Как подсчитать количество строк в Pandas DataFrame
Есть три метода, которые вы можете использовать для быстрого подсчета количества строк в кадре данных pandas:
#count number of rows in index column of data frame len(df.index ) #find length of data frame len(df) #find number of rows in data frame df.shape [0] Каждый метод вернет один и тот же ответ.
Для небольших наборов данных разница в скорости между этими тремя методами незначительна.
Для чрезвычайно больших наборов данных рекомендуется использовать len(df.index) , так как было показано, что это самый быстрый метод.
В следующем примере показано, как использовать каждый из этих методов на практике.
Пример: подсчет количества строк в Pandas DataFrame
В следующем коде показано, как использовать три метода, упомянутых ранее, для подсчета количества строк в кадре данных pandas:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df y x1 x2 x3 0 8 5 11 2 1 12 7 8 2 2 15 7 10 3 3 14 9 6 2 4 19 12 6 5 5 23 9 5 5 6 25 9 9 7 7 29 4 12 9 8 31 5 8 11 9 30 4 8 7 10 31 7 9 7 11 31 7 9 8 #count number of rows in index column of data frame len(df.index ) 12 #find length of data frame len(df) 12 #find number of rows in data frame df.shape [0] 12 Обратите внимание, что каждый метод возвращает один и тот же результат. DataFrame имеет 12 строк.
Как узнать количество строк в таблице python
Чтобы подсчитать количество строк в DataFrame, вы можете использовать свойство dataframe.shape или dataframe.count() .
Dataframe.shape возвращает кортеж, содержащий количество строк в качестве первого элемента и количества столбцов в качестве второго элемента. Индексируя первый элемент, мы можем получить количество строк в DataFrame:
import pandas as pd # initialize dataframe df = pd.DataFrame('a': [1, 4, 7, 2], 'b': [2, 0, 8, 7]>) # number of rows in dataframe num_rows = df.shape[0] print('Number of Rows in DataFrame :',num_rows) # => Number of Rows in DataFrame : 4 Dataframe.count() , с значениями параметров по умолчанию возвращает количество значений вдоль каждого столбца. А в DataFrame каждый столбец содержит одинаковое количество значений, равных количеству строк. Индексируя первый элемент, мы можем получить количество строк в DataFrame:
import pandas as pd # initialize dataframe df = pd.DataFrame('a': [1, 4, 7, 2], 'b': [2, 0, 8, 7]>) # number of rows in dataframe num_rows = df.count()[0] print('Number of Rows in DataFrame :',num_rows) # => Number of Rows in DataFrame : 4 Как задать максимальное количество выводимых строк датафрейма



Скачай курс
в приложении
Перейти в приложение
Открыть мобильную версию сайта
© 2013 — 2023. Stepik
Наши условия использования и конфиденциальности
![]()
Public user contributions licensed under cc-wiki license with attribution required
Формат таблиц в pandas
Если вы пока ещё не знаете как транслировать данные напрямую заказчику в подсознание или, на худой конец, текст сообщения в slack, вам пригодится информация о том, как сделать процесс интерпретации таблиц более быстрым и комфортным.
Например, в excel для этого используется условное форматирование и спарклайны. А в этой статье мы посмотрим как визуализировать данные с помощью Python и библиотеки pandas : будем использовать свойства DataFrame.style и Options and settings .
Настраиваем базовую визуализацию
Импортируем библиотеки: pandas для работы с данными и seaborn для загрузки классического набора данных penguins :
import pandas as pd import seaborn as snsС помощью pd.set_option настроим вывод так чтобы:
- количество строк в таблице было не больше 5;
- текст в ячейке отражался полностью вне зависимости от длины (это удобно, если в ячейке длинный заголовок или URL, которые хочется посмотреть);
- все числа отражались с двумя знаками после запятой;
pd.set_option('max_rows', 5) pd.set_option('display.max_colwidth', None) pd.set_option('display.float_format', ''.format)Прочитаем и посмотрим датафрейм.
penguins = sns.load_dataset(‘penguins’) penguins
Если нужно вернуть настройки к дефолтным, используем pd.reset_option . Например, так, если хотим обновить все настройки разом:
pd.reset_option('all')Полный список свойств set_option .
Настраиваем отображение данных в таблицах
Формат чисел, пропуски и регистр
У датафреймов в pandas есть свойство DataFrame.style , которое меняет отображение содержимого ячеек по условию для строк или столбцов.
Например, мы можем задать количество знаков после запятой, значение для отображения пропусков и регистр для строковых столбцов.
(penguins .head(5) .style .format('', na_rep='-') .format() )
У нас тут всё про пингвинов, но в данные о ценах, можно добавить знак ₽ перед числом таким образом:
(df .style .format('>) )Выделение цветом (минимум, максимум, пропуски)
Функции для поиска минимального и максимального значений не работают с текстовыми полями, поэтому заранее выделим столбцы, для которых они будут применяться, в отдельный список. Этот список будем передавать в параметр subset .
numeric_columns = ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']Подсветим минимум, максимум и пустые ячейки и выведем первые 5 строк датафрейма.
(penguins .head(5) .style .format('', na_rep='-') .format() .highlight_null(null_color='lightgrey') .highlight_max(color='yellowgreen', subset=numeric_columns) .highlight_min(color='coral', subset=numeric_columns) )
Наглядно видно, что в этих 5ти строках самый длинный клюв у пингвина в строке с индексом 2 и у него (неё!) же самые длинные плавники и самый маленький вес.
Усложним ещё немного: посмотрим на разброс длины плавников пингвинов-девочек вида Adelie.
Bar chart в таблице
Для начала, выделим в отдельный датафрейм пингвинов женского пола и вида Adelie и посчитаем для них разброс длин плавников.
adelie_female = (penguins[(penguins['species'] == 'Adelie') & (penguins['sex'] == 'FEMALE')] .copy() ) adelie_female['flipper_l_var'] = ((adelie_female['flipper_length_mm']- adelie_female['flipper_length_mm'].mean()).round())К форматированию числовых значений, пропусков и регистра добавляем формат для столбца ‘flipper_l_var’ . Задаём:
- группу столбцов ( subset ), для которых будем строить график;
- выравнивание ( align ): mid — так как мы ожидаем, что значения будут как положительные, так и отрицательные. Подробнее про другие параметры выравнивания можно посмотреть тут;
- цвет ( color ). В нашем случае 2 цвета: для отрицательных и положительных значений;
- границы ( vmin , vmax ).
Отдельно с помощью set_properties пропишем, что значения в столбце ‘flipper_l_var’ должны стоять в центре ячейки.
(adelie_female .head(5) .style .format('', na_rep='-') .format() .bar(subset=['flipper_l_var'], align='mid', color=['coral', 'yellowgreen'], vmin=adelie_female['flipper_l_var'].min(), vmax=adelie_female['flipper_l_var'].max() ) .set_properties(**, subset='flipper_l_var') )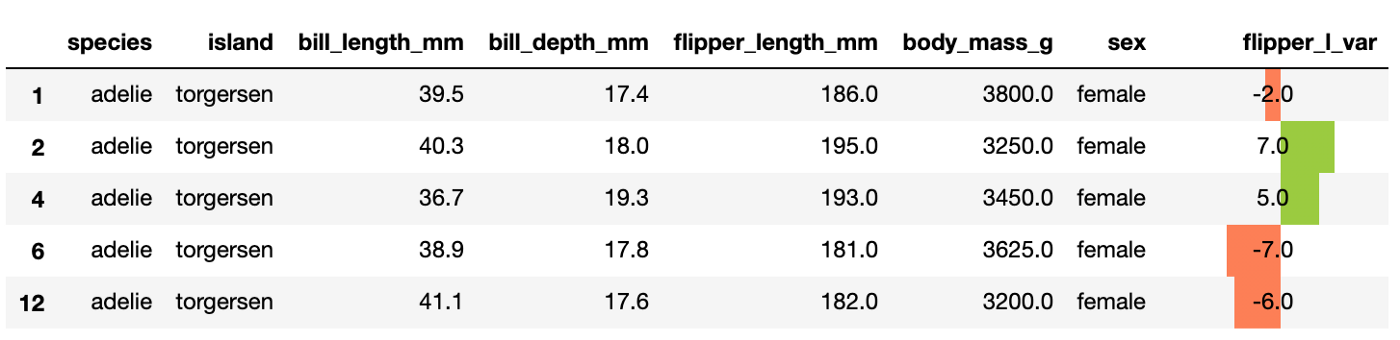
Heatmap в таблице
Иногда очень удобно подсветить все значения в таблице с помощью градиента. Например, когда нужно сравнить сгруппированные данные.
Посчитаем количество пингвинов разных видов и средние значения массы, длин плавников и клюва в зависимости от вида.
species_stat=(penguins .groupby('species') .agg(penguins_count=('species','count'), mean_bill_length=('bill_length_mm', 'mean'), mean_bill_depth=('bill_depth_mm', 'mean'), mean_flipper_length=('flipper_length_mm', 'mean'), mean_body_mass=('body_mass_g', 'mean'), ) )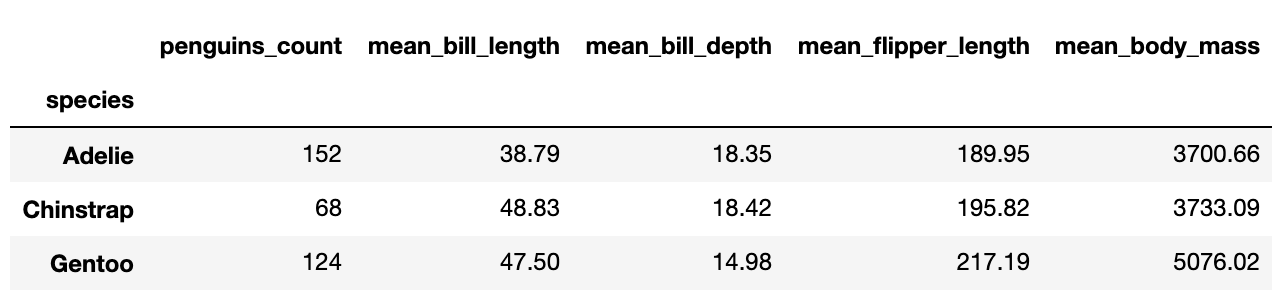
О трех видах пингвинов можно сделать выводы и по этой таблице, но если значений становится чуть больше, хочется сразу заняться чем-то более полезным, чем разглядывать ряды чисел.
Исправим это. Потому что, ну что может быть полезнее и веселее разглядывания чисел?! И если вы думаете по-другому, я не знаю, зачем вы дочитали до этого момента.
(species_stat .T .style .format("") .background_gradient(cmap='Blues', axis=1) )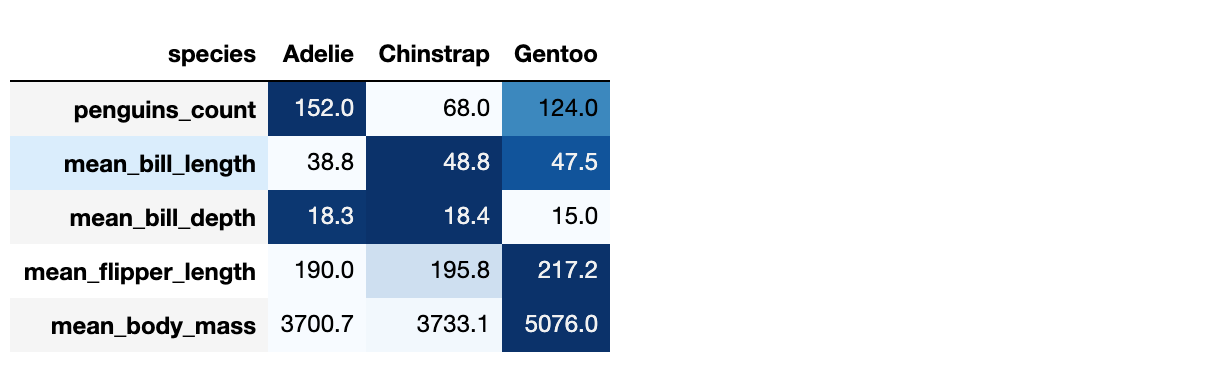
Транспонируем таблицу — так нагляднее сравнение между видами и применяем метод background_gradient со следующими параметрами:
- цветовая карта( cmap ): Blues . Это одна из дефолтных карт;
- сравнение по строкам ( axis=1 ).
Вывод
Форматирование таблиц в pandas с помощью DataFrame.style и Options and settings упрощает жизнь, ну или как минимум улучшает читабельность кода и отчетов. Но обработку типов данных, пропусков и регистра лучше, конечно, проводить осознанно ещё до этапа визуализации.
Дополнительно можно разобраться с:
- Экспортом в excel;
- Собственными функциями для условного форматирования. Мы использовали встроенные функции highlight_max , highlight_min и highlight_null , но для более изощрённых условий можно написать свою;
- Такими библиотеками как sparklines и PrettyPandas .