Хэширование в строковых задачах
Хэш — это какая-то функция, сопоставляющая объектам какого-то множества числовые значения из ограниченного промежутка.
- Быстро считается — за линейное от размера объекта время;
- Имеет не очень большие значения — влезающие в 64 бита;
- «Детерминированно-случайная» — если хэш может принимать \(n\) различных значений, то вероятность того, что хэши от двух случайных объектов совпадут, равна примерно \(\frac\) .
Обычно хэш-функция не является взаимно однозначной: одному хэшу может соответствовать много объектов. Такие функции называют сюръективными.
Для некоторых задач удобнее работать с хэшами, чем с самими объектами. Пусть даны \(n\) строк длины \(m\) , и нас просят \(q\) раз проверять произвольные две на равенство. Вместо наивной проверки за \(O(q \cdot n \cdot m)\) , мы можем посчитать хэши всех строк, сохранить, и во время ответа на запрос сравнивать два числа, а не две строки.

Применения в реальной жизни
- Чек-суммы. Простой и быстрый способ проверить целостность большого передаваемого файла — посчитать хэш-функцию на стороне отправителя и на стороне получателя и сравнить.
- Хэш-таблица. Класс unordered_set из STL можно реализовать так: заведём \(n\) изначально пустых односвязных списков. Возьмем какую-нибудь хэш-функцию \(f\) с областью значений \([0, n)\) . При обработке .insert(x) мы будем добавлять элемент \(x\) в \(f(x)\) -тый список. При ответе на .find(x) мы будем проверять, лежит ли \(x\) -тый элемент в \(f(x)\) -том списке. Благодаря «равномерности» хэш-функции, после \(k\) добавлений ожидаемое количество сравнений будет равно \(\frac\) = \(O(1)\) при правильном выборе \(n\) .
- Мемоизация. В динамическом программировании нам иногда надо работать с состояниями, которые непонятно как кодировать, чтобы «разгладить» в массив. Пример: шахматные позиции. В таком случае нужно писать динамику рекурсивно и хранить подсчитанные значения в хэш-таблице, а для идентификации состояния использовать его хэш.
- Проверка на изоморфизм. Если нам нужно проверить, что какие-нибудь сложные структуры (например, деревья) совпадают, то мы можем придумать для них хэш-функцию и сравнивать их хэши аналогично примеру со строками.
- Криптография. Правильнее и безопаснее хранить хэши паролей в базе данных вместо самих паролей — хэш-функцию нельзя однозначно восстановить.
- Поиск в многомерных пространствах. Детерминированный поиск ближайшей точки среди \(m\) точек в \(n\) -мерном пространстве быстро не решается. Однако можно придумать хэш-функцию, присваивающую лежащим рядом элементам одинаковые хэши, и делать поиск только среди элементов с тем же хэшом, что у запроса.
Хэшируемые объекты могут быть самыми разными: строки, изображения, графы, шахматные позиции, просто битовые файлы.
Сегодня же мы остановимся на строках.
Полиномиальное хэширование
Лайфхак: пока вы не выучили все детерминированные строковые алгоритмы, научитесь пользоваться хэшами.
Будем считать, что строка — это последовательность чисел от \(1\) до \(m\) (размер алфавита). В C++ char это на самом деле тоже число, поэтому можно вычитать из символов минимальный код и кастовать в число: int x = (int) (c — ‘a’ + 1) .
Определим прямой полиномиальный хэш строки как значение следующего многочлена:
\[ h_f = (s_0 + s_1 k + s_2 k^2 + \ldots + s_n k^n) \mod p \]
Здесь \(k\) — произвольное число больше размера алфавита, а \(p\) — достаточно большой модуль, вообще говоря, не обязательно простой.
Его можно посчитать за линейное время, поддерживая переменную, равную нужной в данный момент степени \(k\) :
const int k = 31, mod = 1e9+7; string s = "abacabadaba"; long long h = 0, m = 1; for (char c : s) int x = (int) (c - 'a' + 1); h = (h + m * x) % mod; m = (m * k) % mod; >Можем ещё определить обратный полиномиальный хэш:
\[ h_b = (s_0 k^n + s_1 k^ + \ldots + s_n) \mod p \]
Его преимущество в том, что можно написать на одну строчку кода меньше:
long long h = 0; for (char c : s) int x = (int) (c - 'a' + 1); h = (h * k + x) % mod; >Автору проще думать об обычных многочленах, поэтому он будет везде использовать прямой полиномиальный хэш и обозначать его просто буквой \(h\) .
Зачем это нужно?
Используя тот факт, что хэш это значение многочлена, можно быстро пересчитывать хэш от результата выполнения многих строковых операций.
Например, если нужно посчитать хэш от конкатенации строк \(a\) и \(b\) (т. е. \(b\) приписали в конец строки \(a\) ), то можно просто хэш \(b\) домножить на \(k^<|a|>\) и сложить с хэшом \(a\) :
Удалить префикс строки можно так:
А суффикс — ещё проще:
В задачах нам часто понадобится домножать \(k\) в какой-то степени, поэтому имеет смысл предпосчитать все нужные степени и сохранить в массиве:
const int maxn = 1e5+5; int p[maxn]; p[0] = 1; for (int i = 1; i maxn; i++) p[i] = (p[i-1] * k) % mod;Как это использовать в реальных задачах? Пусть нам надо отвечать на запросы проверки на равенство произвольных подстрок одной большой строки. Подсчитаем значение хэш-функции для каждого префикса:
int h[maxn]; h[0] = 0; // h[k] -- хэш префикса длины k // будем считать, что s это уже последовательность int-ов for (int i = 0; i n; i++) h[i+1] = (h[i] + p[i] * s[i]) % mod;Теперь с помощью этих префиксных хэшей мы можем определить функцию, которая будет считать хэш на произвольном подотрезке:
Деление по модулю возможно делать только при некоторых k и mod (а именно — при взаимно простых). В любом случае, писать его долго, и мы это делать не хотим.
Для нашей задачи не важно получать именно полиномиальный хэш — главное, чтобы наша функция возвращала одинаковый многочлен от одинаковых подстрок. Вместо приведения к нулевой степени приведём многочлен к какой-нибудь достаточно большой — например, к \(n\) -ной. Так проще — нужно будет домножать, а не делить.
int hash_substring (int l, int r) return (h[r+1] - h[l]) * p[n-l] % mod; >Теперь мы можем просто вызывать эту функцию от двух отрезков и сравнивать числовое значение, отвечая на запрос за \(O(1)\) .
Упражнение. Напишите то же самое, но используя обратный полиномиальный хэш — этот способ тоже имеет право на существование, и местами он даже проще. Обратный хэш подстроки принято считать и использовать в стандартном виде из определения, поскольку там нет необходимости в делении.
Лайфхак. Если взять обратный полиномиальный хэш короткой строки на небольшом алфавите с \(k=10\) , то числовое значение хэша строки будет наглядно соотноситься с самой строкой:
Этим удобно пользоваться при дебаге.
Примеры задач
Количество разных подстрок. Посчитаем хэши от всех подстрок за \(O(n^2)\) и добавим их все в std::set . Чтобы получить ответ, просто вызовем set.size() .
Поиск подстроки в строке. Можно посчитать хэши от шаблона (строки, которую ищем) и пройтись «окном» размера шаблона по тексту, поддерживая хэш текущей подстроки. Если хэш какой-то из этих подстрок совпал с хэшом шаблона, то мы нашли нужную подстроку. Это называется алгоритмом Рабина-Карпа.
Сравнение строк (больше-меньше, а не только равенство). У любых двух строк есть какой-то общий префикс (возможно, пустой). Сделаем бинпоиск по его длине, а дальше сравним два символа, идущие за ним.
Палиндромность подстроки. Можно посчитать два массива — обратные хэши и прямые. Проверка на палиндром будет заключаться в сравнении значений hash_substring() на первом массиве и на втором.
Количество палиндромов. Можно перебрать центр палиндрома, а для каждого центра — бинпоиском его размер. Проверять подстроку на палиндромность мы уже умеем. Как и всегда в задачах на палиндромы, случаи четных и нечетных палиндромов нужно обрабатывать отдельно.
Хранение строк в декартовом дереве
Если для вас всё вышеперечисленное тривиально: можно делать много клёвых вещей, если «оборачивать» строки в декартово дерево. В вершине дерева можно хранить символ, а также хэш подстроки, соответствующей её поддереву. Чтобы поддерживать хэш, нужно просто добавить в upd() пересчёт хэша от конкатенации трёх строк — левого сына, своего собственного символа и правого сына.
Имея такое дерево, мы можем обрабатывать запросы, связанные с изменением строки: удаление и вставка символа, перемещение и переворот подстрок, а если дерево персистентное — то и копирование подстрок. При запросе хэша подстроки нам, как обычно, нужно просто вырезать нужную подстроку и взять хэш, который будет лежать в вершине-корне.
Если нам не нужно обрабатывать запросы вставки и удаления символов, а, например, только изменения, то можно использовать и дерево отрезков вместо декартова.
Вероятность ошибки и почему это всё вообще работает
У алгоритмов, использующих хэширование, есть один неприятный недостаток: недетерминированность. Если мы сгенерируем бесконечное количество примеров, то когда-нибудь нам не повезет, и программа отработает неправильно. На CodeForces даже иногда случаются взломы решений, использующих хэширование — можно в оффлайне сгенерировать тест против конкретного решения.
Событие, когда два хэша совпали, а не должны, называется коллизией. Пусть мы решаем задачу определения количества различных подстрок — мы добавляем в set \(O(n^2)\) различных случайных значений в промежутке \([0, m)\) . Понятно, что если произойдет коллизия, то мы какую-то строку не учтем и получим WA. Насколько большим следует делать \(m\) , чтобы не бояться такого?
Выбор констант
Практическое правило: если вам нужно хранить \(n\) различных хэшей, то безопасный модуль — это число порядка \(10 \cdot n^2\) . Обоснование — см. парадокс дней рождений.
Не всегда такой можно выбрать один — если он будет слишком большой, будут происходить переполнения. Вместо этого можно брать два или даже три модуля и считать много хэшей параллельно.
Можно также брать модуль \(2^\) . У него есть несколько преимуществ:
- Он большой — второй модуль точно не понадобится.
- С ним ни о каких переполнениях заботиться не нужно — если все хранить в unsigned long long , процессор сам автоматически сделает эти взятия остатков при переполнении.
- С ним хэширование будет быстрее — раз переполнение происходит на уровне процессора, можно не выполнять долгую операцию % .
Всё с этим модулем было прекрасно, пока не придумали тест против него. Однако, его добавляют далеко не на все контесты — имейте это в виду.
В выборе же \(k\) ограничения не такие серьезные:
- Она должна быть чуть больше размера словаря — иначе можно изменить две соседние буквы и получить коллизию.
- Она должна быть взаимно проста с модулем — иначе в какой-то момент всё может занулиться.
Главное — чтобы значения \(k\) и модуля не знал человек, который генерирует тесты.
Парадокс дней рождений
В группе, состоящей из 23 или более человек, вероятность совпадения дней рождения хотя бы у двух людей превышает 50%.
Более общее утверждение: в мультимножество нужно добавить \(\Theta(\sqrt)\) случайных чисел от 1 до n, чтобы какие-то два совпали.
Первое доказательство (для любителей матана). Пусть \(f(n, d)\) это вероятность того, что в группе из \(n\) человек ни у кого не совпали дни рождения. Будем считать, что дни рождения распределены независимо и равномерно в промежутке от \(1\) до \(d\) .
\[ f(n, d) = (1-\frac) \times (1-\frac) \times . \times (1-\frac) \]
Попытаемся оценить \(f\) :
Из последнего выражения более-менее понятно, что вероятность \(\frac\) достигается при \(n \approx \sqrt\) и в этой точке изменяется очень быстро.
Второе доказательство (для любителей теорвера). Введем \(\frac\) индикаторов — по одному для каждой пары людей \((i, j)\) — каждый будет равен единице, если дни рождения совпали. Ожидание и вероятность каждого индикатора равна \(\frac\) .
Обозначим за \(X\) число совпавших дней рождений. Его ожидание равно сумме ожиданий этих индикаторов, то есть \(\frac \cdot \frac\) .
Отсюда понятно, что если \(d = \Theta(n^2)\) , то ожидание равно константе, а если \(d\) асимптотически больше или меньше, то \(X\) стремится нулю или бесконечности соответственно.
Примечание: формально, из этого явно не следует, что вероятности тоже стремятся к 0 и 1.
Бонус: «мета-задача»
Дана произвольная строка, по которой известным только авторам задачи способом генерируется ответ yes/no. В задаче 100 тестов. У вас есть 20 попыток отослать решение. В качестве фидбэка вам доступны вердикты на каждом тесте. Вердиктов всего два: OK (ответ совпал) и WA. Попытки поделить на ноль, выделить терабайт памяти и подобное тоже считаются как WA.
Хеширование
Хэш — это какая-то функция, сопоставляющая объектам какого-то множества числовые значения из ограниченного промежутка.
- Быстро считается — за линейное от размера объекта время;
- Имеет не очень большие значения — влезающие в 64 бита;
- «Детерминированно-случайная» — если хэш может принимать $n$ различных значений, то вероятность того, что хэши от двух случайных объектов совпадут, равна примерно $\frac$.
Обычно хэш-функция не является взаимно однозначной: одному хэшу может соответствовать много объектов. Такие функции называют сюръективными.
Для некоторых задач удобнее работать с хэшами, чем с самими объектами. Пусть даны $n$ строк длины $m$, и нас просят $q$ раз проверять произвольные две на равенство. Вместо наивной проверки за $O(q \cdot n \cdot m)$, мы можем посчитать хэши всех строк, сохранить, и во время ответа на запрос сравнивать два числа, а не две строки.
Применения в реальной жизни
- Чек-суммы. Простой и быстрый способ проверить целостность большого передаваемого файла — посчитать хэш-функцию на стороне отправителя и на стороне получателя и сравнить.
- Хэш-таблица. Класс unordered_set из STL можно реализовать так: заведём $n$ изначально пустых односвязных списков. Возьмем какую-нибудь хэш-функцию $f$ с областью значений $[0, n)$. При обработке .insert(x) мы будем добавлять элемент $x$ в $f(x)$-тый список. При ответе на .find(x) мы будем проверять, лежит ли $x$-тый элемент в $f(x)$-том списке. Благодаря «равномерности» хэш-функции, после $k$ добавлений ожидаемое количество сравнений будет равно $\frac$ = $O(1)$ при правильном выборе $n$.
- Мемоизация. В динамическом программировании нам иногда надо работать с состояниями, которые непонятно как кодировать, чтобы «разгладить» в массив. Пример: шахматные позиции. В таком случае нужно писать динамику рекурсивно и хранить подсчитанные значения в хэш-таблице, а для идентификации состояния использовать его хэш.
- Проверка на изоморфизм. Если нам нужно проверить, что какие-нибудь сложные структуры (например, деревья) совпадают, то мы можем придумать для них хэш-функцию и сравнивать их хэши аналогично примеру со строками.
- Криптография. Правильнее и безопаснее хранить хэши паролей в базе данных вместо самих паролей — хэш-функцию нельзя однозначно восстановить.
- Поиск в многомерных пространствах. Детерминированный поиск ближайшей точки среди $m$ точек в $n$-мерном пространстве быстро не решается. Однако можно придумать хэш-функцию, присваивающую лежащим рядом элементам одинаковые хэши, и делать поиск только среди элементов с тем же хэшом, что у запроса.
Хэшируемые объекты могут быть самыми разными: строки, изображения, графы, шахматные позиции, просто битовые файлы.
Сегодня же мы остановимся на строках.
Полиномиальное хэширование
Лайфхак: пока вы не выучили все детерминированные строковые алгоритмы, научитесь пользоваться хэшами.
Будем считать, что строка — это последовательность чисел от $1$ до $m$ (размер алфавита). В C++ char это на самом деле тоже число, поэтому можно вычитать из символов минимальный код и кастовать в число: int x = (int) (c — ‘a’ + 1) .
Определим прямой полиномиальный хэш строки как значение следующего многочлена:
$$ h_f = (s_0 + s_1 k + s_2 k^2 + \ldots + s_n k^n) \mod p $$
Здесь $k$ — произвольное число больше размера алфавита, а $p$ — достаточно большой модуль, вообще говоря, не обязательно простой.
Его можно посчитать за линейное время, поддерживая переменную, равную нужной в данный момент степени $k$:
const int k = 31, mod = 1e9+7; string s = "abacabadaba"; long long h = 0, m = 1; for (char c : s) int x = (int) (c - 'a' + 1); h = (h + m * x) % mod; m = (m * k) % mod; >
Можем ещё определить обратный полиномиальный хэш:
$$ h_b = (s_0 k^n + s_1 k^ + \ldots + s_n) \mod p $$
Его преимущество в том, что можно написать на одну строчку кода меньше:
long long h = 0; for (char c : s) int x = (int) (c - 'a' + 1); h = (h * k + x) % mod; >
Автору проще думать об обычных многочленах, поэтому он будет везде использовать прямой полиномиальный хэш и обозначать его просто буквой $h$.
Зачем это нужно?
Используя тот факт, что хэш это значение многочлена, можно быстро пересчитывать хэш от результата выполнения многих строковых операций.
Например, если нужно посчитать хэш от конкатенации строк $a$ и $b$ (т. е. $b$ приписали в конец строки $a$), то можно просто хэш $b$ домножить на $k^<|a|>$ и сложить с хэшом $a$:
Удалить префикс строки можно так:
А суффикс — ещё проще:
В задачах нам часто понадобится домножать $k$ в какой-то степени, поэтому имеет смысл предпосчитать все нужные степени и сохранить в массиве:
const int maxn = 1e5+5; int p[maxn]; p[0] = 1; for (int i = 1; i maxn; i++) p[i] = (p[i-1] * k) % mod;
Как это использовать в реальных задачах? Пусть нам надо отвечать на запросы проверки на равенство произвольных подстрок одной большой строки. Подсчитаем значение хэш-функции для каждого префикса:
int h[maxn]; h[0] = 0; // h[k] -- хэш префикса длины k // будем считать, что s это уже последовательность int-ов for (int i = 0; i n; i++) h[i+1] = (h[i] + p[i] * s[i]) % mod;
Теперь с помощью этих префиксных хэшей мы можем определить функцию, которая будет считать хэш на произвольном подотрезке:
Деление по модулю возможно делать только при некоторых k и mod (а именно — при взаимно простых). В любом случае, писать его долго, и мы это делать не хотим.
Для нашей задачи не важно получать именно полиномиальный хэш — главное, чтобы наша функция возвращала одинаковый многочлен от одинаковых подстрок. Вместо приведения к нулевой степени приведём многочлен к какой-нибудь достаточно большой — например, к $n$-ной. Так проще — нужно будет домножать, а не делить.
int hash_substring (int l, int r) return (h[r+1] - h[l]) * p[n-l] % mod; >
Теперь мы можем просто вызывать эту функцию от двух отрезков и сравнивать числовое значение, отвечая на запрос за $O(1)$.
Упражнение. Напишите то же самое, но используя обратный полиномиальный хэш — этот способ тоже имеет право на существование, и местами он даже проще. Обратный хэш подстроки принято считать и использовать в стандартном виде из определения, поскольку там нет необходимости в делении.
Лайфхак. Если взять обратный полиномиальный хэш короткой строки на небольшом алфавите с $k=10$, то числовое значение хэша строки будет наглядно соотноситься с самой строкой:
Этим удобно пользоваться при дебаге.
Примеры задач
Количество разных подстрок. Посчитаем хэши от всех подстрок за $O(n^2)$ и добавим их все в std::set . Чтобы получить ответ, просто вызовем set.size() .
Поиск подстроки в строке. Можно посчитать хэши от шаблона (строки, которую ищем) и пройтись «окном» размера шаблона по тексту, поддерживая хэш текущей подстроки. Если хэш какой-то из этих подстрок совпал с хэшом шаблона, то мы нашли нужную подстроку. Это называется алгоритмом Рабина-Карпа.
Сравнение строк (больше-меньше, а не только равенство). У любых двух строк есть какой-то общий префикс (возможно, пустой). Сделаем бинпоиск по его длине, а дальше сравним два символа, идущие за ним.
Палиндромность подстроки. Можно посчитать два массива — обратные хэши и прямые. Проверка на палиндром будет заключаться в сравнении значений hash_substring() на первом массиве и на втором.
Количество палиндромов. Можно перебрать центр палиндрома, а для каждого центра — бинпоиском его размер. Проверять подстроку на палиндромность мы уже умеем. Как и всегда в задачах на палиндромы, случаи четных и нечетных палиндромов нужно обрабатывать отдельно.
Вероятность ошибки и почему это всё вообще работает
У алгоритмов, использующих хэширование, есть один неприятный недостаток: недетерминированность. Если мы сгенерируем бесконечное количество примеров, то когда-нибудь нам не повезет, и программа отработает неправильно. На CodeForces даже иногда случаются взломы решений, использующих хэширование — можно в оффлайне сгенерировать тест против конкретного решения.
Событие, когда два хэша совпали, а не должны, называется *коллизией*. Пусть мы решаем задачу определения количества различных подстрок — мы добавляем в set $O(n^2)$ различных случайных значений в промежутке $[0, m)$. Понятно, что если произойдет коллизия, то мы какую-то строку не учтем и получим WA. Насколько большим следует делать $m$, чтобы не бояться такого?
Выбор констант
Практическое правило: если вам нужно хранить $n$ различных хэшей, то безопасный модуль — это число порядка $10 \cdot n^2$. Обоснование — см. парадокс дней рождений.
Не всегда такой можно выбрать один — если он будет слишком большой, будут происходить переполнения. Вместо этого можно брать два или даже три модуля и считать много хэшей параллельно.
Можно также брать модуль $2^$. У него есть несколько преимуществ:
- Он большой — второй модуль точно не понадобится.
- С ним ни о каких переполнениях заботиться не нужно — если все хранить в `unsigned long long`, процессор сам автоматически сделает эти взятия остатков при переполнении.
- С ним хэширование будет быстрее — раз переполнение происходит на уровне процессора, можно не выполнять долгую операцию `%`.
Всё с этим модулем было прекрасно, пока не придумали тест против него. Однако, его добавляют далеко не на все контесты — имейте это в виду.
В выборе же $k$ ограничения не такие серьезные:
- Она должна быть чуть больше размера словаря — иначе можно изменить две соседние буквы и получить коллизию.
- Она должна быть взаимно проста с модулем — иначе в какой-то момент всё может занулиться.
Главное — чтобы значения $k$ и модуля не знал человек, который генерирует тесты.
Парадокс дней рождений
В группе, состоящей из 23 или более человек, вероятность совпадения дней рождения хотя бы у двух людей превышает 50%.
Более общее утверждение: в мультимножество нужно добавить $\Theta(\sqrt)$ случайных чисел от 1 до n, чтобы какие-то два совпали.
-
- Первое доказательство** (для любителей матана). Пусть $f(n, d)$ это вероятность того, что в группе из $n$ человек ни у кого не совпали дни рождения.
Будем считать, что дни рождения распределены независимо и равномерно в промежутке от $1$ до $d$.
$$ f(n, d) = \left(1-\frac\right) \times \left(1-\frac\right) \times\ . \ \times \left(1-\frac\right) $$
Попытаемся оценить $f$:
Из последнего выражения более-менее понятно, что вероятность $\frac$ достигается при $n \approx \sqrt$ и в этой точке изменяется очень быстро.
-
- Второе доказательство** (для любителей теорвера). Введем $\frac$ индикаторов — по одному для каждой пары людей $(i, j)$ — каждый будет равен единице, если дни рождения совпали. Ожидание и вероятность каждого индикатора равна $\frac$.
Обозначим за $X$ число совпавших дней рождений. Его ожидание равно сумме ожиданий этих индикаторов, то есть $\frac \cdot \frac$.
Отсюда понятно, что если $d = \Theta(n^2)$, то ожидание равно константе, а если $d$ асимптотически больше или меньше, то $X$ стремится нулю или бесконечности соответственно.
Примечание: формально, из этого явно не следует, что вероятности тоже стремятся к 0 и 1.
Бонус: «мета-задача»
Дана произвольная строка, по которой известным только авторам задачи способом генерируется ответ yes/no. В задаче 100 тестов. У вас есть 20 попыток отослать решение. В качестве фидбэка вам доступны вердикты на каждом тесте. Вердиктов всего два: OK (ответ совпал) и WA. Попытки поделить на ноль, выделить терабайт памяти и подобное тоже считаются как WA.
Как называется совпадение хэш кодов двух различных строк
mekkuin → I am eating rice everyday
ATSTNG → Does Polygon automaticly send statements and tutorials of all problems into AI service?
MikeMirzayanov → Polygon: AI-Powered Automatic Tips
MikeMirzayanov → Codeforces Single Account Policy: zh0ukangyang is Removed from the Rating
Blinov_Artemii → Bullying on Codeforces
_ _asm__ → Most annoying person on CF in 2023
rohitrao835589 → memes
Vladosiya → Codeforces Round 913 (Div. 3) Editorial
Vladosiya → Codeforces Round 903 (Div. 3) Разбор
cloud_eve → Elementary Number Theory
maomao90 → Editorial for Hello 2024
Palestinian_Dream → Extracting Mathematical Ideas Behind The Problems
changingmong100 → Title: «A Mother’s Love in Codeforces»
I_HATE_CONSTRUCTIVES. → IZhO 2024 day 1 discussion
Victor_Luis123 → Is Dijkstra’s overrated.
maomao90 → Hello 2024
atcoder_official → AtCoder Beginner Contest 335 (Sponsored by Mynavi) Announcement

salt_n_ice → CSES Longest Flight Route TLE in one test case
box → On the Min25 sieve and extensions / SPOJ ASSIEVE
maomao90 → I am top 1 contributor. AMA!
VivaciousAubergine → Wow! You received a rating of -501 in the CodeTON round. Share it!
whatthemomooofun1729 → codeforces login issue
mohammed_orkhan → I wnat to be EXPERT!!
uchicha_itachi → What does plagiarism actually include?
Zhtluo → Is ICPC ECNA 2023 problem C straight-up wrong?
[Tutorial] Полиномиальное хэширование + разбор интересных задач
Правка ru6, от dmkz, 2018-07-07 02:09:25
Здравствуйте! Этот пост написан для всех тех, кто хочет освоить полиномиальные хэши и научиться применять их в решении различных задач. Я кратко приведу теоретический материал, рассмотрю особенности реализации и разберу некоторые задачи, среди них:
- Поиск всех вхождений одной строки длины n в другую длины m за O(n + m)
- Поиск наибольшей общей подстроки двух строк длин n и m (n ≥ m) за O(n + m·log(m) 2 )
- Нахождение лексикографически минимального циклического сдвига строки длины n за O(n·log(n))
- Сортировка всех циклических сдвигов строки длины n в лексикографическом порядке за O(n·log(n) 2 )
- Нахождение количества подпалиндромов строки длины n за O(n·log(n))
- Количество подстрок строки длины n , являющихся циклическими сдвигами строки длины m за O((n + m)·log(n))
- Количество суффиксов строки длины n , бесконечное расширение которых совпадает с бесконечным расширением всей строки за O(n·log(n)) (расширение — дублирование строки бесконечное число раз).
Примечание 1. Не исключено, что некоторые задачи могут быть решены быстрее другими методами, например, сортировка циклических сдвигов — это в точности то, что происходит при построении суффиксного массива, искать все вхождения одной строки в другую и работать с собственными суффиксами позволят префикс-функция и алгоритм Кнута-Морриса-Пратта, а с подпалиндромами отлично справляется алгоритм Манакера
Примечание 2. В задачах выше приведена оценка, когда поиск хэша осуществляется при помощи сортировки и бинарного поиска. Если у Вас есть своя хэш-таблица с открытым перемешиванием или цепочками переполнения, то Вы — счастливчик, смело заменяйте бинарный поиск хэша на поиск в Вашей хэш-таблице, но не вздумайте использовать std::unordered_set , так как на практике поиск в std::unordered_set проигрывает сортировке и бинарному поиску в связи с тем, что эта штука подчиняется стандарту C++ и обязана много чего гарантировать пользователю, что полезно при промышленной разработке и, зачастую, бесполезно в олимпиадном программировании, поэтому сортировка и бинарный поиск для несложных структур одерживают абсолютное первенство в C++ по скорости работы, если не тянуть что-то свое.
Примечание 3. В тех случаях, когда сравнение элементов затратно (например, сравнение по хэшам за O(log(n)) ), то в худшем случае std::random_shuffle + std::sort всегда проигрывает std::stable_sort , так как std::stable_sort гарантирует минимальное число сравнений среди всех сортировок (основанных на сравнениях) для худшего случая.
Решение перечисленных задач будет приведено ниже, исходники тоже.
В качестве плюса полиномиального хэширования могу отметить, что зачастую не нужно думать, можно сразу брать и писать наивный алгоритм решения задачи и ускорять его полиномиальным хэшированием. Лично мне решения с полиномиальным хэшем приходят в голову в первую очередь, может поэтому я синий.
Среди минусов полиномиального хэширования: а) Слишком много операций остатка от деления, порой на грани TLE на больших задачах и б) на codeforces в программах на C++ зачастую маленькие гарантии от взлома из-за MinGW: std::random_device генерирует каждый раз одно и то же число, std::chrono::high_resolution_clock тикает в микросекундах вместо наносекунд. (Компилятор cygwin на windows лишен всех недостатков MinGW, в том числе и медленного ввода/вывода).
`UPD`: Одолели пункт а)
Для того, чтобы не использовать медленную операцию взятия остатка от деления, можно взять два модуля m1 = 2 31 — 1 и m2 = 2 64 .
Тогда для взятия остатка от деления по модулю m2 необходимо проводить вычисления в беззнаковом 64-битном типе, например, в типе unsigned long long в C++, т.к. во многих языках программирования гарантируется, что вычисления в этом типе данных будут проводиться по модулю 2 64 .
Для взятия остатка от деления по модулю 2 31 — 1 = 2147483647 для неотрицательных чисел x до 2 62 (результат умножения двух остатков) можно брать смещенный остаток следующим образом:
x = x + 2147483647; x = (x >> 31) + (x & 2147483647); x = (x >> 31) + (x & 2147483647); return x;В случае сложения и вычитания по модулю m1 двух остатков можно обойтись обычным тернарным оператором.
`UPD`: Одолели пункт б)
Достаточно делать побитовое ИЛИ для значений текущего времени и адреса в памяти, полученного от менеджера кучи:
- (uint64_t)(std::chrono::high_resolution_clock::now().time_since_epoch().count())
- (uint64_t)(std::make_unique().get())
Что такое полиномиальный хэш?
Хэш-функция должна сопоставлять некоторому объекту некоторое число (его хэш) и обладать следующими свойствами:
- Если два объекта совпадают, то их хэши равны.
- Если два хэша равны, то объекты совпадают с большой вероятностью.
Коллизией называется очень неприятная ситуация равенства двух хэшей у несовпадающих объектов. В идеале, при выборе хэш-функции необходимо обеспечить как можно меньшую вероятность коллизии. На практике — такую вероятность, чтобы успешно пройти набор тестов к задаче.
Рассмотрим последовательность a0, a1, . an — 1> . Под полиномиальным хэшем для этой последовательности будем иметь в виду результат вычисления следующего выражения:

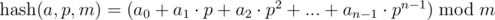
Здесь p и m — точка (или основание) и модуль хэширования соответственно.
Условия, которые мы наложим:
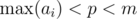 ,
, 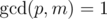 .
.Примечание. Если подумать об интерпретации выражения, то мы сопоставляем последовательности a0, a1, . an — 1> число длины n в системе счисления p и берем остаток от его деления на число m , или значение многочлена (n — 1) -й степени с коэффициентами ai в точке p по модулю m . О выборе p и m поговорим позже.
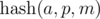
Примечание. Если значение , не взятое по модулю, помещается в целочисленный тип данных (например, 64-битный тип), то можно каждой последовательности сопоставить это число. Тогда сравнение на больше / меньше / равно можно выполнять за O(1) .
Сравнение на равенство за O(1)
Теперь ответим на вопрос, как сравнивать произвольные подпоследовательности за O(1) ? Покажем, что для сравнения подпоследовательностей исходной последовательности a0, a1, . an — 1> достаточно посчитать полиномиальный хэш на каждом префиксе исходной последовательности.
Определим полиномиальный хэш на префиксе как:
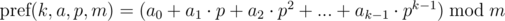
Кратко обозначим
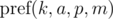 как
как 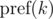 и будем иметь в виду, что итоговое значение берется по модулю m . Тогда:
и будем иметь в виду, что итоговое значение берется по модулю m . Тогда: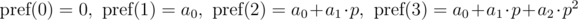
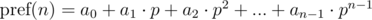
Полиномиальный хэш на каждом префиксе можно находить за O(n) , используя рекуррентные соотношения:
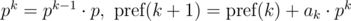
Допустим, нам нужно сравнить две подстроки, начинающиеся в позициях i и j и имеющие длину len , на равенство:
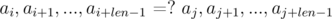
Рассмотрим разности
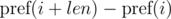 и
и 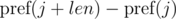 . Не трудно видеть, что:
. Не трудно видеть, что: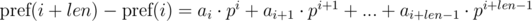
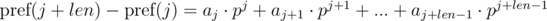
Домножим 1-е уравнение на p j , а 2-е на p i . Получим:
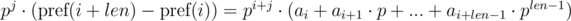
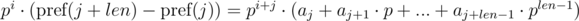
Видим, что в правой части выражений в скобках были получены полиномиальные хэши от подпоследовательностей:
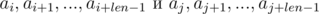
Таким образом, чтобы определить, совпали ли искомые подпоследовательности, необходимо проверить выполнение следующего равенства:
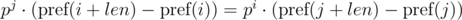
Одно такое сравнение можно выполнять за O(1) , предподсчитав степени p по модулю. С учетом модуля m , имеем:
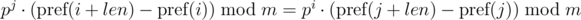
Минусы: сравнение одной строки зависит от параметров другой строки (от j ).
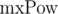
Если нам известны максимальные длины сравниваемых строк, то можно применить другой подход. Обозначим максимальную длину сравниваемых строк как . Домножим 1-е уравнение на p в степени mxPow — i — len + 1 , а 2-е на p в степени mxPow — j — len + 1 . Тогда:
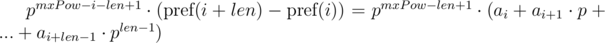
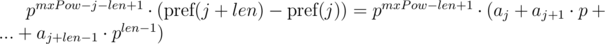
Можем заметить, что в правых частях был получен полиномиальный хэш от искомых подпоследовательностей. Тогда, равенство проверяется следующим образом:
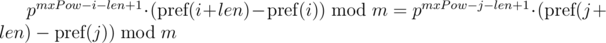
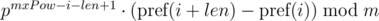
Этот подход позволяет сравнивать одну подстроку длины len со всеми подстроками длины len на равенство, в том числе, и подстроками другой строки, так как выражение для подстроки длины len , начинающейся в позиции i , зависит только от параметров подстроки i , len и константы mxPow , а не от параметров другой подстроки.
Сравнение на больше / меньше за O(log(n))
Рассмотрим две подстроки возможно разных строк длин len1 и len2 , (len1 ≤ len2) , начинающиеся в позициях i и j соответственно. Заметим, что отношение больше / меньше определяется первым несовпадающим символом в этих подстроках, а до позиции этого символа строки совпадают. Таким образом, необходимо найти позицию первого несовпадающего символа методом бинарного поиска, а затем сравнить найденные символы. Благодаря сравнению подстрок на равенство за O(1) , можно решить задачу сравнения подстрок на больше / меньше за O(log(len1)) :
Псевдокод
low = 0; high = len1+1; while (high-low > 1) < mid = (low + high) / 2; if (hash(i,mid) == hash(j,mid)) < low = mid; >else < high = mid; >> low - позиция первого различияМинимизация вероятности коллизии
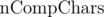
Пусть за все время работы программы нам нужно выполнить сравнений символов. Грубая оценка:
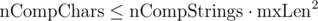
. Тогда вероятность того, что коллизии не произойдет:
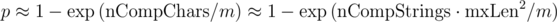
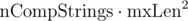
Отсюда очевидно, что m нужно брать значительно больше, чем . Тогда, аппроксимируя экспоненту рядом Тейлора, получаем вероятность коллизии на одном тесте:
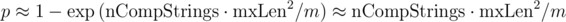
Если мы рассмотрим задачу о поиске вхождений всех циклических сдвигов одной строки в другую строку длин до 10 5 , то мы можем получить 10 15 сравнений символов (может показаться, что 10 20 , но чем больше длина — тем меньше позиций, в которых реально нужно искать совпадения с текущим циклическим сдвигом, поэтому 10 15 ).
Тогда, если мы возьмем простой модуль порядка 10 9 , то мы не пройдем ни один из максимальных тестов.
Если мы возьмем модуль порядка 10 18 , то вероятность коллизии на одном тесте ≈ 0.001 . Если максимальных тестов 100 , то вероятность коллизии в одном из тестов ≈ 0.1 , то есть 10% .
Если мы возьмем модуль порядка 10 27 , то на 100 максимальных тестах вероятность коллизии равна ≈ 10 — 10 .
Вывод: чем больше модуль — тем больше вероятность пройти тест. Эта вероятность не учитывает взломы.
Двойной полиномиальный хэш
Разумеется, в реальных программах мы не можем брать модули порядка 10 27 . Как быть? На помощь приходит китайская теорема об остатках. Если мы возьмем два взаимно простых модуля m1 и m2 , то кольцо остатков по модулю m = m1·m2 эквивалентно произведению колец по модулям m1 и m2 , т.е. между ними существует взаимно однозначное соответствие, основанное на идемпотентах кольца вычетов по модулю m . Иными словами, если вычислять
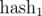 по модулю m1 и
по модулю m1 и 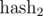 по модулю m2 , а затем сравнивать две подпоследовательности по и одновременно, то это эквивалентно сравнению полиномиальным хэшем по модулю m . Аналогично, можно брать три взаимно простых модуля m1 , m2 , m3 .
по модулю m2 , а затем сравнивать две подпоследовательности по и одновременно, то это эквивалентно сравнению полиномиальным хэшем по модулю m . Аналогично, можно брать три взаимно простых модуля m1 , m2 , m3 .Особенности реализации
Итак, мы подошли к реализации описанного выше. Цель — минимум взятий остатка от деления, т.е. получить два умножения в 64-битном типе и одно взятие остатка от деления в 64-битном типе на одно вычисление двойного полиномиального хэша, при этом получить хэш по модулю порядка 10^27 и защитить код от взлома на codeforces.
Выбор модулей. Выгодно использовать двойной полиномиальный хэш по модулям m1 = 1000000123 и m2 = 2^64 . Если Вам не нравится такой выбор m1 , можете выбрать 1000000321 , главное выбрать такое простое число, чтобы разность двух остатков лежала в пределах знакового 32-битного типа (int). Простое число брать удобнее, так как автоматически обеспечиваются условия gcd(m1, m2) = 1 и gcd(m1, p) = 1 . Выбор в качестве m2 = 2^64 не случаен. Стандарт C++ гарантирует, что все вычисления в unsigned long long выполняются по модулю 2^64 автоматически. Отдельно модуль 2^64 брать нельзя, так как существует анти-хэш тест, который не зависит от выбора точки хэширования p . Модуль m1 необходимо задать как константу для ускорения взятия модуля (компилятор (не MinGW) оптимизирует, заменяя умножением и побитовым сдвигом).
Кодирование последовательности. Если дана последовательность символов, состоящая, например, из маленьких латинских букв, то можно ничего не кодировать, так как каждому символу уже соответствует его код. Если дана последовательность целых чисел разумной для представления в памяти длины, то можно собрать в один массив все встречающиеся числа, отсортировать, удалить повторы и сопоставить каждому числу в последовательности его порядковый номер в полученном упорядоченном множестве. Начинать нумерацию с нуля запрещено: все последовательности вида 0,0,0. 0 разной длины будут иметь один и тот же полиномиальный хэш.
Выбор основания. В качестве основания p достаточно взять любое нечетное число, удовлетворяющее условию max(a[i]) < p < m1 . (нечетное, потому что тогда gcd(p, 2^64) = 1 ). Если Вас могут взломать, то необходимо генерировать p случайным образом с каждым новым запуском программы, причем генерация при помощи std::srand(std::time(0)) и std::rand() не подходит, так как std::time(0) тикает очень медленно, а std::rand() не обеспечивает достаточной равномерности. Если компилятор НЕ MinGW (к сожалению, на codeforces установлен MinGW), то можно использовать std::random_device , std::mt19937 , std::uniform_int_distribution (в cygwin на windows и gnu gcc на linux данный набор обеспечивает почти абсолютную случайность). Если не повезло и Вас посадили на MinGW, то ничего не остается, как std::random_device заменить на std::chrono::high_resolution_clock и надеяться на лучшее (или есть способ достать какой-нибудь счетчик из процессора?). На MinGW этот таймер тикает в микросекундах, на cygwin и gnu gcc в наносекундах.
Гарантии от взлома. Нечетных чисел до модуля порядка 10^9 тоже порядка 10^9 . Взломщику необходимо будет сгенерировать для каждого нечетного числа анти-хэш тест так, чтобы была коллизия в пространстве до 10^27 , скомпоновать все тесты в один большой тест и сломать Вас. Это если использовать не MinGW на Windows. На MinGW таймер тикает, как уже говорилось, в микросекундах. Зная время запуска решения на сервере с точностью до секунд, можно для каждой из 10^6 микросекунд вычислить, какое случайное p сгенерировалось, и тогда вариантов в 1000 раз меньше. Если 10^9 это какая-то космическая величина, то 10^6 уже кажется не такой безопасной. При использовании std::time(0) всего 10^3 вариантов (миллисекунды) — можно ломать. В комментариях я видел, что гроссмейстеры умеют ломать полиномиальный хэш до 10^36 .
Удобство в использовании. Удобно написать универсальный объект для полиномиального хэша и копировать его в ту задачу, где он может понадобиться. Лучше писать самостоятельно для своих нужд и целей в том стиле, в котором пишете Вы, чтобы разбираться в исходном коде при необходимости. Все задачи в этом посте решены при помощи копирования одного и того же объекта. Не исключено, что существуют специфические задачи, в которых это не сработает.
Задача 1. Поиск всех вхождений одной строки длины n в другую длины m за O(n + m)
Дано: Две строки S и T длин до 50000 . Вывести все позиции вхождения строки T в строку S . Индексация с нуля.
Пример: Ввод S = «ababbababa» , T = «aba» , вывод: 0 5 7 .
Решение и код
Посчитаем полиномиальный хэш на префиксах строк S и T . Будем идти вдоль строки S , сравнивая полиномиальный хэш текущей подстроки со всей строкой T . При совпадении хэшей выводим текущую позицию. Асимптотика: O(n) по времени и памяти. Исходный код.
Задача 2. Поиск наибольшей общей подстроки двух строк длин n и m (n ≥ m) за O(n + m·log(m) 2 )
Дано: Длина строк N и две строки A и B длины до 100000 . Вывести длину наибольшей общей подстроки.
Пример: Ввод: N = 28 , A = «VOTEFORTHEGREATALBANIAFORYOU» , B = «CHOOSETHEGREATALBANIANFUTURE» , вывод: THEGREATALBANIA
Решение и код
Первым делом посчитаем полиномиальный хэш на префиксах строк A и B . Пусть мы нашли наибольшую общую подстроку длины len , начинающуюся в позиции pos любой из строк. Тогда общей подстрокой будет также и любая подстрока длин len-1, len-2, . 1 , начинающаяся в позиции pos , а len+1 уже не будет являться общей подстрокой. Видно, что выполняются условия бинарного поиска. Инициализация бинарного поиска: low = 0 , high = N+1 . На каждой итерации поиска будем складывать все хэши подстрок длины mid строки A в вектор, сортировать его, а дальше проходить по хэшам подстрок длины mid строки B и искать их среди отсортированных хэшей строки A . Асимптотика решения по времени O(n log(n)^2) , по памяти O(n) . Исходный код.
Задача 3. Нахождение лексикографически минимального циклического сдвига строки длины n за O(n·log(n))
Дано: Строка S длины до 10^5 . Вывести минимальный лексикографически сдвиг строки A .
Пример: Ввод: «program» , Вывод: «amprogr»
Решение и код
В этой задаче необходимо написать сравнение двух подстрок методом бинарного поиска, описанным выше. Продублируем строку S и посчитаем полиномиальный хэш на префиксе. Каждый циклический сдвиг будем представлять в виде числа (начальной позиции). Сложим в вектор все позиции, а дальше применим линейный алгоритм нахождения минимума в массиве, используя оператор сравнения подстрок. Асимптотика: O(n log(n)) по времени и O(n) по памяти. Исходный код.
Задача 4. Сортировка всех циклических сдвигов строки длины n в лексикографическом порядке за O(n·log(n) 2 )
Дано: Строка S длины до 10^5 . Вывести номер позиции исходного слова в отсортированном списке циклических сдвигов. Если таких позиций несколько, то следует вывести позицию с наименьшим номером. Во второй строке вывести последний столбец таблицы циклических сдвигов.
Пример: Ввод: «abraka» , Вывод: «2 karaab»
Замечания
Не забудьте, что быстрая сортировка в процесса своей работы может переставлять элементы, но по условию задачи, равные циклические сдвиги не переставляются. Изначально теста против этого не было, теперь он есть. Более того, одиночный полиномиальный хэш по модулю 2^64 валится на этой задаче. Изначально анти-хэш теста не было, теперь он есть.
Решение и код
Не хотите строить суффиксный массив? Я тоже. Но когда-то все-таки нужно будет его построить, а пока продублируем строку S и посчитаем полиномиальный хэш на префиксе. Каждый циклический сдвиг будем представлять в виде числа (начальной позиции). Сложим в вектор все позиции, а дальше применим устойчивую сортировку слиянием, используя оператор сравнения подстрок. Асимптотика: O(n log(n)^2) по времени и O(n) по памяти.
Победила сортировка слиянием. Если кто-нибудь сдаст построением суффиксного массива, сообщите Ваш результат.
Задача 5. Нахождение количества подпалиндромов строки длины n за O(n·log(n))
Дано: Строка S длины до 10^5 . Вывести количество подпалиндромов строки.
Пример: Ввод: «ABACABADABACABA» , Вывод: 32
Решение и код
Скопируем исходную строку и обратим порядок элементов. Построим полиномиальный хэш на префиксах исходной строки и развернутой. Будем перебирать центры палиндромов и применять бинарный поиск по длине максимального палиндрома, имеющего центр в текущем символе.
Пусть строка S — исходная, а строка T — развернутая. Тогда необходимо сравнивать хэши:
S[i. i+len-1] и T[j. j+len-1] , где j = n — i + 1 .
Затем будем строить палиндромы четной длины. В этом случае нужно сравнивать хэши:
S[i+1. i+len] и T[j. j+len-1] , где j = n — i + 1 .
Исходный код. Асимптотика решения: O(nlog(n)) по времени и O(n) по памяти. На версии задачи с ограничениями 10^6 код получает Memory Limit (38 МБ). Задача для 10^6 не проходит с хэшем по модулю 2^64 — коллизия на тесте 7.
Задача 6. Количество подстрок строки длины n , являющихся циклическими сдвигами строки длины m за O((n + m)·log(n))
Дано: Заданы две строки S и T длины до 10^5 . Необходимо определить, сколько подстрок строки S являются циклическими сдвигами строки T .
Пример: Ввод: S = «aAaa8aaAa» , T=»aAa» , Вывод: 4
Решение и код
Запомним исходную длину строки T и продублируем строку 2 раза. Пусть n — исходная длина. Построим полиномиальный хэш на префиксах строк S и T . Выпишем хэши всех подстрок длины n строки T и отсортируем. Теперь задача свелась к тому, чтобы поискать каждую подстроку длины n строки S среди выписанных хэшей строки T . Это можно сделать за O(n log(n)) по времени и O(n) по памяти. Исходный код.
Задача 7. Количество суффиксов строки длины n , бесконечное расширение которых совпадает с бесконечным расширением всей строки за O(n·log(n))
Дано: Строка S длины до 10^5 . Бесконечным расширением строки назовем строку, полученную выписыванием исходной строки бесконечное число раз. Например, бесконечное расширение строки «abс» равно «abcabcabcabcabc. «. Необходимо ответить на вопрос, сколько суффиксов исходной строки имеют такое же бесконечное расширение, какое и строка S .
Пример: На входе: S = «qqqq» , на выходе 4 .
Решение и код
Первым делом развернем строку S и будем решать для префиксов. Построим полиномиальный хэш на префиксе строки S . Далее необходимо сравнить расширение каждого префикса с расширением исходной строки.
Пусть есть префикс S[0. m) длины m и префикс S[0. n) длины n , где n >= m . Рассмотрим расширение длины n*m . Это будет означать, что мы префикс S[0..m) запишем n раз подряд, а префикс S[0..n) — m раз подряд:
S[0. m)* = (1+p^m+p^(2m)+p^(3m)+p^((n-1)m))(S[0] + S[1] * p + S[2] * p^2 + . + S[m-1] * p^(m-1)))
S[0. n)* = (1+p^n+p^(2n)+p^(3n)+p^((m-1)n))(S[0] + S[1] * p + S[2] * p^2 + . + S[n-1] * p^(n-1)))
Хэш на префиксе вычислять мы уже умеем, осталось решить подзадачу вычисления следующей суммы:
Ответ sum(a, k) = (a^k-1) / (a — 1) = (a^k — 1) * inverse(a-1, mod) — неверный, так как у четных чисел нет обратных в кольце по модулю 2^64 .
Пусть k — четное, например, k = 8 . Тогда:
sum(a,8) = 1+a+a^2+a^3+a^4+a^5+a^6+a^7 = (1+a)*(1+a^2+a^4+a^6) = (1+a) * sum(a^2, 4)
пусть k — нечетное, например, k = 7 . Тогда:
sum(a,7) = 1+a+a^2+a^3+a^4+a^5+a^6 = 1 + a * (1+a+a^2+a^3+a^4+a^5) = 1 + a * sum(a, 6)
Получили рекуррентные формулы, позволяющие вычислять значения sum(a, k) для любых a и k за O(log(k)) :
sum(a, 2*k) = (1+a) * sum(a^2, k) и sum(a, 2*k+1) = 1 + a * sum(a, 2*k) .
В случае простого же модуля предложенный способ вычисления суммы геометрической прогрессии быстрее в два раза, чем sum(a, k) = (a^k — 1) * inverse(a-1, mod) , так как второй способ вызывает функцию быстрого возведения в степень два раза. В случаях с хэшами ускорение в два раза может быть критично.
Осталось только сравнить sum(p^m, n) * pref(m) с sum(p^n, m) * pref(n) . Асимптотика решения O(n log(n)) по времени и O(n) по памяти. Исходный код.
На этом все. Надеюсь, этот пост поможет Вам активно применять хэширование и решать более сложные задачи. Буду рад любым комментариям, исправлениям и предложениям. В ближайших планах перевести этот пост на английский язык, поэтому нужны ссылки, где эти задачи можно сдать на английском языке. Возможно, к тому времени Вы внесете существенные корректировки и дополнения в этот пост. Ребята из Индии говорят, что пытались сидеть с гугл-переводчиком и переводить с русского языка посты про полиномиальный хэш и у них это плохо вышло. Делитесь другими задачами и, возможно, их решениями, а также решениями указанных задач не через хэши. Спасибо за внимание!
Полезные ссылки:

хэши, хэширование, tutorial, бинарный поиск, сортировка
Полиномиальные хеши и их применение
Здравствуй, хабр. Сегодня я напишу, как можно использовать полиномиальные хеши (далее просто хеши) при решении различных алгоритмических задач.
Введение
Начнем с определения. Пусть у нас есть строка s0..n-1. Полиномиальным хешем этой строки называется число h = hash(s0..n-1) = s0 + ps1 + p 2 s2 +… + p n-1 sn-1, где p — некоторое натуральное число (позже будет сказано, какое именно), а si — код i-ого символа строки s (почти во всех современных языках он записывается s[i] ).
Хеши обладают тем свойством, что у одинаковых строк хеши обязательно равны. Поэтому основная операция, которую позволяют выполнять хеши — быстрое сравнение двух подстрок на равенство. Конечно, чтобы сравнить 2 строки, мы можем написать подобную функцию (будем считать, что длины строк s и t совпадают и равны n):
boolean equals(char[] s, char[] t) < for (int i = 0; i < n; i++) if (s[i] != t[i]) < return false; >> return true; >Однако в худшем случае эта функция обязана проверить все символы, что дает асимптотику O(n).
Сравнение строк с помощью хешей
Теперь посмотрим, как справляются с этой задачей хеши. Так как хеш — это всего лишь число, для их сравнения нам потребуется O(1) времени. Правда, для того, чтобы посчитать хеш одной подстроки наивным способом, требуется O(n) времени. Поэтому потребуется немного повозиться с математическими формулами и научиться находить за O(n) хеши сразу всех подстрок. Давайте сравним подстроки sL..R и tX..Y (одинаковой длины). Пользуясь определением хеша, мы можем записать:
Проведем небольшие преобразования в левой части (в правой части все будет происходить аналогично). Запишем хеш подстроки s0..R, он нам понадобится:
Разобьем это выражение на две части…
… и вынесем из второй скобки множитель p L :
Выражение в первой скобке есть не что иное, как хеш подстроки s0..L-1, а во второй — хеш нужной нам подстроки sL..R. Итак, мы получили, что:
Отсюда вытекает следующая формула для hash(sL..R):
Аналогично, для второй нашей подстроки будет выполнено равенство hash(tX..Y) = (1 / p X )(hash(t0..Y) — hash(t0..X-1)).
Внимательно глядя на эти формулы, можно заметить, что для вычисления хеша любой подстроки нам необходимо знать лишь хеши префиксов этой строки s0..0, s0..1, . s0..n-2, s0..n-1. А, так как хеш каждого следующего префикса выражается через хеш предыдущего, их несложно посчитать линейным проходом по строке. Все сразу за O(n) времени. Степени числа p тоже надо заранее предпросчитать и сохранить в массиве.
// сохраняем в массиве степени числа p, которые нам могут понадобиться pow[0] = 1; for (int i = 1; i // считаем хеши префиксов строки s hs[0] = s[0]; for (int i = 1; i < n; i++) < hs[i] = hs[i - 1] + pow[i] * s[i]; >// считаем хеши префиксов строки t ht[0] = t[0]; for (int i = 1; i
Казалось бы, мы теперь во всеоружии и умеем сравнивать 2 любые подстроки за O(1). Но не все так просто: математические формулы нуждаются в некоторой доработке. К примеру, подобный код:
if ((hs[R] - hs[L - 1]) / pow[L] == (ht[Y] - ht[X - 1]) / pow[X])
-
Замечание первое: L (или X) может оказаться равным нулю, и при вычислении hs[L — 1] произойдет выход за границы массива. Однако если L равно нулю, то интересующий нас хеш подстроки sL..R хранится в точности в hs[R] . Поэтому правильнее вместо hs[L — 1] писать так:
L == 0 ? 0 : hs[L - 1]if ((hs[R] - (L == 0 ? 0 : hs[L - 1])) * pow[X] == (ht[Y] - (X == 0 ? 0 : ht[X - 1])) * pow[L])
Задачи, решаемые с помощью хешей
1. Сравнение подстрок
Первое, и главное, применение, как уже было сказано, это быстрое сравнение двух подстрок — на нем основываются все остальные алгоритмы с хешами. Код в прошлом разделе довольно громоздкий, поэтому я напишу более удобный код, который будет использоваться в дальнейшем.
Следующая функция вычисляет хеш подстроки sL..R, умноженный на p L :long getHash(long[] h, int L, int R) < long result = h[R]; if (L >0) result -= h[L - 1]; return result; >Теперь сравнение двух подстрок мы выполняем следующей строчкой:
if (getHash(hs, L, R) * pow[X] == getHash(ht, X, Y) * pow[L])
Умножение на степени числа p можно назвать «приведением к одной степени». Первый хеш был умножен на p L , а второй — на p X — значит, чтобы сравнение происходило корректно, их надо домножить на недостающий множитель.
Примечание: имеет смысл сначала проверить, совпадают ли длины подстрок. Если нет, то строки в принципе не могут быть равны, и тогда можно не проверять вышезаписанное условие.2. Поиск подстроки в строке за O(n + m)
Хеши позволяют искать подстроку в строке за асимптотически минимальное время. Это делает так называемый алгоритм Рабина-Карпа.
Пусть есть строка s длины n, в которой мы хотим найти все вхождения строки t длины m. Найдем хеш строки t (всей строки целиком) и хеши всех префиксов строки s, а затем будем двигаться по строке s окном длины m, сравнивая подстроки si..i+m-1.
Код:// считаем хеш строки t long ht = t[0]; for (int i = 1; i < m; i++) < ht += pow[i] * t[i]; >// проверяем все позиции for (int i = 0; i + m >3. Нахождение z-функции за O(n log n)
Z-функцией строки s называется массив z, i-ый элемент которого равен наидлиннейшему префиксу подстроки, начинающейся с позиции i в строке s, который одновременно является и префиксом всей строки s. Значение z-функции в нулевой позиции будем считать равным длине строки s, хотя некоторые источники принимают его за ноль (но это не критично).
Конечно, есть алгоритм нахождения z-функции за O(n). Но когда его не знаешь или не помнишь (а алгоритм довольно громоздкий), на помощь приходят хеши.
Идея следующая: для каждого i = 0, 1, . n-1 будем искать zi бинарным поиском, т.е. на каждой итерации сокращая интервал возможных значений вдвое. Это корректно, потому что равенство s0..k-1 = si..i+k-1 обязательно выполняется для всех k, меньших zi, и обязательно не выполняется для больших k.
int[] z = new int[n]; for (int i = 0; i < n; i++) < int left = 1, right = n - i; // текущий интервал значений while (left else < // если не совпадают, надо проверить меньшие значения right = middle - 1; >> >4. Поиск лексикографически минимального циклического сдвига строки за O(n log n).
Существует алгоритм Дюваля, который позволяет решать эту задачу за O(n), однако я знаю некоторых довольно сильных олимпиадных программистов, которые так и не разобрались в нем. Пока они будут в нем разбираться, мы снова применим хеши.
Алгоритм следующий. Сначала примем саму строку s за лучший (лексикографически минимальный) ответ. Затем для каждого циклического сдвига с помощью бинарного поиска найдем длину максимального общего префикса этого сдвига и текущего лучшего ответа. После этого достаточно сравнить следующие за этим префиксом символы и, если надо, обновить ответ.
Еще заметим, что для удобства здесь рекомендуется приписать строку s к самой себе — не придется делать операции взятия по модулю при обращениям к символам строки s. Будем считать, что это уже сделано.int bestPos = 0; for (int i = 1; i < n; i++) < int left = 1, right = n, length = 0; // находим length - длину максимального общего префикса while (left else < right = middle - 1; >> // сравниваем следующий за общим префиксом символ и обновляем ответ // если длина этого префикса равна n, // то текущий циклический сдвиг совпадает с минимальным, // и ответ обновлять не нужно if (length < n && s[i + length] < s[bestPos + length]) < bestPos = i; >>Примечание: по сути, внутри цикла for написан компаратор, сравнивающий лексикографически два циклических сдвига. Используя его, можно за O(n log 2 n) отсортировать все циклические сдвиги.
5. Поиск всех палиндромов в строке за O(n log n).
Опять же, существует решение этой задачи за O(n). И опять мы будем решать ее с помощью хешей.
Подстрока sL..R называется палиндромом, если sL = sR, sL+1 = sR-1, и т.д. Если выражаться русским языком, то это означает, что она читается одинаково как слева направо, так и справа налево.
Возможно, вы уже знаете или догадались, при чем тут хеши. Помимо массива h[] , содержащего хеши для подстрок s0..0, s0..1, . s0..n-2, s0..n-1, посчитаем второй массив rh[] (для «перевернутой» строки), который будем обходить справа налево. Он будет содержать соответственно хеши s0..n-1, s1..n-1, . sn-2..n-1, sn-1..n-1:
rh[n - 1] = s[n - 1]; for (int i = n - 2, j = 1; i >= 0; i--, j++)
Должно уже быть понятно, как за O(1) определять, является ли строка палиндромом. Я напишу функцию getRevHash(), аналогичную getHash(), а потом приведу необходимое условие сравнения. Вы можете самостоятельно убедиться в правильности этого выражения, проделав математические выкладки, подобные тем, что приводились в начале статьи.
long getRevHash(long[] rh, int L, int R) < long result = rh[L]; if (R < n - 1) result -= rh[R + 1]; return result; >boolean isPalindrome(long[] h, long[] rh, long[] pow, int L, int R)
Теперь рассмотрим позицию i в строке. Пусть существует палиндром нечетной длины d с центром в позиции i (в случае четной длины — с центром между позициями i-1 и i). Если обрезать с его краев по одному символу, он останется палиндромом. И так можно продолжать, пока его длина не станет равной нулю.
Таким образом, нам достаточно для каждой позиции хранить 2 значения: сколько существует палиндромов нечетной длины с центром в позиции i, и сколько существует палиндромов четной длины с центром между позициями i-1 и i. Обратите внимание, что эти 2 значения абсолютно независимы друг от друга, и обрабатывать их надо отдельно.Применим, как и ранее, бинарный поиск:
int[] oddCount = new int[n]; for (int i = 0; i < n; i++) < int left = 1, right = min(i + 1, n - i); while (left else < right = middle - 1; >> > int[] evenCount = new int[n]; for (int i = 0; i < n; i++) < int left = 1, right = min(i, n - i); while (left else < right = middle - 1; >> >Теперь можно, к примеру, найти общее количество всех палиндромов в строке, или длину максимального палиндрома. Длина максимального нечетного палиндрома с центром в позиции i считается как 2 * oddCount[i] — 1 , а максимального четного палиндрома — 2 * evenCount[i] .
Еще раз напомню, что нужно быть внимательнее с палиндромами четной и нечетной длины — как правило, их надо обрабатывать независимо друг от друга.Хеши в матрицах
Наконец, рассмотрим более изощренные применения хешей. Теперь наше пространство будет двумерным, и сравнивать мы будем подматрицы. К счастью, хеши очень хорошо обобщаются на двумерный случай (трехмерных и более я не встречал).
Теперь вместо числа p и массива pow у нас будут два различных числа p, q и два массива pow1 , pow2 : по одному числу и по одному массиву в каждом направлении: по вертикали и горизонтали.
Хешем матрицы a0..n-1, 0..m-1 будем называть сумму по всем i = 0, . n-1, j = 0. m-1 величин p i q j aij.
Теперь научимся считать хеши подматриц, содержащих левый верхний элемент a00. Очевидно, что hash(a0..0, 0..0) = a00. Почти так же очевидно, что для всех j = 1. m-1 hash(a0..0, 0..j) = hash(a0..0, 0..j-1) + q j a0j, для всех i = 1. n-1 hash(a0..i, 0..0) = hash(a0..i-1, 0..0) + p i ai0. Это напрямую вытекает из одномерного случая.
Как посчитать хеш подматрицы a0..i, 0..j? Можно догадаться, что hash(a0..i, 0..j) = hash(a0..i-1, 0..j) + hash(a0..i, 0..j-1) — hash(a0..i-1, 0..j-1) + p i q j aij. Эту формулу можно получить из следующих соображений: сложим все слагаемые (хеш, напомню, это сумма нескольких слагаемых), составляющие хеш подматриц a0..i-1, 0..j и a0..i, 0..j-1. При этом мы два раза учли слагаемые, составляющие подматрицу a0..i-1, 0..j-1, так что вычтем их, чтобы они учитывались один раз. Теперь не хватает только элемента aij, умноженного на соответствующие степени p и q.
Примерно из тех же соображений, что и в первой части статьи (вы уже заметили причастность формулы включений-исключений?) строится функция для вычисления хеша произвольной подматрицы ax1..x2, y1..y2:
long getMatrixHash(long[][] h, int x1, int x2, int y1, int y2) < long result = h[x2][y2]; if (x1 >0) result -= h[x1 - 1][y2]; if (y1 > 0) result -= h[x2][y1 - 1]; if (x1 > 0 && y1 > 0) result += h[x1 - 1][y1 - 1]; return result; >Эта функция возвращает хеш подматрицы ax1..x2, y1..y2, умноженный на величину p x1 q y1 .
А сравнение двух подматриц aax1..ax2, ay1..ay2 и abx1..bx2, by1..by2 выполняется с помощью следующего выражения:
if (getMatrixHash(h, ax1, ax2, ay1, ay2) * pow1[bx1] * pow2[by1] == getMatrixHash(h, bx1, bx2, by1, by2) * pow1[ax1] * pow2[ay1])
Хешами также можно решать задачи, связанные с нахождением самой большой симметричной подматрицы и похожие на них. Причем я не знаю сравнимых с хешами по скорости и простоте алгоритмов, выполняющих эту работу. Здесь используются те же принципы, что и при поиске палиндромов в одномерном случае (т.е. считать «реверснутые» хеши справа налево и снизу вверх, проводить бинпоиск отдельно для подматриц четной и нечетной длины). Предлагаю попробовать решить эту задачу самостоятельно — эта статья вам поможет!
Заключение
Итак, в нашем распоряжении есть довольно неплохой аппарат, позволяющий делать многие вещи либо с лучшей возможной асимптотикой, либо лишь чуть-чуть (в логарифм раз) медленнее, чем специализированные алгоритмы. Неплохо, не так ли?
- алгоритмы
- олимпиадные задачи
- хеширование
- строки
- поиск подстроки в строке
- сравнение строк