Парсер Яндекс Wordstat онлайн через API
С помощью инструмента можно отправлять запросы к Yandex вордстат и получать ответы в формате JSON.
Парсер может быть использован для:
- сбора левой колонки Wordstat;
- сбора правой колонки;
- проверки всех видов частотностей по любым регионам;
- проверки сезонности ключевых слов (история запросов).
Экономия времени
Не нужно возиться с прокси и аккаунтами, решением капчей и с другими сопутствующими проблемами. Это мы берём на себя.
Удобный формат
Выдаём данные в том формате, который вы используете для сбора вордстата напрямую в JSON.
Экономия денег
Платите только за то, что использовали. Не нужно арендовать прокси на месяц или оплачивать месячные тарифные планы. Стоимость 1000 запросов от 10р.
В режиме реального времени
Всё происходит в режиме реального времени, вы сразу видите результаты живой выдачи, не используем баз. Парсим Wordstat, а не Яндекс.Директ.
Проверка частотностей запросов в вордстат
Собирайте любые виды частот — 1) базовую; 2) фразовую “”; 3) точную “!”; 4) уточненную []. Поддерживаем настройки сбора: выбор региона или нескольких регионов и устройства).
Сбор ключевых слов с wordstat
Сбор ключевых фраз из левой и правой колонки на любую глубину. Сервис позволяет собирать от 1 до 40 страницы.
История запросов
Поддерживаем выбор регионов и устройств (десктопные, мобильные, планшеты или все). Функционал позволяет отследить, как менялась популярность ключевых фраз. С помощью этих данных Вы можете определить сезонность ключа и общий тренд.
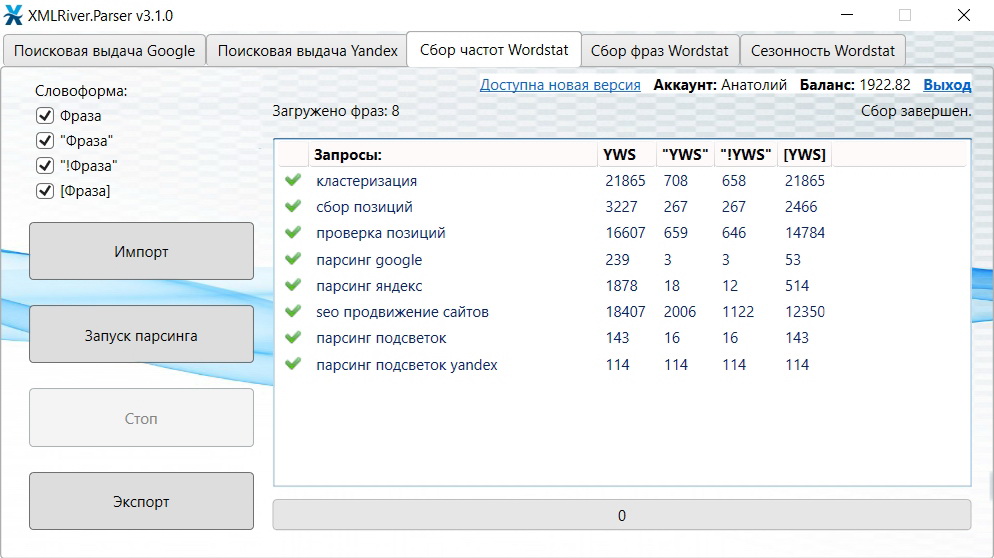
Бесплатная десктопная программа для сбора данных
Предоставляем программу XMLRiver.Parser для сбора фраз, частот всех видов и истории запросов. Выгрузка осуществляется в csv формат.

Павел Горбунов,
SEO-оптимизатор, pavel-gorbunov.ru
Мне понравился сервис. Я парсил выдачу Гугл с его помощью, скорость была хорошая, 1000 запросов сервис собрал очень быстро. В сравнении с другими сервисами получилось чуть быстрее.
Более того, по моему запросу разработчки сделали возможность парсинга ТОП-0 Гугл, поэтому решения для кастомных задач — это явное преимущество. Открытость к диалогу — это главный плюс сервиса для меня. При возникновении нетиповой задачи всегда можно обратиться с запросом на доработку, и будет найдено решение (которого, возможно, еще и нет на рынке). Поэтому рекомендую сервис для типовых и нетиповых задач.

Александр Ожгибесов,
SEO-оптимизатор, ozhgibesov.net
XMLRiver — это единственный работоспособный вариант в больших объемах за адекватный чек парсить Google. Я, как специалист по семантике, использую сервис для парсинга выдачи для SEO. Относительно недавно добавили множество вариаций для дополнительного парсинга, который очень полезен для серьёзной аналитики выдачи (0 позиция, доп ссылки и т.д.). Всячески хвалю и рекомендую XMLRiver для работы!
Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/cw/u4/lf/cwu4lfx-4whdvwu3ccrhmfv_po8.png)
Яндекс.Вордстат — «классический» инструмент для анализа поискового спроса и подбора ключевых слов. Разбираем в деталях, как с ним правильно работать. Делимся полезными фишками и вспомогательными инструментами.
Из статьи вы узнаете:
- зачем нужен Яндекс.Вордстат и для каких задач он подходит;
- как использовать Вордстат для оценки спроса и сезонности;
- как ускорить и упростить подбор ключей в Вордстате;
- как собрать частотность по списку ключей любого объема.
Содержание статьи
Для чего нужен Яндекс.Вордстат
Яндекс.Вордстат — бесплатный сервис для получения статистики поисковых запросов в Яндексе. С помощью сервиса можно посмотреть, сколько раз пользователи искали определенный поисковой запрос на протяжении месяца. Но это далеко не всё.
Какие данные выдает Вордстат
1. Статистика по частотности:
- указанного запроса;
- запросов, которые содержат указанную фразу или слово.
2. Похожие запросы для расширения семантики.
3. Данные по частотности с разбивкой по регионам и городам.
4. Данные по показам с разбивкой по типу устройств (десктопы, смартфоны, планшеты).
5. Сезонные колебания спроса по выбранной фразе (динамика популярности фразы за прошедшие два года в разрезе месяца или недели с разбивкой по типу устройств).
Как работать с Яндекс.Вордстатом
Для работы с сервисом авторизуйтесь в учетной записи Яндекса и перейдите на страницу Вордстата. Здесь вы увидите поисковую строку для ввода ключевых слов, по которым нужно проверить частотность.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/h1/nq/yj/h1nqyj7n0ax-6tnvgjl2jzyckps.png)
Рассмотрим подробнее, как выглядит интерфейс сервиса и какие данные в нем доступны после подбора по ключевой фразе.
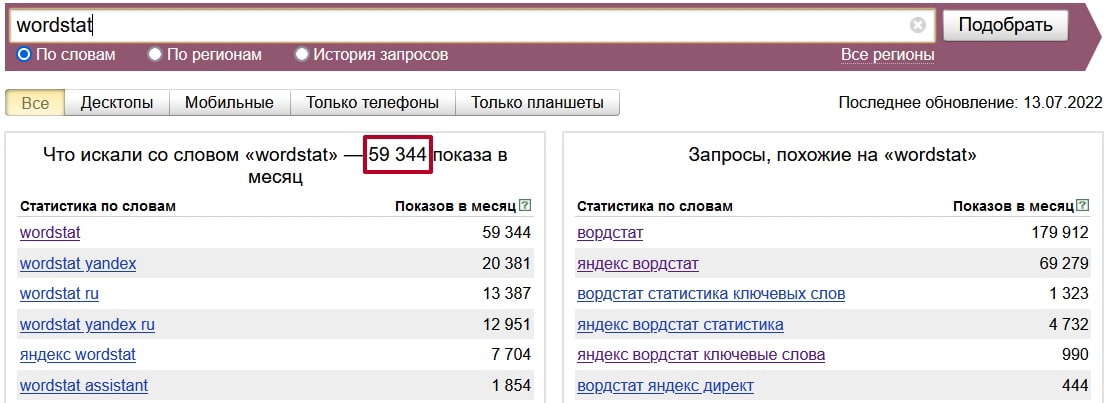
Для примера укажем в поисковой строке фразу «облицовочный кирпич» и нажмем «Подобрать». Сервис покажет две колонки с результатами.
Левая колонка
В левой колонке отображается список запросов, содержащих проверяемую фразу. Напротив каждого запроса — примерный прогноз количества показов, которые можно получить по этому запросу за месяц.
Внизу списка есть кнопки переключения страницы. На одной странице выводится до 50 фраз. Максимально можно посмотреть результаты до 41-й страницы (то есть для одного ключевого слова или фразы можно собрать до 2050 фраз, которые его содержат).
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/ot/-7/iw/ot-7iwkhot7gb93rpnf4xyxbuhm.png)
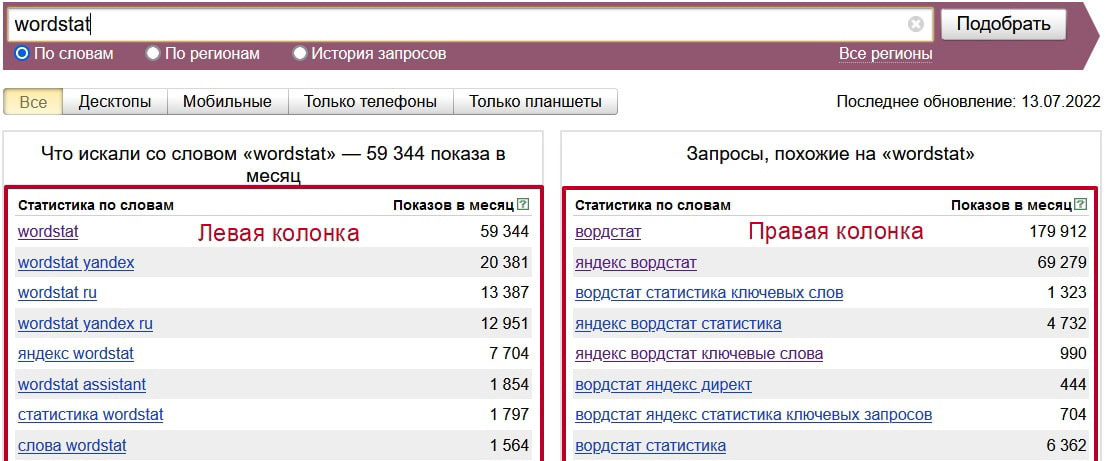
Правая колонка
Также в интерфейсе сервиса отображается правая колонка с названием «Запросы, похожие на . ».
Здесь указаны запросы, похожие на тот, который мы указали для подбора статистики. Запросы из этой колонки могут содержать часть основного запроса, но это не обязательно.
Правая колонка подходит для расширения семантики с целью увеличения охвата.
Проверяем спрос в определенных регионах
В Вордстате доступен просмотр статистики в определенных регионах. Например, если вы планируете рекламироваться только в Московской области, нет смысла смотреть данные частотности по всей России.
Кликните по названию региона, выбранного по умолчанию (справа под поисковой строкой), проставьте галочки возле нужных регионов и нажмите «Выбрать».
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/3t/ox/lb/3toxlbafq81takloucx9mrdbm_u.png)
Сервис отобразит данные по частотности и запросах в выбранных регионах.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/xj/yd/za/xjydzaim-2ep4hu6praqkkcnkyu.png)
Также детализированная статистика по показам и региональной популярности доступна на вкладке «По регионам».
Здесь отобразится список регионов, отсортированный по столбцу с количеством показов в порядке убывания (столбец «Показов в месяц»): первый в списке — регион с самым большим количеством показов, последний — с нулевой или околонулевой частотностью.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/sa/tk/6m/satk6mpskk9baencznfbxbnzqxy.png)
Еще один столбец — «Региональная популярность». Здесь указана доля, которую занимает регион в показах по данному слову, по отношению к доле всех показов, которую занимает регион. Значения в этом столбце следует трактовать так:
| Популярность слова/фразы | Что значит |
| 100% | данная фраза имеет обычный спрос в этом регионе |
| более 100% | повышенный спрос |
| менее 100% | пониженный спрос |
По умолчанию в таблице отображаются сводные данные по всем доступным регионам и городам. С помощью соответствующих вкладок можно переключить отображение и посмотреть данные только по регионам или только по городам.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/jo/kj/8y/jokj8yme8xgxe3vgc0ivzup0fpc.png)
Статистика популярности запросов по регионам
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/fh/cd/3n/fhcd3njf537pk1iqnge9zyqwnvq.png)
Данные по частотности запроса с разбивкой по городам
Также здесь доступно представление в виде карты:
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/v8/fl/sd/v8flsdcc6hkrc8hcfz0yvlbvx8u.png)
Кликните по стране, чтобы посмотреть детализацию популярности запроса по регионам:
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/we/zg/pw/wezgpwir29q1as6tssx-j0sxoee.png)
Обратите внимание! Статистика по регионам особенно важна, если у вас локальный бизнес, привязанный к определенному городу или области.
Но и для бизнесов, которые работают по всей стране, такая статистика также пригодится. Так вы сможете увидеть, в каких регионах спрос ниже. Это поможет задавать корректировки ставок по регионам.
Проверяем зависимость спроса от сезона
Еще одна полезная функция Вордстата — в нем можно проверить, меняется ли спрос на продукт/услугу в зависимости от сезона. Для этого вбейте в поиск нужную фразу и кликните по переключателю «История запросов».
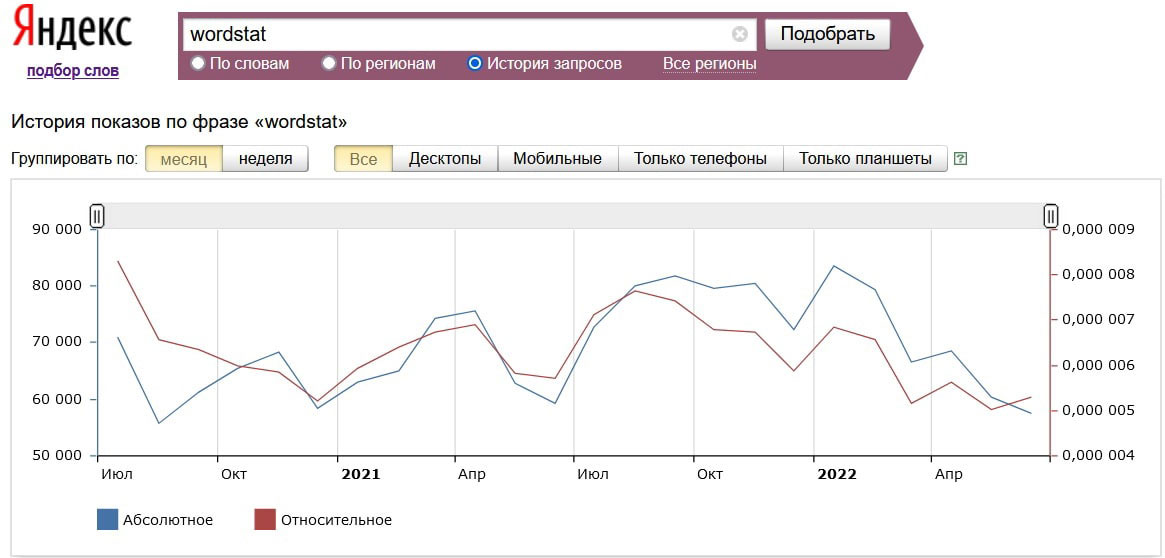
Откроется график, на котором будет динамика количества запросов для выбранной фразы на протяжении двух лет.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/zz/h5/pz/zzh5pz6vhjx5nrhpmybpshlfd9a.png)
В нашем примере видно, что спрос на футболки с принтами более-менее ровный на протяжении года, но в декабре каждого года есть сезонные всплески.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/5e/ex/rk/5eexrkbe7rza9yvkqfqosqsbhem.png)
С помощью проверки фразы в разделе «История запросов» можно обнаружить зарождающиеся тренды. Если вы видите, что по какому-то запросу спрос был низким, но от месяца к месяца начал расти — возможно, это признак нового тренда. В таком случае стоит подумать об оптимизации страниц под этот запрос.
Как работать с разделом «История запросов»
Рассмотрим функционал вкладки «История запросов» подробнее.
Над графиком есть вкладки, с помощью которых можно группировать данные:
- по временному диапазону (месяц или неделя);
- по типу устройств.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/gz/tj/u5/gztju5lmyjvnwtzhbfreknd1rf0.png)
Если выбрать группировку по месяцам, сервис покажет данные за прошедшие два года. При группировке по неделям — только за 1 год.
Также вы можете более детально посмотреть данные за временной отрезок.
Динамику популярности поисковой фразы можно посмотреть для разных типов устройств. Здесь доступны такие варианты:
- только десктопы;
- мобильные (смартфоны и планшеты);
- только телефоны;
- только планшеты.
В примере видим, что доля запросов с планшетов совсем небольшая по сравнению со смартфонами:
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/_i/lb/bx/_ilbbxij9zrmsldt14ai7lks7eo.png)
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/ln/tw/tm/lntwtmmuwdin0rdpaecobn_7e28.png)
График истории показов
На графике есть две линии:
- Синяя — показывает абсолютное значение количества показов по выбранной фразе в конкретный период времени.
- Красная — относительное значение. Рассчитывается как отношение количества показов по выбранной фразе к общему количеству показов всех результатов поиска в Яндексе за соответствующий месяц. Другими словами, относительное значение показывает, насколько данный запрос популярен по сравнению с другими поисковыми запросами.
Под графиком — таблица с абсолютными и относительными значениями по каждому месяцу или по каждой неделе за выбранный период.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/jw/av/at/jwavatc6geo9owjditz_fz8krr4.png)
Используем минус-слова для фильтрации нецелевых запросов
При проверке фразы в Вордстате сервис покажет поисковые запросы, которые могут содержать нерелевантные слова. Такие слова желательно исключить, чтобы оценить чистый спрос на вашу услугу или товар.
Допустим, у вас интернет-магазин цифровой техники, и вы хотите запустить кампанию контекстной рекламы на группу товаров «Ноутбуки». Для оценки спроса смотрим в Вордстате статистику по фразе «купить ноутбук».
Эту фразу пользователи ищут примерно 690 тысяч раз в месяц. При этом запросы с этой фразой иногда содержат слово «недорогой».
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/50/qz/po/50qzpo7va9_qm-vtdqpmgfcobma.png)
Если такой запрос для нас является нецелевым (например, вы продаете только геймерские ноутбуки с топовой начинкой), его лучше исключить из статистики.
Для этого используем минус-слова. Вводим в поисковую строку Вордстата запрос «купить ноутбук» и добавляем минус-слово «-недорогой». Жмем «Подобрать» и видим: количество запросов стало меньше, а в блоке «Что искали со словом» — нет результатов, содержащих слово «недорогой».
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/kj/3e/zk/kj3ezk8nenq-xahogtddsigyjlg.png)
Также к основной фразе можно добавить несколько минус-слов, чтобы исключить другие нерелевантные запросы. Посмотрите запросы из левой и правой колонок, найдите слова или фразы, которые вам не подходят, и укажите их в качестве минус-слов.
На выходе вы получите чистые данные по релевантным запросам, что поможет качественно оценить спрос.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/3u/pw/52/3upw52ngrztv65q59y8nu7y_kb8.png)
Какие группы слов часто используют в качестве минус-слов в контекстной рекламе:
- DIY-слова — «сделать», «своими руками», «самостоятельно» и т. д.;
- маркеры информационных запросов («почему», «как», «чем», «какой» и т. п.);
- слова «мусорного» спроса — «бесплатно», «giveaway», «в дар» и т. п.
- маркеры вторичного рынка — «бу», «подержанный»;
- характеристики или свойства продукта, которые не подходят для вашей кампании. Например, если вы продаете только мужские кроссовки, исключите из статистики слова «женские» и «детские».
Подробно о работе с минус-словами в Яндекс.Директе и Google Ads мы рассказывали в этом посте.
Операторы поиска: уточняем статистику по запросам
С помощью операторов поиска можно уточнить запрос и посмотреть точную статистику показов по фразе в нужной форме или с определенным порядком слов. Использование операторов доступно в разделах «По словам» и «По регионам».
Кавычки » » (фиксация слов)
При указании запроса в кавычках вы увидите статистику только по указанному словосочетанию (без добавления других слов). При этом порядок слов и окончания могут меняться.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/j6/gf/yg/j6gfygss5xtqgggkfcr0pftz2de.png)
Детальный разбор операторов Яндекс.Директа с примерами — в блоге Click.ru.
Восклицательный знак! (фиксация словоформы)
Используется для фиксации окончания в указанном виде и размещается перед словом, в котором его нужно зафиксировать.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/tb/9i/dz/tb9idzmiaswj7oq4ump83mku8h4.png)
Обратите внимание! Используйте оператор «кавычки» совместно с оператором «!». Так вы сможете узнать точную частотность любого запроса.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/v_/vj/jw/v_vjjwtrphfbnxczcz874oocu1g.png)
Плюс + (фиксация стоп-слов)
Используется для проверки частотности по запросам, содержащим стоп-слова (служебные части речи, местоимения и др.). По умолчанию в Яндекс.Вордстате они не учитываются. Например, если мы введем в Вордстате фразу «двери для», сервис покажет статистику без учета предлога «для».
Сравните сами. По запросу «двери» сервис показывает 9 631 111 показов в месяц:
А вот статистика по запросу «двери для» (результат аналогичный):
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/ad/bx/oj/adbxoj0endeeslq0xhgtgjrofgc.png)
А теперь фиксируем стоп-слово «для» и получаем уже 831 973 показов в месяц, а не 9 631 111.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/5a/gd/-g/5agd-gexolx4uuv_zsyje7ydq8m.png)
Вертикальный слэш | (логический оператор «или»)
Применяется для объединения статистики по разным запросам. Например, если мы продаем входные двери, полезно узнать количество запросов от владельцев квартир и загородных домов. Для этого используем оператор | — вводим в Вордстате такую фразу:
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/ny/vd/ds/nyvddsn32bp7kmjiq1gl5dy9hgc.png)
В результатах подбора будет статистика по запросам, содержащим любое из словосочетаний, указанных в круглых скобках.
Квадратные скобки [] (фиксация порядка слов)
При использовании этого оператора система покажет статистику по запросам, в которых содержатся указанные слова в заданном порядке.
Использование [] поможет исключить запросы с иным порядком слов и зафиксировать нужный порядок слов. Это важно, например, если вы рекламируете продажу билетов по конкретным направлениям.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/th/rq/ig/thrqigbufrdwd7pxl4bkibgnu6k.png)
Полезные расширения для работы с Вордстат
Основная сложность при работе с Вордстатом — нужно проверить десятки (а то и сотни запросов) и обработать весь объем полученной информации. Это рутинная задача. Вот два браузерных расширения, которые помогут вам в работе с сервисом:
- Yandex Wordstat Assistant. При включенном расширении в интерфейсе Вордстата слева отображается окно, в которое можно добавить слова из результатов подбора. По ходу того, как вы используете Вордстат для проверки частотности и поиска дополнительных запросов, добавляйте их в список. Затем скопируйте и сохраните список в таблице (расширение позволяет скопировать слова с частотностью или чистый список слов). Это удобнее, чем постоянно переключаться между браузером и таблицей, а также экономит время, если нужно сохранить слова сразу с данными по частотности.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/ci/r5/ig/cir5igglqrm1hthpafusfe8_fww.png)
- Yandex Wordstat Helper. Расширение пригодится для удобного добавления фраз и предложенных Вордстатом вариантов, а также сортировки списка по алфавиту или частотности.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/za/27/1a/za271axzjo3z4f5giggofrpz-uu.png)
Больше полезных расширений (75+) для интернет-маркетинга вы найдете в нашем обзоре.
Как автоматизировать подбор ключевых слов в Вордстате
Даже с помощью плагинов вручную работать с Вордстатом достаточно трудоемко. Но процесс можно автоматизировать. Для этого нам пригодится два инструмента Click.ru:
- Подбор слов и медиапланирование.
- Парсер частотностей Вордстат.
Собираем ключевые слова
Зарегистрируйтесь / авторизуйтесь в Click.ru и откройте инструмент «Подбор слов и медиапланирование».
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/3q/5b/b1/3q5bb1so5bgvc_fdie6pjilfw30.png)
Укажите базовые данные:
- URL сайта, для которого будете собирать слова;
- место размещения рекламы (поиск, контекстно-медийная сеть или оба варианта).
- регионы, в которых планируете показывать рекламу.
По умолчанию система фиксирует стоп-слова (оператор +, который мы рассматривали выше) и проводит кросс-минусацию. Галочки лучше не снимать.
После указания всех необходимых данных нажмите «Начать новый подбор».
Система проанализирует сайт (URL которого указали на этапе базовых настроек). На основе контента сайта система автоматически подберет релевантные ключевые фразы.
Вы можете добавить к этому списку свои слова или воспользоваться дополнительными инструментами автоматического подбора:
- Слова конкурентов. Здесь нужно будет указать URL сайтов-конкурентов. Система проанализирует их и соберет семантику.
- Слова из счетчиков статистики. Откройте доступ к счетчикам Яндекс.Метрики и/или Google Аналитики. На основе их данных система подберет запросы, по которым к вам на сайт приходили посетители.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/jj/lh/bg/jjlhbgzdruk9-qe-dcc8iywsij8.png)
Автоматический подборщик слов — это хорошо. Но нам нужны данные Вордстата. Обратите внимание на блок «Ручной подбор слов». Это и есть подборщик на основе данных Вордстата.
Как работает подборщик:
1. Введите по одному или списком базовые слова:
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/oj/ir/au/ojirauy-tnmfus6mfeyi9nncipu.png)
Система для каждого слова определяет частотность, а также прогнозы по кликам и бюджету в зависимости от желаемой доли трафика (указываете в столбце «Позиция»).
2. Для просмотра вложенных запросов нажмите на значок списка слева от заданной фразы.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/1u/wo/8q/1uwo8qbxhc9etzr8irbbm-orbnw.png)
Углубляться можно до тех пор, пока не закончатся вложенные запросы.
3. Просмотрите список подобранных слов. Поставьте галочки на тех, которые вам подходят, и нажмите «Добавить в медиаплан». Вы можете отметить одновременно запросы из ручного и автоматического подборщиков, и добавить в общий список.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/9q/dt/ct/9qdtctpmdvofokvmqy6fniuzji4.png)
Система просчитает бюджет по ключевым словам. Отчет со списком выбранных слов можно скачать в XLSX-формате. При желании можете продолжить настройку — в этом случае система сгенерирует объявления под каждое ключевое слово.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/uq/bm/fj/uqbmfjplotrirkiifh5fcbhxgd0.png)
Проверяем частотности Вордстат
С помощью парсера Вордстат можно проверить частотность для списка запросов.
Откройте страницу парсера. Укажите список запросов в поле «Список фраз для проверки». Также фразы можно загрузить с помощью XLSX-файла (обратите внимание, все запросы должны находиться на первом листе файла, 1 ячейка — 1 запрос).
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/0p/ks/5m/0pks5mkqcxxif46qpcv4_fx4jjo.png)
Далее задайте настройки парсера:
- Регионы, в которых хотите рекламироваться. Если нужно посмотреть частотность по каждому региону в отдельности, проставьте галочку на опции «Разделить по регионам в отчете».
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/k3/fy/yf/k3fyyfsqvnhmpeko1b1egutsl1g.png)
- Параметры сбора частотностей. Здесь можно указать, с помощью каких операторов следует проверить частотность по каждой фразе. Есть четыре варианта:
- широкое соответствие;
- оператор «» (фиксирует количество слов в фразе);
- оператор «кавычки» с восклицательным знаком. Фиксирует количество слов в фразе и словоформу каждого слова;
- оператор [] (квадратные скобки). Используется для фиксации порядка слов в фразе.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/sq/gu/rf/sqgurfm34-c-tx1afil1_-8sn7g.png)
Поставьте галочки на нужных параметрах (можете проставить галочки на всех четырех). Затем жмите «Запустить проверку». В течение нескольких минут отчет будет готов, и его можно будет скачать в разделе «Список задач».
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/y6/-9/vs/y6-9vsibyat58dglqlu8ivq0nfi.png)
Отчет скачивается в формате XLSX-файла. Для каждого запроса в таблице указана частотность. Данные по частотности с учетом операторов поиска указаны в отдельных столбцах. Отфильтруйте список и удалите фразы с околонулевой частотностью.
![Как использовать Яндекс.Вордстат для контекстной рекламы [подробный гайд]](https://habrastorage.org/webt/8z/x8/k_/8zx8k_6jfhs7r6vh3n3kiazprrs.png)
Вот подробный гайд по работе с парсером Вордстат.
Заключение
Вордстат — это must have инструмент для подготовки рекламных кампаний в Яндекс.Директе. Использовать его напрямую есть смысл в таких случаях:
- вам надо быстро проверить частотность и вложенные запросы по одной или паре фраз;
- вам нужно проанализировать сезонность спроса.
Если же мы говорим о массовом подборе ключевых слов и проверке частотности по уже собранным фразам, то здесь нужны инструменты автоматизации. Это значительно ускорит работу.
- Яндекс.Вордстат
- семантическое ядро
- семантика
- контекстная реклама
- Wordstat
- Блог компании Click.ru
- Интернет-маркетинг
- Контекстная реклама
Пишем свой парсер Яндекс Wordstat, используя API Директа!
Главная > Инструменты > Пишем свой парсер Яндекс Wordstat, используя API Директа!

Всем привет! В предыдущей статье по Яндекс Wordstat я упомянул о возможности облегчить себе жизнь при подборе ключей с помощью API Директа. Как и обещал, я поделюсь своим скриптом на Python, который автоматизирует процесс сбора ключевых фраз. Разберем, как работает парсер Яндекс Wordstat на конкретном примере и, попутно, научимся получать доступ к API Директа и немножко кодить на Python).
API Директа
Думаю, долго распинаться на тему того, что такое Яндекс Директ необходимости нет) Здесь все более или менее в курсе, что такое реклама в интернете, какие виды рекламы бывают и насколько солидный кусок пирога в этом плане у Яндекса.
Ниже, в разделе «С чего начать» есть ссылка на подробный мануал по регистрации нового приложения. В конечно счете, нужно попасть на страницу создания нового приложения https://oauth.yandex.ru/client/new:
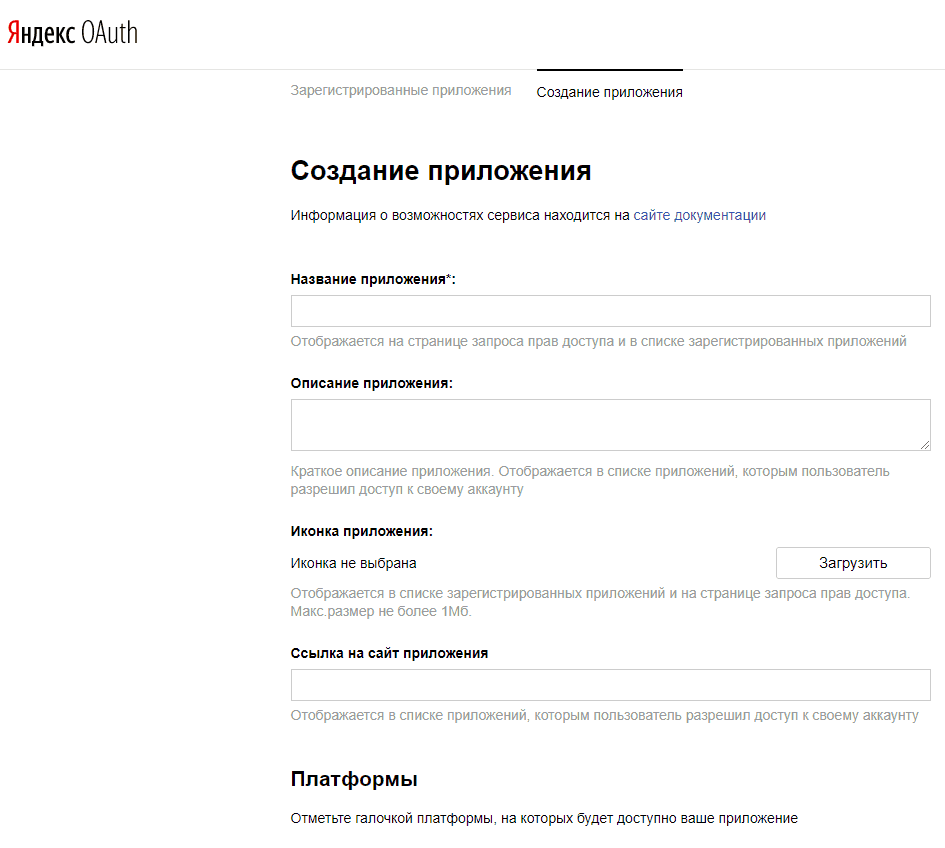
Заполняем необходимые поля:
- Название приложения: можете задать любое название (например, «парсер Яндекс Wordstat» или wordstat_parser»)
- Платформы: отмечаем «Веб-сервисы», подставляем Callback URL, путем нажатия кнопки «Подставить URL для разработки«. Это нужно сделать, чтобы мы могли получить веб-доступ к нашему будущему приложению
- Доступы: выбираем Яндекс.Директ ->Использовать API Яндекс.Директа
Остальное заполнять необязательно. Нажимаем «Создать приложение»:
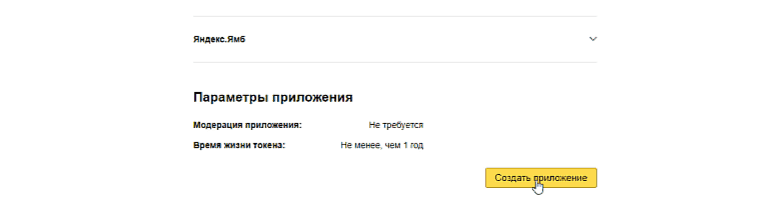
Попадаем на такую страницу и копируем ID нашего приложения:
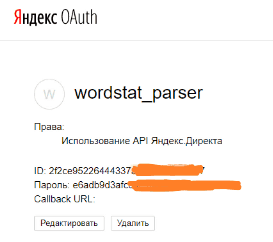
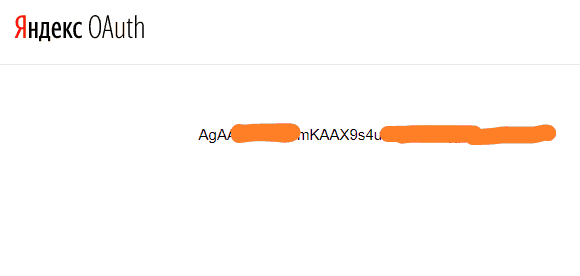
Поздравляю! Токен получен. Сохраните этот ключ в надежном месте, его мы будем вставлять в наш парсер Яндекс Wordstat.

У меня уже есть одобренная заявка (при первом входе, потребуется принять пользовательское соглашение, после чего, получите страницу подобного вида). Вам же нужно нажать кнопку «Новая заявка» -> «Тестовый доступ«:
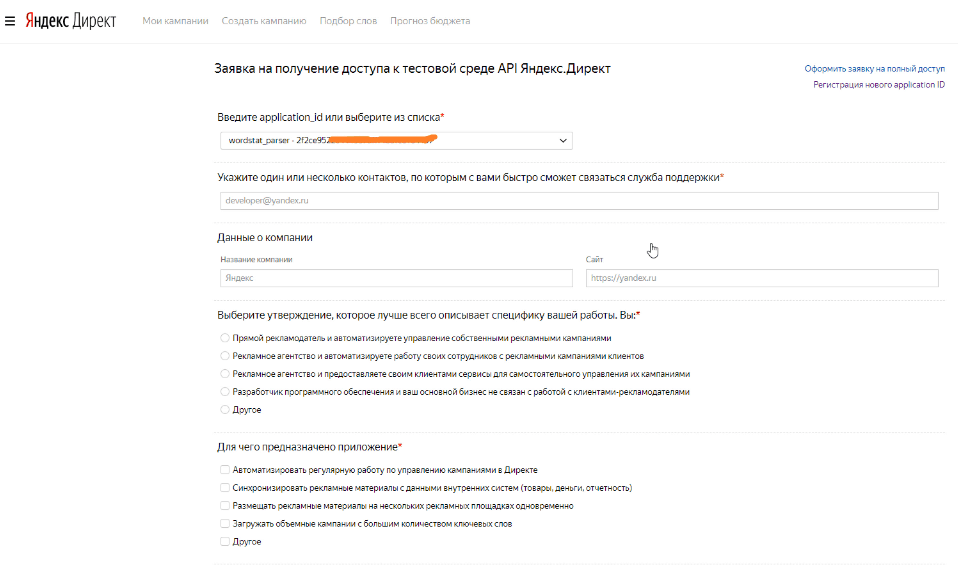
Заполняем необходимые поля:
- application_id: выбираете свое приложение из списка
- E-mail: ваша почта для связи
- Данные о компании: можно не заполнять
- Выберите утверждение…: здесь выбираем первый пункт «Прямой рекламодатель и автоматизируете управление собственными рекламными кампаниями»
- Для чего предназначено приложение: выбираем «Другое» и пишем честно, как есть. Например, «парсер Яндекс Wordstat«
- Основные функции приложения: выбираем «подбор ключевых слов (использование wordstat)«
- Какие новые возможности работы с Директом дает ваше приложение пользователям: пишем что-то в духе «автоматически подбирает ключевые фразы по заданным критериям«
- Ожидаемая дата завершения разработки: я писал примерно + месяц от сегодняшней даты. Влияет ли это на одобрение заявки, честно, не знаю
Читаем пользовательское соглашение. Если все устраивает, соглашаемся и отправляем заявку. Готово)

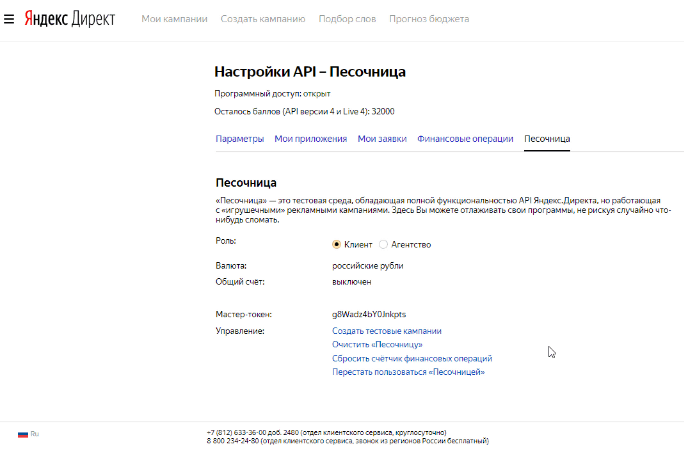
Проверяем, что ничего не забыли
Проверим, что мы должны иметь на данный момент:

- У нас создано приложение в Яндекс Директ
- Мы получили и сохранили отладочный токен (он же — Yandex API Key)
- Получено одобрение на тестовый доступ к нашему приложению
- Активирована песочница
Помним, что на одобрение заявки может уйти несколько дней. Чтобы не терять их впустую, предлагаю заняться подготовкой клиентской стороны (т.е. нашего ПК) к работе с парсером.
Устанавливаем Python
Первое, что нужно сделать — это установить интерпретатор языка Рython (он же — питон). Для этого, заходим на официальный сайт проекта и скачиваем подходящую для нашей системы сборку: https://www.python.org/downloads/


В целом, хотелось бы чуть больше рассказать о том, почему Python так хорош, но в одну статью это не влезет)
Я люблю Python за универсальность. Можно и чат-бота написать и сайты спарсить и рабочую рутину по сведению таблиц Excel автоматизировать. И это не говоря уже о фреймворке Django для веб-приложений на Python!
Приятный бонус — достаточно легко найти высокооплачиваемую работу (если вас это, конечно, интересует). Если задумаете изучить язык на серьезном уровне, рекомендую этот курс. Да, это не быстро (12 месяцев). Да, не бесплатно. Зато, результат обучения с лихвой окупит все вложения.
Дальше все стандартно: запускаем инсталлятор и следуем инструкциям.
Очень удобно, что из коробки вместе с интерпретатором поставляется простенькая среда разработки — IDLE. Конечно, разработчики с опытом уже имеют свою рабочую среду и, понятно, будут работать в ней, но для старта и первого знакомства, IDLE вполне достаточно.

Лично я, в своей работе использую среду Visual Studio Code. Мои скромные потребности она полностью удовлетворяет: интеграция с Git, подсветка и дополнение кода, линтер, встроенный терминал и удобный отладчик. К тому же, она бесплатная) Если захотите чуть глубже окунуться в разработку — рекомендую.
Поздравляю, с подготовкой мы закончили)
Работаем с Yandex.Wordstat-parser
Я написал небольшой класс для работ с API Яндекс Директ в части парсинга ключей из Вордстат. Делал я его для себя и своими силами, поэтому, на идеальный вариант он никак не претендует, но, со своими задачами справляется неплохо) Обсуждение в комментариях приветствуется.
Есть 2 способа установить его: просто скачать с GitHub или с помошью Git (продвинутый способ). Рассмотрим оба варианта.
Качаем парсер Яндекс Wordstat с GitHub
Это очень просто:
- Переходим в репозиторий на GitHub по ссылке: https://github.com/igor-kantor/Yandex.Wordstat-parser

- Нажимаем зеленую кнопку «Clone or download» — > «Download ZIP»;
- Распаковываем архив в любую удобную директорию;
- Готово! Парсер яндекс wordstat уже у вас)
Установка с помощью Git
Тоже самое можно сделать одной простой командой в командной строке, конечно, при условии, что у вас установлен клиент Git:
git clone https://github.com/igor-kantor/Yandex.Wordstat-parser
Класс для работы с API Директа содержится в файле «wsparser.py«. Его трогать не нужно.
В файле «example.py» приведен пример работы с классом wsparser — это и есть парсер Вордстата, в который нужно подставить наши исходные данные.
Открываем файл «example.py» в IDLE (или в любом текстовом редакторе) и вводим свой ключ api yandex, он же — отладочный токен (как его получить, читай выше) — параметр token, и ваш логин в Яндекс — userName:

Параметр url можете оставить без изменения. Если вы получали полный доступ и хотите работать с API Директа не в режиме песочницы, то укажите вместо этого, адрес, указанный строчкой выше (адрес полного доступа). Для парсинга в этом нет необходимости.
Далее, указывается список минус-слов (подробнее, в этой статье), свой список фраз и география (если требуется), по которым хотите собрать выдачу. :

Если хотите уточнить географию — это делается указанием кода региона и/или города в параметре geo.
Больше никаких настроек делать не нужно) Сохраняете файл и запускаете на исполнение. Файл содержит подробные комментарии ко всем действиям — настоятельно рекомендую ознакомиться!
Запуск скрипта
Для запуска скрипта на исполнение достаточно в верхней части окна нажать Run — > Run Module. Откроется терминал Python Shell, куда будет выводиться лог выполнения скрипта. Если все сделали правильно, то увидите нечто подобное:

Теперь откройте папку, где лежит «example.py«:

В файлах «phrases_left.txt» и «shows_left.txt» лежат фразы и частотность левой колонки выдачи Wordstat. В файлах «phrases_right.txt» и «shows_ right .txt» — правая колонка (похожие запросы). За один проход собирается 300 фраз левой колонки для одной фразы. У нас было 2 фразы на входе («фотошоп» и «photoshop»), поэтому, в результате, мы получили 600 фраз на выходе.
Ограничения API Директ на парсинг
Баллы API Директа
Если вы обратили внимание, то в логе парсера первой строчкой приводится информация о том, сколько баллов у нас осталось. При первом запросе результат будет 32000. При втором, уже 31980.
Тем, кто хочет получить результат еще быстрее и без установки дополнительного софта — попробуйте замечательный инструмент для парсинга Wordstat от команды Rush Analytics. Есть бесплатный период, очень удобный интерфейс и, самое главное, он работает в облаке! Это не только удобно, но и гораздо быстрее десктопных приложений.
Тем не менее, надеюсь, что моя статья сподвигнет кого-то на изучение чего-то нового для себя. Разве не от новых достижений мы получаем свою порцию дофамина?) Возможно, кому-то окажется полезным класс на Python и вы используете его в реальном проекте или для создания собственного софта.
С вами был Игорь Кантор, не забывайте подписываться на новости! Всем профита!


Читайте также:
Подбор ключей в Яндекс Wordstat: ручной сбор с Wordstat Assistant
20 ноября, 2019 Автор: Игорь Кантор · Published 20 ноября, 2019 · Last modified 11 марта, 2021
SEO продвижение группы ВКонтакте: органический трафик из поиска
4 марта, 2021 Автор: Игорь Кантор · Published 4 марта, 2021
комментариев 13
Доброго времени суток, Игорь!
Попытался по вашему кейсу сделать парсер но вышла заминка в доступе к приложению API Директа. Мне 3й раз сейчас отказали с комментарием:
«Заявка отклонена. Инструмент для получения статистики поисковых запросов (метод CreateNewWordstatReport и смежные) являются неотъемлемой частью API Директа и самого сервиса Яндекс.Директ. Сам же сервис предназначен исключительно для активных пользователей — в частности рекламодателей. Использование API Директа только для получения данных о статистике поисковых запросов не является целевым использованием сервиса, так как не ведет какого-либо взаимодействия с основными объектами, например рекламными материалами.»
Сталкивались ли с такой проблемой и может знаете как решить ее?
Евгений, здравствуйте!
Я не сталкивался, но предполагаю, что Яндексу не понравилась заявка, а именно, ответ на вопрос «Для чего предназначено приложение». Попробуйте указать что-то в духе «автоматизация управления бюджетом РК». Для чистоты, можно в коде какой-нибудь метод соответствующий упомянуть.
Написал им в поддержку и получил такой ответ: Добрый день, Евгений! К сожалению, в данном случае мы не можем одобрить вашу заявку. Методы «CreateNewWordstatReport» и смежные являются неотъемлемой частью API Директа и самого Яндекс.Директа. Нецелевое использование этого сервиса может привести к каким-либо ограничениям в работе с ним. Если вы не планируете использовать Яндекс.Директ по прямому назначению, то это может считаться нецелевым использованием сервиса. Если вам нужны только данные сервиса Wordstat, то мы рекомендуем использовать общедоступный веб-интерфейс этого сервиса (https://wordstat.yandex.ru ) в ручном режиме. Однако, в случае если вы все же планируете использовать Яндекс.Директ, то опишите, пожалуйста, более подробно, как и какие методы API Директа использует ваша программа: названия методов (включая наименование сервиса для API Директа версии 5); для каких целей используются методы; схема и последовательность вызова методов; с какой частотой производится вызов каждого метода (раз в минуту, раз в час и т.д.) и для каких целей выбрана именно эта частота. Также опишите, как программа производит обработку ошибок, возникающих при работе с API, и как программа учитывает текущие ограничения API Директа. Решил попробовать воспользоваться их Директ.коммандером, вроде тоже самое получается но все равно не то, что мне надо)
не знаете какой-нибудь способ чтоб вордстат выдавал с определенного кол-ва запросов? например чтоб запросы у которых выше 10к не выдавались мне?
Можно спарсить в сервисе Rush Analytics, выгрузить в Excel и отфильтровать по собственным критериям.
В целом, спасибо за ценный комментарий — думаю, читателям будет полезно знать про дополнительные требования к описанию со стороны Яндекс.
Как отпарсить Яндекс wordstat список регионов
При написании своего сервиса SEO аналитики, он же личный кабинет клиента, была поставлена задача получить список федеральных округов, регионов, районов и городов с содержанием идентификаторов Яндекса. Поискав в интернете ничего готово не нашел, так что кому-нибудь данная статья пригодится.
Есть два пути решения как получить список регионов:
1) С помощью API Яндекс директ – выгружается сразу в формате JSON, но что бы получить доступ к API требуется пройти проверку. Так что такой вариант не подходит, нужно еще сделать скрин интерфейса программы (думаю если отскринить скрип, модератор не оценит юмор);
2) Отпарсить html c сайта – самый быстрый и простой вариант.
Первым делом нужно узнать где в html «прячется» наши регионы. Открыв браузер выяснилось, что список регионы загружается с помощью AJAX при клике по ссылке «Все регионы»
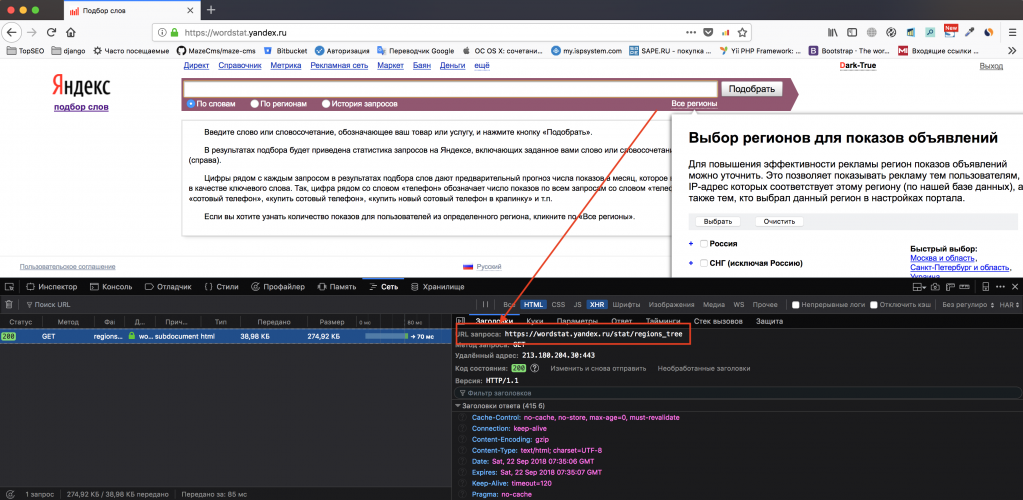
Мы теперь знаем ссылку для получения списка регионов:
https://wordstat.yandex.ru/stat/regions_tree
Написание парсера Яндекс wordstat на Python
Для этих целей нам потребуется 4 модуля, именно:
— «Requests» – для получения html, установить можно командой;
pip install requests
— «BeautifulSoup» – этот модуль нужен для разбора html и поиска нужных узлов DOM по селекторам, а также библиотека для парсинга html5lib, передается в конструктор BeautifulSoup в качестве второго аргумента в виде строки. Не забываем установить модули:
pip install html5lib pip install bs4
— Модуль «re» для работы с регулярными выражениями;
— Модуль «json» для вывода полученного результата в виде json строки.
import requests from bs4 import BeautifulSoup import re import json
Создадим три переменные
headers = < 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' >url = "https://wordstat.yandex.ru/stat/regions_tree" result = []
headers – заголовок агента, чтобы нас не заблокировали;
url — адрес списка регионов;
result – список словарей регионов, который мы получим в результате парсина.
Пишем функцию для парсинга:
def get_region(): if len(result) > 0: return result session = requests.Session() r = requests.get(url, headers=headers) dom = BeautifulSoup(r.text, "html5lib") region = dom.find(id="beginRegions") def get_tree(group, parent): for item in group: if item.name == 'div': if re.match("^region", item['id']): idparse = re.findall(r'region(\d+)', item['id']) result.append(< 'title': item.label.string, 'id': int(idparse[0]), 'parent': int(parent) >) get_tree(item.children, idparse[0]) get_tree(region, 0) return result
get_tree – это рекурсивная функция, которая обходит дочерние узлы и добавляет в наш результирующий список.
Все работает осталось выгрузить полученный список в файл, используем для этого код самопроверки:
if __name__ == '__main__': res = get_region() with open("yandex_region.json", "w") as file: json.dump(res, file)
И еще одна полезная пункция «строит» результат в виде дерева в json bild_tree():
def bild_tree(): if len(result) == 0: get_region() tree = [] def tree_recursive(id, node=<>): for item in result: if item['parent'] == id: if 'id' in node: if not 'children' in node: node['children'] = [] new_node = item.copy() tree_recursive(item['id'], new_node) if 'children' in new_node and len(new_node['children']) == 0: del new_node['children'] node['children'].append(new_node) else: new_node = item.copy() tree_recursive(item['id'], new_node) tree.append(new_node) tree_recursive(0) return tree
Написание такого скрипта заняло не больше 10 минут, что намного меньше, если бы мы проходили всю процедуру регистрации API Яндекс.Директа. В следующих уроках расскажу, как авторизоваться в Яндекс для парсинга ключевых слов и обхода каптчи. Подпишись на рассылку, чтобы узнать первым.
Разделы блога
- Маркетинг 13
- Продвижение 20
- Разработка 23