, .
TrimStart
Метод String.TrimStart аналогичен методу , String.TrimEnd за исключением того, что он создает новую строку путем удаления символов из начала существующего строкового объекта. Массив символов передается методу TrimStart для указания удаляемых символов. Как и в случае с методом TrimEnd , порядок элементов в массиве символов не влияет на операцию обрезки. В случае обнаружения символа, который отсутствует в массиве, операция останавливается.
В следующем примере удаляется первое слово в строке. В этом примере положение символа ‘l’ и символа ‘H’ повернуты обратно, чтобы проиллюстрировать, что порядок символов в массиве не имеет значения.
String^ MyString = "Hello World!"; array^ MyChar = ; String^ NewString = MyString->TrimStart(MyChar); Console::WriteLine(NewString); string MyString = "Hello World!"; char[] MyChar = ; string NewString = MyString.TrimStart(MyChar); Console.WriteLine(NewString); Dim MyString As String = "Hello World!" Dim MyChar() As Char = Dim NewString As String = MyString.TrimStart(MyChar) Console.WriteLine(NewString) Этот код выводит на консоль значение World! .
Удалить
Метод String.Remove удаляет указанное количество знаков, начиная с указанного места в существующей строке. Этот метод подразумевает, что отсчет индекса начинается с нуля.
В следующем примере удаляется 10 символов из строки, начинающейся с пятой позиции отсчитываемого от нуля индекса строки.
String^ MyString = "Hello Beautiful World!"; Console::WriteLine(MyString->Remove(5,10)); // The example displays the following output: // Hello World! string MyString = "Hello Beautiful World!"; Console.WriteLine(MyString.Remove(5,10)); // The example displays the following output: // Hello World! Dim MyString As String = "Hello Beautiful World!" Console.WriteLine(MyString.Remove(5, 10)) ' The example displays the following output: ' Hello World! Замените
Чтобы удалить из строки указанный символ или подстроку, можно вызвать метод String.Replace(String, String) и указать пустую строку (String.Empty) в качестве замены. В следующем примере удаляются все запятые из строки:
using System; public class Example < public static void Main() < String phrase = "a cold, dark night"; Console.WriteLine("Before: ", phrase); phrase = phrase.Replace(",", ""); Console.WriteLine("After: ", phrase); > > // The example displays the following output: // Before: a cold, dark night // After: a cold dark night Module Example Public Sub Main() Dim phrase As String = "a cold, dark night" Console.WriteLine("Before: ", phrase) phrase = phrase.Replace(",", "") Console.WriteLine("After: ", phrase) End Sub End Module ' The example displays the following output: ' Before: a cold, dark night ' After: a cold dark night См. также
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.
Как удалить все буквы и в тексте укажите оптимальный вариант
Конкатенация строк или объединение может производиться как с помощью операции + , так и с помощью метода Concat :
string s1 = "hello"; string s2 = "world"; string s3 = s1 + " " + s2; // результат: строка "hello world" string s4 = string.Concat(s3, ". "); // результат: строка "hello world. " Console.WriteLine(s4);
Метод Concat является статическим методом класса string, принимающим в качестве параметров две строки. Также имеются другие версии метода, принимающие другое количество параметров.
Для объединения строк также может использоваться метод Join :
string s5 = "apple"; string s6 = "a day"; string s7 = "keeps"; string s8 = "a doctor"; string s9 = "away"; string[] values = new string[] < s5, s6, s7, s8, s9 >; string s10 = string.Join(" ", values); Console.WriteLine(s10); // apple a day keeps a doctor away
Метод Join также является статическим. Использованная выше версия метода получает два параметра: строку-разделитель (в данном случае пробел) и массив строк, которые будут соединяться и разделяться разделителем.
Сравнение строк
Для сравнения строк применяется статический метод Compare :
string s1 = "hello"; string s2 = "world"; int result = string.Compare(s1, s2); if (result <0) < Console.WriteLine("Строка s1 перед строкой s2"); >else if (result > 0) < Console.WriteLine("Строка s1 стоит после строки s2"); >else < Console.WriteLine("Строки s1 и s2 идентичны"); >// результатом будет "Строка s1 перед строкой s2"
Данная версия метода Compare принимает две строки и возвращает число. Если первая строка по алфавиту стоит выше второй, то возвращается число меньше нуля. В противном случае возвращается число больше нуля. И третий случай — если строки равны, то возвращается число 0.
В данном случае так как символ h по алфавиту стоит выше символа w, то и первая строка будет стоять выше.
Поиск в строке
С помощью метода IndexOf мы можем определить индекс первого вхождения отдельного символа или подстроки в строке:
string s1 = "hello world"; char ch = 'o'; int indexOfChar = s1.IndexOf(ch); // равно 4 Console.WriteLine(indexOfChar); string substring = "wor"; int indexOfSubstring = s1.IndexOf(substring); // равно 6 Console.WriteLine(indexOfSubstring);
Подобным образом действует метод LastIndexOf , только находит индекс последнего вхождения символа или подстроки в строку.
Еще одна группа методов позволяет узнать начинается или заканчивается ли строка на определенную подстроку. Для этого предназначены методы StartsWith и EndsWith . Например, в массиве строк хранится список файлов, и нам надо вывести все файлы с расширением exe:
var files = new string[] < "myapp.exe", "forest.jpg", "main.exe", "book.pdf", "river.png" >; for (int i = 0; i
Разделение строк
С помощью функции Split мы можем разделить строку на массив подстрок. В качестве параметра функция Split принимает массив символов или строк, которые и будут служить разделителями. Например, подсчитаем количество слов в сроке, разделив ее по пробельным символам:
string text = «И поэтому все так произошло»; string[] words = text.Split(new char[] < ' ' >); foreach (string s in words)
Это не лучший способ разделения по пробелам, так как во входной строке у нас могло бы быть несколько подряд идущих пробелов и в итоговый массив также бы попадали пробелы, поэтому лучше использовать другую версию метода:
string[] words = text.Split(new char[] < ' ' >, StringSplitOptions.RemoveEmptyEntries);
Второй параметр StringSplitOptions.RemoveEmptyEntries говорит, что надо удалить все пустые подстроки.
Обрезка строки
Для обрезки начальных или концевых символов используется функция Trim :
string text = " hello world "; text = text.Trim(); // результат "hello world" text = text.Trim(new char[] < 'd', 'h' >); // результат "ello worl"
Функция Trim без параметров обрезает начальные и конечные пробелы и возвращает обрезанную строку. Чтобы явным образом указать, какие начальные и конечные символы следует обрезать, мы можем передать в функцию массив этих символов.
Эта функция имеет частичные аналоги: функция TrimStart обрезает начальные символы, а функция TrimEnd обрезает конечные символы.
Обрезать определенную часть строки позволяет функция Substring :
string text = "Хороший день"; // обрезаем начиная с третьего символа text = text.Substring(2); // результат "роший день" Console.WriteLine(text); // обрезаем сначала до последних двух символов text = text.Substring(0, text.Length - 2); // результат "роший де" Console.WriteLine(text);
Функция Substring также возвращает обрезанную строку. В качестве параметра первая использованная версия применяет индекс, начиная с которого надо обрезать строку. Вторая версия применяет два параметра — индекс начала обрезки и длину вырезаемой части строки.
Вставка
Для вставки одной строки в другую применяется функция Insert :
string text = "Хороший день"; string substring = "замечательный "; text = text.Insert(8, substring); Console.WriteLine(text); // Хороший замечательный день
Первым параметром в функции Insert является индекс, по которому надо вставлять подстроку, а второй параметр — собственно подстрока.
Удаление строк
Удалить часть строки помогает метод Remove :
string text = "Хороший день"; // индекс последнего символа int ind = text.Length - 1; // вырезаем последний символ text = text.Remove(ind); Console.WriteLine(text); // Хороший ден // вырезаем первые два символа text = text.Remove(0, 2); Console.WriteLine(text); // роший ден
Первая версия метода Remove принимает индекс в строке, начиная с которого надо удалить все символы. Вторая версия принимает еще один параметр — сколько символов надо удалить.
Замена
Чтобы заменить один символ или подстроку на другую, применяется метод Replace :
string text = "хороший день"; text = text.Replace("хороший", "плохой"); Console.WriteLine(text); // плохой день text = text.Replace("о", ""); Console.WriteLine(text); // плхй день
Во втором случае применения функции Replace строка из одного символа «о» заменяется на пустую строку, то есть фактически удаляется из текста. Подобным способом легко удалять какой-то определенный текст в строках.
Смена регистра
Для приведения строки к верхнему и нижнему регистру используются соответственно функции ToUpper() и ToLower() :
string hello = "Hello world!"; Console.WriteLine(hello.ToLower()); // hello world! Console.WriteLine(hello.ToUpper()); // HELLO WORLD!
Регулярные выражения для самых маленьких
Меня зовут Виталий Котов и я немного знаю о регулярных выражениях. Под катом я расскажу основы работы с ними. На эту тему написано много теоретических статей. В этой статье я решил сделать упор на количество примеров. Мне кажется, что это лучший способ показать возможности этого инструмента.
Некоторые из них для наглядности будут показаны на примере языков программирования PHP или JavaScript, но в целом они работают независимо от ЯП.
Из названия понятно, что статья ориентирована на самый начальный уровень — тех, кто еще ни разу не использовал регулярные выражения в своих программах или делал это без должного понимания.
В конце статьи я в двух словах расскажу, какие задачи нельзя решить регулярными выражениями и какие инструменты для этого стоит использовать.

Вступление
Регулярные выражения — язык поиска подстроки или подстрок в тексте. Для поиска используется паттерн (шаблон, маска), состоящий из символов и метасимволов (символы, которые обозначают не сами себя, а набор символов).
Это довольно мощный инструмент, который может пригодиться во многих случая — поиск, проверка на корректность строки и т.д. Спектр его возможностей трудно уместить в одну статью.
В PHP работа с регулярными выражениями заключается в наборе функций, из которых я чаще всего использую следующие:
- preg_match (http://php.net/manual/en/function.preg-match.php)
- preg_match_all (http://php.net/manual/en/function.preg-match-all.php)
- preg_replace (http://php.net/manual/en/function.preg-replace.php)
Функции на match возвращают число найденных подстрок или false в случае ошибок. Функция на replace возвращает измененную строку/массив или null в случае ошибки. Результат можно привести к bool (false, если не было найдено значений и true, если было) и использовать вместе с if или assertTrue для обработки результата работы.
В JS чаще всего мне приходится использовать:
- match (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/match)
- test (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/test)
- replace (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/replace)
Пример использования функций
В PHP регулярное выражение — это строка, которая начинается и заканчивается символом-разделителем. Все, что находится между разделителями и есть регулярное выражение.
Часто используемыми разделителями являются косые черты “/”, знаки решетки “#” и тильды “~”. Ниже представлены примеры шаблонов с корректными разделителями:
- /foo bar/
- #^[^0-9]$#
- %[a-zA-Z0-9_-]%
- /http:\/\//
- #http://#
Создать регулярное выражение можно так:
let regexp = new RegExp("шаблон", "флаги"); Или более короткий вариант:
let regexp = /шаблон/; // без флагов let regexp = /шаблон/gmi; // с флагами gmi (изучим их дальше) Пример самого простого регулярного выражения для поиска:
RegExp: /o/ Text: hello world В этом примере мы просто ищем все символы “o”.
В PHP разница между preg_match и preg_match_all в том, что первая функция найдет только первый match и закончит поиск, в то время как вторая функция вернет все вхождения.
Пример кода на PHP:
int(1) // нам вернулось одно вхождение, т.к. после функция заканчивает работу array(1) < [0]=>string(1) "o" // нам вернулось вхождение, аналогичное запросу, так как метасимволов мы пока не использовали > Пробуем то же самое для второй функции:
int(2) array(1) < [0]=>array(2) < [0]=>string(1) "o" [1]=> string(1) "o" > > В последнем случае функция вернула все вхождения, которые есть в нашем тексте.
Тот же пример на JavaScript:
let str = 'Hello world'; let result = str.match(/o/); console.log(result); ["o", index: 4, input: "Hello world"] Модификаторы шаблонов
Для регулярных выражений существует набор модификаторов, которые меняют работу поиска. Они обозначаются одиночной буквой латинского алфавита и ставятся в конце регулярного выражения, после закрывающего “/”.
- i — символы в шаблоне соответствуют символам как верхнего, так и нижнего регистра.
- m — по умолчанию текст обрабатывается, как однострочная символьная строка. Метасимвол начала строки ‘^’ соответствует только началу обрабатываемого текста, в то время как метасимвол конца строки ‘$’ соответствует концу текста. Если этот модификатор используется, метасимволы «начало строки» и «конец строки» также соответствуют позициям перед произвольным символом перевода и строки и, соответственно, после, как и в самом начале, и в самом конце строки.
О том, какие вообще бывают модификаторы, можно почитать тут.
Пример предыдущего регулярного выражения с модификатором на JavaScript:
let str = "hello world \ How is it going?" let result = str.match(/o/g); console.log(result); ["o", "o", "o", "o"] Метасимволы в регулярных выражениях
Примеры по началу будут довольно примитивные, потому что мы знакомимся с самыми основами. Чем больше мы узнаем, тем ближе к реалиям будут примеры.
Чаще всего мы заранее не знаем, какой текст нам придется парсить. Заранее известен только примерный набор правил. Будь то пинкод в смс, email в письме и т.п.
Первый пример, нам надо получить все числа из текста:
Текст: “Привет, твой номер 1528. Запомни его.” Чтобы выбрать любое число, надо собрать все числа, указав “[0123456789]”. Более коротко можно задать вот так: “[0-9]”. Для всех цифр существует метасимвол “\d”. Он работает идентично.
Но если мы укажем регулярное выражение “/\d/”, то нам вернётся только первая цифра. Мы, конечно, можем использовать модификатор “g”, но в таком случае каждая цифра вернется отдельным элементом массива, поскольку будет считаться новым вхождением.
Для того, чтобы вывести подстроку единым вхождением, существуют символы плюс “+” и звездочка “*”. Первый указывает, что нам подойдет подстрока, где есть как минимум один подходящий под набор символ. Второй — что данный набор символов может быть, а может и не быть, и это нормально. Помимо этого мы можем указать точное значение подходящих символов вот так: “”, где N — нужное количество. Или задать “от” и “до”, указав вот так: “”.
Сейчас будет пара примеров, чтобы это уложилось в голове:
Текст: “Я хочу ходить на работу 2 раза в неделю.” Надо получить цифру из тексте. RegExp: “/\d/” Текст: “Ваш пинкод: 24356” или “У вас нет пинкода.” Надо получить пинкод или ничего, если его нет. RegExp: “/\d*/” Текст: “Номер телефона 89091534357” Надо получить первые 11 символов, или FALSE, если их меньше. RegExp: “/\d/” Примерно так же мы работает с буквами, не забывая, что у них бывает регистр. Вот так можно задавать буквы:
- [a-z]
- [a-zA-Z]
- [а-яА-Я]
Текст: “Вот бежит олень” или “Вот ваш индюк” Надо выбрать либо слово “олень”, либо слово “индюк”. RegExp: “/[а-яА-Я]+/” Такое выражение выберет все слова, которые есть в предложении и написаны кириллицей. Нам нужно третье слово.
Помимо букв и цифр у нас могут быть еще важные символы, такие как:
- \s — пробел
- ^ — начало строки
- $ — конец строки
- | — “или”
Текст: “Вот бежит олень” или “Вот бежит индюк” Надо выбрать либо “олень”, либо “индюк”. RegExp: “/[а-яА-Я]+$/” Если мы точно знаем, что искомое слово последнее, мы ставим “$” и результатом работы будет только тот набор символов, после которого идет конец строки.
То же самое с началом строки:
Текст: “Олень вкусный” или “Индюк вкусный” Надо выбрать либо “олень”, либо “индюк”. RegExp: “/^[а-яА-Я]+/” Прежде, чем знакомиться с метасимволами дальше, надо отдельно обсудить символ “^”, потому что он у нас ходит на две работы сразу (это чтобы было интереснее). В некоторых случаях он обозначает начало строки, но в некоторых — отрицание.
Это нужно для тех случаев, когда проще указать символы, которые нас не устраивают, чем те, которые устраивают.
Допустим, мы собрали набор символов, которые нам подходят: “[a-z0-9]” (нас устроит любая маленькая латинская буква или цифра). А теперь предположим, что нас устроит любой символ, кроме этого. Это будет обозначаться вот так: “[^a-z0-9]”.
Текст: “Я люблю кушать суп” Надо выбрать все слова. RegExp: “[^\s]+” Выбираем все “не пробелы”.
Итак, вот список основных метасимволов:
- \d — соответствует любой цифре; эквивалент [0-9]
- \D — соответствует любому не числовому символу; эквивалент [^0-9]
- \s — соответствует любому символу whitespace; эквивалент [ \t\n\r\f\v]
- \S — соответствует любому не-whitespace символу; эквивалент [^ \t\n\r\f\v]
- \w — соответствует любой букве или цифре; эквивалент [a-zA-Z0-9_]
- \W — наоборот; эквивалент [^a-zA-Z0-9_]
- . — (просто точка) любой символ, кроме перевода “каретки”
Операторы [] и ()
По описанному выше можно было догадаться, что [] используется для группировки нескольких символов вместе. Так мы говорим, что нас устроит любой символ из набора.
Текст: “Не могу перевести I dont know, помогите!” Надо получить весь английский текст. RegExp: “/[A-Za-z\s]/” Тут мы собрали в группу (между символами []) все латинские буквы и пробел. При помощи <> указали, что нас интересуют вхождения, где минимум 2 символа, чтобы исключить вхождения из пустых пробелов.
Аналогично мы могли бы получить все русские слова, сделав инверсию: “[^A-Za-z\s]”.
В отличие от [], символы () собирают отмеченные выражения. Их иногда называют “захватом”.
Они нужны для того, чтобы передать выбранный кусок (который, возможно, состоит из нескольких вхождений [] в результат выдачи).
Текст: ‘Email you sent was ololo@example.com Is it correct?’ Нам надо выбрать email. Существует много решений. Пример ниже — это приближенный вариант, который просто покажет возможности регулярных выражений. На самом деле есть RFC, который определяет правильность email. И есть “регулярки” по RFC — вот примеры.
Мы выбираем все, что не пробел (потому что первая часть email может содержать любой набор символов), далее должен идти символ @, далее что угодно, кроме точки и пробела, далее точка, далее любой символ латиницы в нижнем регистре…
- мы выбираем все, что не пробел: “[^\s]+”
- мы выбираем знак @: “@”
- мы выбираем что угодно, кроме точки и пробела: “[^\s\.]+”
- мы выбираем точку: “\.” (обратный слеш нужен для экранирования метасимвола, так как знак точки описывает любой символ — см. выше)
- мы выбираем любой символ латиницы в нижнем регистре: “[a-z]+”
int(1) array(1) < [0]=>array(1) < [0]=>string(13) "ololo@example.com" > > Получилось! Но что, если теперь нам надо по отдельности получить домен и имя по email? И как-то использовать дальше в коде? Вот тут нам поможет “захват”. Мы просто выбираем, что нам нужно, и оборачиваем знаками (), как в примере:
/[^\s]+@[^\s\.]+\.[a-z]+/ /([^\s]+)@([^\s\.]+\.[a-z]+)/ int(1) array(3) < [0]=>array(1) < [0]=>string(13) "ololo@example.com" > [1]=> array(1) < [0]=>string(5) "ololo" > [2]=> array(1) < [0]=>string(7) "example.com" > > В массиве match нулевым элементом всегда идет полное вхождение регулярного выражения. А дальше по очереди идут “захваты”.
В PHP можно именовать “захваты”, используя следующий синтаксис:
/(?[^\s]+)@(?[^\s\.]+\.[a-z]+)/ Тогда массив матча станет ассоциативным:
[^\s]+)@(?[^\s\.]+\.[a-z]+)/’; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match ); int(1) array(5) < [0]=>array(1) < [0]=>string(13) "ololo@example.com" > ["mail"]=> array(1) < [0]=>string(5) "ololo" > ["domain"]=> array(1) < [0]=>string(7) "example.com" > > Это сразу +100 к читаемости и кода, и регулярки.
Примеры из реальной жизни
Парсим письмо в поисках нового пароля:
Есть письмо с HTML-кодом, надо выдернуть из него новый пароль. Текст может быть либо на английском, либо на русском:
Текст: “пароль: f23f43tgt4” или “password: wh4k38f4” RegExp: “(password|пароль):\s([^<]+)<\/b>” Сначала мы говорим, что текст перед паролем может быть двух вариантов, использовав “или”.
Вариантов можно перечислять сколько угодно:
(password|пароль) Далее у нас знак двоеточия и один пробел:
Далее знак тега b:
Мы оборачиваем его в захват, потому что именно он нам и нужен.
Далее мы пишем закрывающий тег b, проэкранировав символ “/”, так как это спецсимвол:
Все довольно просто.
Парсим URL:
В PHP есть клевая функция, которая помогает работать с урлом, разбирая его на составные части:
array(5) < ["scheme"]=>string(5) "https" ["host"]=> string(14) "hello.world.ru" ["path"]=> string(16) "/uri/starts/here" ["query"]=> string(15) "get_params=here" ["fragment"]=> string(6) "anchor" > Давай сделаем то же самое, только регуляркой? 🙂
Любой урл начинается со схемы. Для нас это протокол http/https. Можно было бы сделать логическое “или”:
(http|https) Но можно схитрить и сделать вот так:
http[s]? В данном случае символ “?” означает, что “s” может есть, может нет…
Далее у нас идет “://”, но символ “/” нам придется экранировать (см. выше):
Далее у нас до знака “/” или до конца строки идет домен. Он может состоять из цифр, букв, знака подчеркивания, тире и точки:
Тут мы собрали в единую группу метасимвол “\w”, точку ”\.” и тире ”-”.
Далее идет URI. Тут все просто, мы берем все до вопросительного знака или конца строки:
Теперь знак вопроса, который может быть, а может не быть:
Далее все до конца строки или начала якоря (символ #) — не забываем о том, что этой части тоже может не быть:
Далее может быть #, а может не быть:
Дальше все до конца строки, если есть:
Вся красота в итоге выглядит так (к сожалению, я не придумал, как вставить эту часть так, чтобы Habr не считал часть строки — комментарием):
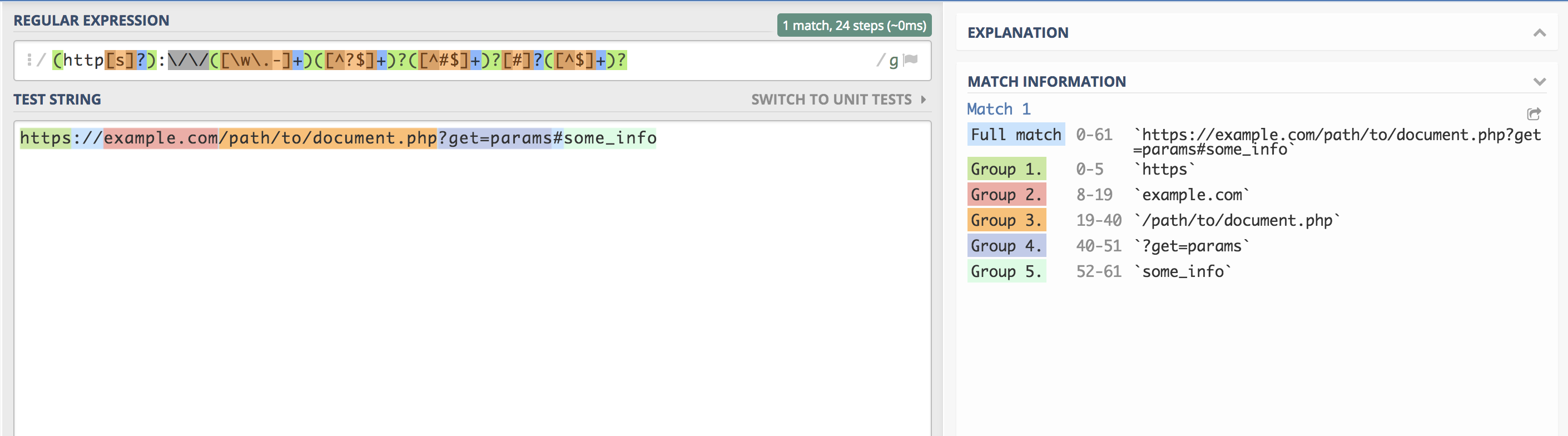
/(?http[s]?):\/\/(?[\w\.-]+)(?[^?$]+)?(?[^#$]+)?[#]?(?[^$]+)?/ Главное не моргать! 🙂
http[s]?):\/\/(?[\w\.-]+)(?[^?$]+)?(?[^#$]+)?[#]?(?[^$]+)?/”; $result = preg_match($regexp, $URL, $match); var_dump( $result, $match ); array(11) < [0]=>string(61) "https://hello.world.ru/uri/starts/here?get_params=here#anchor" ["scheme"]=> string(5) "https" ["domain"]=> string(14) "hello.world.ru" ["URI"]=> string(16) "/uri/starts/here" ["params"]=> string(15) "get_params=here" ["anchor"]=> string(6) "anchor" > Получилось примерно то же самое, только своими руками.
Какие задачи не решаются регулярными выражениями
На первый взгляд кажется, что регулярными выражениями можно описать и распарсить любой текст. Но, к сожалению, это не так.
Регулярные выражении — это подвид формальных языков, который в иерархии Хомского принадлежат 3-ому типу, самому простому. Об этом тут.
При помощи этого языка мы не можем, например, парсить синтаксис языков программирования с вложенной грамматикой. Или HTML код.
Примеры задач:
У нас есть span, внутри которых много других span и мы не знаем сколько. Надо выбрать все, что находится внутри этого span:
ololo1 ololo2 ololo3 ololo4 ololo5 Само собой, если мы парсим HTML, где есть не только этот span. 🙂
Суть в том, что мы не можем начать с какого-то момента “считать” символы span и /span, подразумевая, что открывающих и закрывающих символов должно быть равное количество. И “понять”, что закрывающий символ, для которого ранее не было пары — тот самый закрывающий, который обосабливает блок.
То же самое с кодом и символами <>.
function methodA() < function() > if () < if () > > > В такой структуре мы не сможем при помощи только регулярного выражения отличить закрывающую фигурную скобку внутри кода от той, которая завершает начальную функцию (если код состоит не только из этой функции).
Для решение таких задач используются языки более высокого уровня.
Заключение
Я постарался довольно подробно рассказать об азах мира регулярных выражений. Конечно невозможно в одну статью уместить все. Дальнейшая работа с ними — вопрос опыта и умения гуглить.
Спасибо за внимание.
- Блог компании Badoo
- PHP
- JavaScript
- Программирование
- Регулярные выражения
Создание и форматирование текстовых документов (OpenOffice Writer)
Будьте внимательны! У Вас есть 10 минут на прохождение теста. Система оценивания — 5 балльная. Разбалловка теста — 3,4,5 баллов, в зависимости от сложности вопроса. Порядок заданий и вариантов ответов в тесте случайный. С допущенными ошибками и верными ответами можно будет ознакомиться после прохождения теста. Удачи!
Система оценки: 5 балльная
Список вопросов теста
Вопрос 1
Текстовый редактор это программа для .
Варианты ответов
- обработки графической информации
- обработки видеоинформации
- обработки текстовой информации
- работы с музыкальными записями
Вопрос 2
Какие основные элементы текста мы можем выделить при работе в текстовом процессоре OpenOffice Writer?
Варианты ответов
- символ
- абзац
- строка
- программа
- знак
Вопрос 3
Как удалить все буквы «и» в тексте?
Укажите оптимальный вариант.
Варианты ответов
- Воспользоваться специальной программой
- Поставить курсор после каждой буквы «и» и нажимать BS
- По очереди выделять их и нажимать Del
- Использовать пункт меню Правка — Найти и заменить
Вопрос 4
Укажите порядок сохранения отредактированного документа под другим именем.
Варианты ответов
- Нажать Файл
- Сохранить Как
- Выбрать место и ввести имя файла
- Нажать сохранить
Вопрос 5
Как включить нужную панель инструментов?
Варианты ответов
- Файл — Панели инструментов — Выбрать нужную панель
- Сервис — язык — Панели инструментов — Выбрать нужную панель
- Вид — Панели инструментов — Выбрать нужную панель
- Правка — Панели инструментов — Выбрать нужную панель
Вопрос 6
Какие пункты мы можем осуществить при выводе документа на печать?
Варианты ответов
- Указать количество страниц, например от 2-ой до 10-ой
- Указать печать 2-х страниц на одной
- Указать печать 5 страниц на одной
- Распечатать только отдельные страницы
- Выбрать печать нескольких копий
Вопрос 7
Как удалить символ стоящий слева от курсора.
Варианты ответов
- Нажать Delete
- Нажать BS
- Нажать Alt
- Нажать Ctrl+Shift
Вопрос 8
Варианты ответов
- устройство ввода текстовой информации
- клавиша на клавиатуре
- наименьший элемент отображения на экране
- метка на экране монитора, указывающая позицию, в которой будет отображен вводимый с клавиатуры
Вопрос 9
При наборе текста одно слово от другого отделяется:
Варианты ответов
- точкой
- пробелом
- запятой
- двоеточием
Вопрос 10
В текстовом редакторе при задании параметров страницы устанавливаются:
Варианты ответов
- Гарнитура, размер, начертание
- Отступ, интервал
- Поля, ориентация
- Стиль, шаблон
Вопрос 11
Как можно вставить рисунок в текстовый документ?
Варианты ответов
- из графического редактора
- из файла
- из коллекции готовых картинок
- из меню Файл
- из принтера
Вопрос 12
Как в текстовом редакторе напечатать символ которого нет на клавиатуре?
Варианты ответов
- Воспользоваться вставкой специального символа
- Использовать для этого рисование
- Вставить из специального файла
Вопрос 13
К какому процессу обработки текстовой информации относятся следующие действия:
Ваня напечатал письмо другу, затем исправил некоторые ошибки, правильно расставил знаки препинания и отправил его.
Варианты ответов
- Редактирование текста
- Форматирование текста
- Редактирование и форматирование текста
Вопрос 14
К какому процессу обработки текстовой информации относятся следующие действия:
Николай открыл текст, выровнял в нем заголовок по центру, оформил его большим красивым шрифтом и сделал его красным цветом.
Варианты ответов
- Редактирование текста
- Форматирование текста
- Редактирование и форматирование текста
Вопрос 15
Укажите в каких единицах измерения указывается размер шрифта