Elasticsearch + Kibana (но без Logstash)
При изучении состояния продакшен сервера и поиска возможных ошибок и их причин используются логи приложения. Всё, что в коде выглядит как log.info/debug/error/trace, потом чаще всего попадает в один или несколько файлов, размер которых может достигать нескольких гигабайт в сутки, если слишком увлекаться логированием, например, всех SQL запросов и параметров (show_sql=true). Чтобы такие файлы не блокировали приложение, логи ротируются: файл обрезается до, скажем, 1гб, архивируется, а приложение продолжает писать логи в старый файл, но уже пустой. Такие файлы скапливаются и получают добавку к имени: .1.log.gz, .2.log.gz и так далее до заданного лимита по количеству или сроку давности.

Что же делать если нужно исследовать ошибку, случившуюся два-три дня назад? Опцию открывать файлы по одному в редакторе я не рассматриваю, ведь за неделю может легко накопиться десять или сотня таких файлов. На помощь приходит команда grep/zgrep: пишем незамысловатые команды наподобие Думаю, вы уловили идею: чтобы понять, как обрабатывался один запрос к сервису, нужно распарсить файл, разбить по потокам и разделить на части от строчки «СТАРТ» до строчки «ФИНИШ». Эти части уже можно было бы загрузить в elasticsearch, но не каждую строчку в отдельности.
Распарсить подобные логи на Java несложно, а вот как и можно ли вообще сделать такое в logstash, я не уверен. Поэтому я оставил logstash до лучших времен и подключился к elasticsearch напрямую. Существует проект Spring Data Elasticsearch, который упрощает задачу, но на текущий момент он не поддерживает elasticsearch последней версии, поэтому я использую готовый REST клиент, являющийся частью elasticsearch. При загрузке данных такими блоками можно кроме самого текста выделять важные параметры: время обработки, права доступа, успешно или ошибка, какие-то существенные данные для анализа. После этого по данным параметрам можно будет осуществлять поиск и агрегацию, строить красивые графики и диаграммы. Да, эти параметры приходится доставать из лога с помощью регулярных выражений. Зато не нужно никак менять работающее приложение, достаточно научиться скачивать логи с продакшен сервера.
В качестве примера я проведу небольшое исследование производительности работы с файлами. Программа будет создавать новый файл, записывать в него данные и вычитывать, измеряя затраченное время, а потом удалять файл. Информация о каждом полном цикле будет сохраняться в одной записи в elasticsearch, что в его терминологии называется документом. Всё это будет происходить в многопоточном режиме и количество потоков будет увеличиваться со временем. После чего я покажу базовые способы работы c этими данными в Kibana.
Код тут. Нужно установить Kibana и Elasticsearch 7 версии. Для этого достаточно распаковать архивы и запустить. Вот как это выглядит у меня:
C:\dev\ELK\kibana-7.5.2-windows-x86_64\bin\kibana.bat C:\dev\ELK\elasticsearch-7.5.2\bin\elasticsearch.bat
Теперь нужно научиться сохранять данные в elasticsearch. Он принимает данные в формате JSON, поэтому определим DTO класс:
public class WriteReadBenchmarkResult private String id; private String threadName; private int nThreads; private long writeMillis; private long readMillis; private long fileSizeBytes; private boolean failed = false; private String errorMessage = ""; @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd'T'HH:mm:ssZ"); private OffsetDateTime timestamp = OffsetDateTime.now(); //. getters, setters
Ничего особенного, кроме специфического формата для даты, чтобы elasticsearch определил это поле как время, а не как строку.
Обращаться к elasticsearch будем с помощью High level REST client. Создаём экземпляр клиента с настройками по умолчанию:
@Bean public RestHighLevelClient client() final CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials( AuthScope.ANY, new UsernamePasswordCredentials("elastic", "changeme")); RestClientBuilder builder = RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")) .setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)); RestHighLevelClient client = new RestHighLevelClient(builder); return client; >
Сохраняем коллекцию DTO объектов. Сразу использую bulk операцию, потому что, как правило, в реальности количество записей будет исчисляться миллионами. Индекс «samples-writrateread» в elasticsearch создастся автоматически.
for (WriteReadBenchmarkResult writeReadBenchmarkResult : batch) IndexRequest indexSingleRequest = new IndexRequest("samples-writrateread"); indexSingleRequest.id(writeReadBenchmarkResult.getId()); indexSingleRequest.source(mapper.writeValueAsString(writeReadBenchmarkResult), XContentType.JSON); bulkRequest.add(indexSingleRequest); > BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
Теперь запустим тест, чтобы загрузить данные для анализа. Код в FileWriteReadRandomTaskIT, он довольно длинный, но ничего примечательного. Просто записываем в файл около 30 мегабайт, вычитываем и удаляем. Повторяем операцию 300 раз, а потом увеличиваем количество потоков на 1 и всё по новой. В тестовом запуске получилось пройти от 1 до 29 потоков за пару часов. Теперь переходим к изучению этой информации в Kibana.
Сначала нужно указать на тот индекс, который мы использовали, создав index pattern. Например, по ссылке http://localhost:5601/app/kibana#/management/kibana/index_pattern?_g=(). Либо в левой панели самый нижний значок — настройки. На шаге два (Step 2 of 2: Configure settings) выбираем timestamp, чтобы все наши данные имели временную метку, всё остальное происходит по умолчанию само. А именно: Kibana определяет набор полей и их типы. Например, поле readMillis — число, а значит его можно сравнивать, суммировать, находить максимумы и минимумы.
Я не показываю детально работу с интерфейсом Kibana, думаю для этого эффективнее всего установить и начать нажимать на все кнопки подряд, а также посмотреть пару самых простых сценариев на Youtube. Первое время я пользовался только текстовым поиском, а когда немного освоился, то начал пробовать фильтры, диаграммы и графики.
Итак, поиск. В терминах Kibana — Discover. Всегда нужно указать временные рамки. Пустой запрос означает все данные, простой текст означает индексный поиск по текстовым полям, а указание полей позволяет точно искать записи («nThreads:8» — всё, что запускалось в 8 потоков). Посмотрим все операции и медленные чтения.
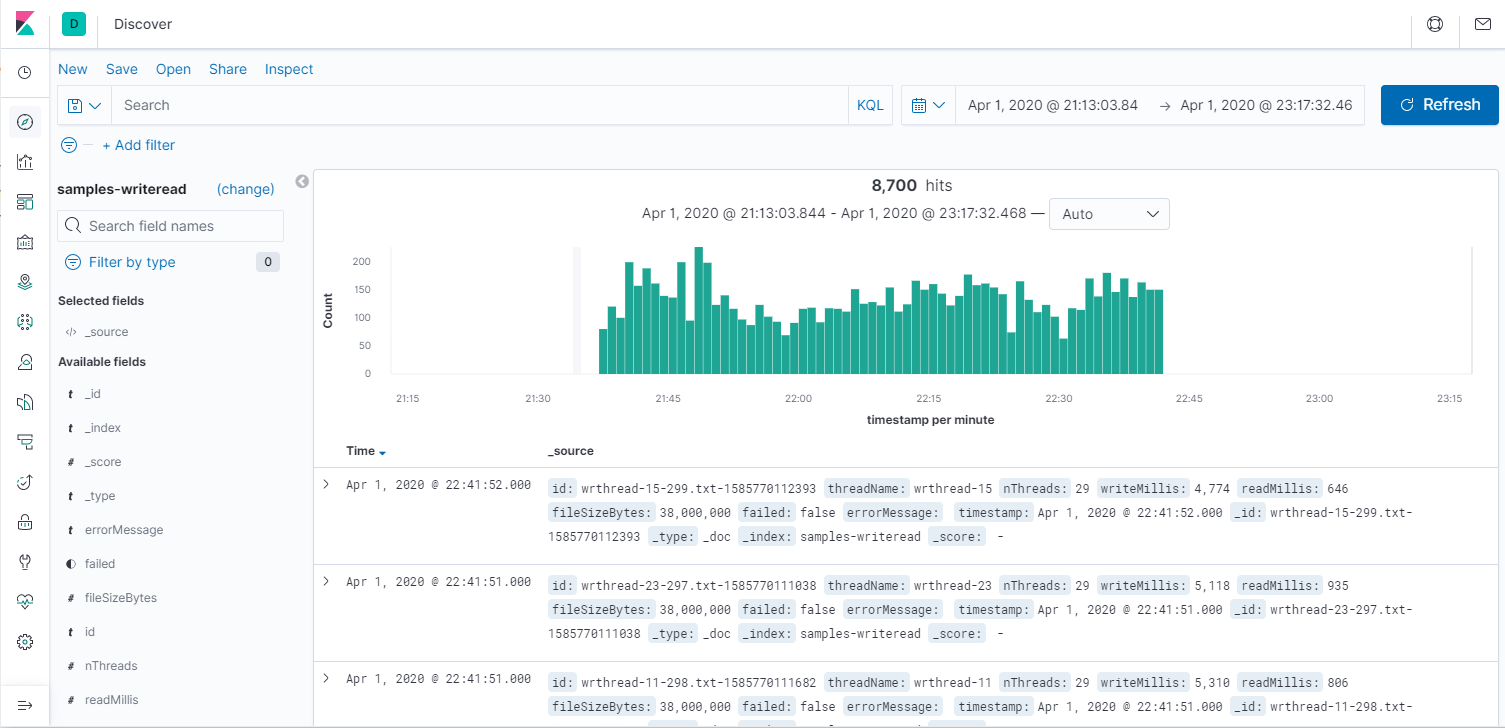
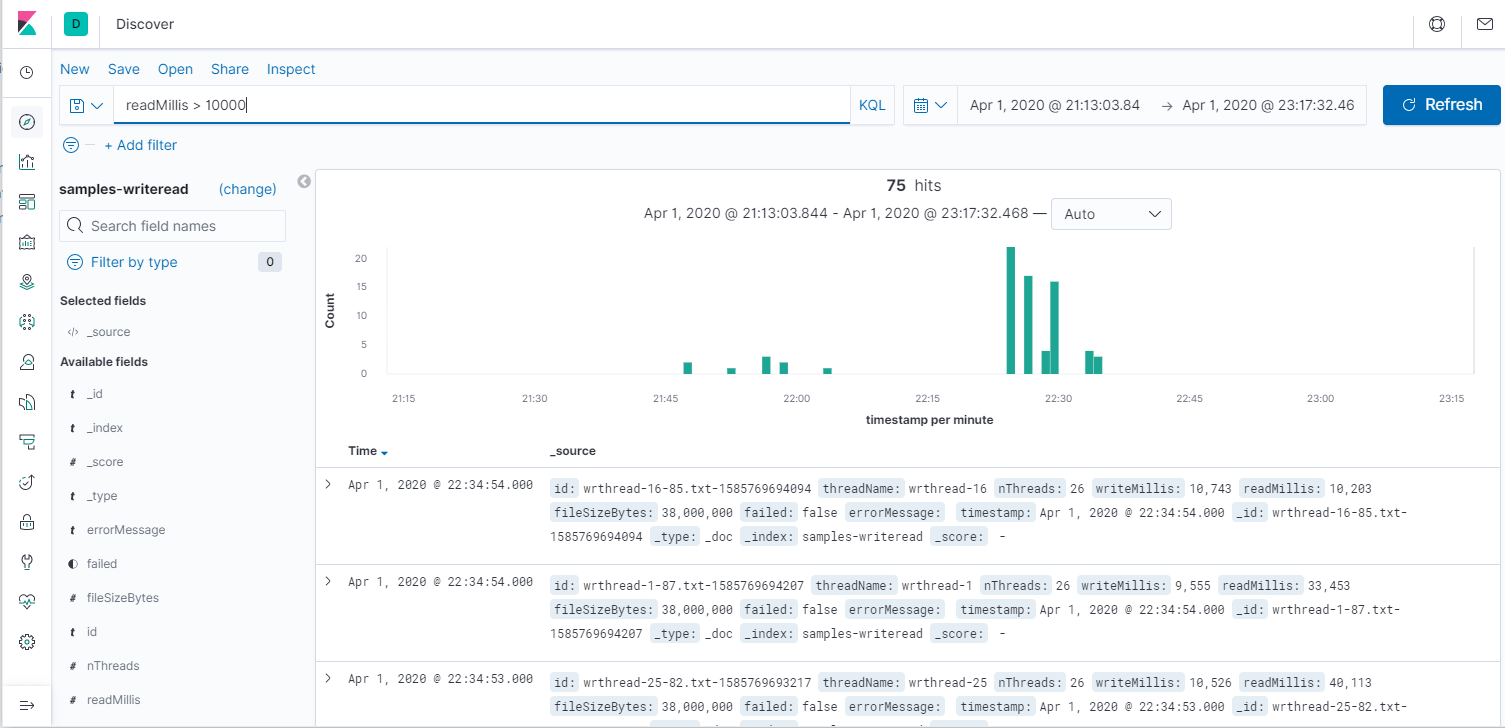
По сравнению в анализом данных командой grep, это уже космос. Давайте теперь посмотрим средние значения на графике. Для этого идём в Visualization -> Lines. Ось Х — Date histogram, то есть агрегация за промежуток времени: секунда, минута, день. Ось Y — Average/Min/Max/Count и и прочее. Первый график за всё время, второй — его начало (от 1 до 10 потоков.) На графике среднее время чтения и записи за 30 секунд, а также количество потоков, но я не смог его масштабировать, поэтому приходится наводить мышкой и на скриншотах не видно. Третий график — Count, показывает пропускную способность системы.
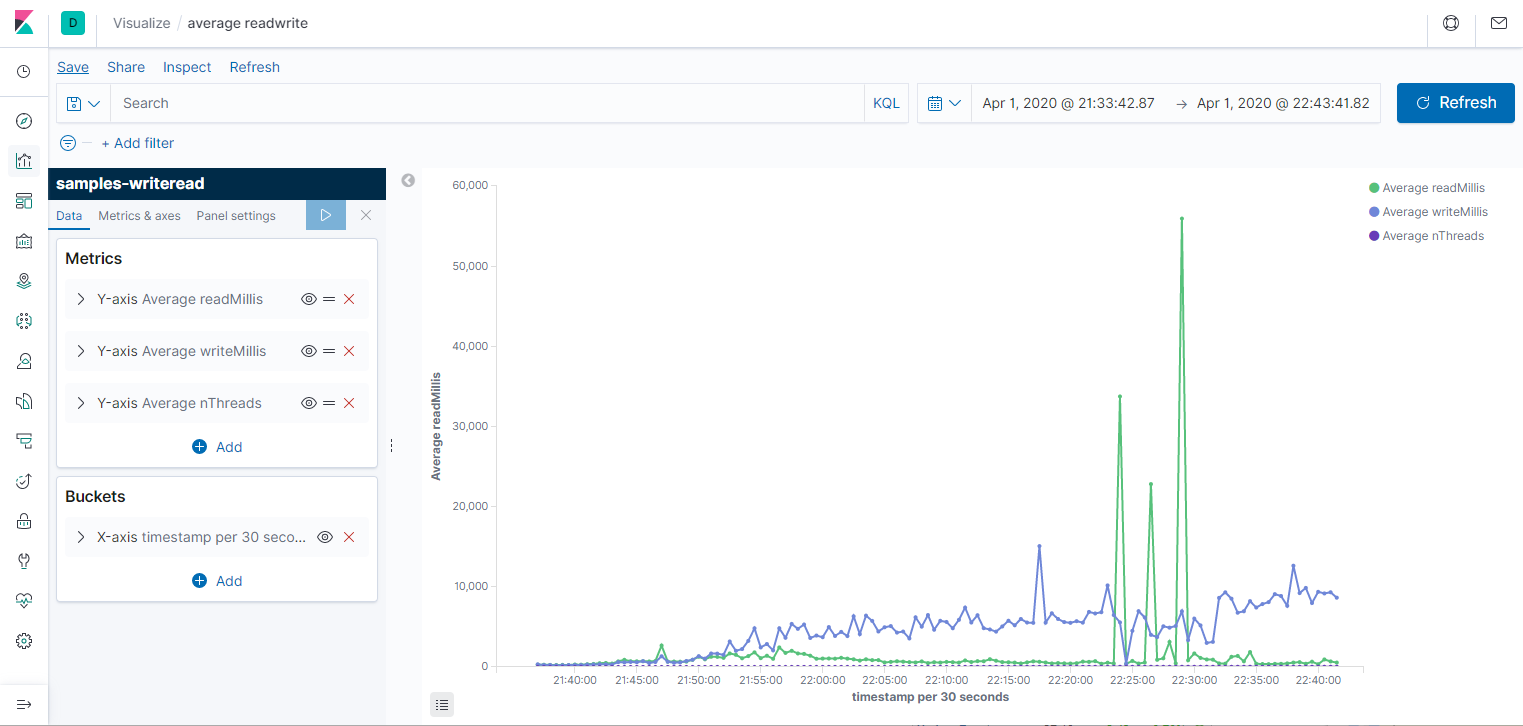
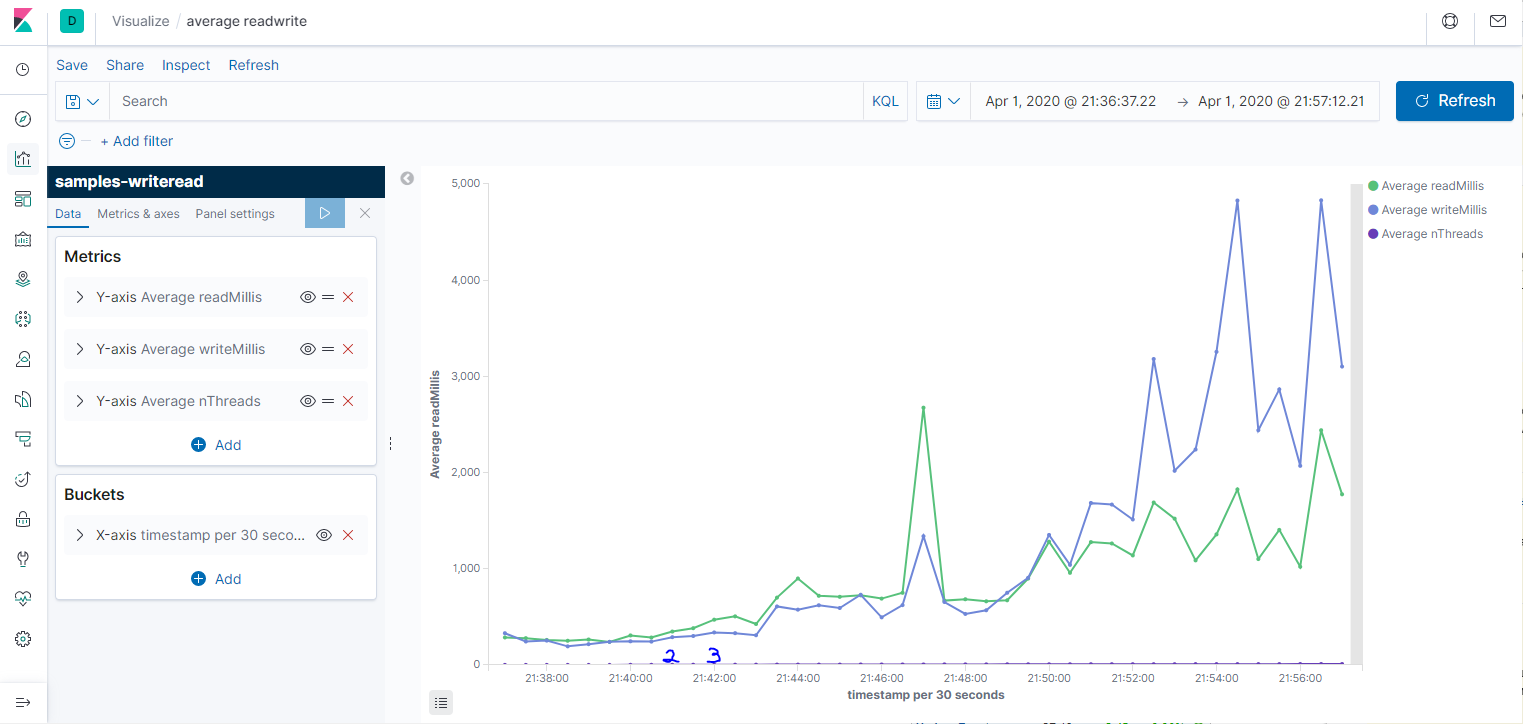
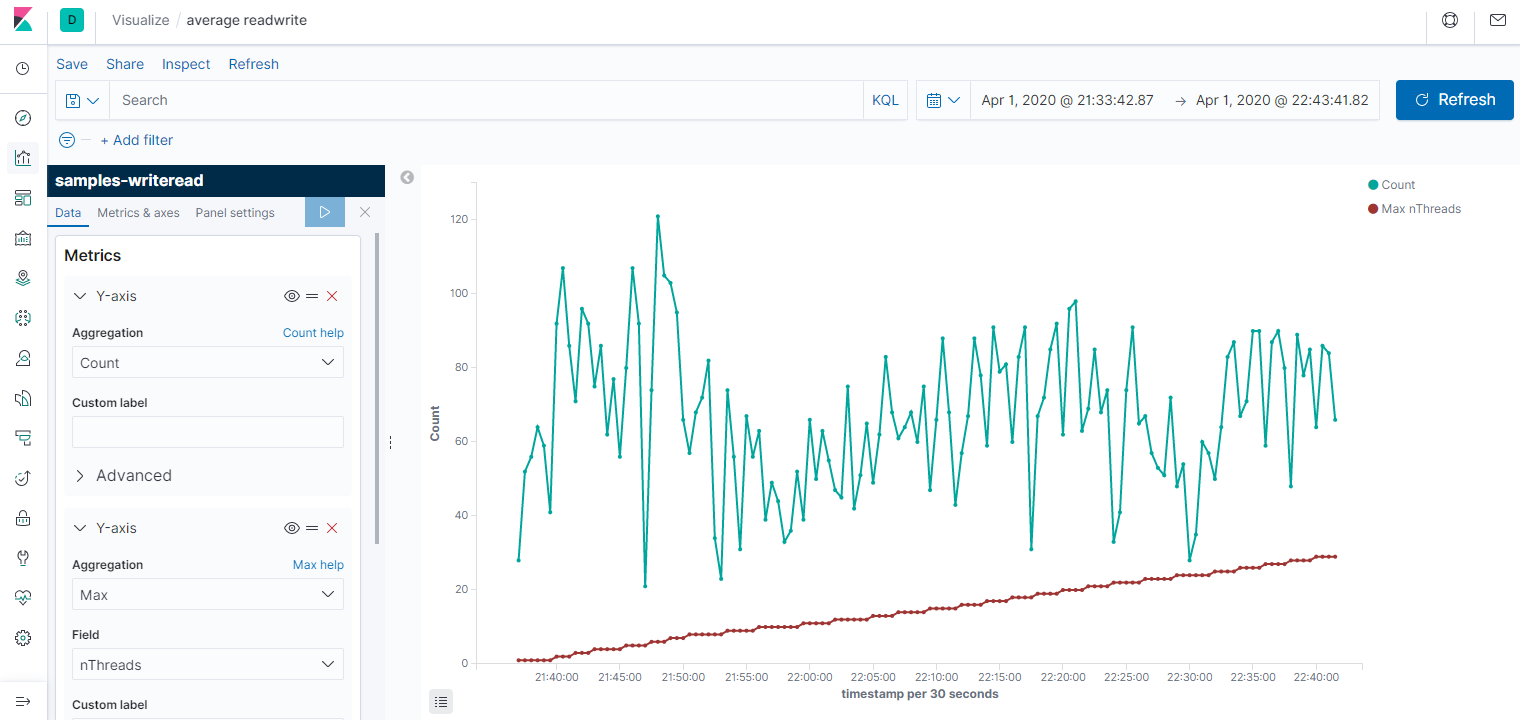
Делаю несколько выводов: во-первых, параметры недостаточно стабильны, чтобы им можно было серьёзно доверять. Во-вторых, с количеством потоков заметно растёт время записи и чтения. Время записи в среднем растёт сильнее. В третьих, при большом количестве потоков происходили очень неприятные пики до 170 секунд на чтение (если смотреть max, а не average). Возможно, ноутбук нагрузился какой-то запланированной работой в это время. Третий график вообще намекает на то, что степень параллелизма никак не влияет на пропускную способность.
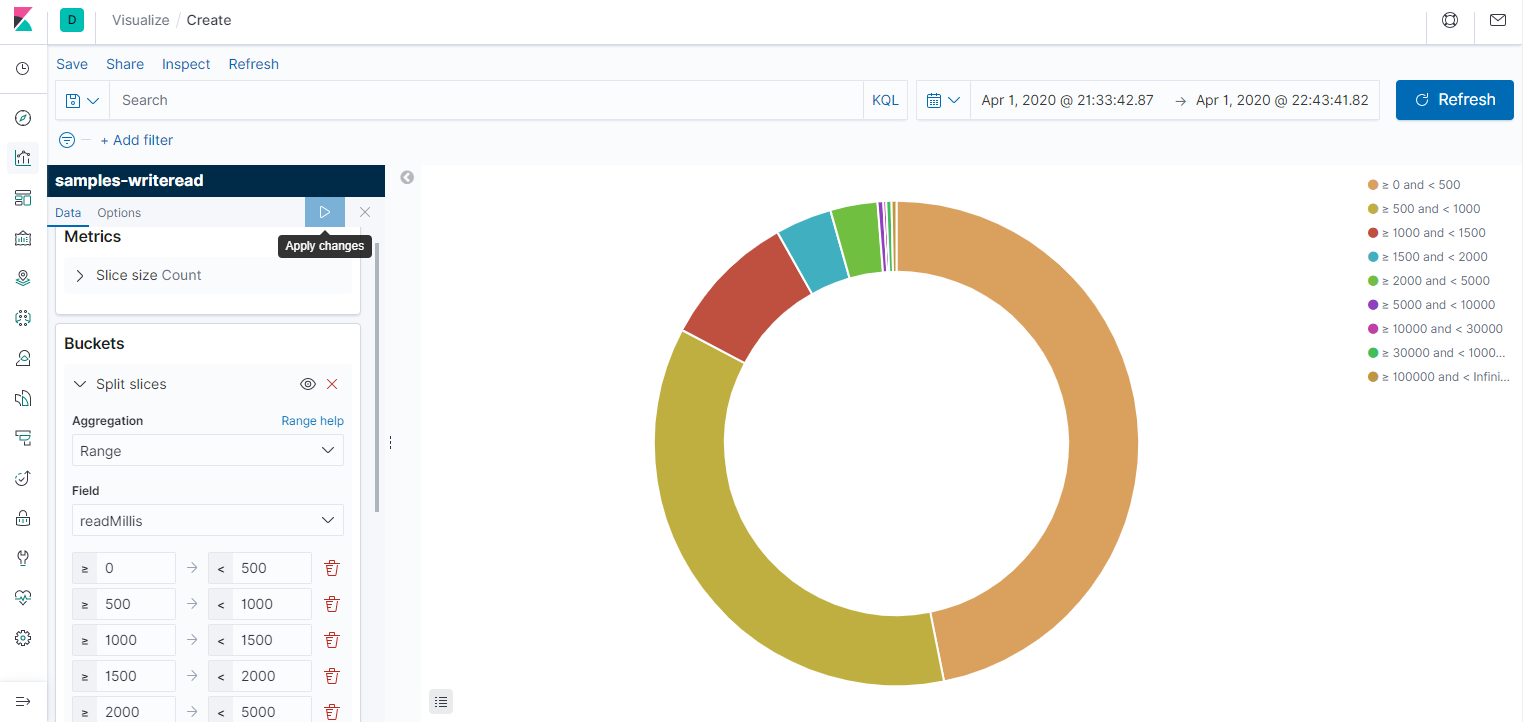
Результат ожидаемый. Если бы вместо жёсткого диска производилась работа с сетью, особенно с источником, который отвечает долго, но размер ответа небольшой, то пропускная способность росла бы почти линейно хоть до 100 потоков. Хотя результатом может стать DDOS источника данных. Думаю, ускорение можно было бы получить, если бы вместо одного жёсткого диска работа бы велась с несколькими. Так или иначе, цель — знакомство с elasticsearch и kibana, а такое мини-исследование производится просто ради спортивного интереса. Напоследок покажу диаграмму типа Pie, просто она мне нравится. Видно, что большинство чтений укладывается в секунду, а из них половина — в полсекунды.
Заключение
В первую очередь, я думаю, elasticsearch + kibana в таком использовании будут полезны тем, кто часто использует команду grep по однотипным логам. Обычно это старые системы, в которых нет времени или необходимости использовать готовые полнофункциональные решения, где всё уже интегрировано и настроено. Второе применение — это произвести более глубокий анализ данных, в особенности, логов, минимальными усилиями.
Не ведется error.log apache2
Все директивы, касательно html-ошибок и прочего включены, результат: access.log:
46.62.83.9 - - [16/Jan/2016:13:06:41 +0100] "POST /dir/expected_catcher.php HTTP/1.1" 200 290 "http://site/dir/" "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2618.8 Safari/537.36" 185.71.77.5 - - [16/Jan/2016:13:06:55 +0100] "POST /dir2/demo_catcher.php HTTP/1.1" 200 250 "-" "Apache-HttpClient/4.3.5 (java 1.5)" [Sat Jan 16 13:06:55 2016] [error] [client 185.71.77.5] PHP Notice: Undefined index: test_notification in /var/www/dir2/catcher.php on line 17 В expected_catcher.php у нас есть ошибка, ее не получается отловить из-за логов. Предположения касательно причин уже иссякли, ничего к сожалению не помогает.
Логи web-сервера apache
Логи web-сервера делятся на два типа: логи ошибок и логи доступа к сайту.
Логи сервера , в том числе логи apache хранятся в каталоге /var/log/ . Логи apache в зависимости от ОС могут иметь такие названия:
- FreeBSD это файлы httpd-error.log и httpd-access.log
- GNU/Debian (Ubuntu) это подкаталог apache2 и в нём файлы: error.log и access.log
- CentOS это подкаталог httpd и в нём файлы: access.log и error.log
Для панели ISPManager 4.
При использовании панели ispmanager, текущие логи виртуалхостов (доменов), созданных в панели, расположены в папке /var/www/httpd-logs/ в виде файлов имядомена.access.log и имядомена.error.log.
Файлы, расположенные в этой папке являются хард-линками на текущие логи, расположенные по адресу /var/www/имя_пользователя/data/logs.
Если была включена ротация логов в панели ispmanager, то в папке /var/www/имя_пользователя/data/logs также лежат сжатые файлы ротированных логов, в зависимости от настроек ротирования. Формат этих файлов выглядит как имядомена.access.log.x.gz и имядомена.error.log.x.gz, где «x» — порядковый номер архивного файла от 0 (самые новые архивы). Ротацию для нагруженных сайтов мы рекомендуем выставлять в панели на один час и с сохранением от 14 до 24 файлов, для ненагруженных сайтов можно оставлять ротацию по умолчанию.
Для анализа этих логов Вы можете использовать утилиты командной строки cat, tail, head. Для архивных логов в этом и других примерах вместо cat необходимо использовать zcat.
Также мы не рекомендуем использовать для просмотра логов текстовые редакторы, так как в случае логов большого размера это может привести к зависанию редактора и большой нагрузке на процессор.
Например, для анализа обновлений текущего лога сайта Вы можете использовать утилиту tail
tail -f /var/www/httpd-logs/имядомена.access.log
Для выхода из режима просмотра нажмите ctrl+c
Для полного просмотра лога можете воспользоваться связкой команд
cat /var/www/httpd-logs/имядомена.access.log | less
Для вывода самых активных айпи адресов со статистикой запросов можно использовать подобный шаблон команды
cat /var/www/httpd-logs/имядомена.access.log | awk ‘< print $1 >‘ | sort | uniq -c | sort -nr | head
Возможные проблемы.
(все нижеописанные операции Вы выполняете на свой страх и риск и возможна потеря логов. Рекомендуем при необходмиости скопировать логи в отдельную папку)
Если логи в папке /var/www/httpd-logs/ логи не обновляются и имеют неактуальные даты, скорее всего повредилась связь хард-линков. Необходимо пересоздать хардлинки для нормального логгирования. Для этого выполните следующие команды:
rm -f /var/www/httpd-logs/*
rm -f /var/www/*/data/logs/*.log
/usr/local/ispmgr/sbin/mgrctl -m ispmgr user | awk » | awk -F= » | sh
service httpd restart (Centos)
service apache2 restart (Debian/Ubuntu)
Если логи в папке /var/www/httpd-logs/ занимают много места, проверьте, выполняется ли ротация логов. Для этого выполните команду
/usr/local/ispmgr/sbin/rotate
После этого проверьте работу планировщика cron
- Как изменить ДНС сервера для моего домена?
- Реселлерская программа по регистрации доменов для клиентов VPS и физических серверов.
- Мой дамп mysql-базы занимает больше, чем разрешено заливать через phpMyAdmin. Что делать?
- Мой сайт на VDS выдает ошибку PHP типа «Allowed memory size of X bytes exhausted (tried to allocate Y bytes)»
- Сайт выдает ошибку «Call to undefined function. «
- Сайт выдает ошибку «Can’t connect to database server» или подобную.
- Сайт работает, но очень медленно.
- Сервер DNS second.freehsot.com.ua что это и зачем?
- Как выполнить перезагрузку физического сервера?
- Как заказать дополнительный IP адрес?
- Можно ли перейти на более производительный физический сервер без перестановки системы?
- Как продлить услугу сервера?
- Я забыл свой пароль на FTP от сервера резервных копий. Что делать?
- Настройка мониторинга веб сервера apache с помощью модуля mod_status
- Сервера с IPMI
- Мой провайдер заблокировал 25 порт, не могу подключится к своему серверу.
- Подключение по VPN к серверу с IPMI
- Ошибка, порт 25 не доступен. SMTP, проверка с помощью telnet
- Диагностировка с WinMTR
- Логи web-сервера apache
- Ошибка недоверенное соединение
- Восстановление баз данных MySQL с таблицами myisam и innodb
- Установка панели Vesta и размещение сайта на примере wordpress
- Настройка кеширования в Worpdress с помощью плагина W3 Total Cache и memcached
не менять формат логов
Пересылаю логи Apache на удаленный сервер syslog-ng, где они записываются в файл.
Можно ли не менять формат лога при записи, на удаленном сервере syslog-ng добавляет дату и ip?
WinLin2 ★★
05.02.20 16:50:05 MSK
template apache_access_log < template("$MSG\n"); >; destination apache_access_log < file('/var/log/$HOST/apache/access.log' template(apache_access_log)); >; spirit ★★★★★
( 05.02.20 17:44:22 MSK )
Ответ на: комментарий от spirit 05.02.20 17:44:22 MSK
Исходный лог на сервере Apache:
111.222.111.222 — — [05/Feb/2020:20:35:10 +0300] «GET / HTTP/1.0» 200 4692
Лог на сервере syslog-ng:
без template:
Feb 5 20:15:42 10.1.1.1 111.222.111.222 — — [05/Feb/2020:20:15:42 +0300] «GET / HTTP/1.0» 200 4692
template:
— — [05/Feb/2020:20:35:10 +0300] «GET / HTTP/1.0» 200 4692
Обрезается адрес клиента.
WinLin2 ★★
( 05.02.20 20:49:22 MSK ) автор топика
Ответ на: комментарий от WinLin2 05.02.20 20:49:22 MSK
Правильная настройка такая:
template(«$PROGRAM $MESSAGE\n»)