SQL-Ex blog

Кучи в SQL Server: часть 3 — некластеризованные индексы
Добавил Sergey Moiseenko on Суббота, 19 сентября. 2020
- Кучи в SQL Server: часть 1 — основы
- Кучи в SQL Server: часть 2 — оптимизация чтений
- Кучи в SQL Server: часть 3 — некластеризованные индексы (эта статья)
Некластеризованный индекс
Некластеризованный индекс — это структура индекса, который отделен от данных в таблице. При этом данные могут находиться быстрей, чем с помощью поиска в самой таблице. Как правило, некластеризованные индексы создаются для улучшения производительности часто используемых запросов, которые не покрываются кластеризованным индексом или кучей.
Демонстрация
- Номер файла
- Страница данных
- Слот
Для работы с примерами обратитесь к предыдущей статье. Используется таблица с приблизительно 4000000 записями данных.
К этой таблице очень часто обращаются пользователи для вывода заказов за определенный период. Поскольку не существует индекса на атрибуте OrderDate, всегда должно выполняться сканирование таблицы.
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate = '20081220'
OPTION (QUERYTRACEON 9130);
GO
Использование сканирования таблицы видно в плане выполнения на рис.1.
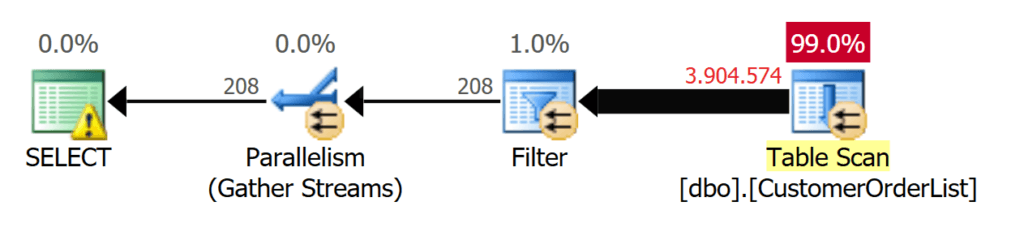
Рис.1: TABLE SCAN используется для получения 208 записей
Сканирования таблицы может быть достаточно быстрым на быстрых системах (0,716 секунд), и программиста может устроить такой временной интервал.
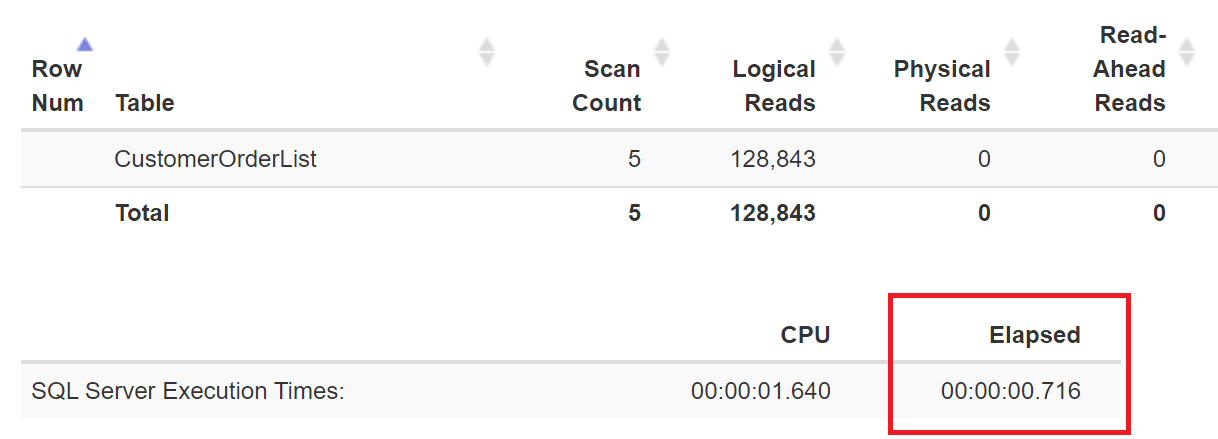
Рис.2: ЦП используется более 1,6 секунды, и затраченное время 0,716 секунды
Высокое время ЦП обусловлено тем фактом, что запрос использует параллельное выполнение, показанное на рис.3.
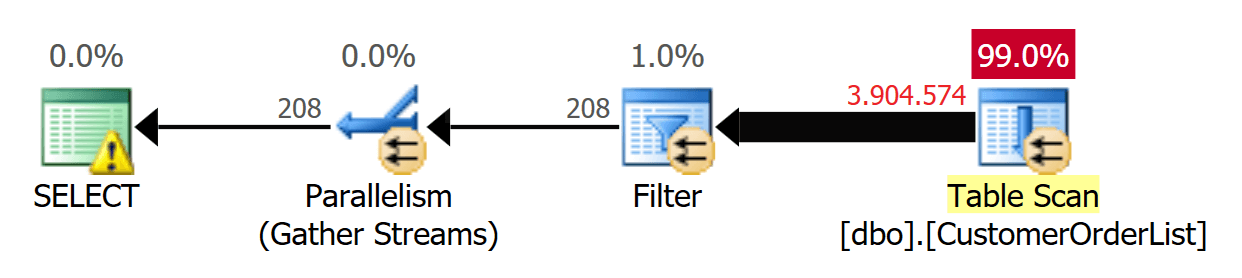
Рис.3: Параллельный план
- Запрос распараллеливается и использует процессоры, сконфигурированные для MAXDOP!
- Блокировка [SCH-S] удерживается на таблице во все время выполнения!
- Что происходит, если не только один пользователь выполнит запрос, но также имеется веб-клиент, выполняющий параллельно тысячи запросов?
CREATE NONCLUSTERED INDEX nix_CustomerOrderList_OrderDate
ON dbo.CustomerOrderList (OrderDate);
GO
Если вы снова выполните тот же запрос из предыдущего примера, то получите следующее улучшение, показанное на рисунке 4:
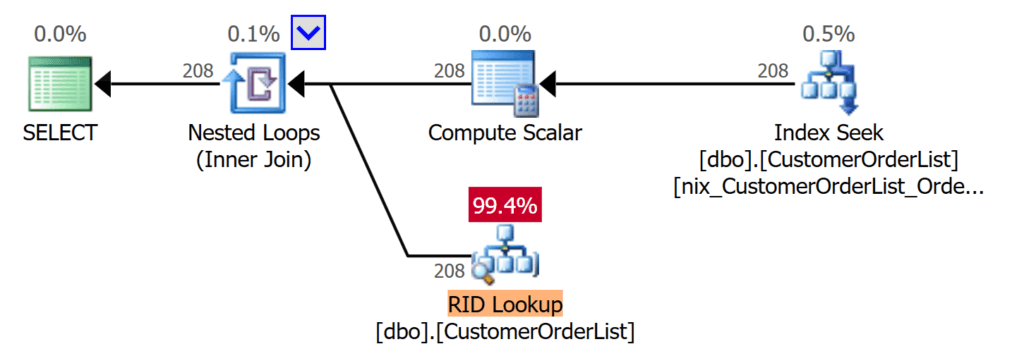
Рис.4: Уменьшается число операций ввода/вывода при использовании подходящего индекса
Теперь запрос уже не сканирует таблицу, и время выполнения также существенно уменьшилось, что видно на рисунке 5:
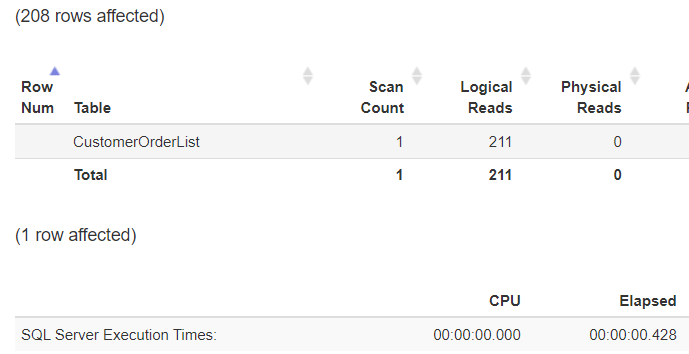
Рис.5: Нет избыточного использования ресурсов
- Запрос больше не распараллеливается, поскольку его стоимость упала ниже порога параллелизации.
- Затраты ЦП больше не могут быть измерены.
- Только блокировка SCH-S все еще используется, однако, имея в виду время выполнения, возможно, это можно проигнорировать,
Внутренние структуры
Некластеризованный индекс (НКИ) должен ВСЕГДА хранить ссылку на запись в таблице. Поскольку НКИ обычно содержит только несколько атрибутов таблицы, необходимо гарантировать, что атрибуты, которые не используются в НКИ, могут в любое время быть определены из таблицы. Эта ссылка хранится в куче как RID (RowLocatorID) и имеет размер 8 байт!
В примере выше запрос требует всего 211 операций ввода/вывода для извлечения данных. Если посмотреть план выполнения, можно увидеть использование ранее созданного индекса. Каждый индекс имеет структуру дерева со ссылками на следующий уровень. Это означает, что данные в индексе могут быть найдены быстро и эффективно. На рисунке 6 показана структура индекса.
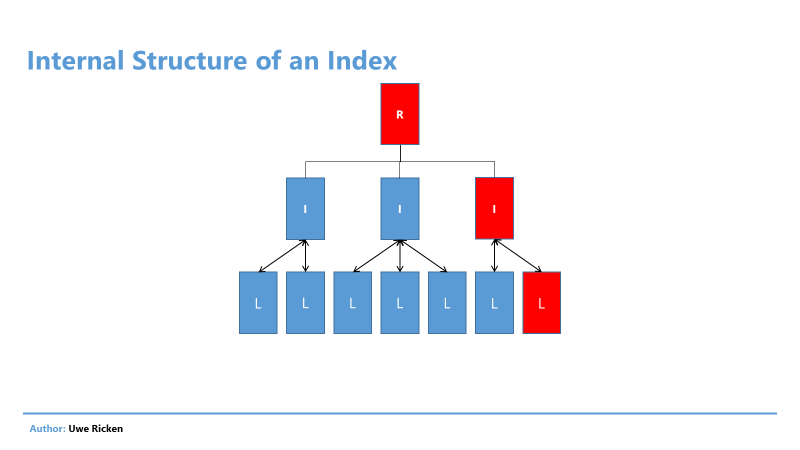
Рис.6: Поиск в структуре индекса B-Tree
Просмотр индекса показывает эту структуру. Для этого сначала должна быть определена страница данных, которая представляет корневой узел.
-- Получить информацию о корневом узле индекса
SELECT P.index_id,
SIAU.total_pages,
SIAU.used_pages,
SIAU.data_pages,
SIAU.root_page,
sys.fn_PhysLocFormatter(SIAU.root_page) AS root_page
FROM sys.system_internals_allocation_units AS SIAU
INNER JOIN sys.partitions AS P
ON (SIAU.container_id = P.partition_id)
WHERE P.object_id = OBJECT_ID(N'dbo.CustomerOrderList', N'U');
GO
Подробная информация о структуре индекса, показанная на рисунке 7, получена с помощью системного dmv (динамического представления). Помним, что индексы с или представляют сами таблицы! — это куча, а представляет кластеризованный индекс. Все остальные индексы некластеризованные.

Рис.7: Индексы
Корневой узел в индексе nix_CustomerOrderList_OrderDate находится в файле #1 на странице данных 73346. Содержимое страницы данных можно проверить с помощью недокументированной команды DBCC PAGE.
DBCC TRACEON (3604);
DBCC PAGE (0, 1, 73346, 3);
GO
Можно увидеть, что индекс использует только атрибуты, указанные при его создании. Все остальные атрибуты должны читаться из самой таблицы!

Рис.8: Поиск 2008-12-20 должен быть продолжен на странице 73348
Для поиска заказов за 20 декабря 2008 должен использоваться атрибут OrderDate, чтобы найти предельное значение, в котором размещается искомая дата. Поиск продолжается на следующем уровне на странице 73348, пока не будет достигнут самый нижний уровень.
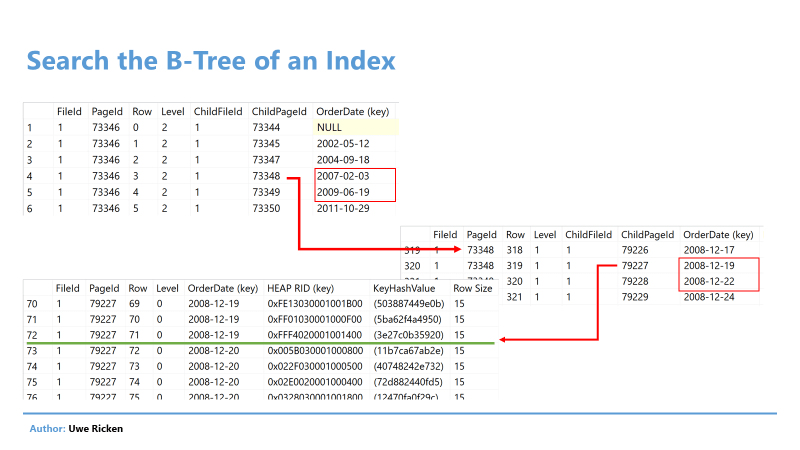
Рис.9: С помощью 3 операций ввода/вывода вы достигаете первой записи в индексе
Фактически требуется три операции ввода/вывода. Принимая во внимание общее число операций 211, становится ясно, что произойдет на следующем шаге. Поскольку индекс хранит только атрибут OrderDate, информация о других атрибутах записи данных отсутствует. Чтобы получить эту информацию, Microsoft SQL Server должен декодировать RID для получения страницы данных, где размещена запись.
RID хранится в индексе для каждой записи и имеет фиксированную длину 8 байтов. Эти 8 байтов содержат всю необходимую информацию для получения записи данных.

Рис.10: Положение набора данных как RID
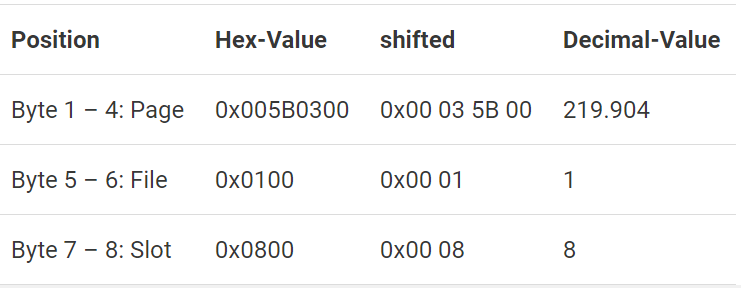
Запись, чья OrderDate представлена в индексе, находится в файле #1 на странице #219904 в слоте #8.
DBCC PAGE (0, 1, 219904, 3) WITH TABLERESULTS;
GO
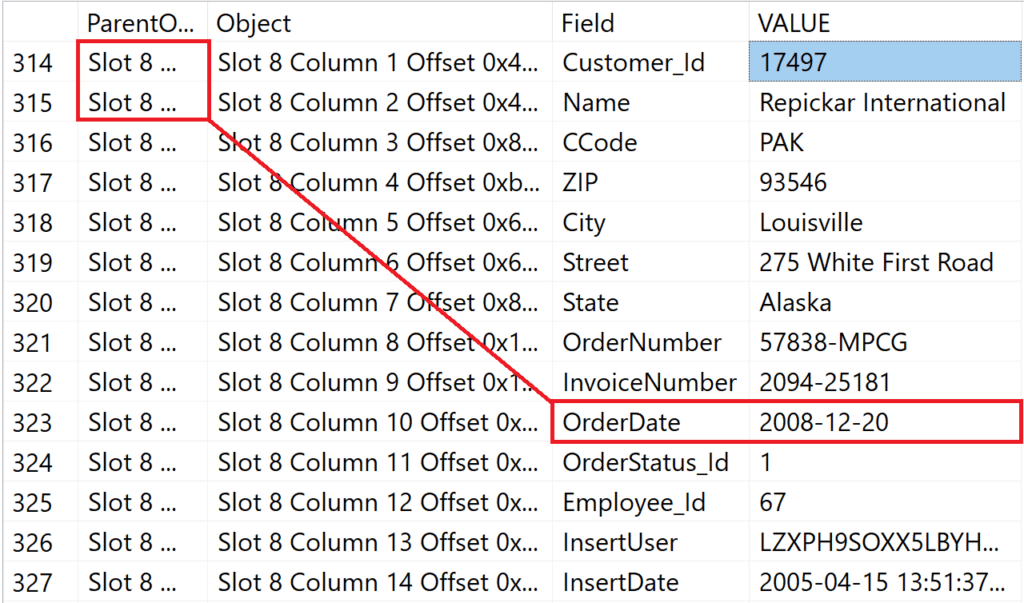
Рис.11: Содержимое слота #8
Процесс повторяется для каждой записи, найденной в индексе. Математика, стоящая за 211, довольно тривиальна: 3 операции ввода/вывода для поиска в индексе + 208*1 операций для ссылок на саму таблицу.
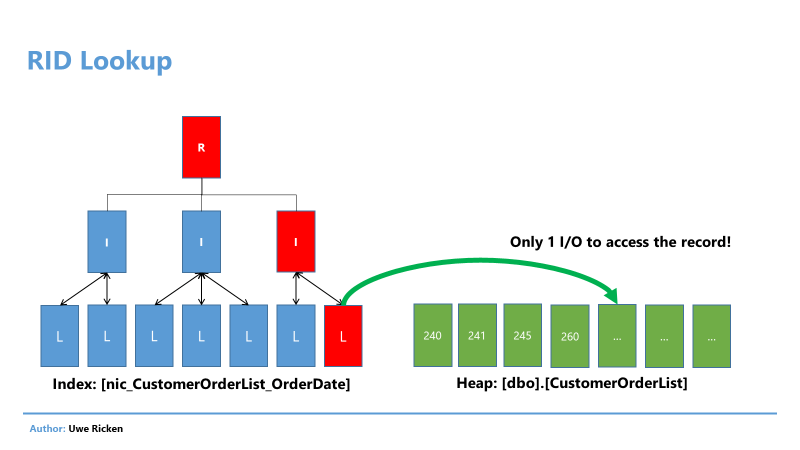
Рис.12: Доступ к куче по RID
Поиск RID против поиска ключа
В отличие от кучи, Microsoft SQL Server не может обратиться непосредственно к странице данных, на которой размещается запись, в таблице с кластеризованным индексом. При кластеризованном индексе Microsoft SQL Server сохраняет не положение записи данных в НКИ для таблицы со сгруппированным индексом, а значение ключа атрибута кластеризованного индекса.
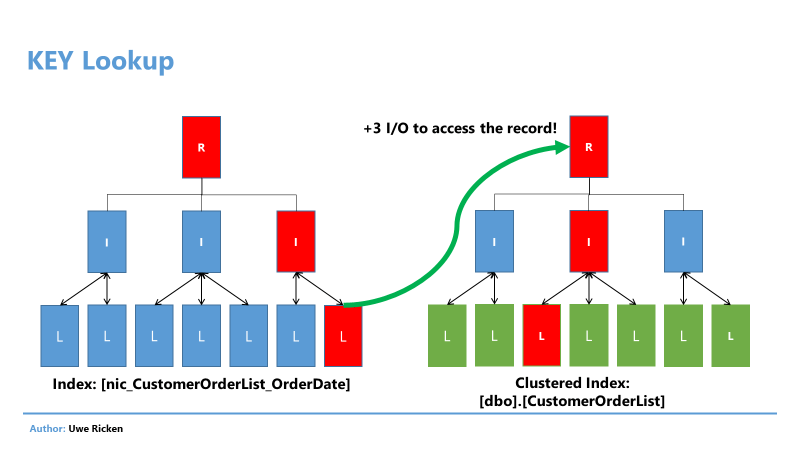
Рис.13: Дополнительные операции ввода/вывода при использовании кластеризованного индекса
Преимущество использования кластеризованного индекса заключается в обслуживании кластеризованных индексов, а не в производительности запросов (обсуждается в следующей статье). Сравнив один и тот же запрос для кучи и для кластеризованного индекса, можно обнаружить следующие различия в плане выполнения:
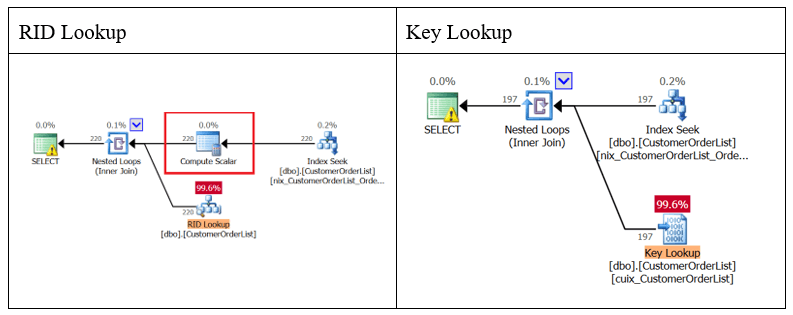
Рис.14: Сравнение планов с RID Lookup и Key Lookup
При поиске RID, потребуется преобразовывать RowLocatorID, что приведет (предположительно) к более высокой нагрузке на процессор. Одной из самых больших проблем в плане выполнения Microsoft SQL Server является оценка стоимости скалярных (SCALAR) операций. По умолчанию они оцениваются в 0%; однако тут забывается, что оператор должен выполняться для КАЖДОЙ записи, выходящей из предыдущего оператора.
Чтобы сделать обоснованное утверждение о стоимости преобразования, выполняется следующий код с SQLQueryStress Адама Мачаника и четырьмя потоками (число ЦП в тестовой машине):
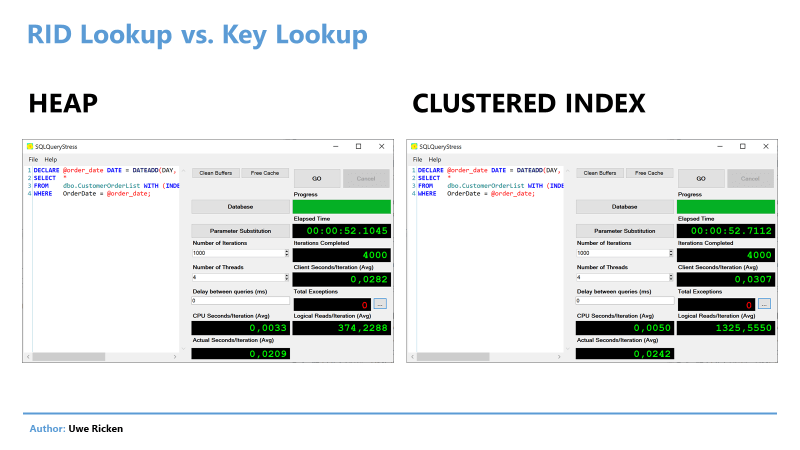
Рис.15: Сравнение производительности кучи и кластеризованного индекса
При непосредственном сравнении куча «побеждает» по всем позициям. Особенно интересно в этом сравнении тот факт, что нагрузка на процессор в 3,3 мс/итерация значительно ниже нагрузки для кластеризованного индекса (5мс).
Другое различие — не следует недооценивать — операции ввода/вывода на итерацию. Конечно, куча тут может набрать очки, поскольку требует одну операцию для доступа к таблице, в то время как кластеризованный индекс — 3 операции.
Выводы
- Markus Wienand. Nonsensical defaults: primary key as cluster key
- Thomas Kejser. Clustered Index Vs. Heap
Все, что необходимо знать про индексы MS SQL
Предлагаем расширить знания об индексах в MS SQL Server. Получите полное представление о них, преимуществах использования, структуре. Узнаете, как создавать индексы, оптимизировать и удалять. Все самое полезное читайте в одной статье.
Что такое индексы в sql server
Разберемся в понятии индексов (indexes) – это особые таблицы, используемые поисковыми системами для поиска данных. Их активное использование играет важнейшую роль в повышении производительности sql серверов.
Словно указатель в грамотно составленной книге, индекс помогает быстро получить доступ к строкам требуемых данных в таблице, соответствующих запросу. Таким образом, их использование позволяет ускорить выполнение требуемого запроса.
К примеру, для получения всех страниц в книге, касающихся выбранной тематики, сначала нужно обратиться к перечню тем, а затем выбрать нужные страницы. Для этого следует создать индекс по выбранной теме. На ее основе и будут выбираться ссылки на страницы книги по затронутой теме. Используя значения, заданные первичным ключом, sql server найдет нужный индекс и с его помощью быстро выберет все строки с необходимыми данными. Если не использовать индекс, то для поиска информации будет произведено сканирование каждой строки таблицы. Это значительно понизит производительность и увеличит время поиска.
Благодаря индексу процесс поиска данных сокращается за счет их упорядочивания как физического, так и логического. Таким образом, он выглядит как набор ссылок на данные, которые упорядочены по выбранному столбцу таблицы. Такой столбец называется индексированным. Индексы находятся в таблице и по сути выступают полезными внутренними механизмами системы sql-сервера, которые помогают сделать доступ к данным наиболее оптимальным.
Создать стандартный индекс можно на всех столбцах данных, кроме:
- столбцов, которые используются для хранения данных объектов, имеющих большие размеры, (LOB): TEXT, IMAGE, VARCHAR (MAX);
- представленных в XML. Для работы с данными, представлены в таком формате используются xml-index, которые отличаются от стандартных. О них рассказано ниже.
Об индексах и кучах
Как только таблица создана и в ней еще нет индексов, она выглядит как куча данных (Heap). В ней все записи хранятся хаотично, без определенного порядка. Потому их и называют «кучами».
Если в таблице необходимо найти определенные данные, sql server просканирует ее (Table scan). Пока в таблице не заданы индексы, поддерживающие ограничения (UNIQUE CONSTRAINT, UNIQUE INDEX или PRIMARY KEY), сервер прочитает все табличные записи (с первой до последней) и выберет те, которые удовлетворяют условиям поиска.
Это демонстрирует базовые функции indexes:
- повышение скорости поиска информации и производительности запросов;
- сохранение целостности данных через обеспечение уникальности строк таблицы.
Но не всегда индекс помогает ускорить поиск информации. Для таблиц небольших размеров обычный перебор данных может оказаться намного эффективнее выборки данных по индексам.
Indexes имеют и недостатки:
- требуется много места на дисковом пространстве и в оперативной памяти. Чем длиннее ключ, тем большего размера индекс и место для его хранения;
- замедляется производительность системы (медленнее выполняются операции вставок, обновления либо удаления записей).
Но современные методы их создания позволяют не только снижать негативный эффект для вышеперечисленных операций, но и увеличивать скорость выполнения.
Структура
Все индексы имеют одинаковую структуру (structure). Они состоят из:
- наборов страниц;
- узлов, имеющих древовидную структуру, иерархическую по природе.
Все они хранятся в виде сбалансированных B-деревьев (B-tree). Начало такого дерева расположено в корневом узле (находящимся на вершине иерархии) и по сути является «входной дверью». Этот узел имеет одну страницу, в которой содержатся указатели на ключи последующих уровней.
В нижней части иерархии расположены листья дерева (являющиеся конечными узлами). Длины веток одинаковы.
В таком дереве сбалансирована каждая ветка. Благодаря внутреннему механизму при любых изменениях в таблице дерево снова становится сбалансированным.
При формировании запроса к индексированному столбцу подсистема начинает процесс поиска с верхнего узла к нижним, проходя промежуточные и обрабатывая их. На каждом уровне располагается все более развернутая информация о запрашиваемых данных. Как только достигается нижний уровень листьев (leaf level) поиск прекращается, т.к. подсистема запросов находит необходимое значение.
Типы индексов
В Microsoft SQL Server используются следующие индексы: кластерные и некластерные. Рассмотрим их подробнее.
Кластерный индекс
Основная его задача — сохранение табличных данных в виде, отсортированном по значению ключа. Таблице или представлению может быть присущ лишь единственный кластеризованный индекс (Clustered index), потому что табличные данные могут отсортировываться в едином возможном порядке – либо возрастания, либо убывания. По возможности, у каждой таблицы должен быть Clustered index.
Табличные данные будут храниться отсортированными лишь в том случае, когда таблица имеет кластеризованный индекс. Строки табличных данных Clustered index хранит в уровнях листьев.
Если у таблицы нет Clustered index, в момент формирования ограничений PRIMARY KEY и UNIQUE, он формируется автоматически. Когда для таблиц/ куч созданы Nonclustered indexes, то в процессе создания Clustered index все некластеризованные должны быть перестроены.
Содержание листьев зависит от того, индекс кластерный или некластерный. Они могут содержать как табличные данные, так и ссылки, указывающие на строки с ними.
Некластерный индекс
Некластеризованными (Nonclustered) называют такие индексы, которые содержат:
- значения ключей – ключевые столбцы, по которым они определены;
- указатели на строки в таблице, содержащие реальные данные (значения ключа).
Чтобы обнаружить и получить запрашиваемые данные, для системы подзапросов потребуется совершение дополнительных операций. Содержимое указателей на запрашиваемые данные полностью зависит от того, как они хранятся.
Он может указывать на:
- кучу и тем самым приводить к идентификатору строки с искомыми данными;
- таблицу с Clustered index, указывая, что именно он используется что для поиска действительных данных.
Nonclustered indexes могут быть расширены дополнительными столбцами (included column). А значит, листья будут сохранять значения индексированных и дополнительных неиндексированных столбцов. Это свойство дает возможность обойти определенные ограничения, возложенные на индекс. Данный подход позволяет включать неиндексируемые столбцы либо обходить ограничения на длину индекса.
Главные свойства Nonclustered indexes:
- их нельзя отсортировать;
- на таблицу или представление можно сформировать свыше одного (до 999) некластеризованных индексов. Но не стоит создавать максимальное количество Nonclustered indexes. Нужно помнить, что они способны как повысить, так и понизить производительность.
Nonclustered indexes могут создаваться на любых таблицах, в том числе и имеющих кластерный индекс.
Специальные типы индексов
Существует большое число специальных индексов, которые могут быть как кластерными, так и некластерными. Рассмотрим некоторые из них.
Фильтруемый
Фильтруемым (Filtered) индексом называют оптимизированный Nonclustered index, в котором задействован предикат фильтра для индексации части строк в таблице.
Тщательно спроектированный Filtered index способен:
- увеличить производительность;
- уменьшить затраты на обслуживание и хранение индексов.
Составной
Составным называют индекс, который:
- может включать более одного (до 16) столбцов, выступающих ключевыми значениями;
- ограничивается общей длиной (не превышающей 900 байт);
- содержит поля, которые принадлежат единой таблице.
Простые индексы, в отличие от составных, создаются лишь по единственному столбцу.
Создание составных индексов целесообразно, когда:
- для поискового запроса ключами выступают два и более столбцов;
- в поисковом запросе используются все поля составного индекса. Поисковый запрос, в котором не задействованы все поля, вероятнее всего, использоваться не будет.
Отличным примером может служить телефонный справочник. Он сформирован по фамилии и имени, т.к. много людей имеют одинаковую фамилию. Следовательно, логично будет создать индекс одновременно и по фамилии, и по имени.
Отметим, что наивысший приоритет в процессе сортировки принадлежит первым колонкам, описываемым в CREATE INDEX. Потому, в числе первых должны указываться колонки уникальные. Чтобы индекс был задействован при выборке данных в таблице, сам запрос обязательно должен ссылаться именно на колонку, указанную первой.
Использование составных индексов поможет увеличить производительность за счет того, что для выполнения поиска данных сервер будет сканировать только его, что поможет снизить в таблице число индексов.
Query Optimizer использует их в зависимости от структуры запроса.
Уникальный
Уникальным (Unique) называют индекс, обеспечивающий уникальное значение всех строк по определенному ключу и гарантирующий, что в ключе индекса не будет значений одинаковых, повторяющихся. Для составного ключа понятие уникальности касается всех index columns, но не распространяется на каждый столбец в отдельности.
Если в таблице формируется Unique index одновременно по ряду столбцов, это означает, что абсолютно каждая вариация значений в ключе будет уникальной.
SQL сервером создается автоматически Unique index для ключевых столбцов при формировании ограничений UNIQUE либо PRIMARY KEY. Но он формируется лишь при выполнении условия отсутствия дублей в ключевых столбцах таблицы.
Уникальный индекс создается автоматом при определении ограничений столбца:
- первичным ключом (на один столбец либо сразу на несколько), при условии, что кластерный индекс ранее не создавался. В том случае, когда он все-таки уже создан, сервер создаст уникальный некластерный индекс по первичному ключу;
- ограничением на уникальность значений – сервером создается Unique Nonclustered index. Когда кластерный индекс не был сформирован заранее, есть возможность создания именно Unique Clustered index.
Колоночный
Колоночным (Columnstore) называют индекс, в котором данные хранятся в столбцах. Использование Columnstore indexes наиболее целесообразно применять для крупных хранилищ, т.к. они помогут:
- производительность запросов увеличить в несколько раз;
- размеры данных уменьшить (благодаря их сжатию).
Пространственный
Пространственным (Spatial) называют тип расширенного индекса, позволяющего индексировать столбцы с пространственными данными (представленные в типах Geography или Geometry). Spatial index позволяет наилучшим образом использовать определенные операции запросов относительно пространственных столбцов и может создаваться только для них.
Основное условие создания пространственного индекса – наличие PRIMARY KEY для таблиц.
Полнотекстовый
Полнотекстовые (Full-text) индексы применяются для повышения эффективности поиска определенных слов в строках, где данные представлены в символах.
Действия по созданию и обслуживанию Full-text indexes называются «заполнениями». Встречаются заполнения:
- полное – осуществляется SQL сервером после создания нового Full-text index. Размер таблицы влияет на затребованный объем ресурсов. При увеличении размера на операцию требуются ресурсы большего размера. Потому предусмотрена возможность откладывания этого процесса;
- основанное на отслеживании изменений – применяется для того, чтобы обслуживать Full-text index после полного заполнения (первоначального).
Покрывающий
Покрывающим (Covering) называют индекс, позволяющий на конкретный запрос получать запрашиваемую информацию в полном объеме с листьев индекса, не обращаясь к записям таблицы. А значит, в Covering index хранится достаточный объем данных для полноценного ответа на запрос. Потому нет необходимости обращаться к таблице.
Благодаря тому, что ответ можно получить без использования таблицы, покрывающие индексы быстрее остальных. Однако, они становятся достаточно большими, потому злоупотреблять ими не стоит.
XML-индекс
XML – специфический тип индекса, предназначенный для работы с данными в столбцах таблицы, представленными в соответствующем формате. Он делает более эффективной обработку поисковых запросов к ним.
- первичные – индексируют, хранят в столбцах XML теги, пути, значения. Целесообразно создавать, когда таблица по первичному ключу имеет кластерный индекс;
- вторичные – создаются лишь для таблиц с первичным XML-index. Применяются для увеличения производительности системы по определенному типу обращения к XML-столбцам. Встречаются типы XML-indexes: PATH, VALUE, PROPERTY.
Индексы, используемые в оптимизированных таблицах
Активно используются специальные индексы для таблиц данных:
- оптимизированные для памяти (In-Memory OLTP). К таковым относятся Хэш индексы (Hash);
- Nonclustered indexes, которые специально создаются для сканирования (как упорядоченного, так и диапазонного) и оптимизируются для памяти.
Создание и проектирование индексов в ms sql server
Польза индексов очевидна, потому и проектироваться они должны крайне аккуратно. Созданные тщательным образом способны улучшить производительность, а непрофессионально – понизить.
Индексы занимают достаточно много дискового места, потому не имеет смысла создавать их больше, чем нужно. Более того, при каждом обновлении строк, автоматически обновляются и индексы. Это в свою очередь может потребовать увеличения ресурсов и грозить снижением производительности.
Очень важно при проектировании соблюдать ряд требований как к базам данных, так и к запросам направленным к ним.
Базы данных
Как сказано выше, производительность системы напрямую зависит от индексов. При поступлении запроса они могут увеличивать ее, обеспечивая быстрый поиск данных либо снижать, т.к. при каждой операции с данными будут изменяться и они, дабы отражать действия, производимые над данными. И не важно, что происходит с ними – добавление, удаление или обновление.
Потому, при разработке плана стратегии по индексированию, необходимо придерживаться советов специалистов:
- Если предполагается частое обновление данных в таблице, то для нее нужно применять минимум индексов.
- Для таблицы со значительным количеством данных, которые предположительно будут редко изменяться, можно использовать то число индексов, которое улучшит производительность запросов. Но для таблиц небольшого объема не всегда целесообразно вообще их использовать. Такой поиск может выполняться дольше, чем обычное сканирование таблицы.
- Для Clustered indexes используйте самые короткие поля, которые только допустимы. Лучше всего их применять на столбцах с уникальными значениями и в которых не допускается использование NULL. По этой причине чаще всего PRIMARY KEY выступает в роли Clustered index.
- Производительность индекса напрямую зависит от того, насколько уникальны значения в столбце. Она снижается с увеличением дублей если в столбце и растет с уменьшением. Потому, при каждой возможности следует использовать уникальный индекс.
- Если используется составной индекс, то в нем нужно учитывать порядок столбцов. Первыми идут те, в которых в выражениях используется WHERE. За ними – столбцы с наивысшими показателями уникальных значений. Остальные выстраиваются по мере понижения этого показателя.
- Допускается использование индекса на вычисляемых столбцах таблицы, но лишь при условии соблюдения определенных требований (для вычисления значений такого столбца могут использоваться только детерминистические выражения, т.е. результат для определенного набора входящих параметров всегда должен быть одинаковым).
Запросы к базе данных
При проектировании вторым важным пунктом является понимание и учет того, какие выполняются запросы к базе данных. Необходимо учитывать частоту изменения данных, а также требуется соблюдение определенных принципов:
- Предпочтительнее, чтобы один запрос содержал наибольшее число строк, нежели разбивать их на соответствующее число отдельных запросов.
- На столбцах, используемых в запросах с WHERE чаще всего, предпочтительнее создавать Nonclustered index в качестве условия поиска и соединения в JOIN.
- Следует воспользоваться возможностями индексирования столбцов, используемых в поисковых запросах на соответствие конкретным значениям.
Способы создания индексов
Предусмотрено создание индексов ms sql server с помощью двух инструментов. В этом помогут:
- SSMS (MSSQL Management Studio);
- специальный язык Transact-SQL (T-SQL, поддерживающий Paging Queries).
Как создать кластеризованный индекс
Как отмечалось выше, создание кластеризованного индекса sql сервером происходит автоматически, когда определенный столбец выбирается в качестве первичного ключа (PRIMARY KEY). Когда такого не происходит, следует создать кластерный индекс своими руками.
Чтобы создать Clustered index воспользуемся Management Studio. Для этого следует:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать соответствующую таблицу.
- Остановившись на пункте «Индексы» кликнуть мышкой.
- Выбрать «Создать индекс» и соответствующий тип (выбираем «Кластеризованный»).
- В новом окне появится форма «Новый индекс». Здесь потребуется вписать наименование нового создаваемого индекса (в рамках одной таблицы требуется, чтобы оно было уникальным). Поставить галочку, что он уникальный.
- Выбрать столбец, который будет являться ключом индекса. Он ляжет в основу создаваемого Clustered index. Провести сортировку строк табличных данных кнопкой «Добавить».
- После ввода всех необходимых параметров кликнуть «ОК».
Результатом действий станет кластерный индекс.
Он может быть создан и с помощью инструкций Transact-SQL CREATRE INDEX.
Как создать некластеризованный индекс
Для создания Nonclustered index можно воспользоваться Management Studio либо инструкциями T-SQL.
Создание Nonclustered index с включенными столбцами
Коснемся вопроса, как создать Nonclustered index с условием, что в индекс включены столбцы, которые не являются ключевыми. Такой индекс принято использовать в тех случаях, когда индекс создается под конкретный запрос. К примеру, чтобы индексом покрывался запрос полностью, т.е. включал все столбцы. Вследствие того, что запрос покрыт, увеличивается производительность. Это становится возможным благодаря тому, что оптимизатор запросов может получить все значения столбцов в индексе без обращения к табличным данным. Это ведет к уменьшению числа операций ввода-вывода на диске.
Однако стоит учитывать, что с включением в индекс неключевых столбцов размер его увеличивается. А значит, для его хранения понадобится больше дискового пространства. Это также может снизить производительность операций INSERT, UPDATE, DELETE и MERGE в базовой таблице данных.
Для его создания также воспользуемся Management Studio:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать требуемую таблицу и щелкнуть мышкой по пункту «Индексы».
- Выбрать «Создать индекс», а затем «Некластеризованный» (не ставить галочку на уникальности).
- В открывшейся форме «Новый индекс» вписать наименование нового индекса, добавить один или несколько ключевых столбцов, воспользовавшись кнопкой «Добавить».
- Перейти во вкладку «Включено столбцы». Добавить все столбцы, которые должны быть включены в индекс, воспользовавшись кнопкой «Добавить».
- Когда введены все нужные параметры кликнуть «ОК».
При необходимости, можно легко создать фильтруемый Nonclustered index. Для этого следует воспользоваться T-SQL и в операторе CREATE NONCLUSTERED INDEX в WHERE указать условие фильтрации. Так можно отфильтровать практически любые данные, не важные в запросах.
Удаление индекса
Пришло время узнать о том, какими способами могут удаляться индексы. Для начала воспользуемся Management Studio. Для этого необходимо:
- Открыть SSMS.
- Выбрать индекс, подлежащий удалению.
- Щелкнуть мышкой по нему и из списка выбрать «Удалить».
- Выполненное действие подтвердить нажатием «ОК».
Удаление индексов выполняется и с помощью инструкций T-SQL DROP INDEX (DROP INDEX IX_NonClustered ON TestTable). Однако ею нельзя воспользоваться для удаления тех индексов, которые создавались через формирование ограничений PRIMARY KEY и UNIQUE. Чтобы удалить их, следует воспользоваться инструкцией ALTER TABLE с предложением DROP CONSTRAINT.
Как выполнить изменение значений коэффициента, который установлен по умолчанию
Чтобы внести изменения в значения коэффициента, которые установлены по умолчанию, следует воспользоваться:
- SSMS;
- инструкцией T-SQL, выполнив запуск системной сохраненной процедуры;
- sp configure.
Особенности индексов и условий предложения WHERE
Если предложение WHERE инструкции SELECT содержит условие поиска данных с одним столбцом, то необходимо для него создать индекс. Это условие очень важно при высокой селективности (selectivity) условия.
Но он будет абсолютно бесполезным при постоянном уровне селективности от 80% и выше. Простое сканирование табличных данных потребует меньше времени.
Если в часто применяемом запросе условие поиска включает оператор AND, то лучше всего – создать составной индекс, включив в него сразу все табличные столбцы, которые указывались в предложении WHERE инструкции SELECT.
Оптимизация индексов
После выполнения любых действий с табличными данными sql сервером в тот же момент производятся соответствующие правки в индексах. Спустя некоторое время все подобные исправления могут спровоцировать фрагментацию данных. В результате, их может разбросать по всей базе.
Подобная фрагментация данных может стать причиной понижения производительности. Потому крайне важно время от времени проводить дефрагментацию. К подобным операциям по обслуживанию индексов относят реорганизацию и перестроение индексов.
Чтобы понять, какую именно операцию требуется провести – реорганизацию или перестроение, следует выяснить степень фрагментации данных. Она поможет понять, какой способ дефрагментации будет наиболее эффективным и что выбрать.
Чтобы выяснить уровень фрагментации следует воспользоваться системной табличной функцией sys.dm_db_index_physical_stats. Для определения уровня фрагментации всего перечня таблиц для выбранной базы, можете воспользоваться следующим запросом:
SELECT OBJECT_NAME(T1.object_id) AS NameTable,
T1.index_id AS IndexId,
T2.name AS IndexName,
T1.avg_fragmentation_in_percent AS Fragmentation
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS T1
LEFT JOIN sys.indexes AS T2 ON T1.object_id = T2.object_id AND T1.index_id = T2.index_id
Согласно рекомендациям Microsoft, последующие действия будут зависеть от уровня фрагментации:
- меньше 5% – о дефрагментации следует пока забыть;
- от 5 до 30% – требуется выполнить реорганизацию индекса. Это потребует минимального количества ресурсов системы и ее можно провести без долговременной блокировки;
- свыше 30% – следует выполнить перестроение индекса. При значительном уровне фрагментации это наиболее эффективно.
Реорганизация индекса
Реорганизацией называют процесс устранения фрагментации индекса. В его ходе происходит дефрагментация конечного уровня кластерных и некластерных индексов по таблицам и представлениям. Говоря простым языком – выполняется простое переупорядочивание страниц. В основе переупорядочивания лежит логический порядок конечных узлов (выполняете слева направо).
Если хотите провести реорганизацию – воспользуйтесь:
- MSSQL Management Studio. На выбранном индексе следует щелкнуть мышкой, из списка выбрать и нажать «Реорганизовать»;
- соответствующими инструкциями T-SQL.
Перестроение индекса
Перестроением называется операция по устранению фрагментации индекса. Он заключается в устранении старого и формировании нового.
Перестроение индекс выполняется несколькими способами. В этом поможет:
- Management Studio. Для этого необходимо выбрать нужный индекс, мышкой кликнуть по нему и выбрать «Перестроить»;
- инструкция ALTER INDEX ix с предложением REBUILD, которая по сути является заменой инструкции DBCC DBREINDEX. Ею пользуются, когда возникла потребность в масштабной операции;
- инструкция CREATE NONCLUSTERED INDEX (CREATE INDEX) с предложением DROP_EXISTING. Подходит, чтобы перестроить индекс и изменить его определения (удалить либо добавить ключевые столбцы).
Это вся полезная информация по индексам в Microsoft SQL Server. Изучайте их, а если возникнут вопросы – задавайте. Удачи в изучении и применении indexes ms sql.
Создание некластеризованных индексов
Некластеризованные индексы можно создавать в SQL Server с помощью SQL Server Management Studio или Transact-SQL. Некластеризованный индекс — это структура индекса, отделенная от данных, хранящихся в таблице, и переупорядочивающая один или несколько выделенных столбцов. Некластеризованные индексы часто помогают быстрее находить данные, чем поиск в базовой таблице; Иногда запросы могут быть полностью отвечать данными в некластеризованном индексе, или некластеризованный индекс может указывать ядро СУБД на строки в базовой таблице. Обычно некластеризованные индексы создаются с целью повышения производительности часто используемых запросов, не входящих в кластеризованный индекс, либо для поиска строк таблицы, не имеющей кластеризованного индекса (которая называется кучей). Можно создать несколько некластеризованных индексов для таблицы или индексированного представления.
Подготовка к работе
Типичные реализации
Некластеризованные индексы реализуются следующим образом.
- Ограничения UNIQUE При создании ограничения UNIQUE создается уникальный некластеризованный индекс. Он нужен, чтобы принудительно применять ограничение UNIQUE по умолчанию. Если кластеризованный индекс в таблице еще не создан, то можно указать уникальный кластеризованный индекс. Дополнительные сведения см. в статье Ограничения уникальности и проверочные ограничения.
- Индекс, не зависящий от ограничения По умолчанию некластеризованный индекс создается в том случае, если ранее не был задан кластеризованный индекс. Для таблицы может быть создано не более 999 некластеризованных индексов. В это число входят любые индексы, созданные ограничениями PRIMARY KEY или UNIQUE, но не входят XML-индексы.
- Некластеризованный индекс в индексированном представлении Некластеризованные индексы в представлении могут создаваться только после создания в нем уникального кластеризованного индекса. Дополнительные сведения см. в разделе «Создание индексированных представлений».
Безопасность
Разрешения
Необходимо разрешение ALTER для таблицы или представления. Пользователь должен быть членом предопределенной роли сервера sysadmin или предопределенных ролей базы данных db_ddladmin и db_owner.
Использование среды SQL Server Management Studio
Создание некластеризованного индекса с помощью конструктора таблиц
- В обозревателе объектов разверните базу данных, содержащую таблицу, в которой необходимо создать некластеризованный индекс.
- Разверните папку Таблицы.
- Щелкните правой кнопкой мыши таблицу, в которой нужно создать некластеризованный индекс, и выберите пункт Конструктор.
- Щелкните правой кнопкой мыши столбец, для которого нужно создать некластеризованный индекс, и выберите Индексы/Ключи.
- В диалоговом окне Индексы и ключи нажмите Добавить.
- Выберите новый индекс в текстовом поле Выбранный первичный/уникальный ключ или индекс .
- Выберите в сетке элемент Создать как кластеризованныйи в раскрывающемся списке справа от свойства выберите значение Нет .
- Выберите Закрыть.
- В меню Файл выберите пункт Сохранитьимя_таблицы.
Создание некластеризованного индекса в обозревателе объектов
- В обозревателе объектов разверните базу данных, содержащую таблицу, в которой необходимо создать некластеризованный индекс.
- Разверните папку Таблицы.
- Разверните таблицу, для которой необходимо создать некластеризованный индекс.
- Щелкните правой кнопкой мыши папку Индексы, выберите Создать индекс и Некластеризованный индекс.
- В диалоговом окне Создание индекса на странице Общие введите имя нового индекса в поле Имя индекса .
- В разделе Ключевые столбцы индекса щелкните Добавить….
- В диалоговом окне Выбор столбцов изимя_таблицы установите флажки для столбцов таблицы, добавляемых к некластеризованному индексу.
- Нажмите ОК.
- В диалоговом окне «Создать индекс» нажмите кнопку «ОК«.
Использование Transact-SQL
Создание некластеризованного индекса в таблице с помощью Transact-SQL
- В обозреватель объектов подключитесь к экземпляру ядро СУБД с AdventureWorks2022 установленным. Вы можете скачать AdventureWorks2022 из примеров баз данных.
- На стандартной панели выберите пункт Создать запрос.
- Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить.
USE AdventureWorks2022; GO -- Find an existing index named IX_ProductVendor_VendorID and delete it if found. IF EXISTS (SELECT name FROM sys.indexes WHERE name = N'IX_ProductVendor_VendorID') DROP INDEX IX_ProductVendor_VendorID ON Purchasing.ProductVendor; GO -- Create a nonclustered index called IX_ProductVendor_VendorID -- on the Purchasing.ProductVendor table using the BusinessEntityID column. CREATE NONCLUSTERED INDEX IX_ProductVendor_VendorID ON Purchasing.ProductVendor (BusinessEntityID); GO Следующие шаги
- Инструкция CREATE INDEX (Transact-SQL)
- Руководство по проектированию индексов SQL Server
Кластеризованные и некластеризованные индексы
Индекс является структурой на диске, которая связана с таблицей или представлением и ускоряет получение строк из таблицы или представления. Индекс содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Эти ключи хранятся в виде структуры сбалансированного дерева, которая поддерживает быстрый поиск строк по их ключевым значениям в SQL Server.
В документации по SQL Server термин «сбалансированное дерево» обычно используется в отношении индексов. В индексах rowstore SQL Server реализует B+-дерево. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в руководстве по архитектуре и проектированию индексов SQL Sql Server и Azure.
Таблица или представление может иметь индексы следующих типов.
- кластеризация.
- Кластеризованные индексы сортируют и хранят строки данных в таблицах или представлениях на основе их ключевых значений. Эти ключевые значения — это столбцы, включенные в определение индекса. Существует только один кластеризованный индекс для каждой таблицы, так как строки данных могут храниться в единственном порядке.
- Строки данных в таблице хранятся в порядке сортировки только в том случае, если таблица содержит кластеризованный индекс. Если у таблицы есть кластеризованный индекс, то таблица называется кластеризованной. Если у таблицы нет кластеризованного индекса, то строки данных хранятся в неупорядоченной структуре, которая называется кучей.
- Некластеризованные индексы имеют структуру, отдельную от строк данных. В некластеризованном индексе содержатся значения ключа некластеризованного индекса, и каждая запись значения ключа содержит указатель на строку данных, содержащую значение ключа.
- Указатель из строки индекса в некластеризованном индексе, который указывает на строку данных, называется указателем строки. Структура указателя строки зависит от того, хранятся ли страницы данных в куче или в кластеризованной таблице. Для кучи указатель строки является указателем на строку. Для кластеризованной таблицы указатель строки данных является ключом кластеризованного индекса.
- Вы можете добавить неключевые столбцы на конечный уровень некластеризованного индекса, чтобы обойти существующее ограничение на ключи индексов и выполнять полностью индексированные запросы. Дополнительные сведения см. в статье Создание индексов с включенными столбцами. Дополнительные сведения об ограничениях ключа индекса см. в разделе «Максимальная емкость» для SQL Server.
Как кластеризованные, так и некластеризованные индексы могут быть уникальными. При использовании уникального индекса две строки не могут иметь одинаковое значение для ключа индекса. В противном случае индекс не является уникальным, и несколько строк могут совместно использовать одно и то же значение ключа. Дополнительные сведения см. в статье Создание уникальных индексов.
Обслуживание индексов таблиц и представлений происходит автоматически при любом изменении данных в таблице.
Дополнительные типы индексов специальных назначений см. в индексах индексов специальных назначений.
Индексы и ограничения
SQL Server автоматически создает индексы при определении ограничений PRIMARY KEY и UNIQUE в столбцах таблицы. Например, при создании таблицы с ограничением UNIQUE ядро СУБД автоматически создает некластеризованный индекс. Если вы настроите первичный ключ, ядро СУБД автоматически создает кластеризованный индекс, если кластеризованный индекс еще не существует. Если вы пытаетесь применить ограничение PRIMARY KEY в существующей таблице, для которой уже создан кластеризованный индекс, SQL Server применяет первичный ключ с помощью некластеризованного индекса.
Использование индексов оптимизатором запросов
Хорошо разработанные индексы могут снизить операции ввода-вывода на диске и использовать меньше системных ресурсов. Таким образом, эти индексы повышают производительность запросов. Индексы могут быть полезны для различных запросов, содержащих инструкции SELECT, UPDATE, DELETE или MERGE. Рассмотрим запрос SELECT JobTitle, HireDate FROM HumanResources.Employee WHERE BusinessEntityID = 250 в базе данных AdventureWorks2022 . При выполнении этого запроса оптимизатор запросов оценивает все доступные методы получения данных и выбирает наиболее эффективный метод. Этим методом может являться просмотр таблицы или просмотр одного или более индексов, если они существуют.
Во время сканирования таблицы оптимизатор запросов считывает все строки в таблице и извлекает строки, соответствующие критериям запроса. Просмотр таблицы формирует много дисковых операций ввода-вывода и может быть ресурсоемкой операцией. Но если результирующий набор запроса содержит высокий процент строк таблицы, то просмотр таблицы может оказаться самым эффективным методом.
Когда оптимизатор запросов использует индекс, он выполняет поиск по ключевым столбцам индекса, находит место хранения запрашиваемых строк и извлекает оттуда совпадающие строки. Как правило, поиск индекса гораздо быстрее, чем поиск в таблице. В отличие от таблицы, индекс часто содержит очень мало столбцов для каждой строки, а строки отсортированы по порядку.
Оптимизатор запросов обычно выбирает наиболее эффективный метод при выполнении запросов. Но если отсутствуют доступные индексы, оптимизатор запросов должен использовать просмотр таблицы. Ваша задача — спроектировать и создать индексы, которые лучше всего подходят для конкретной среды, чтобы оптимизатор запросов мог выбирать из нескольких эффективных индексов. SQL Server предоставляет помощник по настройке ядра СУБД для анализа среды базы данных и выбора соответствующих индексов.
Дополнительные сведения о рекомендациях по проектированию индексов и внутренних компонентах см . в руководстве по архитектуре индекса SQL Server и Azure SQL.
Следующие шаги
- Руководство по архитектуре и разработке индексов SQL Server и Azure SQ
- Создание кластеризованных индексов
- Создание некластеризованных индексов