Строение ELF-файлов⚓︎
ELF — сокращение от «Executable and Lincable Format» — формат исполняемых и связываемых файлов. ELF определяет их структуру. Данная спецификация позволяет UNIX-подобным(/образным) системам правильно интерпретировать содержащиеся в файле машинные команды. Используется во многих операционных системах: GNU/Linux, FreeBSD, Solaris, etc.
Понимание строения ELF файла может редко пригодиться, но, тем не менее, оно будет полезно для понимания процесса разработки программного обеспечения, поиска дыр в безопасности и обнаружения подозрительных программ или файлов.
Начальное строение⚓︎
Для начала создадим директорию, в которой будут расположены тестовые программы, на которых будем «упражняться»:
mkdir ~/LinuxPrograms cd ~/LinuxPrograms
Типы⚓︎
Есть несколько типов ELF файлов (см. таблицы в конце статьи): * Перемещаемый файл — хранит инструкции (и данные), которые могут быть связаны с другими объектными файлами. Результатом может быть объектный или исполняемый файл. Так же к этому типу относятся объектные файлы статических библиотек. * Разделяемый объектный файл — также как и первый тип, содержит инструкции и данные, может быть связан с другими перемещаемыми и разделяемыми объектными файлами, в результате чего будет создан новый объектный файл, либо же при запуске программы ОС может динамически связывать его с исполняемым файлом программы , в результате чего будет создан исполняемый образ программы (в посл. случае речь идёт о разделяемых библиотеках). * Исполняемый файл — содержит полное описание, позволяющее ОС создать образ процесса. В т.ч.: инструкции, данные, описания необходимых разделяемых объектных файлов и др.
Для того, чтобы вывод всех команд, приведённых ниже, был краток, прост и понятен, напишите какую-нибудь простейшую программу, в которой нет ничего лишнего, что затраднит чтение:
vim simple.c int main() return(0); >
И скомпилируйте её:
gcc -o simple simple.c
Убедитесь в том, что это ELF файл:
file simple
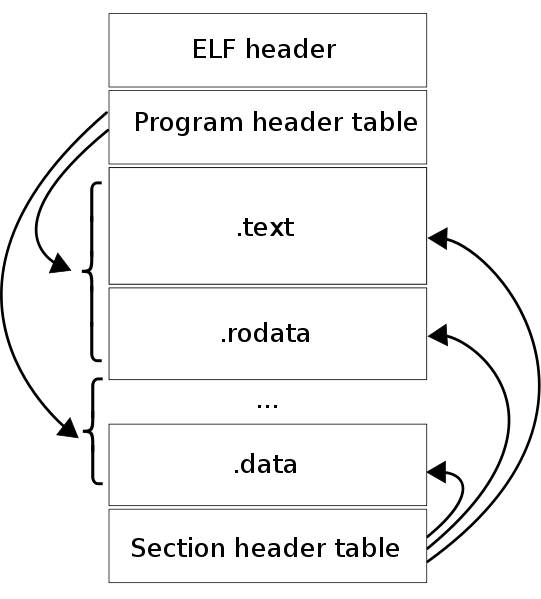
Структура у каждого файла может различаться. Грубо говоря, ELF файл состоит из: * Заголовка * Данных
Подробнее: * Таблица заголовков программы: 0 или более сегментов памяти (только в исполняемом файле). Сообщает, как исполняемый файл должен быть помещён в виртуальную память процесса. Это необходимо для образа процесса, исполняемых файлов и общих объектов. Для перемещаемых объектных файлов это не требуется. * Таблица заголовков разделов: 0 или более разделов. Сообщает, как и куда нужно загрузить раздел. Каждая запись раздела в таблице содержит название и размер раздела. Таблица заголовков раздела должна использоваться для файлов, используемых при редактировании ссылок. * Данные: тпблицы заголовка программы или раздела * Заголовок ELF (54/64 байта для 32/64 бит): определяет использование 32/64 бит (смотреть struct Elf32_Ehdr / struct Elf64_Ehdr в /usr/include/elf.h ) * Заголовок программы: как создать образ процесса. Используются во время выполнения. Сообщают ядру или компоновщику время выполнения ld.so , что загружать в память и как найти информацию о динамической компоновке. * Заголовок разделов: используются во время компоновки или компиляции. Сообщают редактору ссылок ld , как разрашать символы и как группировать похожие потоки байтов из разных двоичных объектов ELF.
- Разделы — самые мелкие неделимые единицы в ELF файле, которые могут быть обработаны. Разделы содержат основную часть информации об объектных файлах для представления связывания. Эти данные включают инструкции, таблицу символов и информацию о перемещении. (просмотр ссылок)
- Сегменты — наименьшие отдельные единицы, которые могут быть отображены в памяти с помощью exec или компоновщика. (исполняемые)
Разделы и сегменты не имеют определённого порядка в ELF. Только заголовок имеет фиксированную позицию.
При помощи утилиты readelf можно просмотреть основную информацию о файле.
Эта утилита входит в состав пакета binutils , поэтому ничего доустанавливать не надо.
Основные возможности readelf :
-
Просмотр заголовка файла:
readelf -h simple
readelf -S -W simple
readelf -s -W simple
Формат файлов ELF
В современных POSIX-системах основным форматом исполняемых файлов, объектных файлов, динамических библиотек является формат ELF. Этот формат используется и на 32-битных (Elf32), и на 64-битных (Elf64) системах и для машин с порядком байт Little-endian, и для машин с порядком байт Big-endian. Далее приведено краткое описание формата Elf32. Формат Elf64 отличается размерами полей, содержащих виртуальные адреса, размеры и смещения в файле.
В описании формата будут использоваться типы данных [u]intN_t, где u является признаком беззнаковости, а N определяет размер типа, например, uint16_t. Эти типы определены в стандартном заголовочном файле stdint.h.
#include
Все типы данных и константы описаны в заголовочном файле elf.h.
Заголовок файла
В начале файла (со смещения 0 от начала) идет заголовок ELF-файла, описываемый следующей структурой:
typedef struct < unsigned char e_ident[16]; uint16_t e_type; uint16_t e_machine; uint32_t e_version; uint32_t e_entry; uint32_t e_phoff; uint32_t e_shoff; uint32_t e_flags; uint16_t e_ehsize; uint16_t e_phentsize; uint16_t e_phnum; uint16_t e_shentsize; uint16_t e_shnum; uint16_t e_shstrndx; >Elf32_Ehdr;
Структура определена таким образом, что поля структуры выровнены по естественным для данной архитектуры правилам выравнивания (то есть 16-битные поля располагаются по четным адресам, а 32-битные — по адресам кратным 4), а полный размер структуры кратен 4 байтам. 16- и 32-битные значения представлены в порядке байт, естественном для соответствующей архитектуры.
Поле e_ident содержит идентификационную информацию о файле. Поле представляет собой массив байт для того, чтобы иметь одинаковое представление на архитектурах с разным размером слова и разным порядком байт в слове. Элементы массива имеют следующее назначение:
| Элемент | Значение | Описание |
|---|---|---|
| e_ident[0] | ‘\x7f’ | «Магическое» значение |
| e_ident[1] | ‘E’ | «Магическое» значение |
| e_ident[2] | ‘L’ | «Магическое» значение |
| e_ident[3] | ‘F’ | «Магическое» значение |
| e_ident[4] | 1 | Размер слова: 0 — неизвестно, 1 — 32, 2 — 64 |
| e_ident[5] | 1 | Порядок байт: 0 — неизвестно, 1 — little-endian, 2 — big-endian |
| e_ident[6] | 1 | Версия формата ELF: 0 — неизвестно, 1 — текущая версия |
| e_ident[7] | 0 | ОС и бинарный интерфейс, для Linux — 0 |
| e_ident[8] | 0 | Версия бинарного интерфейса, для Linux — 0 |
| e_ident[9] - e_ident[15] | 0 | Зарезервировано |
В дальнейшем будут приводиться значения констант для ОС Linux на архитектуре i386. За значениями констант для других операционных систем или архитектур обращайтесь к документации.
Поле e_type идентифицирует тип файла: 0 (неизвестно), 1 (объектный файл), 2 (исполняемый файл), 3 (разделяемая библиотека), 4 (core-файл).
Поле e_machine идентифицирует тип процессора: 0 (неизвестно), 3 (Intel 80386 и совместимые).
Поле e_version идентифицирует версию файла: 0 (недопустимая версия), 1 (текущая версия).
Поле e_entry определяет виртуальный адрес точки входа в программу. После загрузки программы в память управление передается на этот адрес.
Поле e_phoff задает смещение от начала файла до начала таблицы заголовков программы (program header table). Информация о таблице заголовков программы будет дана ниже.
Поле e_shoff задает смещение от начала файла до начала таблицы заголовков секций (program section table). Информация о таблице заголовков секций будет дана ниже.
Поле e_flags задает дополнительные процессорно-специфичные флаги. В настоящее время значение данного поля должно всегда быть 0.
Поле e_ehsize хранит размер заголовка ELF-файла. Его значение должно быть равно 52 (sizeof(Elf32_Ehdr)).
Поле e_phentsize хранит размер одной записи в таблице заголовков программы. Его значение должно быть 32 (sizeof(Elf32_Phdr)) или 0, если таблица заголовков программы пуста.
Поле e_phnum хранит количество записей в таблице заголовков программы.
Поле e_shentsize хранит размер одной записи в таблице заголовков секций. Его значение должно быть равно 40 (sizeof(Elf32_Shdr)) или 0, если таблица заголовков секций пуста.
Поле e_shnum хранит количество записей в таблице заголовков секций.
Поле e_shstrndx хранит индекс заголовка секции, которая хранит имена всех секций (см. ниже).
Таблица заголовков секций
Информация, хранящаяся в ELF-файле, организована в секции. Каждая секция имеет свое уникальное имя. Некоторые секции хранят служебную информацию ELF-файла (например, таблицы строк), другие секции хранят отладочную информацию, третьи секции хранят код или данные программы.
Таблица заголовков секций представляет собой массив структур Elf32_Shdr. Количество элементов массива определяется полем e_shnum заголовка ELF-файла. Массив находится по смещению, хранящемуся в поле e_shoff. Элемент массива 0 зарезервирован и не используется для описания секций. Таким образом, описания секций находятся в элементах массива с индексами от 1 и до e_shnum — 1.
Структура Elf32_Shdr определена следующим образом:
typedef struct < uint32_t sh_name; uint32_t sh_type; uint32_t sh_flags; uint32_t sh_addr; uint32_t sh_offset; uint32_t sh_size; uint32_t sh_link; uint32_t sh_info; uint32_t sh_addralign; uint32_t sh_entsize; >Elf32_Shdr;
Поле sh_name хранит индекс имени секции. Индекс имени — это смещение в данных секции, индекс которой задается в поле e_shstrndx заголовка ELF-файла. По этому смещению размещается строка, завершающаяся нулевым байтом, являющаяся именем секции.
Таким образом, чтобы получить имя секции необходимо выполнить следующие действия:
- Загрузить заголовок секции, индекс которой хранится в поле e_shstrndx заголовка ELF-файла.
- Загрузить тело соответствующей секции.
- По смещению, заданному в поле sh_name относительно начала области памяти, в которую загружена секция, находится требуемая строка имени секции.
Поле sh_type хранит тип секции. Возможные значения поля перечислены ниже.
| Значение | Симв. имя | Описание |
|---|---|---|
| 0 | SHT_NULL | Пустой заголовок секции. Значения всех прочих полей заголовка секции неопределены. |
| 1 | SHT_PROGBITS | Секции программы (код или данные или что-либо еще). |
| 2 | SHT_SYMTAB | Таблица символов (для объектных файлов или динамических библиотек). |
| 3 | SHT_STRTAB | Таблица строк. |
| 4 | SHT_RELA | Записи о перемещаемых адресах (relocations). |
| 5 | SHT_HASH | Хеш-таблица имен для динамического связывания. |
| 6 | SHT_DYNAMIC | Информация для динамического связывания. |
| 7 | SHT_NOTE | Произвольная дополнительная информация. |
| 8 | SHT_NOBITS | Секция не занимает место в файле, но занимает место в адресном пространстве процесса. |
| 9 | SHT_REL | Записи о перемещаемых адресах. |
Поле sh_flags хранит битовые флаги, описывающие дополнительные атрибуты.
| Значение | Симв. константа | Описание |
|---|---|---|
| 1 | SHF_WRITE | Содержимое секции должно быть доступно на запись в адресном пространстве процесса. |
| 2 | SHF_ALLOC | Для содержимого секции выделяется память в адресном пространстве процесса. |
| 4 | SHF_EXECINSTR | Секция содержит инструкции процессора. |
Флаги могут комбинироваться с помощью операции побитового или.
Поле sh_addr хранит адрес в виртуальном адресном пространстве процесса в случае, если секция загружается в виртуальное адресное пространство процесса.
Поле sh_offset хранит смещение от начала файла, по которому размещаются данные секции.
Поле sh_size хранит размер секции в байтах.
Поле sh_link хранит индекс другой секции (в некоторых специальных случаях).
Поле sh_info хранит дополнительную информацию о секции.
Поле sh_addralign хранит требование по выравниванию адреса начала секции в памяти. Значения 0 или 1 означают отсутствие требования по выравниванию. В противном случае значением поля должна быть степень 2. Например, секции, загружаемые в виртуальное адресное пространство процесса, как правило, выровнены по размеру страницы процессора (4096).
Поле sh_entsize хранит размер одной записи, если секция хранит таблицу из записей фиксированного размера.
Таблица заголовков программы
Таблица заголовков программы содержит информацию, необходимую для загрузки программы на выполнение.
Таблица заголовков программы представляет собой массив структур Elf32_Phdr. Массив размещается по смещению от начала файла, которое хранится в поле e_phoff заголовка ELF-файла, а количество элементов массива хранится в поле e_phnum заголовка ELF-файла.
Структура Elf32_Phdr определена следующим образом.
typedef struct < uint32_t p_type; Elf32_Off p_offset; Elf32_Addr p_vaddr; Elf32_Addr p_paddr; uint32_t p_filesz; uint32_t p_memsz; uint32_t p_flags; uint32_t p_align; >Elf32_Phdr;
Поле p_type хранит тип заголовка. Некоторые возможные значения типа заголовка приведены в таблице ниже.
| Значение | Симв. константа | Описание |
|---|---|---|
| 0 | PT_NULL | Обозначает не используемую запись |
| 1 | PT_LOAD | Сегмент программы, загружаемый в память |
| 2 | PT_DYNAMIC | Информация для динамического связывания |
| 3 | PT_INTERP | Загрузчик программ |
| 4 | PT_NOTE | Дополнительная информация |
| 6 | PT_PHDR | Информация о самой таблице заголовков программы |
| 7 | PT_TLS | Thread-local storage |
Поле p_offset хранит смещение от начала файла, по которому располагается данный сегмент.
Поле p_vaddr хранит виртуальный адрес начала сегмента в памяти.
Значение поля p_paddr должно быть равно 0.
Поле p_filesz хранит размер сегмента в файле (может быть 0).
Поле p_memsz хранит размер сегмента в памяти (может быть 0).
Поле p_flags хранит флаги доступа к сегменту в памяти (могут объединяться с помощью побитового «или»).
| Значение | Симв. константа | Описание |
|---|---|---|
| 1 | PT_X | Сегмент доступен на выполнение |
| 2 | PT_W | Сегмент доступен на запись |
| 4 | PT_R | Сегмент доступен на чтение |
Сегмент PT_NOTE
В сегменте ELF-файла с типом PT_NOTE хранится дополнительная информация о состоянии выполнения программы. Сегмент сам содержит произвольное количество записей произвольного размера. Сегмент всегда имеет размер, кратный 4 байтам (для Elf32), и каждая запись в сегменте начинается со смещения, кратного 4 байтам. В начале каждой записи находится заголовок записи, описываемый следующей структурой:
typedef struct < Elf32_Word n_namesz; Elf32_Word n_descsz; Elf32_Word n_type; >Elf32_Nhdr;
Поле n_namesz содержит длину названия записи. Название должно быть непустой строкой, завершающейся байтом 0. Сама строка названия записи начинается сразу же после структуры Elf32_Nhdr.
Поле n_descsz содержит длину информационной части записи. Длина должна быть кратна 4 байтам. Информационная часть записи начинается сразу после названия записи с учетом выравнивания по границе 4 байт.
Поле n_type содержит тип записи. Возможные типы записи зависят от типа файла (объектный, core) и рассматриваются в соответствующих разделах.
Ниже приведен пример сегмента PT_NOTE.
| См. от начала | Значение | Комментарий | |||
|---|---|---|---|---|---|
| 0x0000 | 0x07 | 0x00 | 0x00 | 0x00 | n_namesz == 7 |
| 0x0004 | 0x08 | 0x00 | 0x00 | 0x00 | n_descsz == 8 |
| 0x0008 | 0x01 | 0x00 | 0x00 | 0x00 | n_type == 1 |
| 0x000c | ‘G’ | ‘N’ | ‘U’ | ‘D’ | имя записи: «GNUDBG» |
| 0x0010 | ‘B’ | ‘G’ | ‘\0’ | 0x00 | |
| 0x0014 | 0x01 | 0x02 | 0x03 | 0x04 | информация: 0x04030201 0x08070605 |
| 0x0018 | 0x05 | 0x06 | 0x07 | 0x08 | |
core-файлы
core-файл — это ELF-файл, у которого значение поля e_type заголовка равно ET_CORE (4). В core-файле таблица заголовков секций пуста, а таблица заголовков программ состоит из записей типа PT_LOAD, хранящих содержимое адресного пространства процесса на момент завершения работы процесса, и записи типа PT_NOTE, хранящей состояние процесса на момент завершения работы процесса.
Для тестового файла sample.core содержимое таблицы заголовков программ имеет следующий вид.
| p_type | p_flags | p_offset | p_vaddr | p_filesz | p_memsz | p_align |
|---|---|---|---|---|---|---|
| PT_NOTE | — | 0x00000234 | 0x00000000 | 1216 | 0 | 0 |
| PT_LOAD | r-x | 0x00001000 | 0x08048000 | 4096 | 8192 | 4096 |
| PT_LOAD | rw- | 0x00002000 | 0x0804a000 | 4096 | 4096 | 4096 |
| PT_LOAD | rw- | 0x00003000 | 0x08542000 | 135168 | 135168 | 4096 |
| PT_LOAD | r-x | 0x00024000 | 0x4f2d0000 | 4096 | 126976 | 4096 |
| PT_LOAD | r— | 0x00025000 | 0x4f2ef000 | 4096 | 4096 | 4096 |
| PT_LOAD | rw- | 0x00026000 | 0x4f2f0000 | 4096 | 4096 | 4096 |
| PT_LOAD | r-x | 0x00027000 | 0x4f2f7000 | 4096 | 1748992 | 4096 |
| PT_LOAD | — | 0x00028000 | 0x4f4a2000 | 0 | 4096 | 4096 |
| PT_LOAD | r— | 0x00028000 | 0x4f4a3000 | 8192 | 8192 | 4096 |
| PT_LOAD | rw- | 0x0002a000 | 0x4f4a5000 | 4096 | 4096 | 4096 |
| PT_LOAD | rw- | 0x0002b000 | 0x4f4a6000 | 12288 | 12288 | 4096 |
| PT_LOAD | rw- | 0x0002e000 | 0xb778a000 | 4096 | 4096 | 4096 |
| PT_LOAD | rw- | 0x0002f000 | 0xb77a1000 | 8192 | 8192 | 4096 |
| PT_LOAD | r-x | 0x00031000 | 0xb77a3000 | 4096 | 4096 | 4096 |
| PT_LOAD | rw- | 0x00032000 | 0xbfe6d000 | 139264 | 139264 | 4096 |
Первый сегмент (сегмент PT_NOTE) содержит информацию о состоянии процесса на момент создания core-файла.
Для core-файлов возможны следующие значения поля n_type (в таблице ниже перечислены не все возможные значения).
| Значение | Симв. константа | Описание |
|---|---|---|
| 1 | NT_PRSTATUS | Информационная часть записи имеет тип prstatus_t |
| 2 | NT_FPREGSET | Информационная часть записи имеет тип prfpregset_t |
| 3 | NT_PRPSINFO | Информационная часть записи имеет тип prpsinfo_t |
Типы структур, используемые в информационных частях записей, определены в заголовочном файле
#include
Структура prstatus_t определена следующим образом:
typedef struct elf_prstatus < struct elf_siginfo pr_info; // информация о сигналах short int pr_cursig; // текущий сигнал unsigned long int pr_sigpend; // множество сигналов, ожидающих доставки unsigned long int pr_sighold; // множество удерживаемых сигналов pid_t pr_pid; // pid процесса pid_t pr_ppid; // pid родителя pid_t pr_pgrp; // группа процессов pid_t pr_sid; // идентификатор сессии struct timeval pr_utime; // пользовательское время struct timeval pr_stime; // системное время struct timeval pr_cutime; // накопленное пользовательское время struct timeval pr_cstime; // накопленное системное время elf_gregset_t pr_reg; // регистры общего назначения int pr_fpvalid; // true, если использовались регистры FPU >prstatus_t;
Тип elf_gregset_t определен следующим образом:
typedef unsigned long elf_gregset_t[ELF_NGREG];
то есть представляет собой массив, в котором каждый регистр общего назначения находится по определенному индексу.
| индекс | регистр |
|---|---|
| 0 | ebx |
| 1 | ecx |
| 2 | edx |
| 3 | esi |
| 4 | edi |
| 5 | ebp |
| 6 | eax |
| 7 | ds |
| 8 | es |
| 9 | fs |
| 10 | gs |
| 11 | orig_eax |
| 12 | eip |
| 13 | cs |
| 14 | eflags |
| 15 | sp |
| 16 | ss |
Формат отладочной информации stabs
При компиляции в исполняемый файл может добавляться отладочная информация, которую отладчик использует для отображения хода исполнения программы в терминах языка высокого уровня. Существует несколько форматов отладочной информации (STABS, DWARF), здесь описывается формат STABS как самый простой.
Для компиляции программы с добавлением отладочной информации в формате STABS используется опция gcc -gstabs, например
gcc -gstabs -std=gnu11 sample.c -o sample
В формате STABS отладочная информация хранится в секциях .stab и .stabstr ELF-файла.
Секция .stab содержит массив структур:
struct Stab < uint32_t n_strx; // позиция начала строки в секции .strstab uint8_t n_type; // тип отладочного символа uint8_t n_other; // прочая информация uint16_t n_desc; // описание отладочного символа uintptr_t n_value; // значение отладочного символа >;
Секция .stabstr хранит символьные строки, завершающиеся байтом 0, которые используются в записях в секции .stab.
Поле n_type хранит тип записи. Возможные типы записей можно найти в stab.h, нас будут интересовать только некоторые из них.
| Симв. имя | Значение | Описание |
|---|---|---|
| N_SO | 0x64 | Информация о единице компиляции: n_desc — язык исходного кода n_strx — индекс в секции .stabstr строки имени основного файла единицы компиляции n_value — адрес первой инструкции |
| N_SOL | 0x84 | Имя файла, устанавливаемое с помощью директивы #line или имя файла, включаемого с помощью #include n_strx — индекс в секции .stabstr строки имени файла Будем предполагать, что действие имени файла, устанавливаемого в записи N_SOL, начинается со следующей записи. |
| N_FUN | 0x24 | Имя функции n_value — адрес первой инструкции функции n_strx — индекс в секции .stabstr строки имени функции Имя состоит непосредственно из названия и после ‘:’ следуют типы параметров, если таковые есть |
| N_SLINE | 0x44 | Номер строки исполняемого кода n_value — смещение первой инструкции строки относительно начала функции n_desc — номер строки в исходном тексте |
Каждой единице компиляции соответствуют две записи N_SO. Первая запись находится в начале описания единицы компиляции и содержит ее имя в поле n_strx и адрес первой инструкции в поле n_value. Вторая запись находится в конце описания единицы компиляции и содержит нулевое значение (пустая строка) в поле n_strx и адрес непосредственно следующий за концом кода данной единицы компиляции в поле n_value.
Записи N_SLINE упорядочены по смещениям внутри функции.
Первая запись в таблице .stab является служебной и имеет тип N_UNDF. Индекс этой записи полагается равным 0.
Формат STABS не позволяет однозначно установить адрес, на котором заканчивается тело функции. Можно использовать следующую эвристику: функция заканчивается либо с началом следующей функции, тогда адрес конца функции — это адрес начала следующей функции, либо с концом единицы компиляции, тогда адрес конца функции — это адрес, хранящийся в поле n_value записи N_SO в конце единицы компиляции.
Как обычно, предполагается, что все диапазоны адресов и значений включают в себя нижнее значение, но не включают в себя верхнее значение, то есть имеют вид [low;high).
Имя файла, в котором располагается функция, может находиться в записи N_SOL после записи N_FUN самой функции, но до первой записи N_SLINE. Следует полагать, что имя файла, в котором определена функция совпадает с именем файла, установленному до первой записи N_SLINE в данной функции.
Пример: файл file1.h:i
#include void func2(int val)
#include «file1.h» int val; int func1(void) < scanf("%d", &val); return val; >int main()
SO 0 2 08048430 1 file1.c FUN 0 0 08048430 3880 func2:F(0,18) . SOL 0 0 08048430 668 file1.h SLINE 0 3 00000000 0 SLINE 0 4 00000006 0 SLINE 0 5 00000019 0 FUN 0 0 0804844b 3905 func1:F(0,1) SOL 0 0 0804844b 1 file1.c SLINE 0 4 00000000 0 SLINE 0 5 00000006 0 SLINE 0 6 0000001a 0 SLINE 0 7 0000001f 0 FUN 0 0 0804846c 3918 main:F(0,1) SLINE 0 10 00000000 0 SLINE 0 11 00000009 0 SLINE 0 12 0000000e 0 SLINE 0 13 0000001b 0 SLINE 0 14 00000020 0 SO 0 0 0804848e 0
Введение в ELF-файлы в Linux: понимание и анализ
Есть в мире вещи, которые мы принимаем как нечто само собой разумеющееся, хотя они являются истинными шедеврами. Одними из таких вещей являются утилиты Linux, такие, как ls и ps. Хотя они обычно воспринимаются как простые, это оказывается далеко не так, если мы заглянем внутрь. И таким же оказывается ELF, Executable and Linkable Format. Формат файлов, который используется повсеместно, но мало кто его понимает. Это краткое руководство поможет вам достичь понимания.

Прочтя это руководство, вы изучите:
- Зачем нужен формат ELF и для каких типов файлов он используется
- Структуру файла ELF и детали его формата
- Как читать и анализировать бинарное содержимое файла ELF
- Какие инструменты используются для анализа бинарных файлов
Что представляет собой файл ELF?
ELF — это сокращение от Executable and Linkable Format (формат исполняемых и связываемых файлов) и определяет структуру бинарных файлов, библиотек, и файлов ядра (core files). Спецификация формата позволяет операционной системе корректно интерпретировать содержащиеся в файле машинные команды. Файл ELF, как правило, является выходным файлом компилятора или линкера и имеет двоичный формат. С помощью подходящих инструментов он может быть проанализирован и изучен.
Зачем изучать ELF в подробностях?
Перед тем, как погрузиться в технические детали, будет не лишним объяснить, почему понимание формата ELF полезно. Во-первых, это позволяет изучить внутреннюю работу операционной системы. Когда что-то пошло не так, эти знания помогут лучше понять, что именно случилось, и по какой причине. Также возможность изучения ELF-файлов может быть ценна для поиска дыр в безопасности и обнаружения подозрительных файлов. И наконец, для лучшего понимания процесса разработки. Даже если вы программируете на высокоуровневом языке типа Go, вы всё равно будет лучше знать, что происходит за сценой.
Итак, зачем изучать ELF?
- Для общего понимания работы операционной системы
- Для разработки ПО
- Цифровая криминалистика и реагирование на инциденты (DFIR)
- Исследование вредоносных программ (анализ бинарных файлов)
От исходника к процессу
Какую бы операционную систему мы не использовали, необходимо каким-то образом транслировать функции исходного кода на язык CPU — машинный код. Функции могут быть самыми базовыми, например, открыть файл на диске или вывести что-то на экран. Вместо того, чтобы напрямую использовать язык CPU, мы используем язык программирования, имеющий стандартные функции. Компилятор затем транслирует эти функции в объектный код. Этот объектный код затем линкуется в полную программу, путём использования линкера. Результатом является двоичный файл, который может быть выполнен на конкретной платформе и конкретном типе CPU.
Прежде, чем начать
Этот пост содержит множество команд. Лучше запускать их на тестовой машине. Скопируйте существующие двоичные файлы, перед тем, как запускать на них эти команды. Также мы напишем маленькую программу на С, которую вы можете скомпилировать. В конечном итоге, практика — лучший способ чему-либо научиться.
Анатомия ELF-файла
Распространённым заблуждением является то, что файлы ELF предназначены только для бинарных или исполняемых файлов. Мы уже сказали, что они могут быть использованы для частей исполняемых файлов (объектного кода). Другим примером являются файлы библиотек и дампы ядра (core-файлы и a.out файлы). Спецификация ELF также используется в Linux для ядра и модулей ядра.

Структура
В силу расширяемости ELF-файлов, структура может различаться для разных файлов. ELF-файл состоит из:
- заголовка ELF
- данных

заголовок ELF
Как видно на скриншоте, заголовок ELF начинается с «магического числа». Это «магическое число» даёт информацию о файле. Первые 4 байта определяют, что это ELF-файл (45=E,4c=L,46=F, перед ними стоит значение 7f).
Заголовок ELF является обязательным. Он нужен для того, чтобы данные корректно интерпретировались при линковке и исполнении. Для лучшего понимания внутренней работы ELF-файла, полезно знать, для чего используется эта информация.
Класс
После объявления типа ELF, следует поле класса. Это значение означает архитектуру, для которой предназначен файл. Оно может равняться 01 (32-битная архитектура) или 02 (64-битная). Здесь мы видим 02, что переводится командой readelf как файл ELF64, то есть, другими словами, этот файл использует 64-битную архитектуру. Это неудивительно, в моей машине установлен современный процессор.
Данные
Далее идёт поле «данные», имеющее два варианта: 01 — LSB (Least Significant Bit), также известное как little-endian, либо 02 — MSB (Most Significant Bit, big-endian). Эти значения помогают интерпретировать остальные объекты в файле. Это важно, так как разные типы процессоров по разному обрабатывают структуры данных. В нашем случае используется LSB, так как процессор имеет архитектуру AMD64.
Эффект LSB становится видимым при использовании утилиты hexdump на бинарном файле. Давайте посмотрим заголовок ELF для /bin/ps.
$ hexdump -n 16 /bin/ps 0000000 457f 464c 0102 0001 0000 0000 0000 0000 0000010Мы видим, что пары значений другие, из-за интерпретации порядка данных.
Версия
Затем следует ещё одно магической значение «01», представляющее собой номер версии. В настоящее время имеется только версия 01, поэтому это число не означает ничего интересного.
OS/ABI
Каждая операционная система имеет свой способ вызова функций, они имеют много общего, но, вдобавок, каждая система, имеет небольшие различия. Порядок вызова функции определяется «двоичным интерфейсом приложения» Application Binary Interface (ABI). Поля OS/ABI описывают, какой ABI используется, и его версию. В нашем случае, значение равно 00, это означает, что специфические расширения не используются. В выходных данных это показано как System V.
Версия ABI
При необходимости, может быть указана версия ABI.
Машина
Также в заголовке указывается ожидаемый тип машины (AMD64).
Тип
Поле типа указывает, для чего предназначен файл. Вот несколько часто встречающихся типов файлов.
CORE (значение 4)
DYN (Shared object file), библиотека (значение 3)
EXEC (Executable file), исполняемый файл (значение 2)
REL (Relocatable file), файл до линковки (значение 1)
Смотрим полный заголовок
Хотя некоторые поля могут быть просмотрены через readelf, их на самом деле больше. Например, можно узнать, для какого процессора предназначен файл. Используем hexdump, чтобы увидеть полный заголовок ELF и все значения.
7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF. | 02 00 3e 00 01 00 00 00 a8 2b 40 00 00 00 00 00 |..>. +@. | 40 00 00 00 00 00 00 00 30 65 01 00 00 00 00 00 |@. 0e. | 00 00 00 00 40 00 38 00 09 00 40 00 1c 00 1b 00 |. @.8. @. |(вывод hexdump -C -n 64 /bin/ps)
Выделенное поле определяет тип машины. Значение 3e — это десятичное 62, что соответствует AMD64. Чтобы получить представление обо всех типах файлов, посмотрите этот заголовочный файл.
Хотя вы можете делать всё это в шестнадцатиричном дампе, имеет смысл использовать инструмент, который сделает работу за вас. Утилита dumpelf может быть полезна. Она показывает форматированный вывод, соответствующий заголовку ELF. Хорошо будет изучить, какие поля используются, и каковы их типичные значения.
Теперь, кгда мы объяснили значения этих полей, время посмотреть на то, какая реальная магия за ними стоит, и перейти к следующим заголовкам!
Данные файла
Помимо заголовка, файлы ELF состоят из трёх частей.
- Программные заголовки или сегменты
- Заголовки секций или секции
- Данные
Заголовки программы
Файл ELF состоит из нуля или более сегментов, и описывает, как создать процесс, образ памяти для исполнения в рантайме. Когда ядро видит эти сегменты, оно размещает их в виртуальном адресном пространстве, используя системный вызов mmap(2). Другими словами, конвертирует заранее подготовленные инструкции в образ в памяти. Если ELF-файл является обычным бинарником, он требует эти программные заголовки, иначе он просто не будет работать. Эти заголовки используются, вместе с соответствующими структурами данных, для формирования процесса. Для разделяемых библиотек (shared libraries) процесс похож.

Программный заголовок в бинарном ELF-файле
Мы видим в этом примере 9 программных заголовков. Сначала трудно понять, что они означают. Давайте погрузимся в подробности.
GNU_EH_FRAME
Это сортированная очередь, используемая компилятором GCC. В ней хранятся обработчики исключений. Если что-то пошло не так, они используются для того, чтобы корректно обработать ситуацию.
GNU_STACK
Этот заголовок используется для сохранения информации о стеке. Интересная особенность состоит в том, что стек не должен быть исполняемым, так как это может повлечь за собой уязвимости безопасности.
Если сегмент GNU_STACK отсутствует, используется исполняемый стек. Утилиты scanelf и execstack показывают детали устройства стека.
# scanelf -e /bin/ps TYPE STK/REL/PTL FILE ET_EXEC RW- R-- RW- /bin/ps # execstack -q /bin/ps - /bin/psКоманды для просмотра программного заголовка:
- dumpelf (pax-utils)
- elfls -S /bin/ps
- eu-readelf –program-headers /bin/ps
Секции ELF
Заголовки секции
Заголовки секции определяют все секции файла. Как уже было сказано, эта информация используется для линковки и релокации.
Секции появляются в ELF-файле после того, как компилятор GNU C преобразует код С в ассемблер, и ассемблер GNU создаёт объекты.
Как показано на рисунке вверху, сегмент может иметь 0 или более секций. Для исполняемых файлов существует четыре главных секций: .text, .data, .rodata, и .bss. Каждая из этих секций загружается с различными правами доступа, которые можно посмотреть с помощью readelf -S.
.text
Содержит исполняемый код. Он будет упакован в сегмент с правами на чтение и на исполнение. Он загружается один раз, и его содержание не изменяется. Это можно увидеть с помощью утилиты objdump.
12 .text 0000a3e9 0000000000402120 0000000000402120 00002120 2**4 CONTENTS, ALLOC, LOAD, READONLY, CODE.data
Инициализированные данные, с правами на чтение и запись.
.rodata
Инициализированные данные, с правами только на чтение. (=A).
.bss
Неинициализированные данные, с правами на чтение/запись. (=WA)
[24] .data PROGBITS 00000000006172e0 000172e0 0000000000000100 0000000000000000 WA 0 0 8 [25] .bss NOBITS 00000000006173e0 000173e0 0000000000021110 0000000000000000 WA 0 0 32Команды для просмотра секций и заголовков.
- dumpelf
- elfls -p /bin/ps
- eu-readelf –section-headers /bin/ps
- readelf -S /bin/ps
- objdump -h /bin/ps
Группы секций
Некоторые секции могут быть сгруппированы, как если бы они формировали единое целое. Новые линкеры поддерживают такую функциональность. Но пока такое встречается не часто.
# readelf -g /bin/ps There are no section groups in this file.Хотя это может показаться не слишком интересным, большие преимущества даёт знание инструментов анализа ELF-файлов. По этой причине, обзор этих инструментов и их назначения приведён в конце статьи.
Статические и динамические бинарные файлы
Когда мы имеем дело с бинарными файлами ELF, полезно будет знать, как линкуются эти два типа файлов. Они могут быть статическими и динамическими, и это относится к библиотекам, которые они используют. Если бинарник «динамический», это означает, что он использует внешние библиотеки, содержащие какие-либо общие функции, типа открытия файла или создания сетевого сокета. Статические бинарники, напротив, включают в себя все необходимые библиотеки.
Если вы хотите проверить, является ли файл статическим или динамическим, используйте команду file. Она покажет что-то вроде этого:
$ file /bin/ps /bin/ps: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.24, BuildID[sha1]=2053194ca4ee8754c695f5a7a7cff2fb8fdd297e, strippedЧтобы определить, какие внешние библиотеки использованы, просто используйте ldd на том же бинарнике:
$ ldd /bin/ps linux-vdso.so.1 => (0x00007ffe5ef0d000) libprocps.so.3 => /lib/x86_64-linux-gnu/libprocps.so.3 (0x00007f8959711000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f895934c000) /lib64/ld-linux-x86-64.so.2 (0x00007f8959935000)Совет: Чтобы посмотреть дальнейшие зависимости, лучше использовать утилиту lddtree.
Инструменты анализа двоичных файлов
Если вы хотите анализировать ELF-файлы, определённо будет полезно сначала посмотреть на существующие инструменты. Существуют тулкиты для обратной разработки бинарников и исполняемого кода. Если вы новичок в анализе ELF-файлов, начните со статического анализа. Статический анализ подразумевает, что мы исследуем файлы без их запуска. Когда вы начнёте лучше понимать их работу, переходите к динамическому анализу. Запускайте примеры и смотрите на их реальное поведение.
Популярные инструменты
Radare2
Тулкит Radare2 создан Серджи Альваресом (Sergi Alvarez). Число 2 подразумевает, что код был полностью переписан по сравнению с первой версией. Сейчас он используется многими исследователями, для изучения работы кода.
Программные пакеты
Большинство Linux-систем имеют установленный пакет binutils. Другие пакеты могут помочь вам увидеть больше информации. Правильный тулкит упростит вашу работу, особенно если вы занимаетесь анализом ELF-файлов. Я собрал здесь список пакетов и утилит для анализа ELF-файлов.
elfutils
/usr/bin/eu-addr2line
/usr/bin/eu-ar – альтернатива ar, для создания и обработки архивных файлов
/usr/bin/eu-elfcmp
/usr/bin/eu-elflint – проверка на соответствие спецификациям gABI и psABI
/usr/bin/eu-findtextrel – поиск релокаций текста
/usr/bin/eu-ld – комбинирует объектный и архивные файлы
/usr/bin/eu-make-debug-archive
/usr/bin/eu-nm – показывает символы объектного и исполняемого файлов
/usr/bin/eu-objdump – показывает информацию из объектного файла
/usr/bin/eu-ranlib – создаёт индекс архивных файлов
/usr/bin/eu-readelf – показывает ELF-файл в читаемой форме
/usr/bin/eu-size – показывает размер каждой секции (text, data, bss, etc)
/usr/bin/eu-stack – показывает стек текущего процесса или дампа ядра
/usr/bin/eu-strings – показывает текстовые строки (как утилита strings)
/usr/bin/eu-strip – удаляет таблицу символов из файла ELF
/usr/bin/eu-unstrip – добавляет символы и отладочную информацию в бинарник
Примечание: пакет elfutils будет хорошим началом, он содержит большинство утилит для анализа
elfkickers
/usr/bin/ebfc – компилятор языка Brainfuck
/usr/bin/elfls – показывает программные заголовки и заголовки секций с флагами
/usr/bin/elftoc – преобразует бинарник в программу на С
/usr/bin/infect – утилита, инжектирующая дроппер, создаёт файл setuid в /tmp
/usr/bin/objres – создаёт объект из обычных или бинарных данных
/usr/bin/rebind – изменяет связывание и видимость символов в ELF-файлах
/usr/bin/sstrip – удаляет ненужные компоненты из ELF-файла
Примечание: автор пакета ELFKickers сфокусирован на манипулировании ELF-файлами, что позволяет вам получить больше информации при работе с «неправильными» ELF-бинарниками
pax-utils
/usr/bin/dumpelf – дамп внутренней структуры ELF
/usr/bin/lddtree – как ldd, с установкой уровня показываемых зависимостей
/usr/bin/pspax – выводит ELF/PaX информацию о запущенных процессах
/usr/bin/scanelf – широкий диапазон информации, включая подробности PaX
/usr/bin/scanmacho – показывает подробности бинарников Mach-O (Mac OS X)
/usr/bin/symtree – показывает символы в виде дерева
Примечание: некоторые утилиты в этом пакете могут рекурсивно сканировать директории, и идеальны для анализа всего содержимого директории. Фокус сделан на инструментах для исследования подробностей PaX. Помимо поддержки ELF, можно извлекать информацию из Mach-O-бинарников.
scanelf -a /bin/ps TYPE PAX PERM ENDIAN STK/REL/PTL TEXTREL RPATH BIND FILE ET_EXEC PeMRxS 0755 LE RW- R-- RW- - - LAZY /bin/psprelink
/usr/bin/execstack – можно посмотреть или изменить информацию о том, является ли стек исполняемым
/usr/bin/prelink – релоцирует вызовы в ELF файлах, для ускорения процесса
Часто задаваемые вопросы
Что такое ABI?
ABI — это Бинарный Интерфейс Приложения (Application Binary Interface) и определяет, низкоуровневый интерфейс между операционной системой и исполняемым кодом.
Что такое ELF?
ELF — это Исполняемый и Связываемый Формат (Executable and Linkable Format). Это спецификация формата, определяющая, как инструкции записаны в исполняемом коде.
Как я могу увидеть тип файла?
Используйте команду file для первой стадии анализа. Эта команда способна показать подробности, извлечённые из «магических» чисел и заголовков.
Заключение
Файлы ELF предназначены для исполнения и линковки. В зависимости от назначения, они содержат необходимые сегменты и секции. Ядро ОС просматривает сегменты и отображает их в память (используя mmap). Секции просматриваются линкером, который создаёт исполняемый файл или разделяемый объект.
Файлы ELF очень гибкие и поддерживаются различные типы CPU, машинные архитектуры, и операционные системы. Также он расширяемый, каждый файл сконструирован по-разному, в зависимости от требуемых частей. Путём использования правильных инструментов, вы сможете разобраться с назначением файла, и изучать содержимое бинарных файлов. Можно просмотреть функции и строки, содержащиеся в файле. Хорошее начало для тех, кто исследует вредоносные программы, или понять, почему процесс ведёт себя (или не ведёт) определённым образом.
Ресурсы для дальнейшего изучения
Если вы хотите больше знать про ELF и обратную разработку, вы можете посмотреть работу, которую мы выполняем в Linux Security Expert. Как часть учебной программы, мы имеем модуль обратной разработки с практическими лабораторными работами.
Для тех из вас, кто любит читать, хороший и глубокий документ: ELF Format и документ за авторством Брайана Рейтера (Brian Raiter), также известного как ELFkickers. Для тех, кто любит разбираться в исходниках, посмотрите на документированный заголовок ELF от Apple.
Совет:
если вы хотите стать лучше в анализе файлов, начните использовать популярные инструменты анализа, которые доступны в настоящее время.
- Программирование
- Анализ и проектирование систем
- Системное программирование
Создание исполняемого файла ELF вручную
Привет, класс, и добро пожаловать в x86 Masochism 101. Здесь вы узнаете, как использовать опкоды непосредственно для создания исполняемого файла, даже не прикасаясь к компилятору, ассемблеру или компоновщику. Мы будем использовать только редактор, способный изменять двоичные файлы (т.е. шестнадцатеричный редактор), и «chmod», чтобы сделать файл исполняемым.
Если это вас не заводит, то я даже не знаю.
Если серьезно, то это одна из тех вещей, которые я лично считаю очень интересными. Очевидно, вы не собираетесь использовать это для создания серьезных программ с миллионами строк. Тем не менее, вы можете получить огромное удовольствие, узнав, что вы действительно понимаете, как такие вещи действительно работают на низком уровне. Также здорово иметь возможность сказать, что вы написали исполняемый файл, даже не касаясь компилятора или интерпретатора. Помимо этого, существуют приложения для программирования ядра, реверс-инжиниринга и (что неудивительно) создания компиляторов.
Прежде всего, давайте очень быстро посмотрим, как на самом деле работает выполнение файла ELF. Многие детали будут опущены. Что важно, так это получить хорошее представление о том, что делает ваш компьютер, когда вы говорите ему выполнить двоичный файл ELF.
Когда вы говорите компьютеру выполнить двоичный файл ELF, первое, что он будет искать, — это соответствующие заголовки ELF. Эти заголовки содержат всевозможную важную информацию об архитектуре процессора, сегментах и секциях файла и многое другое — мы поговорим об этом позже. Заголовок также содержит информацию, которая помогает компьютеру идентифицировать файл как ELF. Что наиболее важно, заголовок ELF содержит информацию о таблице заголовков программы (program header table) в случае исполняемого файла и виртуальном адресе, на который компьютер передает управление при выполнении.
Таблица заголовков программы, в свою очередь, определяет несколько сегментов. Если вы когда-либо программировали на ассемблере, вы можете думать о некоторых сегментах, таких как «text» и «data», как о сегментах в исполняемом файле. Заголовки программы также определяют, где в фактическом файле находятся данные этих сегментов, и какой адрес виртуальной памяти им назначить.
Если все было сделано правильно, компьютер загружает все сегменты в виртуальную память на основе данных в заголовках программ, затем передает управление на адрес виртуальной памяти, назначенный в заголовке ELF, и начинает выполнение инструкций.
Прежде чем мы начнем практиковаться, убедитесь, что у вас есть настоящий шестнадцатеричный редактор на вашем компьютере, и что вы можете запускать двоичные файлы ELF и вы используете компьютер архитектуры x86. Большинство шестнадцатеричных редакторов должны работать и позволять редактировать и сохранять вашу работу — мне лично нравится Bless. Если вы работаете в Linux, с двоичными файлами ELF все будет в порядке. Некоторые другие Unix-подобные операционные системы тоже могут работать, но разные ОС реализуют вещи немного по-разному, поэтому я не могу быть уверен. Я также широко использую системные вызовы, что еще больше ограничивает совместимость. Если вы используете Windows, вам не повезло. Точно так же, если архитектура вашего процессора отличается от x86 (хотя x86_64 должна работать), поскольку я просто не могу предоставить коды операций для каждой архитектуры.
Создание исполняемого файла ELF состоит из трех этапов. Сначала мы создадим фактическую полезную нагрузку (payload), используя опкоды. Во-вторых, мы создадим заголовки ELF и program header table, чтобы превратить эту полезную нагрузку в рабочую программу. Наконец, мы убедимся, что все смещения и виртуальные адреса верны, и заполним последние пробелы.
Предупреждение: создание исполняемого файла ELF вручную может быть очень неприятным. Я сам предоставил пример двоичного файла, который вы можете использовать для сравнения своей работы, но имейте в виду, что нет компилятора или компоновщика, который бы сказал вам, что вы сделали не так. Если (читайте: когда) вы облажались, ваш компьютер сообщит вам только «Ошибка ввода-вывода» или «Ошибка сегментации», что затрудняет отладку этих программ. И никаких отладочных символов не будет!
Создание полезной нагрузки
Давайте постараемся сделать полезную нагрузку простой, но достаточно сложной, чтобы быть интересной. Наша полезная нагрузка должна вывести «Hello World!» на экран, затем выйти с кодом 93. Это сложнее, чем кажется. Нам понадобится как текстовый сегмент (содержащий исполняемые инструкции), так и сегмент данных (содержащий строку «Hello World!» и некоторые другие второстепенные данные). Давайте посмотрим на ассемблерный код, который нам нужен для этого:
(text segment) mov ebx, 1 mov eax, 4 mov ecx, HWADDR mov edx, HWLEN int 0x80 mov eax, 1 mov ebx, 0x5D int 0x80Приведенный выше код не слишком сложен, даже если вы никогда не программировали на ассемблере. Прерывание 0x80 используется для выполнения системных вызовов, причем значения в регистрах EAX и EBX сообщают ядру, что это за вызов. Вы можете получить более подробную информацию о системных вызовах и их значениях в соответствующем мануале.
Для нашей полезной нагрузки нам нужно преобразовать эти инструкции в шестнадцатеричные коды операций. К счастью, есть хорошие онлайн-мануалы, которые помогают нам в этом. Попробуйте найти такой для семейства x86 и посмотрите, сможете ли вы понять, как перейти от приведенного выше кода к приведенным ниже шестнадцатеричным кодам:
0xBB 0x01 0x00 0x00 0x00 0xB8 0x04 0x00 0x00 0x00 0xB9 0x** 0x** 0x** 0x** 0xBA 0x0D 0x00 0x00 0x00 0xCD 0x80 0xB8 0x01 0x00 0x00 0x00 0xBB 0x5D 0x00 0x00 0x00 0xCD 0x80(Здесь звёздочки обозначают виртуальные адреса. Мы их еще не знаем, поэтому пока оставим их пустыми)
Вторая часть полезной нагрузки состоит из сегмента данных, который на самом деле представляет собой просто строку «Hello World!\n». Используйте таблицу преобразования ASCII (‘man ascii’), чтобы преобразовать эти значения в шестнадцатеричный формат, и вы увидите, как мы получим следующие данные:
(data segment) 0x48 0x65 0x6C 0x6C 0x6F 0x20 0x57 0x6F 0x72 0x6C 0x64 0x21 0x0AИ вот наша полезная нагрузка готова!
Создание заголовков
Вот где это может очень быстро стать очень сложным. Я объясню некоторые из наиболее важных параметров в процессе построения заголовков, но вы, вероятно, захотите внимательно взглянуть на несколько более подробное руководство, если вы когда-нибудь собираетесь создавать заголовки ELF полностью самостоятельно. Заголовок ELF имеет следующую структуру, размер в байтах в скобках:
e_ident(16), e_type(2), e_machine(2), e_version(4), e_entry(4), e_phoff(4), e_shoff(4), e_flags(4), e_ehsize(2), e_phentsize(2), e_phnum(2), e_shentsize(2) e_shnum(2), e_shstrndx(2)Теперь мы заполним структуру, и я объясню немного больше об этих параметрах, где это необходимо.
e_ident (16) — этот параметр содержит первые 16 байтов информации, которая идентифицирует файл как файл ELF. Первые четыре байта всегда содержат 0x7F, ‘E’, L ‘, F’. Байты с пятого по седьмой содержат 0x01 для 32-битных двоичных файлов на машинах с little-endian. Байты с восьмого по пятнадцатый являются заполнителями, поэтому они могут быть 0x00, а шестнадцатый байт содержит длину этого блока, поэтому он должен быть 16 (= 0x10).
e_type (2) — установите в 0x02 0x00. По сути, это говорит компьютеру, что это исполняемый файл ELF.
e_machine (2) — установите значение 0x03 0x00, что сообщает компьютеру, что файл ELF был создан для работы на процессорах типа i386.
e_version (4) — установите 0x01 0x00 0x00 0x00.
e_entry (4) — передать управление на этот виртуальный адрес при исполнении. Мы еще не определили его, поэтому пока это 0x** 0x** 0x** 0x**.
e_phoff (4) — смещение от файла к program header table. Мы помещаем его сразу после заголовка ELF, так что размер заголовка ELF в байтах: 0x34 0x00 0x00 0x00.
e_shoff (4) — смещение от начала файла к таблице заголовков раздела. Нам это не нужно. 0x00 0x00 0x00 0x00.
e_flags (4) — флаги нам тоже не нужны. 0x00 0x00 0x00 0x00 снова.
e_ehsize (2) — размер заголовка ELF, поэтому содержит 0x34 0x00.
e_phentsize (2) — размер заголовка программы. Технически мы этого еще не знаем, но я уже могу сказать вам, что он должен содержать 0x20 0x00. Прокрутите вниз, чтобы проверить, если хотите.
e_phnum (2) — количество заголовков программы, что напрямую соответствует количеству сегментов в файле. Нам нужен текст и сегмент данных, поэтому это должно быть 0x02 0x00.
e_shentsize (2), e_shnum (2), e_shstrndx (2) — все это на самом деле не актуально, если мы не реализуем заголовки секций (а мы не реализуем), поэтому вы можете просто установить это значение 0x00 0x00 0x00 0x00 0x00 0x00.
И это заголовок ELF! Это первое, что находится в файле, и если вы все сделали правильно, окончательный заголовок в шестнадцатеричном формате должен выглядеть так:
0x7F 0x45 0x4C 0x46 0x01 0x01 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10 0x02 0x00 0x03 0x00 0x01 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x34 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x34 0x00 0x20 0x00 0x02 0x00 0x00 0x00 0x00 0x00 0x00 0x00Однако мы еще не закончили с заголовками. Теперь нам нужно также создать program header table. Он имеет следующие записи:
p_type(4), p_offset(4), p_vaddr(4), p_paddr(4), p_filesz(4), p_memsz(4), p_flags(4), p_align(4)Опять же, я заполню структуру (на этот раз дважды: один для сегмента текста, второй для сегмента данных) и объясню ряд вещей по пути:
p_type (4) — сообщает программе тип сегмента. И текст, и данные используют здесь PT_LOAD (= 0x01 0x00 0x00 0x00).
p_offset (4) — смещение от начала файла. Эти значения зависят от размера заголовков и сегментов, поскольку мы не хотим, чтобы они перекрывались. Пока пусть будет 0x** 0x** 0x** 0x**.
p_vaddr (4) — какой виртуальный адрес назначить сегменту. Пусть будет 0x** 0x** 0x** 0x** 0x**, мы поговорим об этом позже.
p_paddr (4) — физическая адресация не имеет значения, поэтому вы можете указать здесь 0x00 0x00 0x00 0x00.
p_filesz (4) — количество байтов в образе файла сегмента, должно быть больше или равно размеру полезной нагрузки в сегменте. Опять же, установите значение 0x** 0x** 0x** 0x**. Мы изменим это позже.
p_memsz (4) — количество байтов в памяти образа сегмента. Обратите внимание, что это не обязательно равно p_filesz, но может быть и так. Пока оставьте его на 0x** 0x** 0x** 0x**, но помните, что позже мы можем установить его на то же значение, которое мы присваиваем p_filesz.
p_flags (4) — эти флаги могут быть непростыми, если вы не привыкли с ними работать. Что вам нужно запомнить, так это то, что флаг READ — 0x04, флаг WRITE — 0x02, а флаг EXEC — 0x01. Для текстового сегмента мы хотим READ + EXEC, поэтому 0x05 0x00 0x00 0x00, а для сегмента данных мы предпочитаем READ + WRITE + EXEC, поэтому 0x07 0x00 0x00 0x00.
p_align (4) — указывает на выравнивание страниц памяти. Размер страницы обычно составляет 4 КиБ, поэтому значение должно быть 0x1000. Помните, что x86 является little-endian, поэтому окончательное значение равно 0x00 0x10 0x00 0x00.
Уф. Мы, безусловно, уже многое сделали. Мы еще не заполнили многие поля в заголовках программ, и нам также не хватает нескольких байтов в заголовке ELF, но мы приближаемся. Если все пойдет по плану, таблица заголовков вашей программы (которую, кстати, можно вставить непосредственно за заголовком ELF — помните наше смещение в этом заголовке?) Должна выглядеть примерно так:
0x01 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x00 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x05 0x00 0x00 0x00 0x00 0x10 0x00 0x00 0x01 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x00 0x00 0x00 0x00 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x** 0x07 0x00 0x00 0x00 0x00 0x10 0x00 0x00Заполнение пробелов
Хотя мы уже выполнили большую часть тяжелой работы, нам все еще нужно сделать несколько сложных вещей. У нас есть заголовок ELF и таблица программ, которые мы можем разместить в начале нашего файла, и у нас есть полезная нагрузка для нашей реальной программы, но нам все еще нужно поместить что-то в таблицу, которая сообщает компьютеру, где это найти. И нам нужно разместить нашу полезную нагрузку в файле, чтобы ее можно было найти.
Во-первых, мы хотим вычислить размер наших заголовков и полезной нагрузки, прежде чем мы сможем определить какие-либо смещения. Просто сложите вместе размеры всех полей в заголовках и получите минимальное смещение для любого из сегментов. В заголовке ELF 116 байт + 2 заголовка программы, и 116 = 0x74, поэтому минимальное смещение равно 0x74. Чтобы сделать это безопасно, давайте установим начальное смещение на 0x80. Заполните от 0x74 до 0x7F 0x00, затем поместите текстовый сегмент в 0x80 в файл.
Размер самого текстового сегмента составляет 34 = 0x22 байта, что означает, что минимальное смещение для сегмента данных составляет 0x80 + 0x22 = 0xA2. Поместим сегмент данных в 0xA4 и заполним 0xA2 и 0xA3 значениями 0x00.
Если вы делали все вышеперечисленное в своем шестнадцатеричном редакторе, теперь у вас будет двоичный файл, содержащий ELF, и заголовки программ от 0x00 до 0x73, от 0x74 до 0x7F будут заполнены нулями, текстовый сегмент размещен от 0x80 до 0xA1, 0xA2 и 0xA3 снова являются нулями, и сегмент данных идет от 0xA4 до 0xB0. Если вы следуете этим инструкциям, и не получаете правильного результата, сейчас самое время посмотреть, что пошло не так.
Предполагая, что теперь все находится в нужном месте в файле, пора изменить некоторые из наших предыдущих звездочек на фактические значения. Я просто сначала дам вам значения для каждого параметра, а затем объясню, почему мы используем именно эти значения.
e_entry (4) — 0x80 0x80 0x04 0x08; Мы выберем 0x8048080 в качестве точки входа в виртуальной памяти. Существуют некоторые правила относительно того, что вы можете, а что не можете выбрать в качестве точки входа, но самое важное, что нужно помнить, — это то, что начальный адрес виртуальной памяти по модулю размера страницы должен быть равен смещению в файле по модулю размера страницы. Вы можете проверить это в справочнике по ELF и некоторым другим хорошие книгам для получения дополнительной информации, но если это кажется слишком сложным, просто забудьте об этом и используйте эти значения.
p_offset (4) — 0x80 0x00 0x00 0x00 для текста, 0xA4 0x00 0x00 0x00 для данных. Это из-за очевидной причины, по которой эти сегменты находятся в файле.
p_vaddr (4) — 0x80 0x80 0x04 0x08 для текста, 0xA4 0x80 0x04 0x08 для данных. Мы хотим, чтобы сегмент текста был точкой входа для программы, и мы помещаем сегмент данных в память таким образом, чтобы он прямо соответствовал физическим смещениям.
p_filesz (4) — 0x24 0x00 0x00 0x00 для текста, 0x20 0x00 0x00 0x00 для данных. Это просто байтовые размеры различных сегментов файла и памяти. В этом случае p_memsz = p_filesz, поэтому используйте те же значения там.
Окончательный результат
Если вы выполнили все до буквы, вот что вы получите, если выгрузите все в шестнадцатеричном формате:
7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 10 02 00 03 00 01 00 00 00 80 80 04 08 34 00 00 00 00 00 00 00 00 00 00 00 34 00 20 00 02 00 00 00 00 00 00 00 01 00 00 00 80 00 00 00 80 80 04 08 00 00 00 00 24 00 00 00 24 00 00 00 05 00 00 00 00 10 00 00 01 00 00 00 A4 00 00 00 A4 80 04 08 00 00 00 00 20 00 00 00 20 00 00 00 07 00 00 00 00 10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 BB 01 00 00 00 B8 04 00 00 00 B9 A4 80 04 08 BA 0D 00 00 00 CD 80 B8 01 00 00 00 BB 2A 00 00 00 CD 80 00 00 48 65 6C 6C 6F 20 57 6F 72 6C 64 21 0AВот и все. Запустите chmod +x для этого двоичного файла, а затем выполните его. Hello World в 178 байтах. Надеюсь, вам понравилось это писать. 🙂 Если вы считаете этот HOWTO полезным или интересным, дайте мне знать! Я всегда это ценю. Также всегда приветствуются советы, комментарии и / или конструктивная критика.
- Ненормальное программирование
- Assembler
- Отладка
- Реверс-инжиниринг