Преобразование и приведение примитивных типов
Иногда возникают ситуации, когда необходимо переменной одного типа присвоить значение переменной другого типа. Например:
int i = 11; byte b = 22; i = b;В Java существует два типа преобразований — автоматическое преобразование (неявное) и приведение типов (явное преобразование).
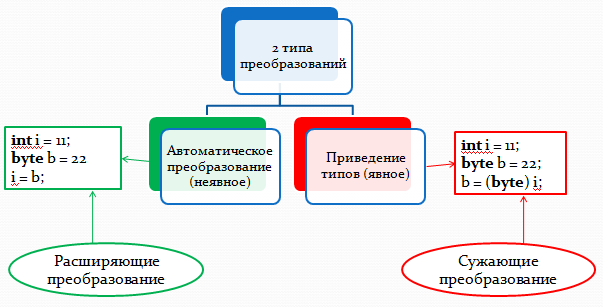
1. Автоматическое преобразование типов Java
Рассмотрим сначала автоматическое преобразование. Если оба типа совместимы, их преобразование будет выполнено в Java автоматически. Например, значение типа byte всегда можно присвоить переменной типа int, как это показано в предыдущем примере.
Для автоматического преобразования типа должно выполняться два условия:
- оба типа должны быть совместимы
- длина целевого типа должна быть больше длины исходного типа
В этом случае происходит преобразование с расширением.
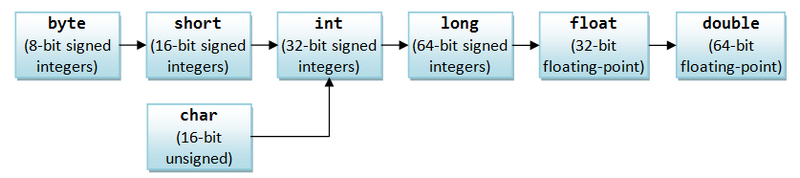
Следующая схема показывает расширяющее преобразование в Java:

Сплошные линии обозначают преобразования, выполняемые без потери данных. Штриховые линии говорят о том, что при преобразовании может произойти потеря точности.
Например, тип данных int всегда достаточно велик, чтобы хранить все допустимые значения типа byte , поэтому никакие операторы явного приведения типов в данном случае не требуются. С точки зрения расширяющего преобразования числовые типы данных, в том числе целочисленные и с плавающей точкой, совместимы друг с другом. В то же время не существует автоматических преобразований числовых типов в тип char или boolean . Типы char и boolean также не совместимы друг с другом.
Стоит немного пояснить почему, к примеру тип byte не преобразуется автоматически (не явно) в тип char, хотя тип byte имеет ширину 8 бит, а char — 16. То же самое касается и преобразования типа short в char . Это происходит потому, что byte и short знаковые типы данных, а char беззнаковый. Поэтому в данном случае требуется использовать явное приведение типов, поскольку компилятору надо явно указать, что вы знаете чего хотите и как будет обрабатываться знаковый бит типов byte и short при преобразовании к типу char .
Поведение величины типа char в большинстве случаев совпадает с поведением величины целого типа, следовательно, значение типа char можно использовать везде, где требуются значения int или long . Однако напомним, что тип char не имеет знака, поэтому он ведет себя отлично от типа short , несмотря на то что диапазон обоих типов равен 16 бит.
2. Приведение типов Java
Несмотря на все удобство автоматического преобразования типов, оно не в состоянии удовлетворить все насущные потребности. Например, что делать, если значение типа int нужно присвоить переменной типа byte ? Это преобразование не будет выполняться автоматически, поскольку длина типа byte меньше, чем у типа int . Иногда этот вид преобразования называется сужающим преобразованием, поскольку значение явно сужается, чтобы уместиться в целевом типе данных.
Чтобы выполнить преобразование двух несовместимых типов данных, нужно воспользоваться приведением типов. Приведение — это всего лишь явное преобразование типов. Общая форма приведения типов имеет следующий вид:
(целевой_тип) значениегде параметр целевой_тип обозначает тип, в который нужно преобразовать указанное значение.
Например, в следующем фрагменте кода тип int приводится к типу byte :
int i = 11; byte b = 22; b = (byte) i;Рассмотрим пример преобразования значений с плавающей точкой в целые числа. В этом примере дробная часть значения с плавающей точкой просто отбрасывается (операция усечения):
double d = 3.89; int a = (int) d; //Результат будет 3При приведении более емкого целого типа к менее емкому старшие биты просто отбрасываются:
int i = 323; byte b = (byte) i; //Результат будет 67При приведении более емкого значения с плавающей точкой в целое число происходит усечение и отбрасывание старших битов:
double d = 389889877779.89; short s = (short) d; //Результат будет -13. Автоматическое продвижение типов в выражениях
Помимо операций присваивания, определенное преобразование типов может выполняться и в выражениях.
В языке Java действуют следующие правила:
- Если один операнд имеет тип double , другой тоже преобразуется к типу double .
- Иначе, если один операнд имеет тип float , другой тоже преобразуется к типу float .
- Иначе, если один операнд имеет тип long , другой тоже преобразуется к типу long .
- Иначе оба операнда преобразуются к типу int .
- В выражениях совмещенного присваивания (+=,-=,*=,/=) нет необходимости делать приведение.
При умножении переменной b1 ( byte ) на 2 ( int ) результат будет типа int . Поэтому при попытке присвоить результат в переменную b2 ( byte ) возникнет ошибка компиляции. Но при использовании совмещенной операции присваивания (*=), такой проблемы не возникнет:
byte b1 = 1; byte b2 = 2 * b1; //Ошибка компиляции int i1 = 2 * b1; b2 *= 2;В следующем примере тоже возникнет ошибка компиляции — несмотря на то, что складываются числа типа byte , результатом операции будет тип int , а не short .
Преобразование типов в Java
Преобразование типов — это тема, которая может показаться сложной начинающим программировать на Java. Однако, заверим Вас, на самом деле всё просто. Главное понять по каким законам происходит взаимодействие между переменными и помнить об этом при написании программ. Итак, давайте разбираться.
В Java существует 2 типа преобразований — картинка Вам в помощь:

Напомним, что вся «Вселенная Java» состоит из:
- примитивных типов (byte, short, int, long, char, float, double, boolean)
- объектов
В данной статье мы:
- рассмотрим преобразование типов для примитивных типов переменных
- преобразование объектов (String, Scanner и др.) в этой статье не рассматривается, поскольку с объектами происходит отдельная «магия» — это тема для отдельной статьи.
Автоматическое преобразование
Ну, что ж, давайте попробуем разобраться что такое «автоматическое преобразование».
Помните, когда мы рассматривали типы переменных (в статье «Переменные в Java. Создание переменной»), мы говорили, что переменная — это некоторый «контейнер» , в котором может храниться значение для дальнейшего использования в программе. Также мы говорили о том, что каждый тип переменной имеет свой диапазон допустимых значений и объем занимаемой памяти. Вот она табличка, где это все было расписано:

Так вот, к чему мы, собственно говоря, клоним. К тому, что совсем не просто так Вам давались диапазоны допустимых значений и объем занимаемой памяти ��
Давайте, сравним, например:
1. byte и short. byte имеет меньший диапазон допустимых значений, чем short. То есть byte это как бы коробочка поменьше, а short — это коробочка побольше. И значит, мы можем byte вложить в short.
2. byte и int . byte имеет меньший диапазон допустимых значений, чем int. То есть byte это как бы коробочка поменьше, а int — это коробочка побольше. И значит, мы можем byte вложить в int.
3. int и long. int имеет меньший диапазон допустимых значений, чем long. То есть int это как бы коробочка поменьше, а long — это коробочка побольше. И значит, мы можем int вложить в long.

Это и есть пример автоматического преобразования. Это можно схематически изобразить в виде вот такой картинки:

Давайте рассмотрим как это работает на практике.
Пример №1
Код №1 — если Вы запустите это код на своем компьютере, в консоли будет выведено число 15
Pro Java
Преобразование типов в Java это достаточно большая тема, но мы постараемся рассмотреть ее как можно более полно и вместе с тем компактно. Частично мы уже касались этой темы когда рассматривали примитивные типы Java.
В Java возможны преобразования между целыми значениями и значениями с плавающей точкой. Кроме того, можно преобразовывать значения целых типов и типов с плавающей точкой в значения типа char и наоборот, поскольку каждый символ соответствует цифре в кодировке Unicode. Фактически тип boolean является единственным примитивным типом в Java, который нельзя преобразовать в другой примитивный тип. Кроме того, любой другой примитивный тип нельзя преобразовать в boolean.
Преобразование типов в Java бывает двух видов: неявное и явное.
Неявное преобразование типов выполняется в случае если выполняются условия:
- Оба типа совместимы
- Длина целевого типа больше или равна длине исходного типа
Во всех остальных случаях должно использоваться явное преобразование типов.
Так же существуют два типа преобразований:
- Расширяющее преобразование (widening conversion)
- Сужающее преобразование (narrowing conversion)
Расширяющее преобразование (widening conversion) происходит, если значение одного типа преобразовывается в более широкий тип, с большим диапазоном допустимых значений. Java выполняет расширяющие преобразования автоматически, например, если вы присвоили литерал типа int переменной типа double или значение пепременной типа char переменной типа int. Неявное преобразование всегда имеет расширяющий тип .
Но у тут могут быть свои небольшие грабельки. Например если преобразуется значение int в значение типа float. И у значения int в двоичном представлении больше чем 23 значащих бита, то возможна потеря точности, так как у типа float под целую часть отведено 23 бита. Все младшие биты значения int, которые не поместятся в 23 бита мантиссы float, будут отброшены, поэтому хотя порядок числа сохраниться, но точность будет утеряна. То же самое справедливо для преобразования типа long в тип double.
Расширяющее преобразование типов Java можно изобразить еще так:

Сплошные линии обозначают преобразования, выполняемые без потери данных. Штриховые линии говорят о том, что при преобразовании может произойти потеря точности.
Стоит немного пояснить почему, к примеру тип byte не преобразуется автоматически (не явно) в тип char, хотя тип byte имеет ширину 8 бит, а char 16, тоже самое касается и преобразования типа short в char. Это происходит потому, что byte и short знаковые типы данных, а char без знаковый. Поэтому в данном случае требуется использовать явное приведение типов, поскольку компилятору надо явно указать что вы знаете чего хотите и как будет обрабатываться знаковый бит типов byte и short при преобразовании к типу char.
Поведение величины типа char в большинстве случаев совпадает с поведением величины целого типа, следовательно, значение типа char можно использовать везде, где требуются значения int или long. Однако напомним, что тип char не имеет знака, поэтому он ведет себя отлично от типа short, несмотря на то что диапазон обоих типов равен 16 бит.
short s = ( short ) 0xffff ; // Данные биты представляют число –1
char c = ‘\uffff’ ; // Те же биты представляют символ юникода
int i1 = s ; // Преобразование типа short в int дает –1
int i2 = c ; // Преобразование char в int дает 65535
Сужающее преобразование (narrowing conversion) происходит, если значение преобразуется в значение типа, диапазон которого не шире изначального. Сужающие преобразования не всегда безопасны: например, преобразование целого значения 13 в byte имеет смысл, а преобразование 13000 в byte неразумно, поскольку byte может хранить только числа от −128 до 127. Поскольку во время сужающего преобразования могут быть потеряны данные, Java компилятор возражает против любого такого преобразования, даже если преобразуемое значение укладывается в более узкий диапазон указанного типа:
int i = 13 ;
byte b = i ; // Компилятор не разрешит это выражение
Единственное исключение из правила – присвоение целого литерала (значения типа int) переменной byte или short, если литерал соответствует диапазону переменной.
Сужающее преобразование это всегда явное преобразование типов .
Явное преобразование примитивных типов
Оператором явного преобразования типов или точнее говоря приведения типов являются круглые скобки, внутри которых указан тип, к которому происходит преобразование – (type). Например:
int i = 13 ;
byte b = ( byte ) i ; // Принудительное преобразование int в byte
i = ( int ) 13.456 ; // Принудительное преобразование литерала типа double в int 13
Приведение примитивных типов чаще всего используют для преобразования значений с плавающей точкой в целые числа . При этом дробная часть значения с плавающей точкой просто отбрасывается (то есть значение с плавающей точкой округляется по направлению к нулю, а не к ближайшему целому числу). По существу берется только целочисленная часть вещественного типа и она уже приводится к целевому типу целочисленного числа.
При приведении более емкого целого типа к менее емкому старшие биты просто отбрасываются . По существу это равнозначно операции деления по модулю приводимого значения на диапазон целевого типа (например для типа byte это 256).
Слишком большое дробное число при приведении к целому превращается в MAX_VALUE или MIN_VALUE .
Слишком большой double при приведении к float превращается в Float.POSITIVE_INFINITY или Float.NEGATIVE_INFINITY .
Таблица представленная ниже представляет собой сетку, где для каждого примитивного типа указаны типы, в которые их можно преобразовать, и способ преобразования. Буква N в таблице означает невозможность преобразования. Буква Y означает расширяющее преобразование, которое выполняется автоматически. Буква С означает сужающее преобразование, требующее явного приведения. Наконец, Y* означает автоматическое расширяющее преобразование, в процессе которого значение может потерять некоторые из наименее значимых разрядов. Это может произойти при преобразовании int или long во float или double. Типы с плавающей точкой имеют больший диапазон, чем целые типы, поэтому int или long можно представить посредством float или double. Однако типы с плавающей точкой являются приближенными числами и не всегда могут содержать так много значащих разрядов в мантиссе, как целые типы.

Автоматическое расширение типов в выражениях
Так же стоит еще раз упомянуть об автоматическом повышении (расширении) типов в выражениях. Мы с этим уже сталкивались когда рассматривали целочисленные типы данных и операции над ними, но все же стоит и тут напомнить, чтобы усвоилось еще лучше и к тому же это имеет непосредственное отношение к данной теме. В примере ниже знак @ означает любой допустимый оператор, например +, –, *, / и т.п.

То есть, все целочисленные литералы в выражениях, а так же типы byte, short и char расширяются до int . Если, как описано выше, в выражении не присутствуют другие, более большие типы данных (long, float или double). Поэтому приведенный выше пример вызовет ошибку компиляции, так как переменная c имеет тип byte, а выражение b+1, в результате автоматического повышения имеет тип int.
Неявное приведение типов в выражениях совмещенного присваивания
Хоть данный раздел и относится к неявному преобразованию (приведению) типов, его объяснение мы привели тут, поскольку в данном случае так же работает и автоматическое расширение типов в выражениях, а затем уже неявное приведение типов. Вот такой кордебалет. Пример ниже я думаю все разъяснит. Так же как и в предыдущем объяснении знак @ означает любой допустимый оператор, например +, –, *, / и т.п.

Это стоит пояснить на простом примере:
byte b2 = 50 ;
b2 = b2 * 2 ; // не скомпилируется
b2 *= 2 ; //скомпилируется, хотя и равнозначна b2 = b2 * 2
Вторя строка, приведенная в примере не скомпилируется из-за автоматического расширения типов в выражениях, так как выражение b2*2 имеет тип int, так как происходит автоматическое расширение типа (целочисленные литералы в выражении всегда int). Третья же строка спокойно скомпилируется, так как в ней сработает неявное приведение типов в совмещенном выражении присваивания.
Boxing/unboxing – преобразование примитивных типов в объекты обертки
Boxing и unboxin – это тоже достаточно большая тема, но она достаточно простая.
По существу boxing и unboxing это преобразование примитивных типов в объекты обертки и обратно .
Для объектов оберток примитивных типов применимо все что было сказано выше.
Об классах обертках упоминалось в таблицах, при разборе каждого из примитивных типов. Но тогда это было лишь упоминание в таблице.
Так вот, для каждого примитивного типа есть его старший брат, и он совсем не примитивный, а является настоящим классом, с полями и методами. И для каждой такой парочки возможно автоматическое преобразование.

Обычно, если в программе есть много математических вычислений, то лучше пользоваться примитивными типами, так как это быстрее и экономнее с точки зрения ресурсов, но иногда бывает необходимость преобразовать примитивный тип в объект.
Приведу простой пример:
int i3 ;
byte b2 = 3 ;
Byte myB ;
myB = b2 ;
myB ++;
b2 = myB ;
i3 = myB ;
Если пока не понятно зачем это нужно, то это не страшно, просто завяжите узелок на память.
Примитивные типы в Java: Не такие уж они и примитивные


Разработку приложений можно рассматривать как работу с некоторыми данными, а точнее — их хранение и обработку. Сегодня хотелось бы затронуть первый ключевой аспект. Как данные хранятся в Java? Тут у нас есть два возможные формата: ссылочный и примитивный тип данных. Давайте поговорим о видах примитивных типов и возможностях работы с ними (как ни крути, это фундамент наших знаний языка программирования). Примитивные типы данных Java — это основа, на которой держится всё. Нет, я нисколько не преувеличиваю. У Oracle примитивам посвящён отдельный Tutorial: Primitive Data TypesНемного истории. Вначале был ноль. Но ноль — это скучно. И тогда появился bit (бит). Почему его так назвали? Назвали его так от сокращения «binary digit» (двоичное число). То есть у него есть только два значения. А так как был ноль, то логично, что теперь стало или 0 или 1. И стало жить веселее. Биты начали собираться в стаи. И эти стаи стали называть byte (байт). В современном мире byte = 2 в третьей степени, т.е. 8. Но, оказывается, так было не всегда. Существует множество догадок, легенд и слухов, откуда пошло название byte. Кто-то считает, что всё дело в кодировках того времени, а кто-то считает, что так было выгоднее считать информацию. Байт — это наименьшая адресуемая часть памяти. Именно байты имеют уникальные адреса в памяти. Есть легенда о том, что ByTe это сокращение от Binary Term — машинное слово. Машинное слово – если говорить просто, это количество данных, которые процессор может обработать за одну операцию. Раньше размер машинного слова совпадал с наименьшей адресуемой памятью. В Java, переменные могут хранить только значение байтов. Как я и говорил выше, в Java существует два вида переменных:
- примитивные типы java, хранят непосредственно значение байтов данных (подробнее типы этих примитивов мы разберем немного ниже);
- ссылочный тип, хранит байты адреса объекта в Heap, то есть через эти переменные мы получаем доступ непосредственно к самому объекту(такой себе пульт от объекта)
Java byte
Итак, история подарила нам байт – минимальный объём памяти, который мы можем использовать. И состоит он из 8 бит. Самый маленький целый тип данных в java – byte. Это знаковый 8-битовый тип. Что это значит? Давайте считать. 2 ^ 8 будет 256. Но что же делать, если мы хотим отрицательное число? И решили разработчики Java, что двоичный код «10000000» будет обозначать -128, то есть старший бит (самый левый бит) будет обозначать, отрицательное ли число. Двоичное «0111 1111» равняется 127. То есть 128 никак не обозначить, т.к. это будет -128. Полный расчёт приведён в этом ответе: Why is the range of bytes -128 to 127 in Java? Чтобы понять как получаются числа, стоит посмотреть на картинку:

Соответственно, чтобы вычислить размер 2^(8-1) = 128. Значит минимальная граница (а она с минусом) будет -128. А максимальная 128 – 1 (вычитаем ноль). То есть максимум будет 127. На самом деле, с типом byte работаем мы не так часто на «высоком уровне». В основном это обработка «сырых» данных. Например, при работе с передачей данных по сети, когда данные это набор 0 и 1, переданных через какой-то канал связи. Или при чтении данных из файлов. Так же могут быть использованы при работе со строкам и кодировками. Пример кода:
public static void main(String []args) < byte value = 2; byte shortByteValue = 0b10; // 2 System.out.println(shortByteValue); // Начиная с JDK7 мы можем разделять литералы подчёркиваниями byte minByteValue = (byte) 0B1000_0000; // -128 byte maxByteValue = (byte) 0b0111_1111; // 127 byte minusByteValue = (byte) 0b1111_1111; // -128 + 127 System.out.println(minusByteValue); System.out.println(minByteValue + " to " + maxByteValue); >
Кстати, не стоит думать, что использование типа byte будет снижать потребление памяти. В основном byte используется для уменьшения расхода памяти при хранении данных в массивах (например, хранение данных, полученных по сети в некотором буфере, который будет реализован в виде массива байт). А вот при операциях над данными использование byte не оправдает ваши ожидания. Связано это с реализацией Java Virtual Machine (JVM). Так как большинство систем 32 или 64 разрядные, то byte и short при вычислениях будут приведены к 32-битному int, о котором мы поговорим дальше. Так проще производить вычисления. Подробнее см. Is addition of byte converts to int because of java language rules or because of jvm?. В ответе даны так же ссылки на JLS (Java Language Specification). Кроме того, использование byte в неправильном месте может привести к неловким моментам:
public static void main(String []args) < for (byte i = 1; i >
Тут будет зацикливание. Потому что значение счётчика дойдёт до максимума (127), произойдёт переполнение и значение станет -128. И мы никогда не выйдем из цикла.
short
Лимит значений из byte довольно мал. Поэтому, для следующего типа данных решили увеличить количество бит вдвое. То есть теперь не 8 бит, а 16. То есть 2 байта. Значения можно посчитать так же. 2^(16-1) = 2 ^ 15 = 32768. Значит, диапазон от -32768 до 32767. Используют его совсем редко для каких-либо специальных случаев. Как говорит нам документация языка Java: «you can use a short to save memory in large arrays».
int
Вот мы и добрались до самого частоиспользуемого типа. Занимает он 32 бита, или 4 байта. В общем, мы продолжаем удваивать. Диапазон значений от -2^31 до 2^31 – 1.
Максимальное значение int
Максимальное значение int 2147483648 – 1, что совсем не мало. Как выше было указано, для оптимизации вычислений, т.к. современным компьютерам с учетом их разрядности удобнее считать, данные могут быть неявно преобразованы к int. Вот простой пример:
byte a = 1; byte b = 2; byte result = a + b;
Такой безобидный код, а мы получим ошибку: «error: incompatible types: possible lossy conversion from int to byte». Придётся исправить на byte result = (byte)(a + b); И ещё один безобидный пример. Что будет если запустим следующий код?
int value = 4; System.out.println(8/value); System.out.println(9/value); System.out.println(10/value); System.out.println(11/value);
А мы получим вывод
2 2 2 2
*звуки паники* Дело обстоит в том, что при работе с int значениями остаток отбрасывается, оставляя только целую часть(в таких случая лучше уж использовать double).
long
Продолжаем удваивать. 32 умножаем на 2 и получаем 64 бита. По традиции, это 4 * 2, то есть 8 байт. Диапазон значений от -2^63 до 2^63 – 1. Более чем достаточно. Данный тип позволяет считать большие-большие числа. Часто используется при работе со временем. Или с большими расстояниями, например. Для обозначения того, что число это long после числа ставят литерал L – Long. Пример:
long longValue = 4; longValue = 1l; // Не ошибка, но плохо читается longValue = 2L; // Идеально
Хочется забежать вперёд. Далее мы будем рассматривать тот факт, что для примитивов есть соответствующие обёртки, которые дают возможность работать с примитивами как с объектами. Но есть интересная особенность. Вот пример: На том же Tutorialspoint online compiler можете проверить такой вот код:
public class HelloWorld < public static void main(String []args) < printLong(4); >public static void printLong(long longValue) < System.out.println(longValue); >>
Данный код работает без ошибок, всё хорошо. Но стоит в методе printLong заменить тип с long на Long (т.е. тип становится не примитивным, а объектным), как становится джаве непонятно, какой параметр мы передаём. Она начинает считать, что передаётся int и будет ошибка. Поэтому, в случае с методом необходимо будет явно указывать 4L. Очень часто long используется как ID при работе с базами данных.
Java float и Java double
Данные типы называются типами с плавающей точкой. То есть это не целочисленные типы. Тип float является 32битным (как int), а double называется типом с двойной точностью, поэтому он 64битный (умножаем на 2, всё как мы любим). Пример:
public static void main(String []args) < // float floatValue = 2.3; lossy conversion from double to float float floatValue = 2.3F; floatValue = 2.3f; double doubleValue = 2.3; System.out.println(floatValue); double cinema = 7D; >
А вот пример разницы значений (из-за точности типов):
public static void main(String []args)
Данные примитивные типы используются в математике, например. Вот доказательство, константа для вычисления числа PI. Ну и вообще можно посмотреть API класса Math. Вот что ещё должно быть важно и интересно: даже в документации сказано: «This data type should never be used for precise values, such as currency. For that, you will need to use the java.math.BigDecimal class instead.Numbers and Strings covers BigDecimal and other useful classes provided by the Java platform.». То есть деньги в float и double не надо вычислять. Пример про точность на примере работы в NASA: Java BigDecimal, Dealing with high precision calculations Ну и чтобы самим прочувствовать:
public static void main(String []args)
Выполните этот пример, а потом добавьте 0 перед цифрами 5 и 4. И вы увидите весь ужас) Есть интересный доклад на русском про float и double в тему: https://youtu.be/1RCn5ruN1fk Примеры работы с BigDecimal можно увидеть здесь: Make cents with BigDecimal Кстати, float и double могут вернуть не только число. Например, пример ниже вернёт Infinity (т.е. бесконечность):
public static void main(String []args) < double positive_infinity = 12.0 / 0; System.out.println(positive_infinity); >
А этот вернёт NAN:
public static void main(String []args) < double positive_infinity = 12.0 / 0; double negative_infinity = -15.0 / 0; System.out.println(positive_infinity + negative_infinity); >
Про бесконечность понятно. А что такое NaN? Это Not a number, то есть результат не может быть высчитан и не является числом. Вот пример: Мы хотим вычислить квадратный корень из -4. Квадратный корень из 4 это 2. То есть 2 надо возвести квадрат и тогда мы получим 4. А что надо возвести в квадрат, чтобы получить -4? Не получится, т.к. если положительное число будет, то оно и останется. А если было отрицательное, то минус на минус даст плюс. То есть это не вычисляемо.
public static void main(String []args) < double sqrt = Math.sqrt(-4); System.out.println(sqrt + 1); if (Double.isNaN(sqrt)) < System.out.println("So sad"); >System.out.println(Double.NaN == sqrt); >
Вот ещё отличный обзор на тему чисел с плавающей точкой: Где ваша точка?
Java boolean
Следующий тип – булевский (логический тип). Он может принимать значения только true или false, которые являются ключевыми словами. Используется в логических операциях, таких как циклы while, и в ветвлении при помощи if, switch. Что тут можно интересного узнать? Ну, например, теоретически, нам достаточно 1 бита информации, 0 или 1, то есть true или false. Но на самом деле Boolean будет занимать больше памяти и это будет зависеть от конкретной реализации JVM. Обычно на это тратится столько же, сколько на int. Как вариант – использовать BitSet. Вот краткое описание из книги «Основы Java»: BitSet
Java char
- Таблица Unicode символов
- Таблица символов ASCII

Пример в студию:
public static void main(String[] args) < char symbol = '\u0066'; // Unicode symbol = 102; // ASCII System.out.println(symbol); >
Кстати, char, являясь по своей сути всё таки числом, поддерживает математические действия, такие как сумма. А иногда это может привести к забавным последствиям:
public class HelloWorld < public static void main(String []args)< String costForPrint = "5$"; System.out.println("Цена только для вас " + + costForPrint.charAt(0) + getCurrencyName(costForPrint.charAt(1))); >public static String getCurrencyName(char symbol) < if (symbol == '$') < return " долларов"; >else < throw new UnsupportedOperationException("Not implemented yet"); >> >
Настоятельно советую проверить в онлайн IDE от tutorialspoint. Когда я увидел этот пазлер на одной из конференций мне это подняло настроение. Надеюсь, Вам пример тоже понравится) UPDATED: Это было на Joker 2017, доклад: «Java Puzzlers NG S03 — Откуда вы все лезете-то?!».
Литералы
- Десятеричная система: 10
- Шестнадцатеричная система: 0x1F4, начинается с 0x
- Восьмеричная система: 010, начинается с нуля.
- Двоичная система (начиная с Java7): 0b101, начинается с 0b
int costInDollars = 08;
Эта строчка кода не скомпилируется:
error: integer number too large: 08
Кажется, что за бред. А теперь вспомним про двоичную и восьмеричную системы. В двоичной системе нет двойки, т.к. есть два значения (начиная с 0). А восьмеричной системе есть 8 значений, начиная с нуля. То есть самого значения 8 нет. Поэтому и ошибка, которая на первый взгляд кажется абсурдной. И чтобы вспомнить вот «вдогонку» правила перевода значений:

Классы-обертки

Примитивы в Java имеют свои классы-обертки, чтобы можно было работать с ними как с объектами. То есть, для каждого примитивного типа существует, соответствующий ему ссылочный тип. Классы-обертки являются immutable (неизменяемыми): это означает, что после создания объекта его состояние — значение поля value — не может быть изменено. Классы-обертки задекларированы как final: объекты, так сказать, read-only. Также хотелось бы упомянуть, что от этих классов невозможно наследоваться. Java автоматически делает преобразования между примитивными типами и их обертками:
Integer x = 9; // autoboxing int n = new Integer(3); // unboxing
Процесс преобразования примитивных типов в ссылочные (int->Integer) называется autoboxing (автоупаковкой), а обратный ему — unboxing (автораспаковкой). Эти классы дают возможность сохранять внутри объекта примитив, а сам объект будет вести себя как Object (ну как любой другой объект). При всём этом мы получаем большое количество разношерстных, полезных статических методов, как например — сравнение чисел, перевод символа в регистр, определение того, является ли символ буквой или числом, поиск минимального числа и т.п. Предоставляемый набор функционала зависит лишь от самой обертки. Пример собственной реализации обёртки для int:
public class CustomerInt < private final int value; public CustomerInt(int value) < this.value = value; >public int getValue() < return value; >>
В основном пакете, java.lang, уже есть реализации классы Boolean, Byte, Short, Character, Integer, Float, Long, Double, и нам не нужно ничего городить своего, а только переиспользовать готовое. К примеру, такие классы дают нам возможность создать, скажем, List , ведь List должен содержать только объекты, чем примитивы не являются. Для преобразования значения примитивного типа есть статические методы valueOf, например, Integer.valueOf(4) вернёт объект типа Integer. Для обратного преобразования есть методы intValue(), longValue() и т. п. Компилятор вставляет вызовы valueOf и *Value самостоятельно, это и есть суть autoboxing и autounboxing. Как выглядит пример автоупаковки и автораспаковки, представленный выше, на самом деле:
Integer x = Integer.valueOf(9); int n = new Integer(3).intValue();
Подробнее про автоупаковку и автораспаковку можно почитать вот в этой статье.
Приведение типов
При работе с примитивами существует такое понятие как приведение типов, одно из не очень приятных свойств C++, тем не менее приведение типов сохранено и в языке Java. Иногда мы сталкиваемся с такими ситуациями, когда нам нужно совершать взаимодействия с данными разных типов. И очень хорошо, что в некоторых ситуациях это возможно. В случае с ссылочными переменными, там свои особенности, связанные с полиморфизмом и наследованием, но сегодня мы рассматриваем простые типы и соответственно приведение простых типов. Существует преобразование с расширением и преобразование сужающее. Всё на самом деле просто. Если тип данных становится больше (допустим, был int, а стал long), то тип становится шире (из 32 бит становится 64). И в этом случае мы не рискуем потерять данные, т.к. если влезло в int, то в long влезет тем более, поэтому данное приведение мы не замечаем, так как оно осуществляется автоматически. А вот в обратную сторону преобразование требует явного указания от нас, данное приведение типа называется — сужение. Так сказать, чтобы мы сами сказали: «Да, я даю себе отчёт в этом. В случае чего — виноват сам».
public static void main(String []args)
Чтобы потом в таком случае не говорили что «Ваша Джава плохая», когда получат внезапно -128 вместо 128 ) Мы ведь помним, что в байте 127 верхнее значение и всё что находилось выше него соответственно можно потерять. Когда мы явно превратили наш int в байт, то произошло переполнение и значение стало -128.
Область видимости

Это то место в коде, где данная переменная будет выполнять свои функции и хранить в себе какое-то значение. Когда же эта область закончится, переменная перестанет существовать и будет стерта из памяти и. как уже можно догадаться, посмотреть или получить ее значение будет невозможно! Так что же это такое — область видимости? Область определяется «блоком» — вообще всякой областью, замкнутой в фигурные скобки, выход за которые сулит удаление данных объявленных в ней. Или как минимум — сокрытие их от других блоков, открытых вне текущего. В Java область видимости определяется двумя основными способами:
- Классом.
- Методом.
Как я и сказал, переменная не видна коду, если она определена за пределами блока, в котором она была инициализирована. Смотрим пример:
int x; x = 6; if (x >= 4) < int y = 3; >x = y;// переменная y здесь не видна!
И как итог мы получим ошибку:
Error:(10, 21) java: cannot find symbol symbol: variable y location: class com.javaRush.test.type.Main
Области видимости могут быть вложенными (если мы объявили переменную в первом, внешнем блоке, то во внутреннем она будет видна).
Заключение
- Целые числа: byte, short, int, long — представляют собой целые числа со знаком.
- Числа с плавающей точкой — эта группа включает себе float и double — типы, которые хранят числа с точностью до определённого знака после запятой.
- Булевы значения — boolean — хранят значения типа «истина/ложь».
- Символы — в эту группу входит типа char.