Построение полигона, гистограммы, кумуляты, огивы
Для наглядности строят различные графики статистического распределения, и, в частности, полигон и гистограмму.
Полигон
Полигоном частот называют ломаную, отрезки которой соединяют точки , а на оси ординат – соответствующие им частоты , а на оси ординат – соответствующие им относительные частоты (частости) Пример 1
Построить полигон частот и полигон относительных частот (частостей):
| 2 | 7 | 8 | 15 | 16 | 17 |
| Решение |
Вычислим относительные частоты (частости):

Полигон относительных частот

В случае интервального ряда для построения полигона в качестве берутся середины интервалов.
Гистограмма
В случае интервального статистического распределения целесообразно построить гистограмму.
Гистограммой частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиною , а высоты (в случае равных интервалов) должны быть пропорциональны частотам. При построении гистограммы с неравными интервалами по оси ординат наносят не частоты, а плотность частоты . Это необходимо сделать для устранения влияния величины интервала на распределение и иметь возможность сравнивать частоты.
В случае построения гистограммы относительных частот (гистограммы частостей) высоты в случае равных интегралов должны быть пропорциональны относительной частоте Пример 2
Построить гистограмму частот и относительных частот (частостей)
| 2-5 | 5-8 | 8-11 | 11-14 | 14-17 | 17-20 |
| Решение |
Вычислим относительные частоты:

Гистограмма относительных частот
Построить гистограмму частот (случай неравных интервалов).
| 2-4 | 4-8 | 8-13 | 13-15 | 15-17 | 17-20 |
| Решение |
Вычислим плотности частоты:
| Интервалы, | Плотность частоты, | ||
| 2 – 4 | 15 | 2 | 7.500 |
| 4 – 8 | 35 | 4 | 8.750 |
| 8 – 13 | 64 | 5 | 12.800 |
| 13 – 15 | 55 | 2 | 27.500 |
| 15 – 17 | 21 | 2 | 10.500 |
| 17 – 20 | 10 | 3 | 3.333 |
| Итого | 200 | — | — |

Кумулята и огива
При помощи кумуляты (кривой сумм) изображается ряд накопленных частот. Накопленные частоты определяются путём последовательного суммирования частот по группам и показывают, сколько единиц совокупности имеют значения признака не больше, чем рассматриваемое значение. При построении кумуляты интервального вариационного ряда по оси абсцисс откладываются варианты ряда, а по оси ординат накопленные частоты, которые наносят на поле в виде перпендикуляров к оси абсцисс в верхних границах интервалов. Затем эти перпендикуляры соединяют и получают ломаную линию, т.е. кумуляту.
Если при графическом изображении вариационного ряда в виде кумуляты оси поменять местами, то получим огиву. То есть огива строится аналогично кумуляте с той лишь разницей, что накопленные частоты помещают на оси абсцисс, а значения признака — на оси ординат.
Построить кумулятивную кривую:
| 2 | 5 | 8 | 11 | 14 | 17 |
| Решение |
Вычислим накопленные частоты:
| 2 | 15 | 15 |
| 7 | 35 | 50 |
| 8 | 64 | 114 |
| 15 | 55 | 169 |
| 16 | 21 | 190 |
| 17 | 10 | 200 |
| Итого | 200 | — |
Если по каким-либо причинам не справляетесь с решением задач, на портале можно заказать выполнение расчетной домашней работы, ИДЗ, РГР, контрольной и даже отдельных задач в разумные сроки. Чтобы вы смогли сделать заказ, я доступен по следующим каналам связи::
Контакты будут для вас
видны на территории
России и Беларуси
Общение без посредников. Удобная оплата переводом на банковскую карту. Опыт работы более 25 лет.
Подробное решение в формате электронного документа получите точно в срок или раньше.
Помощь во время экзамена/зачета/самостоятельной в онлайн-режиме строго по предварительной записи. Если вы уже знаете расписание зачетов/экзаменов и вам требуется онлайн-помощь — обращайтесь.
Инструменты Excel для построения гистограмм, полигонов
Процедура «Гистограмма» пакета «Анализ данных. Вычисление частот и накопленных частот. Построение гистограмм.
В процедуре автоматически выполняются следующие вычисления:
выбирается число m интервалов группировки (7 £ m £ 20);
вычисляются середины интервалов группировки 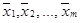 ,
, 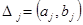 ,
, 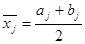 ;
;
для каждого интервала вычисляются частоты nj — количество выборочных значений, которые попали в j -й интервал;
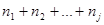
для каждого интервала вычисляются накопленные частоты — количество выборочных значений, не превышающих верхней границы j -го интервала;
Строится гистограмма – график ступенчатой функции 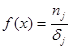 ,
, 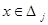 ,
, 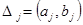 , D j = ( aj , bj ) ,
, D j = ( aj , bj ) , 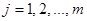 .
.
Для того чтобы вычислять накопленные частоты и отобразить гистограмму в листе в листе Excel , в окне процедуры следует пометить соответствующие поля.
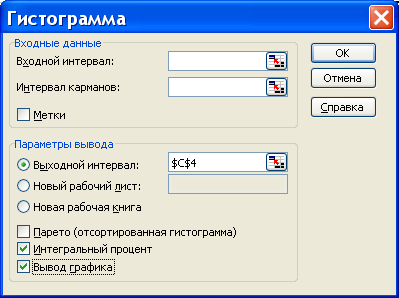
Результаты вычислений процедуры представлены в виде таблицы (ниже приведены две таблицы, первая – когда поле «Интегральный процент» не помечено, вторая – когда помечено)
2.2.1. Гистограмма частот
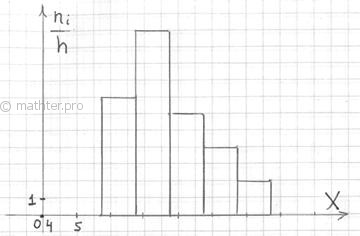
– это фигура, состоящая из прямоугольников, ширина которых равна длинам частичных интервалов (данные задачи), а высота – соответствующим плотностям частот:
при этом вполне допустимо использовать нестандартную шкалу по оси абсцисс, в данном случае я начал нумерацию с четырёх. Площадь гистограммы частот в точности равна объёму совокупности: . В нашем случае и плотности совпали с самими частотами , таким образом:
2.2.2. Гистограмма относительных частот
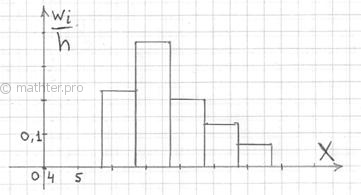
– это фигура, состоящая из прямоугольников, ширина которых равна длинам частичных интервалов, а высота – соответствующим плотностям относительных частот:
Площадь такой гистограммы равна единице: , и это статистический аналог функции плотности распределения непрерывной случайной величины.
Построенный чертёж даёт наглядное и весьма точное представление о распределении цен на ботинки по всей генеральной совокупности. При условии, что выборка представительна.
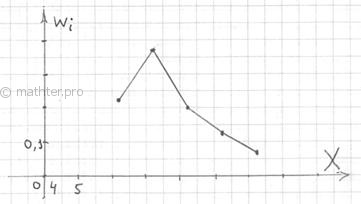
И для ИВР чаще всего требуется построить гистограмму именно относительных частот. А вместе с ней нередко и полигон таковых частот. Без проблем, полигон относительных частот – это ломаная, соединяющая соседние точки , где – середины интервалов:
По сути, здесь мы приблизили интервальный ряд дискретным, выбрав в качестве вариант середины интервалов. Это важнейший принцип и метод, который неоднократно встретится нам в будущем.
Большим достоинством приведённого решения является тот факт, что многие вычисления здесь устные, а если вы помните, как делить «столбиком», то можно обойтись даже без калькулятора. Вот она где притаилась, смерть Терминатора 🙂 😉
модел_3
СТАТИСТИЧЕСКАЯ ОБРАБОТКА ОДНОМЕРНОЙ ВЫБОРКИ Цель работы – получение основных навыков обработки одномерной выборки в пакетах MS Excel и MATLAB. Пакет MS Excel отлично подходит для простых задач вычисления числовых характеристик выборки. Для вычисления выборочных числовых характеристик средствами MS Excel можно использовать встроенные функции
| категории «Статистические». | |||||||
| Функция СРЗНАЧ возвращает значение выборочного | среднего | x , | |||||
| функция ДИСП позволяет получить значение оценки дисперсии S 2 | , а при | ||||||
| x | |||||||
| ~ 2 | |||||||
| помощи функции ДИСПР можно получить значение дисперсии S x . | |||||||
| Функция | СТАНДОТКЛОН | вычисляет | выборочное | ||||
| среднеквадратическое отклонение | S x , | а функция СТАНДОТКЛОНП дает | |||||
| ~ | |||||||
| возможность получить | значение | среднеквадратического отклонения | S x . | ||||
| Значение выборочного | момента | корреляции (ковариацию) | ˆ | можно | |||
| V XY | |||||||
рассчитать, используя функцию КОВАР, а выборочный коэффициент корреляции r xy можно вычислить, обратившись к функции КОРРЕЛ. В то же время, при вычислении выборочных числовых характеристик в MS Excel можно воспользоваться возможностями пакета анализа. Процедура действий в этом случае, следующая: 1. Открыть меню Сервис и выбрать Анализ данных. 2. Указать необходимую строку в списке Инструменты анализа. 3. Ввести входной и выходной диапазоны ячеек и установить необходимые параметры. Так, например, для одновременного вычисления выборочного среднего и дисперсии, а также других характеристик выборки, может быть использована процедура «Описательная статистика». Эта процедура позволяет получить очень полный статистический отчет. Для выполнения процедуры необходимо: 1
1. Выполнить команду Сервис – Анализ данных, в появившемся списке «Инструменты анализа» выбрать строку «Описательная статистика» и нажать «Ок». 2. В появившемся диалоговом окне указать входной диапазон анализируемых данных. 3. Указать входной диапазон, т.е. указать адрес ячейки на листе. 4. В разделе Группировка установить переключатель в положение «по столбцам». 5. Установить флажок в поле «Итоговая статистика», нажать ОК. В результате проведенного анализа в указанном выходном диапазоне для каждого столбца данных выводятся следующие статистические характеристики: 1. среднее (выборочное среднее x ), 2. стандартная ошибка (величина S n x ), 3. медиана (выборочная квантиль второго порядка), 4. мода (наиболее часто повторяющееся выборочное значение), 5. стандартное отклонение (величина S x ), 6. дисперсия выборки (выборочная дисперсия S x 2 ), 7. эксцесс (оценка коэффициентов эксцесса), 8. асимметричность (оценка коэффициента асимметрии), 9. интервал (размах выборки x max x min ), 10. минимум (наименьшее выборочное значение x min ), 11. максимум (наибольшее выборочное значение x max ), 12. сумма (сумма всех выборочных значений), 13. счет (объем выборки). Этапы выполнения работы 2
1. Получение допуска к работе. Необходимо переписать данные своего варианта N (см. приведенные ниже варианты заданий к работе №1, выборка объемом 50) 2. Выполнить аналитически от руки или в электронном виде: 2.1. Построение вариационного и статистического рядов, найти размах выборки; 2.2. Построение таблицы абсолютных и относительных частот группированной выборки, расчет интервалов провести по формуле Стерджеса; 2.3. Построить эмпирическую функцию распределения, гистограмму, полигон частот. 3. Средствами MS Excel и MATLAB найти оценки математического ожидания, дисперсии (смещенной и несмещенной), медианы и моды. Построить графики эмпирической функции распределения, гистограмму и полигон частот. Решение задачи в пакете MATLAB Для начала нам необходима выборка, с которой можно работать. В данном примере мы ее сгенерируем сами. Обратите внимание, что у каждого студента выборка уже задана вариантом задания, и ее не нужно будет генерировать. clear all close all clc % Генерация выборки, для дальнейшей работы % мат. ожидание генерируемой выборки mu = 0; % Среднеквадратическое отклонение sigma = 1; % Объем выборки n = 50; % Генерация нормально распределенных случайных чисел 3
X = normrnd(mu,sigma,n,1); % Генерация лог-нормально распределенных % случайных чисел % Данная выборка является в нашем случае % входной x = exp(X); Далее построим вариационный ряд, определим количество интервалов и найдем абсолютную частоту попадания элемента выборки в каждый из интервалов. % Построение вариационного ряда x = sort(x); % Поиск минимального и максимального % элементов выборки xmax = max(x); xmin = min(x); % Определим количество интервалов % по формуле Стерджесса b = 3.332; r = ceil(1+b*log10(n)); % Длина интервала stp = (xmax-xmin)/r; % Определяем середины интервалов centr = []; centr(1) = xmin+(stp/2); for i=2:1:r centr(i) = centr(i-1)+stp; end % Определяем абсолютную частоту k1 = xmin; i = 1; while i<=r k2 = 0; for j=1:n if (x(j)>=k1) & (x(j)<=k1+stp) k2 = k2+1; end end freqn(i) = k2; 4
k1 = xmin+stp*i; i = i+1; end Рассчитаем числовые характеристики выборки и выведем их на экран, при помощи следующего программного кода: % Числовые характеристики выборки: % Выборочное среднее m = mean(x); % Дисперсия D = var(x); % Ср. кв. отклонение SKO = std(x); % Мода moda = mode(x); % Медиана med = median(x); % Коэффициент эксцесса kurt = kurtosis(x); % Коэффициент асимметрии skew = skewness(x); % Вывод значений fprintf( ‘Максимальное значение = %f\n’ ,xmax); fprintf( ‘Минимальное значение = %f\n’ ,xmin); fprintf( ‘Количество интервалов = %f\n’ ,r); fprintf( ‘Длина одного интервала = %f\n’ ,r); fprintf( ‘Выборочное среднее = %f\n’ ,m); fprintf( ‘Выборочная дисперсия = %f\n’ ,D); fprintf( ‘Ср. кв. отклонение = %f\n’ ,SKO); fprintf( ‘Мода = %f\n’ ,moda); fprintf( ‘Медиана = %f\n’ ,med); fprintf( ‘Коэффициент эксцесса = %f\n’ ,kurt); fprintf( ‘Коэффициент асимметрии = %f\n’ ,skew); Далее построим полигон частот, гистограмму и эмпирическую функцию распределения, которые показаны на рис. 1-3 соответственно. % Построение полигона частот figure() plot(centr,freqn/n, ‘r-o’ ) xlabel( ‘Интервалы’ ); ylabel( ‘Относительная частота’ ) 5
grid on % Построение гистограммы figure() histogram(x,r) xlabel( ‘Интервалы’ ); ylabel( ‘Частота’ ) grid on % Построение эмпирической % функции распределения figure() ecdf(x) % Подпись оси 0X xlabel( ‘x’ ) % Подпись оси 0Y ylabel( ‘F(x)’ ) % Добавление сетки на график grid on
| Рис. 1. Полигон частот |
Рис. 2. Гистограмма Рис. 3. Эмпирическая функция распределения Выполнение работы в Excel в данной лабораторной работе мы пропустим, Excel по умолчанию не предоставляет возможности 7