Как написать программу для распознавания тестов по фотографии?
Есть идея создать что-то на подобии ZipGrade (https://www.zipgrade.com/) — это мобильное приложение которое по фотографии сделанной специальной формы распознает ответы на вопросы и считает количество правильных и не правильных ответов. Вопрос заключается в том как можно реализовать приблизительно такой функционал распознавания ответов в форме по фото на python (если можно, то показать минимальный пример распознавания по фотографий в формах)?
Отслеживать
задан 19 мая 2023 в 15:40
245 2 2 серебряных знака 11 11 бронзовых знаков
Для этого стоит использовать обученную модель компьютерного зрения, я знаю что есть библиотеки с уже обученными моделями, распознающими текст по фото, но не уверен, что есть такие, которые распознают выбранные ответы со специальной формы(посмотрел форму по ссылке). Поэтому есть 2 варианта, либо использовать более простую форму, использующую пары № вопроса — ответ, либо заняться обучением модели самому и научить ее распознавать по фото номер вопроса и ответ. Для этого подойдет библиотека cv2
19 мая 2023 в 15:46
1 ответ 1
Сортировка: Сброс на вариант по умолчанию

Минимальный пример кода:
import cv2 import numpy as np # загрузка изображения img = cv2.imread('123.png') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # Бинаризация изображения ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV) # Поиск внешних контуров contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) lst = [] for inx, contour in enumerate(reversed(contours), 1): # Получение координат и размеров описывающего прямоугольника x, y, w, h = cv2.boundingRect(contour) # Выделение области roi = thresh[y:y+h, x:x+w] # Подсчет количества черных пикселей внутри прямоугольника black_pixels = cv2.countNonZero(roi) #print(black_pixels) q = 0 if black_pixels > 2700: #print(inx) q = 1 # Отображение результата на изображении cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2) lst.append(q) chunks = [lst[i:i + 5] for i in range(0, len(lst), 5)] for inx, chunk in enumerate(chunks,1): max_index = chunk.index(1)+1 print(f'вопрос ответ ') # Отображение результата cv2.imshow("Result", img) cv2.waitKey(0) cv2.destroyAllWindows() вопрос 1 ответ 3 вопрос 2 ответ 4 Как написать программу, которая распознает глаза и лица на фото?
Для начала нужно выбрать алгоритм работы и основу для данной задачи. Такая задача может быть реализована с помощью opencv или же с помощью сверточных нейронных сетей (CNN object detection). Если выбор лежит в сторону нейронных сетей то лучше использовать готовые струткруры детекторов (например YoLo). Также желательно найти готовый датасет уже размеченых фото, например mrl.cs.vsb.cz/eyedataset, или разметить картинки самому https://towardsdatascience.com/collecting-data-for.
В датасете уже пристутствуют размеченые данные и координаты блоков. При непосредственной работе с обученой сетью и ее внедрению в систему нужно будет принимать с выхода сети тензор (вектор) с размечеными областями и вектор классов, но для задачи определения одного типа обьектов (глаза) вектор классов Вам не понадобится
Ответ написан более трёх лет назад
Нравится 1 1 комментарий
Рустем Сайфуллин @i_rustem Автор вопроса
спасибо большое
Ответы на вопрос 1
Как написать программу, которая распознает глаза и лица на фото? — какие чудесные, содержательные вопросы пошли на форуме. Ну вот «как написать программу»?
Да элементарно написать такую программу, так-же, как пишутся любые другие программы.
1. Изучаем подходящий язык программирования. Подойдет любой — Python,С++,С#, Julia, Go. на худой конец сойдет и Java.
2. Изучаем методы или ХОТЯ-БЫ инструменты для решения вашей проблемы(в данном случае — распознавания изображения по фото-видео) созданные кем то другим и любезно предоставленные для широкого пользования. Именно изучаем — т.е. смотрим, сравниваем, какой нам подойдет, а какой нет, каким удобнее пользоваться именно в нашем конкретном случае и исходя из нашего опыта, какой дешевле купить, легче установить, проще интегрировать и т.д.
3. Думаем, как встроить/использовать изученные вами и инструменты в программу, которую вы напишете на изученном вами языке.
4. Обучаем построенную систему — как это сделать отличается для каждого из инструментов и (вот неожиданность!) описывается в документации к нему. Кроме того, на сегодня в интернете для каждого из инструментов существует по несколько десятков примеров их использования в аналогичных проектах — ищем, изучаем, применяем.
5.После этого легко и непринужденно применяем нашу программу там и так, как посчитаем нужным. Хоть для распознавания лиц и глаз, хоть ушей и хвостов, хоть колес и руля.
Все, как вы видите совершенно так-же как и при решении любой задачи — ИЗУЧАЕМ, ДУМАЕМ, ПРИМЕНЯЕМ. А вы думали, что эта задача решается как-то по другому, и ее можно в трех строчках описать в виде ответа на форуме. Или что какой-то из этих этапов можно пропустить?
Как написать программу для распознавания лиц


Александр Белозеров Эксперт в разработке ПО.

Выясняем, как устроено распознавание лиц на видео и фото, и пробуем самостоятельно создать собственный детектор вместе с программистом Александром Белозеровым.
Где нужно распознавание лиц?
- Государство: видеоаналитика используется службами безопасности стран для пограничного контроля, а в Москве так находили нарушителей карантина. Службы безопасности организаций, имеющих дело с секретностью, также используют алгоритмы идентификации для контроля доступа сотрудников к секретным объектам.
- IT-индустрия: Microsoft, Google, Яндекс, ВКонтакте тоже разрабатывают собственные алгоритмы.
- Медицина: технология помогает выявить болезни и отслеживать прогресс в лечении.
- Банкинг: банки используют идентификацию по лицу, чтобы снять деньги в банкомате или получить кредит.
- Образование: распознавание лица помогает поймать тех, кто списывает, — сервисы подключаются к камере на компьютере студента и отслеживают его поведение и движение глаз.
- Персональные портативные устройства: на смартфонах помимо идентификации пользователя распознавание лица выполняет и развлекательную функцию — у приложений Samsung и Snapchat оно лежит в основе AR-фильтров и масок для лица.

Освойте профессию
«Fullstack-разработчик на Python»
Fullstack-разработчик на Python
Fullstack-разработчики могут в одиночку сделать IT-проект от архитектуры до интерфейса. Их навыки востребованы у работодателей, особенно в стартапах. Научитесь программировать на Python и JavaScript и создавайте сервисы с нуля.

Профессия / 12 месяцев
Fullstack-разработчик на Python
Создавайте веб-проекты самостоятельно

Как работает распознавание лиц: метод Виолы-Джонса
Один из способов распознать образ — найти контур объекта и исследовать его свойства. По этому принципу работает метод Виолы-Джонса с использованием признаков Хаара, который придумал венгерский математик Альфред Хаар.
Признаки — это набор геометрических фигур с черно-белым узором, их еще называют маски. Они помогают найти границы какой-либо формы, например очертания лица, линии бровей, носа или рта.

В алгоритме Виолы-Джонса маски накладываются на разные части кадра, а программа определяет, может ли в них находиться объект. Работает это так:
- Классификатор (алгоритм, который будет искать объект в кадре) обучают на фотографиях лиц и получают пороговое значение — его превышение будет сигнализировать о том, что в кадре есть лицо.
- В классификатор загружают изображение, на котором будут искать лицо.
- Классификатор накладывает на него маски и отдельно складывает яркость пикселей, попавших в белую часть маски, и яркость пикселей, попавших в черную часть маски. Потом из первого значения он вычитает второе.
Результат сравнивается с пороговой величиной.
Если результат меньше пороговой величины, значит, в части кадра нет лица, и алгоритм заканчивает свою работу. А если больше, он переходит к следующей части кадра.
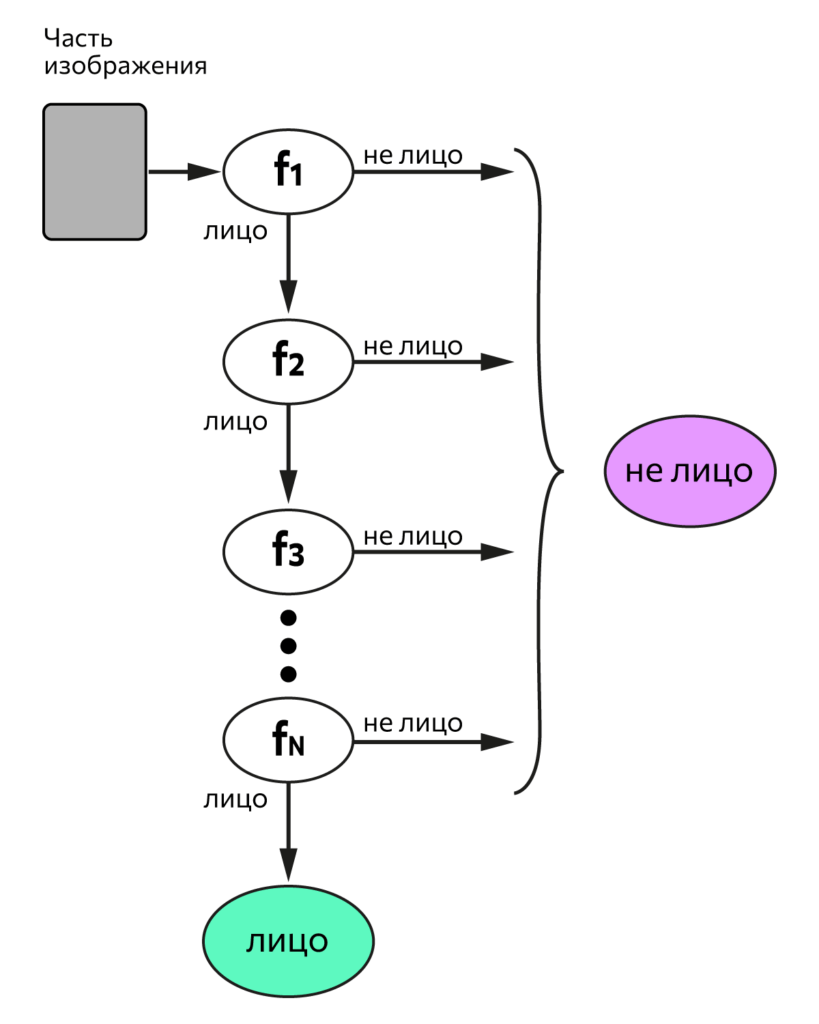
На практике маски находят лицо на фотографии так:

Для разработки мы советуем кроссплатформенную среду разработки PyCharm — в ней есть полезные инструменты для управления версиями пакетов, анализа кода и его отладки. Скачать ее можно тут.
Шаг 3. Создайте новый проект на Python, мы назвали его opencv_face_recognition.
Шаг 4. По правому клику на названии проекта в дереве каталогов добавьте новый файл main.py.
Шаг 5. Установите библиотеку. Для этого в настройках (Settings) проекта нужно найти вкладку с управлением конфигурацией интерпретатора, нажать на «+», вбить в поиск последовательно «opencv-python» и «opencv-contrib-python» и установить эти пакеты.
Это облегченная версия, которая использует для расчетов только процессор, но процесс установки все равно может занять до 15 минут.
Шаг 6. Чтобы использовать установленную библиотеку OpenCV, импортируйте модуль cv2:
До тех пор пока мы не обратимся к каким-либо именам из него, он будет подсвечиваться серым, как неиспользуемый.
Шаг 7. Поместите ранее скачанный классификатор haarcascade_frontalface_default.xml в папку проекта
и загрузите его следующим образом:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
Обратите внимание, что в PyCharm для его корректной подсветки синтаксиса нам пришлось переписать первую строку с импортом.
Шаг 8. Загрузите изображение, на котором мы будем искать лицо, в режиме оттенков серого — информация о цвете алгоритму не важна, только его интенсивность:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Мы будем использовать кадр из сериала «Секретные материалы» с Малдером и Скалли; вы можете поместить в папку проекта любое другое фото.

Шаг 9. Напишите код. Для поиска лиц на изображении мы используем метод с сигнатурой (его именем и списком параметров)
cv2.CascadeClassifier.detectMultiScale (image [, scaleFactor [, minNeighbors [, flags [, minSize [, maxSize]]]]]):
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
Нам хватит первых трех параметров.
- В image надо будет передать 8-битную матрицу изображения.
- scaleFactor показывает, во сколько раз мы будем уменьшать исходное изображение, пытаясь обнаружить объект: это делается потому, что мы изначально не знаем, какого размера будет лицо. Чем меньше будет этот коэффициент, тем дольше будет работать алгоритм.
- minNeighbors влияет на качество обнаружения: чем больше его значение, тем меньше образов сможет обнаружить алгоритм, но тем точнее будет его работа.
Дефолтные значения для последних двух параметров — 1.1 и 3. Их можно заменить на любые другие и подобрать для конкретного случая, если на дефолтных значениях алгоритм будет работать плохо.
Шаг 10. Если лица будут обнаружены, функция вернет набор объектов типа Rect (x, y, w, h) — прямоугольников, начало которых задано парой координат (x, y), а ширина и высота — как w и h. В цикле for добавим эти прямоугольники в исходное изображение image при помощи cv2.rectangle(image, start_point, end_point, color, thickness) по координатам их противоположных вершин (x, y) и (x+w, y+h):
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
Шаг 11. Для отображения результата и закрытия программы по нажатию клавиши добавим еще несколько строк: вывод картинки, ожидание нажатия любой клавиши и последующее закрытие окна. В итоге весь наш проект будет выглядеть так:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
img = cv2.imread(‘xfiles4.jpg’)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.imshow(‘img’, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Шаг 12. Сочетанием клавиш Ctrl-Shift-F10 (Ctrl-Shift-R на MacOS) запустим скрипт:
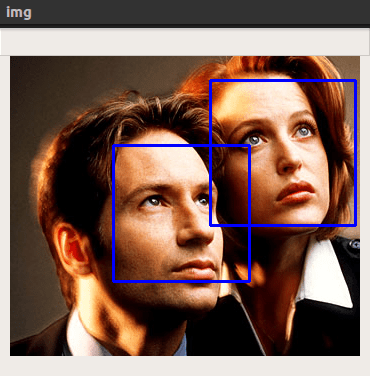
Инструкция: распознаем лицо в видеопотоке с веб-камеры
Модернизируем наш код так, чтобы в реальном времени обнаруживать лица в кадре, например, на видео с веб-камеры.
Шаг 1. Создайте объект для захвата видеострима:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
capture_io = cv2.VideoCapture(2)
Число для cv2.VideoCapture() придется поперебирать, индексом нашей внешней веб-камеры оказалась двойка.
Шаг 2. Считывать кадры с видеоустройства будем в вечном цикле: cv2.VideoCapture.read() возвращает булево значение об успешном считывании из потока (оно нам не нужно) в паре с самой картинкой. Преобразуем ее в 8-битную матрицу так же, как и раньше:
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
capture_io = cv2.VideoCapture(2)
while True:
_, img = capture_io.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Шаг 3. Остается переписать только конец цикла — чтобы у него было условие выхода, например, по нажатию на «q» (от quit, «выйти»). cv2.waitKey(time) 10 мс ожидает ввода с клавиатуры юникод-символа, который приведет к закрытию стрима и программы.
import cv2.cv2 as cv2
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
capture_io = cv2.VideoCapture(2)
while True:
_, img = capture_io.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.imshow(‘img’, img)
if cv2.waitKey(10) & 0xFF == ord(«q»):
break
capture_io.release()
cv2.destroyAllWindows()
Шаг 4. Код готов, нажимаем Ctrl-Shift-F10 (Ctrl-Shift-R на MacOS) и наблюдаем результат вживую:
Создаём свою модель распознавания лиц на Python
У нас уже есть большой цикл про компьютерное зрение и распознавание лиц. В этом цикле мы научились видеть лицо человека, определять примерный возраст и пол, работать с веб-камерой и с файлами. Если не читали, можно начать сейчас:
- Как работает распознавание лиц;
- Находим лица в картинке с веб-камеры;
- Учим нейросеть определять пол и возраст по картинке с камеры;
- Учим нейросеть распознавать возраст по фотографии.
Пока что наш алгоритм не умеет различать разных людей в кадре. Максимум — сказать, что это «мужчина, столько-то лет», а кто конкретно — нет.
Чтобы нейронка научилась узнавать вас по лицу, нужно создать собственную модель распознавания лиц и скормить её нейросети. Тогда она сможет определять и подписывать имя человека в кадре. Сегодня мы сделаем первую часть — соберём датасет и обучим на нём нашу нейросеть. А во второй части прикрутим новую модель к алгоритмам распознавания.
Коротко про распознавание лиц и компьютерное зрение
- Для распознавания лица компьютер должен получить изображение — через камеру или готовый файл.
- Компьютер использует особый алгоритм, который разбивает изображение на прямоугольники.
- С помощью этих прямоугольников алгоритм пытается найти на картинке знакомые переходы между светлыми и тёмными областями.
- Если в одном месте программа находит много таких совпадений, то, скорее всего, это лицо человека.
- Чтобы программистам каждый раз не писать свой код распознавания с нуля, сделали библиотеку компьютерного зрения — cv2. Если в неё загрузить заранее подготовленные параметры лиц, она сможет распознавать их намного точнее.
- С помощью этой библиотеки можно находить на картинке не только лица, но и другие предметы — для этого нужно использовать дополнительные библиотеки либо обучать систему самому.
- Чтобы нейросеть могла понять, кто именно перед ней, её тоже нужно этому обучить отдельно.
Что нужно для обучения нейросети
Чтобы научить нейросеть узнавать конкретных людей в кадре, нужно:
- Собрать датасет.
- Обучить нейросеть на этом датасете и выгрузить результат обучения в отдельный файл.
Датасет в нашем случае — это набор фотографий. Фото должны быть подобраны так, чтобы лицо было в разных ракурсах или с разным освещением. Чем больше фото, тем точнее обучение. Идеально, если по имени файла сразу будет понятно, какие фото к какому человеку относятся.
Когда датасет будет собран, мы отдадим его нейросети — она распознает все лица и построит их модель, которую можно сохранить в отдельном файле. Если этот файл потом отдать другой нейросети, она сможет понять, кто именно находится перед ней в кадре.
Подготовка
В папке, где будет лежать скрипт, нужно создать две папки:
В первой папке будут лежать фотографии, на которых будет учиться нейросеть, а во второй будут результаты этого обучения.
Ещё нужно скачать файл haarcascade_frontalface_default.xml и положить его туда же, где и скрипт. Это модель распознавания лиц по примитивам Хаара.
Собираем датасет
В коммерческих проектах датасет собирают долго и из разных источников, а потом вручную проверяют каждое фото, подходит оно или нет. Чтобы не тратить на это время, используем такой лайфхак: мы сгенерируем датасет из кадров с камеры. Для этого мы запустим захват видео и каждые 100 миллисекунд будем брать новый кадр и запоминать лицо оттуда.
Точно так же работает разблокировка по лицу с помощью камеры в Андроиде: телефон просит покрутить головой перед камерой, а сам в это время делает много снимков, а потом тренирует модель распознавания.
Сначала подключим все нужные библиотеки:
# подключаем библиотеку машинного зрения
import cv2
# библиотека для вызова системных функций
import os
Сразу подключим модель с примитивами Хаара к нейросети — это тот самый файл, который скачивали отдельно.
Чтобы нейросеть в процессе обучения знала, кому принадлежат эти фотографии, добавим параметр id. Это будет внутренний номер пользователя, который мы потом превратим в настоящее имя:
# получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # указываем, что мы будем искать лица по примитивам Хаара detector = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # счётчик изображений i=0 # расстояния от распознанного лица до рамки offset=50 # запрашиваем номер пользователя name=input('Введите номер пользователя: ') # получаем доступ к камере video=cv2.VideoCapture(0)Последнее, что осталось, — сделать цикл, который соберёт как минимум 30 фотографий, найдёт на них лица и запишет их файл с нужными именами. Так как примитивы Хаара — это чёрно-белые прямоугольники, для простоты и ускорения работы мы тоже будем переводить кадры в ч/б. Чтобы потом в процессе тренировки нейросети было проще, мы будем сохранять не кадр с камеры целиком, а только лицо:
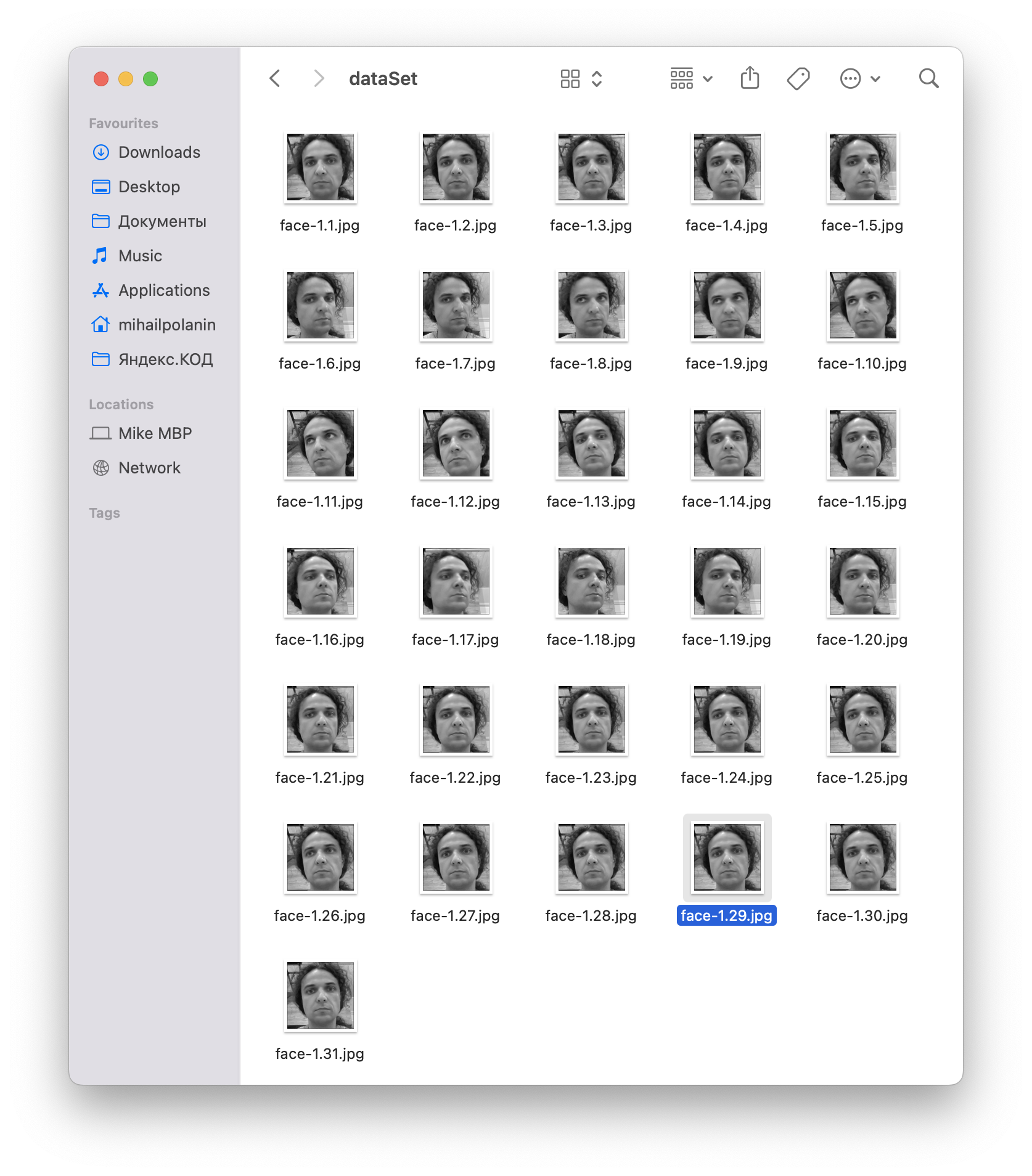
# запускаем цикл while True: # берём видеопоток ret, im =video.read() # переводим всё в ч/б для простоты gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) # настраиваем параметры распознавания и получаем лицо с камеры faces=detector.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100)) # обрабатываем лица for(x,y,w,h) in faces: # увеличиваем счётчик кадров i=i+1 # записываем файл на диск cv2.imwrite("dataSet/face-"+name +'.'+ str(i) + ".jpg", gray[y-offset:y+h+offset,x-offset:x+w+offset]) # формируем размеры окна для вывода лица cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2) # показываем очередной кадр, который мы запомнили cv2.imshow('im',im[y-offset:y+h+offset,x-offset:x+w+offset]) # делаем паузу cv2.waitKey(100) # если у нас хватает кадров if i>30: # освобождаем камеру video.release() # удалаяем все созданные окна cv2.destroyAllWindows() # останавливаем цикл breakСохраняем скрипт как face_gen.py — потому что для тренировки нам понадобится отдельный код. После запуска в терминале нужно будет ввести номер пользователя — им может быть любое число. Во время работы скрипт покажет нам 30 кадров, которые он сделал, а в папке dataSet появятся новые файлы — это значит, что мы всё сделали правильно:
Обучаем нейросеть
Создаём новый файл face_train.py — он будет отвечать за обучение на собранном датасете. Так как мы сами придумывали формат имени файла, то это сильно упростит нам задачу: цифра, которая стоит после дефиса и до первой точки, и будет id пользователя:
face-1.29.jpg ← здесь после дефиса и до первой точки стоит число 1, значит эта фотография относится к пользователю с >
Начало скрипта будет похоже на предыдущее, добавятся только две библиотеки — для обучения нейросети и для работы с изображениями:
# подключаем библиотеку компьютерного зрения import cv2 # библиотека для вызова системных функций import os # для обучения нейросетей import numpy as np # встроенная библиотека для работы с изображениями from PIL import Image # получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # создаём новый распознаватель лиц recognizer = cv2.face.LBPHFaceRecognizer_create() # указываем, что мы будем искать лица по примитивам Хаара faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # путь к датасету с фотографиями пользователей dataPath = path+r'/dataSet'Теперь самое интересное — собираем картинки и id пользователя из датасета. Для простоты id будем называть подписью — если у нас не будет сведений о том, что за человек на фотографиях, будем просто выводить номер пользователя как подпись.
Логика будет такая:
- Открываем папку с картинками.
- По очереди читаем каждую картинку и переводим её в специальный формат, с которым умеет работать библиотека numpy.
- Получаем id пользователя из имени файла — просто убираем всё до дефиса и после первой точки.
- Определяем лицо на картинке — это будет просто, потому что на картинках и так будут только лица.
- Добавляем лица в список лиц.
- Добавляем id пользователя в список пользователей
- Чтобы было видно, что скрипт работает, на долю секунды будем выводить на экран текущую картинку.
- На выходе получим список с лицами и идентификаторами пользователей, к которым они относятся.
Запишем это в виде кода на Python:
# получаем картинки и подписи из датасета def get_images_and_labels(datapath): # получаем путь к картинкам image_paths = [os.path.join(datapath, f) for f in os.listdir(datapath)] # списки картинок и подписей на старте пустые images = [] labels = [] # перебираем все картинки в датасете for image_path in image_paths: # читаем картинку и сразу переводим в ч/б image_pil = Image.open(image_path).convert('L') # переводим картинку в numpy-массив image = np.array(image_pil, 'uint8') # получаем id пользователя из имени файла nbr = int(os.path.split(image_path)[1].split(".")[0].replace("face-", "")) # определяем лицо на картинке faces = faceCascade.detectMultiScale(image) # если лицо найдено for (x, y, w, h) in faces: # добавляем его к списку картинок images.append(image[y: y + h, x: x + w]) # добавляем id пользователя в список подписей labels.append(nbr) # выводим текущую картинку на экран cv2.imshow("Adding faces to traning set. ", image[y: y + h, x: x + w]) # делаем паузу cv2.waitKey(100) # возвращаем список картинок и подписей return images, labelsНаконец, обучаем и сохраняем модель, чтобы её можно было использовать в других проектах. При этом нейросети неважно, сколько пользователей и фотографий будет в датасете — один или тысяча. Она запомнит их все, сопоставит одно с другим и запомнит, как выглядит пользователь под каждым номером. Результат такой обработки сохраним в yml-файле — это один из стандартных форматов для таких моделей:
# получаем список картинок и подписей
images, labels = get_images_and_labels(dataPath)
# обучаем модель распознавания на наших картинках и учим сопоставлять её лица и подписи к ним
recognizer.train(images, np.array(labels))
# сохраняем модель
recognizer.save(path+r’/trainer/trainer.yml’)
# удаляем из памяти все созданные окнаы
cv2.destroyAllWindows()
Если после запуска скрипта в папке trainer появился файл trainer.yml — поздравляем, вы только что обучили нейросеть распознавать лицо человека!
face_gen.py
# подключаем библиотеку машинного зрения import cv2 # библиотека для вызова системных функций import os # получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # указываем, что мы будем искать лица по примитивам Хаара detector = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # счётчик изображений i=0 # расстояния от распознанного лица до рамки offset=50 # запрашиваем номер пользователя name=input('Введите номер пользователя: ') # получаем доступ к камере video=cv2.VideoCapture(0) # запускаем цикл while True: # берём видеопоток ret, im =video.read() # переводим всё в ч/б для простоты gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) # настраиваем параметры распознавания и получаем лицо с камеры faces=detector.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100)) # обрабатываем лица for(x,y,w,h) in faces: # увеличиваем счётчик кадров i=i+1 # записываем файл на диск cv2.imwrite("dataSet/face-"+name +'.'+ str(i) + ".jpg", gray[y-offset:y+h+offset,x-offset:x+w+offset]) # формируем размеры окна для вывода лица cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2) # показываем очередной кадр, который мы запомнили cv2.imshow('im',im[y-offset:y+h+offset,x-offset:x+w+offset]) # делаем паузу cv2.waitKey(100) # если у нас хватает кадров if i>30: # освобождаем камеру video.release() # удаляем все созданные окна cv2.destroyAllWindows() # останавливаем цикл breakface_train.py
# подключаем библиотеку компьютерного зрения import cv2 # библиотека для вызова системных функций import os # для обучения нейросетей import numpy as np # встроенная библиотека для работы с изображениями from PIL import Image # получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # создаём новый распознаватель лиц recognizer = cv2.face.LBPHFaceRecognizer_create() # указываем, что мы будем искать лица по примитивам Хаара faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # путь к датасету с фотографиями пользователей dataPath = path+r'/dataSet' # получаем картинки и подписи из датасета def get_images_and_labels(datapath): # получаем путь к картинкам image_paths = [os.path.join(datapath, f) for f in os.listdir(datapath)] # списки картинок и подписей на старте пустые images = [] labels = [] # перебираем все картинки в датасете for image_path in image_paths: # читаем картинку и сразу переводим в ч/б image_pil = Image.open(image_path).convert('L') # переводим картинку в numpy-массив image = np.array(image_pil, 'uint8') # получаем id пользователя из имени файла nbr = int(os.path.split(image_path)[1].split(".")[0].replace("face-", "")) # определяем лицо на картинке faces = faceCascade.detectMultiScale(image) # если лицо найдено for (x, y, w, h) in faces: # добавляем его к списку картинок images.append(image[y: y + h, x: x + w]) # добавляем id пользователя в список подписей labels.append(nbr) # выводим текущую картинку на экран cv2.imshow("Adding faces to traning set. ", image[y: y + h, x: x + w]) # делаем паузу cv2.waitKey(100) # возвращаем список картинок и подписей return images, labels # получаем список картинок и подписей images, labels = get_images_and_labels(dataPath) # обучаем модель распознавания на наших картинках и учим сопоставлять её лица и подписи к ним recognizer.train(images, np.array(labels)) # сохраняем модель recognizer.save(path+r'/trainer/trainer.yml') # удаляем из памяти все созданные окнаы cv2.destroyAllWindows()Что дальше
Теперь у нас всё готово для того, чтобы мы добавили новую модель в скрипт распознавания лиц. Сделаем это в следующий раз и посмотрим, как нейросеть справляется с этой задачей.
Любите данные? Посмотрите вот это
Возможно, у вас получится построить карьеру в мире дата-сайенса. Это новое направление, в котором очень нужны люди. Изучите эту сферу и начните карьеру в ИТ: старт — бесплатно, а после обучения — помощь с трудоустройством.



Получите ИТ-профессию
В «Яндекс Практикуме» можно стать разработчиком, тестировщиком, аналитиком и менеджером цифровых продуктов. Первая часть обучения всегда бесплатная, чтобы попробовать и найти то, что вам по душе. Дальше — программы трудоустройства.