Знакомимся с методом обратного распространения ошибки
Всем привет! Новогодние праздники подошли к концу, а это значит, что мы вновь готовы делиться с вами полезным материалом. Перевод данной статьи подготовлен в преддверии запуска нового потока по курсу «Алгоритмы для разработчиков».

Метод обратного распространения ошибки – вероятно самая фундаментальная составляющая нейронной сети. Впервые он был описан в 1960-е и почти 30 лет спустя его популяризировали Румельхарт, Хинтон и Уильямс в статье под названием «Learning representations by back-propagating errors».
Метод используется для эффективного обучения нейронной сети с помощью так называемого цепного правила (правила дифференцирования сложной функции). Проще говоря, после каждого прохода по сети обратное распространение выполняет проход в обратную сторону и регулирует параметры модели (веса и смещения).
В этой статья я хотел бы подробно рассмотреть с точки зрения математики процесс обучения и оптимизации простой 4-х слойной нейронной сети. Я считаю, что это поможет читателю понять, как работает обратное распространение, а также осознать его значимость.
Определяем модель нейронной сети
Четырехслойная нейронная сеть состоит из четырех нейронов входного слоя, четырех нейронов на скрытых слоях и 1 нейрона на выходном слое.

Простое изображение четырехслойной нейронной сети.
Входной слой
На рисунке нейроны фиолетового цвета представляют собой входные данные. Они могут быть простыми скалярными величинами или более сложными – векторами или многомерными матрицами.
Уравнение, описывающее входы xi.
Первый набор активаций (а) равен входным значениям. «Активация» — это значение нейрона после применения функции активации. Подробнее смотрите ниже.
Скрытые слои
Конечные значения в скрытых нейронах (на рисунке зеленого цвета) вычисляются с использованием z l – взвешенных входов в слое I и a I активаций в слое L. Для слоев 2 и 3 уравнения будут следующими:


W 2 и W 3 – это веса на слоях 2 и 3, а b 2 и b 3 – смещения на этих слоях.
Активации a 2 и a 3 вычисляются с помощью функции активации f. Например, эта функция f является нелинейной (как сигмоид, ReLU и гиперболический тангенс) и позволяет сети изучать сложные паттерны в данных. Мы не будем подробно останавливаться на том, как работают функции активации, но, если вам интересно, я настоятельно рекомендую прочитать эту замечательную статью.
Присмотревшись внимательно, вы увидите, что все x, z 2 , a 2 , z 3 , a 3 , W 1 , W 2 , b 1 и b 2 не имеют нижних индексов, представленных на рисунке четырехслойной нейронной сети. Дело в том, что мы объединили все значения параметров в матрицы, сгруппированные по слоям. Это стандартный способ работы с нейронными сетями, и он довольно комфортный. Однако я пройдусь по уравнениям, чтобы не возникло путаницы.
Давайте возьмем слой 2 и его параметры в качестве примера. Те же самые операции можно применить к любому слою нейронной сети.
W 1 – это матрица весов размерности (n, m), где n – это количество выходных нейронов (нейронов на следующем слое), а m – число входных нейронов (нейронов в предыдущем слое). В нашем случае n = 2 и m = 4.

Здесь первое число в нижнем индексе любого из весов соответствует индексу нейрона в следующем слое (в нашем случае – это второй скрытый слой), а второе число соответствует индексу нейрона в предыдущем слое (в нашем случае – это входной слой).
x – входной вектор размерностью (m, 1), где m – число входных нейронов. В нашем случае m = 4.

b 1 – это вектор смещения размерности (n, 1), где n – число нейронов на текущем слое. В нашем случае n = 2.

Следуя уравнению для z 2 мы можем использовать приведенные выше определения W 1 , x и b 1 для получения уравнения z 2 :

Теперь внимательно посмотрите на иллюстрацию нейронной сети выше:
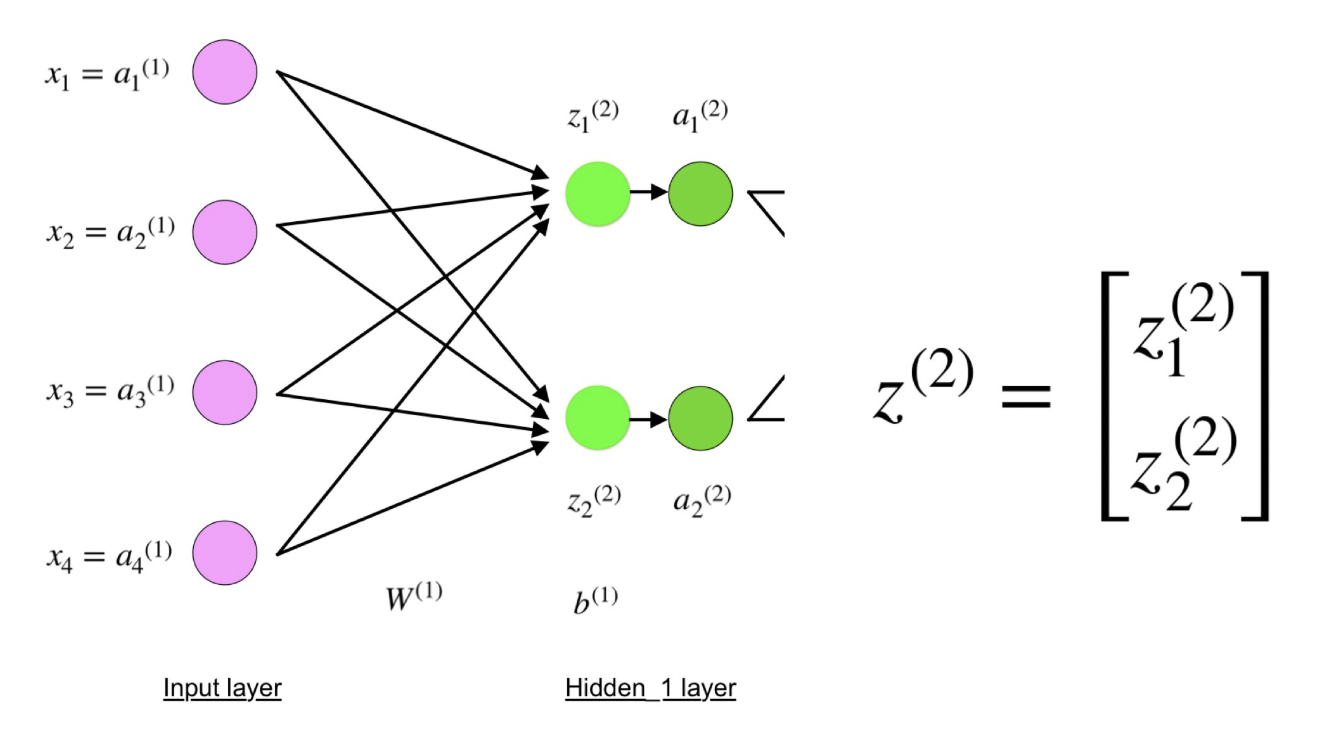
Как видите, z 2 можно выразить через z1 2 и z2 2 , где z1 2 и z2 2 – суммы произведений каждого входного значения x i на соответствующий вес Wij 1 .
Это приводит к тому же самому уравнению для z 2 и доказывает, что матричные представления z 2 , a 2 , z 3 и a 3 – верны.
Выходной слой
Последняя часть нейронной сети – это выходной слой, который выдает прогнозируемое значение. В нашем простом примере он представлен в виде одного нейрона, окрашенного в синий цвет и рассчитываемого следующим образом:

И снова мы используем матричное представление для упрощения уравнения. Можно использовать вышеприведенные методы, чтобы понять лежащую в их основе логику.
Прямое распространение и оценка
Приведенные выше уравнения формируют прямое распространение по нейронной сети. Вот краткий обзор:

(1) – входной слой
(2) – значение нейрона на первом скрытом слое
(3) – значение активации на первом скрытом слое
(4) – значение нейрона на втором скрытом слое
(5) – значение активации на втором скрытом уровне
(6) – выходной слой
Заключительным шагом в прямом проходе является оценка прогнозируемого выходного значения s относительно ожидаемого выходного значения y.
Выходные данные y являются частью обучающего набора данных (x, y), где x – входные данные (как мы помним из предыдущего раздела).
Оценка между s и y происходит через функцию потерь. Она может быть простой как среднеквадратичная ошибка или более сложной как перекрестная энтропия.
Мы назовем эту функцию потерь С и обозначим ее следующим образом:

Где cost может равняться среднеквадратичной ошибке, перекрестной энтропии или любой другой функции потерь.
Основываясь на значении С, модель «знает», насколько нужно скорректировать ее параметры, чтобы приблизиться к ожидаемому выходному значению y. Это происходит с помощью метода обратного распространения ошибки.
Обратное распространение ошибки и вычисление градиентов
Опираясь на статью 1989 года, метод обратного распространения ошибки:
Постоянно настраивает веса соединений в сети, чтобы минимизировать меру разности между фактическим выходным вектором сети и желаемым выходным вектором.
и
…дает возможность создавать полезные новые функции, что отличает обратное распространение от более ранних и простых методов…
Другими словами, обратное распространение направлено на минимизацию функции потерь путем корректировки весов и смещений сети. Степень корректировки определяется градиентами функции потерь по отношению к этим параметрам.
Возникает один вопрос: Зачем вычислять градиенты?
Чтобы ответить на этот вопрос, нам сначала нужно пересмотреть некоторые понятия вычислений:
Градиентом функции С(x 1 , x 2 , …, x m ) в точке x называется вектор частных производных С по x.

Производная функции С отражает чувствительность к изменению значения функции (выходного значения) относительно изменения ее аргумента х (входного значения). Другими словами, производная говорит нам в каком направлении движется С.
Градиент показывает, насколько необходимо изменить параметр x (в положительную или отрицательную сторону), чтобы минимизировать С.
Вычисление этих градиентов происходит с помощью метода, называемого цепным правилом.
Для одного веса (w jk )l градиент равен:

(1) Цепное правило
(2) По определению m – количество нейронов на l – 1 слое
(3) Вычисление производной
(4) Окончательное значение
Аналогичный набор уравнений можно применить к (b j )l:

(1) Цепное правило
(2) Вычисление производной
(3) Окончательное значение
Общая часть в обоих уравнениях часто называется «локальным градиентом» и выражается следующим образом:

«Локальный градиент» можно легко определить с помощью правила цепи. Этот процесс я не буду сейчас расписывать.
Градиенты позволяют оптимизировать параметры модели:
Пока не будет достигнут критерий остановки выполняется следующее:

- Начальные значения w и b выбираются случайным образом.
- Эпсилон (e) – это скорость обучения. Он определяет влияние градиента.
- w и b – матричные представления весов и смещений.
- Производная C по w или b может быть вычислена с использованием частных производных С по отдельным весам или смещениям.
- Условие завершение выполняется, как только функция потерь минимизируется.
Заключительную часть этого раздела я хочу посвятить простому примеру, в котором мы рассчитаем градиент С относительно одного веса (w 22 )2.
Давайте увеличим масштаб нижней части вышеупомянутой нейронной сети:

Визуальное представление обратного распространения в нейронной сети
Вес (w 22 )2 соединяет (a 2 )2 и (z 2 )2, поэтому вычисление градиента требует применения цепного правила на (z 3 )2 и (a 3 )2:

Вычисление конечного значения производной С по (a 2 )3 требует знания функции С. Поскольку С зависит от (a 2 )3, вычисление производной должно быть простым.
Я надеюсь, что этот пример сумел пролить немного света на математику, стоящую за вычислением градиентов. Если захотите узнать больше, я настоятельно рекомендую вам посмотреть Стэндфордскую серию статей по NLP, где Ричард Сочер дает 4 замечательных объяснения обратного распространения.
Заключительное замечание
В этой статье я подробно объяснил, как обратное распространение ошибки работает под капотом с помощью математических методов, таких как вычисление градиентов, цепное правило и т.д. Знание механизмов этого алгоритма укрепит ваши знания о нейронных сетях и позволит вам чувствовать себя комфортно при работе с более сложными моделями. Удачи вам в путешествии по глубокому обучению!
На этом все. Приглашаем всех на бесплатный вебинар по теме «Дерево отрезков: просто и быстро».
- Artificial Intelligence
- Deep Learning
- Algorithms
- Mathematics
- Data Science
- Блог компании OTUS
- Алгоритмы
- Big Data
- Математика
Обратное распространение ошибки
Метод обратного распространения ошибок (англ. backpropagation) — метод вычисления градиента, который используется при обновлении весов в нейронной сети.
Обучение как задача оптимизации
Рассмотрим простую нейронную сеть без скрытых слоев, с двумя входными вершинами и одной выходной, в которых каждый нейрон использует линейную функцию активации, (обычно, многослойные нейронные сети используют нелинейные функции активации, линейные функции используются для упрощения понимания) которая является взвешенной суммой входных данных.
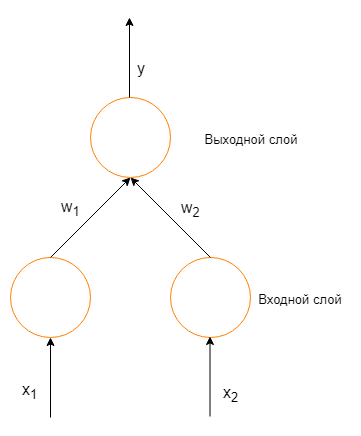
Простая нейронная сеть с двумя входными вершинами и одной выходной
Изначально веса задаются случайно. Затем, нейрон обучается с помощью тренировочного множества, которое в этом случае состоит из множества троек [math](x_1, x_2, t)[/math] где [math]x_1[/math] и [math]x_2[/math] — это входные данные сети и [math]t[/math] — правильный ответ. Начальная сеть, приняв на вход [math]x_1[/math] и [math]x_2[/math] , вычислит ответ [math]y[/math] , который вероятно отличается от [math]t[/math] . Общепринятый метод вычисления несоответствия между ожидаемым [math]t[/math] и получившимся [math]y[/math] ответом — квадратичная функция потерь:
[math]E=(t-y)^2, [/math] где [math]E[/math] ошибка. В качестве примера, обучим сеть на объекте [math](1, 1, 0)[/math] , таким образом, значения [math]x_1[/math] и [math]x_2[/math] равны 1, а [math]t[/math] равно 0. Построим график зависимости ошибки [math]E[/math] от действительного ответа [math]y[/math] , его результатом будет парабола. Минимум параболы соответствует ответу [math]y[/math] , минимизирующему [math]E[/math] . Если тренировочный объект один, минимум касается горизонтальной оси, следовательно ошибка будет нулевая и сеть может выдать ответ [math]y[/math] равный ожидаемому ответу [math]t[/math] . Следовательно, задача преобразования входных значений в выходные может быть сведена к задаче оптимизации, заключающейся в поиске функции, которая даст минимальную ошибку.
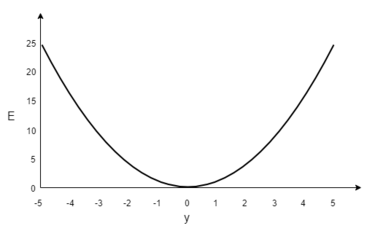
График ошибки для нейрона с линейной функцией активации и одним тренировочным объектом
В таком случае, выходное значение нейрона — взвешенная сумма всех его входных значений:
где [math]w_1[/math] и [math]w_2[/math] — веса на ребрах, соединяющих входные вершины с выходной. Следовательно, ошибка зависит от весов ребер, входящих в нейрон. И именно это нужно менять в процессе обучения. Распространенный алгоритм для поиска набора весов, минимизирующего ошибку — градиентный спуск. Метод обратного распространения ошибки используется для вычисления самого «крутого» направления для спуска.
Дифференцирование для однослойной сети
Метод градиентного спуска включает в себя вычисление дифференциала квадратичной функции ошибки относительно весов сети. Обычно это делается с помощью метода обратного распространения ошибки. Предположим, что выходной нейрон один, (их может быть несколько, тогда ошибка — это квадратичная норма вектора разницы) тогда квадратичная функция ошибки:
[math]E = \tfrac 1 2 (t — y)^2,[/math] где [math]E[/math] — квадратичная ошибка, [math]t[/math] — требуемый ответ для обучающего образца, [math]y[/math] — действительный ответ сети.
Множитель [math]\textstyle\frac[/math] добавлен чтобы предотвратить возникновение экспоненты во время дифференцирования. На результат это не повлияет, потому что позже выражение будет умножено на произвольную величину скорости обучения (англ. learning rate).
Для каждого нейрона [math]j[/math] , его выходное значение [math]o_j[/math] определено как
[math]o_j = \varphi(\text_j) = \varphi\left(\sum_^n w_o_k\right).[/math]
Входные значения [math]\text_j[/math] нейрона — это взвешенная сумма выходных значений [math]o_k[/math] предыдущих нейронов. Если нейрон в первом слое после входного, то [math]o_k[/math] входного слоя — это просто входные значения [math]x_k[/math] сети. Количество входных значений нейрона [math]n[/math] . Переменная [math]w_[/math] обозначает вес на ребре между нейроном [math]k[/math] предыдущего слоя и нейроном [math]j[/math] текущего слоя.
Функция активации [math]\varphi[/math] нелинейна и дифференцируема. Одна из распространенных функций активации — сигмоида:
[math] \varphi(z) = \frac 1 >[/math]
у нее удобная производная:
Находим производную ошибки
Вычисление частной производной ошибки по весам [math]w_[/math] выполняется с помощью цепного правила:
Только одно слагаемое в [math]\text_j[/math] зависит от [math]w_[/math] , так что
Если нейрон в первом слое после входного, то [math]o_i[/math] — это просто [math]x_i[/math] .
Производная выходного значения нейрона [math]j[/math] по его входному значению — это просто частная производная функции активации (предполагается что в качестве функции активации используется сигмоида):
По этой причине данный метод требует дифференцируемой функции активации. (Тем не менее, функция ReLU стала достаточно популярной в последнее время, хоть и не дифференцируема в 0)
Первый множитель легко вычислим, если нейрон находится в выходном слое, ведь в таком случае [math]o_j = y[/math] и
Тем не менее, если [math]j[/math] произвольный внутренний слой сети, нахождение производной [math]E[/math] по [math]o_j[/math] менее очевидно.
Если рассмотреть [math]E[/math] как функцию, берущую на вход все нейроны [math]L = [/math] получающие на вход значение нейрона [math]j[/math] ,
и взять полную производную по [math]o_j[/math] , то получим рекурсивное выражение для производной:
Следовательно, производная по [math]o_j[/math] может быть вычислена если все производные по выходным значениям [math]o_\ell[/math] следующего слоя известны.
Если собрать все месте:
Чтобы обновить вес [math]w_[/math] используя градиентный спуск, нужно выбрать скорость обучения, [math]\eta \gt 0[/math] . Изменение в весах должно отражать влияние [math]E[/math] на увеличение или уменьшение в [math]w_[/math] . Если [math]\frac<\partial E><\partial w_> \gt 0[/math] , увеличение [math]w_[/math] увеличивает [math]E[/math] ; наоборот, если [math]\frac<\partial E><\partial w_> \lt 0[/math] , увеличение [math]w_[/math] уменьшает [math]E[/math] . Новый [math]\Delta w_[/math] добавлен к старым весам, и произведение скорости обучения на градиент, умноженный на [math]-1[/math] , гарантирует, что [math]w_[/math] изменения будут всегда уменьшать [math]E[/math] . Другими словами, в следующем уравнении, [math]- \eta \frac<\partial E><\partial w_>[/math] всегда изменяет [math]w_[/math] в такую сторону, что [math]E[/math] уменьшается:
[math] \Delta w_ = — \eta \frac<\partial E><\partial w_> = — \eta \delta_j o_i[/math]
Алгоритм
- [math]\eta[/math] — скорость обучения
- [math]\alpha[/math] — коэффициент инерциальности для сглаживания резких скачков при перемещении по поверхности целевой функции
- [math]\_^[/math] — обучающее множество
- [math]\textrm[/math] — количество повторений
- [math]network(x)[/math] — функция, подающая x на вход сети и возвращающая выходные значения всех ее узлов
- [math]layers[/math] — количество слоев в сети
- [math]layer_i[/math] — множество нейронов в слое i
- [math]output[/math] — множество нейронов в выходном слое
fun BackPropagation: init repeat : for = to : = for : = for = to : for : = for : = = return
Недостатки алгоритма
Несмотря на многочисленные успешные применения обратного распространения, оно не является универсальным решением. Больше всего неприятностей приносит неопределённо долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.

Градиентный спуск может найти локальный минимум вместо глобального
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших выходных значениях, а производная активирующей функции будет очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть.
Локальные минимумы
Градиентный спуск с обратным распространением ошибок гарантирует нахождение только локального минимума функции; также, возникают проблемы с пересечением плато на поверхности функции ошибки.
Примечания
- Алгоритм обучения многослойной нейронной сети методом обратного распространения ошибки
- Neural Nets
- Understanding backpropagation
См. также
- Нейронные сети, перцептрон
- Стохастический градиентный спуск
- Настройка глубокой сети
- Практики реализации нейронных сетей
Источники информации
- https://en.wikipedia.org/wiki/Backpropagation
- https://ru.wikipedia.org/wiki/Метод_обратного_распространения_ошибки
Подробно рассматриваем обратное распространение ошибки для простой нейронной сети. Численный пример
В данной статье мы рассмотрим прямое распространение сигнала и обратное распространение ошибки в полносвязной нейронной сети прямого распространения. В результате получим весь набор формул, необходимых для программной реализации нейронной сети. В завершении статьи рассмотрим численный пример.
«Полносвязная» (fully connected) — означает, что каждый нейрон предыдущего слоя соединён с каждым нейроном следующего слоя. «Прямого распространения» (feedforward) — означает, что сигнал проходит через нейронную сеть в одном направлении от входного к выходному слою.
Полносвязная нейронная сеть прямого распространения («перцептрон») — это простейший и наиболее типичный пример искусственной нейронной сети.
Нейронная сеть как функция
Искусственная нейронная сеть является математической функцией, а точнее — композицией (суперпозицией) функций.
Было доказано (George Cybenko, 1989), что полносвязная нейронная сеть прямого распространения с хотя бы одним скрытым слоем и достаточным количеством нейронов потенциально может аппроксимировать любую непрерывную функцию, т.е. по своей сути она — универсальный аппроксиматор.
«Свойства универсальной аппроксимации встречаются в математике чаще, чем можно было бы ожидать. Например, теорема Вейерштрасса — Стоуна доказывает, что любая непрерывная функция на замкнутом интервале может быть приближена многочленной функцией. Если ослабить наши критерии далее, можно использовать ряды Тейлора и ряды Фурье, предлагающие некоторые возможности универсальной аппроксимации (в пределах их областей схождения). Тот факт, что универсальная сходимость — довольно обычное явление в математике, дает частичное обоснование эмпирического наблюдения, что существует много малых вариантов полносвязных сетей, которые, судя по всему, дают свойство универсальной аппроксимации».
— Рамсундар Б., Заде Р.Б. TensorFlow для глубокого обучения. Спб., 2019. С. 101.
Запишем нейронную сеть, которую мы будем рассматривать в данной статье, в виде функции:
где — вектор входных значений — первый слой, — второй, скрытый и — третий слои нейронной сети, , — векторы смещений и , — матрицы весов второго и третьего слоёв соответственно, — вектор-функция активации второго слоя, — вектор-функция активации третьего, последнего слоя и, соответственно, вектор выходных значений нейронной сети.
Мы будем использовать принятую в литературе по нейронам сетям запись , где — вектор-столбец (в литературе по математике под вектором стандартно (по умолчанию) понимается вектор-столбец). Произведение матриц определено, если число столбцов равно числу строк . Таким образом число столбцов матрицы равно числу строк векторов и .
Для комфортного чтения статьи необходимо обладать некоторым знанием линейной алгебры (обязательный минимум — операции над матрицами), производной сложной функции и частных производных.
Дизайн нейронной сети
Нейронная сеть имеет три слоя с тремя нейронами в каждом из них. Нелинейное изменение проходящего через сеть сигнала обеспечивает функция активации сигмоид (sigmoid) на скрытом и выходном слоях:
Поскольку на практике большинство реальных данных имеют нелинейный характер, используются нелинейные функции активации, позволяющие извлекать нелинейные зависимости в данных.

Перепишем уравнение рассматриваемой сети для заданных параметров:
Функция активации поэлементно применяется к каждому элементу соответствующего вектора .
Прямое распространение сигнала
Запишем уравнения для прямого прохождения сигнала через нейронную сеть:
где — номер соответствующего целевого (вектора ) и выходного значений, — число выходных значений.
Таким образом, функция стоимости для нашей нейронной сети в развёрнутом виде:
Функция стоимости показывает нам насколько сильно отличаются текущие значения нейронной сети от целевых.
Обратное распространение ошибки и обновление
В сущности, для реализации алгоритма обратного распространения ошибки используется довольно простая идея.
Градиент (в общем случае) — вектор, определяющий направление наискорейшего роста функции нескольких переменных. Вычитая из текущих значений весов и смещений соответствующие значения частных производных как элементов градиента функции стоимости , мы будем приближаться к одному из ближайших (относительно начальной точки) минимумов функции стоимости и, таким образом, уменьшать величину ошибки. Согласно необходимому условию экстремума, в точках экстремума функции многих переменных её градиент равен нулю, .
Этот подход называется алгоритмом градиентного спуска. Иногда может возникать путаница или отождествление этих двух алгоритмов, поскольку они тесно взаимосвязаны и один используется для реализации другого.
Несмотря на простоту и эффективность, алгоритм градиентного спуска в общем случае имеет свои ограничения, например, седловая точка, локальный минимум, перетренировка (overtraining) (попадание в глобальный минимум).
Найдём частные производные по всем элементам матрицы :
поскольку — константа, то ,
Преобразуем функцию активации сигмоид и найдём её производную:
В производной по матрице мы находим производную по каждому из её элементов.
Раскроем сумму для переменной матрицы :
Найдём частную производную по переменной . Поскольку
Преобразуем сигмоид и получим окончательную форму выражения для :
Обратное распространение ошибки является частным случаем автоматического дифференцирования, для реализации которого нам и необходимо привести все вычислительные выражения к определённому виду.
Таким же образом для переменных и получим:
Найдём новые значения (обновлённые веса) для переменных , и :
где (и́та) — буква греческого алфавита, обычно используемая для обозначения скорости обучения (learning rate), её значение должно быть установлено на промежутке от 0 до 1; * — новое значение переменной.
Найдём остальные частные производные для матрицы . Раскроем сумму для :
Найдём частную производную по переменной :
Преобразуем сигмоид и получим окончательную форму выражения для :
Таким же образом для переменных и получим:
Найдём новые значения (обновлённые веса) для переменных , и:
Раскроем сумму для :
Найдём частную производную по переменной :
Преобразуем сигмоид и получим окончательную форму выражения для :
Таким же образом для переменных и получим:
Найдём новые значения (обновлённые веса) для переменных , и :
Теперь найдём частные производные по всем элементам вектора :
Найдём частную производную по :
Преобразуем сигмоид и получим окончательную форму выражения для :
Найдём новое значение для смещения :
Вычислим частные производные по и :
Найдём новые значения для и:
Найдём частные производные по всем элементам матрицы . Раскроем сумму для переменной матрицы . Поскольку
тогда сумма для переменной матрицы :
Найдём новое значение (обновлённый вес) для переменной :
Найдём остальные частные производные и их новые значения для матрицы .
Теперь найдём частные производные по всем элементам вектора . Раскроем сумму для переменной :
Найдём новое значение для :
Найдём остальные частные производные для вектора :
Найдём новые значения для переменных и :
Численный пример
Задача обучения нейронной сети состоит в аппроксимации некоторой неизвестной функции, которая отображает в .
Другими словами, существует некоторая неизвестная нам функция , которая для набора значений независимых переменных выдаёт результат, соответствующий набору значений зависимых переменных . Задача нейронной сети в результате обучения «заменить», приблизить, т.е. аппроксимировать неизвестную функцию . В случае успешного решения задачи, значения нашей нейронной сети на выходном слое будут приблизительно равны значениям вектора аппроксимируемой функции.
Выберем случайным образом следующие начальные значения для нашей нейронной сети:
А также входные и целевые значения:
После первого прямого прохождения сигнала значения скрытого и выходного слоёв:
Для скорости обучения установим значение .
Вычислим для первой эпохи (epoch) обучения нейронной сети обновлённые значения весов и :
Новые значения других весов и смещений находятся аналогичным образом, в соответствии с полученными ранее формулами.
После 10 000 эпох обучения матрицы весов и выходной слой имеют следующие значения:
Обобщение для произвольного числа слоёв
Мы рассмотрели частный случай алгоритма обратного распространения ошибки для нейронной сети с одним скрытым слоем. Запишем формулы для реализации нейронной сети с произвольным числом скрытых слоёв.
где — номер выходного слоя, — индекс строки матрицы весов, — число выходных значений.
Надеемся, что статья будет интересной и полезной для всех, кто приступает к изучению глубинного обучения и нейронных сетей!
- artifical intelligence
- machine learning
- deep learning
- neural networks
- backpropagation
- машинное обучение
- глубинное обучение
- нейронные сети
- обратное распространение ошибки
- cезон machine learning
- Алгоритмы
- Математика
- Машинное обучение
- Искусственный интеллект
Алгоритм обратного распространения ошибки (Back propagation algorithm)
Алгоритм обратного распространения ошибки — популярный алгоритм обучения плоскослоистых нейронных сетей прямого распространения (многослойных персептронов). Относится к методам обучения с учителем, поэтому требует, чтобы в обучающих примерах были заданы целевые значения. Также является одним из наиболее известных алгоритмов машинного обучения.
В основе идеи алгоритма лежит использование выходной ошибки нейронной сети
E = 1 2 k ∑ i = 1 ( y − y ′ ) 2
для вычисления величин коррекции весов нейронов в ее скрытых слоях, где k — число выходных нейронов сети, y — целевое значение, y ′ — фактическое выходное значение. Алгоритм является итеративным и использует принцип обучения «по шагам» (обучение в режиме on-line), когда веса нейронов сети корректируются после подачи на ее вход одного обучающего примера.
На каждой итерации происходит два прохода сети — прямой и обратный. На прямом входной вектор распространяется от входов сети к ее выходам и формирует некоторый выходной вектор, соответствующий текущему (фактическому) состоянию весов. Затем вычисляется ошибка нейронной сети как разность между фактическим и целевым значениями. На обратном проходе эта ошибка распространяется от выхода сети к ее входам, и производится коррекция весов нейронов в соответствии с правилом:
Δ w j , i ( n ) = − η ∂ E a v ∂ w i j , (1)
где w j , i — вес i-й связи j-го нейрона, η — параметр скорости обучения, который позволяет дополнительно управлять величиной шага коррекции Δ w j , i с целью более точной настройки на минимум ошибки и подбирается экспериментально в процессе обучения (изменяется в интервале от 0 до 1).
Учитывая, что выходная сумма j-го нейрона равна
S j = n ∑ i = 1 w i j x i ,
можно показать, что
∂ E ∂ w i j = ∂ E ∂ S j ∂ S j ∂ w i j = x i ∂ E ∂ S j .
Из последнего выражения следует, что дифференциал ∂ S j активационной функции нейронов сети f ( s ) должен существовать и не быть равным нулю в любой точке, т.е. активационная функция должна быть дефференцируема на всей числовой оси. Поэтому для применения метода обратного распространения используют сигмоидальные активационные функции, например, логистическую или гиперболический тангенс.
Таким образом, алгоритм использует так называемый стохастический градиентный спуск, «продвигаясь» в многомерном пространстве весов в направлении антиградиента с целью достичь минимума функции ошибки.
На практике обучение продолжают не до точной настройки сети на минимум функции ошибки, а до тех пор, пока не будет достигнуто достаточно точное его приближение. Это позволит, с одной стороны, уменьшить число итераций обучения, а с другой — избежать переобучения сети.
В настоящее время разработано множество модификаций алгоритма обратного распространения. Например, используется обучение не «по шагам» (когда выходная ошибка вычисляется, а веса корректируются на каждом примере), а «по эпохам» в режиме off-line (когда изменение весов производится после подачи на вход сети всех примеров обучающего множества, а ошибка усредняется по всем примерам).
Обучение «по эпохам» является более устойчивым к выбросам и аномальным значениям целевой переменной за счет усреднения ошибки по многим примерам. Но при этом повышается вероятность «застревания» алгоритма в локальных минимумах. Вероятность этого для обучения «по шагам» меньше, поскольку использование отдельных примеров создает «шум», который «выталкивает» алгоритм из ям градиентного рельефа.
К преимуществам алгоритма обратного распространения ошибки относятся простота реализации и устойчивость к аномалиям и выбросам в данных. К недостаткам можно отнести:
- неопределенно долгий процесс обучения;
- возможность «паралича сети», когда при больших значениях рабочая точка активационной функции оказывается в области насыщения сигмоиды и производная в выражении (1) становится близкой к 0, а коррекции весов практически не происходит и процесс обучения «замирает»;
- уязвимость алгоритма к попаданию в локальные минимумы функции ошибки.
Впервые алгоритм был описан в 1974 г. А.И. Галушкиным, а также, независимо и одновременно, Полом Дж. Вербосом. Далее существенно развит в 1986 г. Дэвидом И. Румельхартом.