7.7. Работа со стеком
Прежде, чем двигаться дальше в описании команд перехода, нам необходимо изучить понятие стека и рассмотреть команды работы со стеком.
Стеком называется сегмент памяти, на начало которого указывает сегментный регистр SS. При работе программы в регистр SS можно последовательно загружать адреса начал нескольких сегментов, поэтому иногда говорят, что в программе несколько стеков. Однако в каждый момент стек только один – тот, на который сейчас указывает регистр SS. Именно этот стек мы и будем иметь в виду.
Кроме начала, у стека есть текущая позиция – вершина стека, её смещение от начала сегмента стека записано в регистре SP (stack pointer). Следовательно, как мы уже знаем, физический адрес вершины стека можно получить по формуле Афиз = (SS*16 + SP)mod 2 20 .
Стек есть аппаратная реализация абстрактной структуры данных стек, с которой Вы познакомились в прошлом семестре. В стек можно записывать (и, соответственно, читать из него) только машинные слова, чтение и запись байтов не предусмотрена в архитектуре рассматриваемого нами компьютера. Это, конечно, не значит, что в стеке нельзя хранить байты, двойные слова и т.д., просто нет машинных команд для записи в стек и чтения из стека данных этих форматов.
В соответствие с определением понятия стек последнее записанное в него слово будет читаться из стека первым. Это так называемое правило «последний пришёл – первый вышел» (английское сокращение LIFO). 1 Обычно стек принято изображать «растущим» снизу-вверх. Как следствие получается, что конец стека фиксирован и расположен снизу, а вершина двигается вверх (при записи в стек) и вниз (при чтении из стека).
В каждый момент времени регистр SP указывает на последнее слово, записанное в стек. Обычно стек изображают, как показано на рис. 7.1.
Начало стека SS
Вершина стека SP
SP для пустого стека
Рис. 7.1. Так мы будем изображать стек.
На нашем рисунке, как обычно, стек растёт снизу-вверх, занятая часть стека закрашена. В начале работы программы, когда стек пустой, регистр SP указывает на первое слово за концом стека. Особым является случай, когда стек имеет максимальный размер 2 16 байт, в этом случае значение регистра SP для пустого стека равно нулю, т.е. совпадает со значением этого регистра и для полного стека, поэтому стеки максимального размера использовать не рекомендуется, так как будет затруднён контроль пустоты и переполнения стека.
Обычно для резервирования памяти под стек на языке Ассемблера описывается специальный сегмент стека. В наших предыдущих программах мы делали это таким образом:
stack segment stack
dw 64 dup (?)
stack ends
Имя сегмента стека и способ резервирования памяти может быть любым, например, можно описать такой стек:
st_1 segment stack
db 128 dup (?)
То, что этот сегмент будет при выполнении программы использоваться именно как сегмент стека, указывается параметром stack директивы segment. Этот параметр является служебным словом языка Ассемблера и, вообще говоря, не должен употребляться ни в каком другом смысле. 2
В нашем последнем примере размер сегмента стека установлен в 64 слова, поэтому в начале работы регистр SP будет иметь значение 128, т.е., как мы и говорили ранее, указывает на первое слово за концом стека. Области памяти в стеке обычно не имеют имён, так как доступ к ним, как правило, производится только с использованием регистров.
Обратим здесь внимание на важное обстоятельство. Перед началом работы со стеком необходимо загрузить в регистры SS и SP требуемые значения, однако сама программа это сделать не может, т.к. при выполнении самой первой команды программы стек уже должен быть доступен (почему это так мы узнаем в нашем курсе позже, когда будем изучать механизм прерываний). Поэтому в рассмотренных выше примерах программ мы сами не загружали в регистры SS и SP никаких начальных значений. Как мы узнаем позже, перед началом выполнения нашей программы этим регистрам присвоит значения специальная системная программа загрузчик, которая размещает нашу программу в памяти и передаёт управление на команду, помеченную той меткой, которая указана в конце нашего модуля в качестве параметра директивы end. Разумеется, позже при работе программы мы и сами можем загрузить в регистр SS новое значение, это будет переключением на другой сегмент стека.
Рассмотрим сначала те команды работы со стеком, которые не являются командами перехода. Команда
где op1 может иметь форматы r16, m16, CS,DS,SS,ES, записывает в стек слово, определяемое своим операндом. Это команда выполняется по правилу:
Здесь запись обозначает адрес в стеке, вычисляемый по формуле
Особым случаем является команда
В младших моделях нашего семейства она выполняется, как описано выше, а в старших – по схеме
Следовательно, если мы хотим, чтобы наша программа правильно работала на всех моделях семейства, надо с осторожностью использовать в программе команду push SP .
где op1 может иметь форматы r16, m16, SS, DS, ES, читает из стека слово и записывает его в место памяти, определяемое своим операндом. Это команда выполняется по правилу:
записывает в стек регистр флагов FLAGS, а команда
наоборот, читает из стека слово и записывает его в регистр флагов FLAGS. Эти команды удобны для сохранения в стеке и восстановления значения регистра флагов.
В старших моделях нашего семейства появились две новые удобные команды работы со стеком. Команда
последовательно записывает в стек регистры AX,CX,DX,BX,SP (этот регистр записывается до его изменения), BP,SI и DI. Команда
последовательно считывает из стека и записывает значения в эти же регистры (но, естественно, в обратном порядке). Эти команды предназначены для сохранения в стеке и восстановления значений сразу всех этих регистров.
Команды записи в стек не проверяют того, что стек уже полон, для надёжного программирования это должен делать сам программист. Например, для проверки того, что стек уже полон, и писать в него нельзя, можно использовать команду сравнения
cmp SP,0; стек уже полон ?
и выполнить условный переход, если регистр SP равен нулю. Особым случаем здесь будет стек максимального размера 2 16 байт, для него значение регистра SP=0 как для полного, так и для пустого стека (обязательно понять это!), поэтому не рекомендуется использовать стек максимального размера.
Аналогично для проверки того, что стек уже пуст, и читать из него нельзя, следует использовать команду сравнения
cmp SP,K; стек пуст ?
где K – чётное число – размер стека в байтах. Если размер стека в байтах нечётный, то стек полон при SP=1, т.е. в общем случае необходима проверка SP
В качестве примера использования стека рассмотрим программу для решения следующей задачи. Необходимо вводить целые беззнаковые числа до тех пор, пока не будет введено число ноль (признак конца ввода). Затем следует вывести в обратном порядке то из введённых чисел, которые принадлежат диапазону [2..100] (сделаем спецификацию, что таких чисел может быть не более 300). Ниже приведено возможное решение этой задачи.
include io.asm
st segment stack
db 128 dup (?); это для системных нужд
dw 300 dup (?); это для хранения наших чисел
code segment
assume cs:code,ds:code,ss:st
T1 db ′Вводите числа до нуля$′
T2 db ′Числа в обратном порядке:′,10,13,′$′
T3 db ′Ошибка – много чисел!′,10,13,′$′
mov ax,code
mov dx, offset T1; Приглашение к вводу
sub cx,cx; хороший способ для cx:=0
L: inint ax
cmp ax,0; проверка конца ввода
je Pech; на вывод результата
ja L; проверка диапазона
cmp cx,300; в стеке уже 300 чисел ?
push ax; запись числа в стек
inc cx; счетчик количества чисел в стеке
Pech: jcxz Kon; нет чисел в стеке
mov dx, offset T2
L1: pop ax
outword ax,10; ширина поля вывода=10
Kon: finish
Err: mov dx,T3
end program_start
Заметим, что в нашей программе нет собственно переменных, а только строковые константы, поэтому мы не описали отдельный сегмент данных, а разместили эти строковые константы в кодовом сегменте. Можно считать, что сегменты данных и кода в нашей программе совмещены. Мы разместили строковые константы в начале сегмента кода, перед входной точкой программы, но с таким же успехом можно разместить эти строки и в конце кодового сегмента после последней макрокоманды finish.
Обратите внимание, как мы выбрали размер стека: 128 байт мы зарезервировали для системных нужд (как уже упоминалось, стеком будут пользоваться и другие программы, подробнее об этом будет рассказано далее) и 300 слов мы отвели для хранения введённых нами чисел. При реализации этой программы может возникнуть желание определять, что введено слишком много чисел, анализируя переполнение стека. Другими словами, вместо проверки
cmp cx,300; в стеке уже 300 чисел ?
казалось бы, можно было поставить проверку исчерпания стека
cmp SP,2; стек уже полон ?
Это, однако, может повлечь за собой тяжёлую ошибку. Дело в том, что в стеке может остаться совсем мало места, а, как мы знаем, стек использует не только наша, но и другие программы, которые в этом случае будут работать неправильно.
Теперь, после того, как мы научились работать со стеком, вернёмся к дальнейшему рассмотрению команд перехода.
Стек
Стеком называют область программы для временного хранения произвольных данных. Разумеется, данные можно сохранять и в сегменте данных, однако в этом случае для каждого сохраняемого на время данного надо заводить отдельную именованную ячейку памяти, что увеличивает размер программы и количество используемых имен. Удобство стека заключается в том, что его область используется многократно, причем сохранение в стеке данных и выборка их оттуда выполняется с помощью эффективных команд push и pop без указания каких-либо имен.
Стек традиционно используется, например, для сохранения содержимого регистров, используемых программой, перед вызовом подпрограммы, которая, в свою очередь, будет использовать регистры процессора «в своих личных целях». Исходное содержимое регистров извлекается из стека после возврата из подпрограммы. Другой распространенный прием — передача подпрограмме требуемых ею параметров через стек. Подпрограмма, зная, в каком порядке помещены в стек параметры, может забрать их оттуда и использовать при своем выполнении.
Отличительной особенностью стека является своеобразный порядок выборки содержащихся в нем данных: в любой момент времени в стеке доступен только верхний элемент, т.е. элемент, загруженный в стек последним. Выгрузка из стека верхнего элемента делает доступным следующий элемент.
Элементы стека располагаются в области памяти, отведенной под стек, начиная со дна стека (т.е. с его максимального адреса) по последовательно уменьшающимся адресам. Адрес верхнего, доступного элемента хранится в регистре-указателе стека SP. Как и любая другая область памяти программы, стек должен входить в какой-то сегмент или образовывать отдельный сегмент. В любом случае сегментный адрес этого сегмента помещается в сегментный регистр стека SS. Таким образом, пара регистров SS:SP описывают адрес доступной ячейки стека: в SS хранится сегментный адрес стека, а в SP — смещение последнего сохраненного в стеке данного (рис. 1.10, а). Обратите внимание на то, что в исходном состоянии указатель стека SP указывает на ячейку, лежащую под дном стека и не входящую в него.

Рис. 1.10. Организация стека:
а — исходное состояние, б — после загрузки одного элемента (в данном примере — содержимого регистра АХ), в — после загрузки второго элемента (содержимого регистра DS), г — после выгрузки одного элемента, д — после выгрузки двух элементов и возврата в исходное состояние.
Загрузка в стек осуществляется специальной командой работы со стеком push (протолкнуть). Эта команда сначала уменьшает на 2 содержимое указателя стека, а затем помещает операнд по адресу в SP. Если, например, мы хотим временно сохранить в стеке содержимое регистра АХ, следует выполнить команду
Стек переходит в состояние, показанное на рис. 1.10, б. Видно, что указатель стека смещается на два байта вверх (в сторону меньших адресов) и по этому адресу записывается указанный в команде проталкивания операнд. Следующая команда загрузки в стек, например,
переведет стек в состояние, показанное на рис. 1.10, в. В стеке будут теперь храниться два элемента, причем доступным будет только верхний, на который указывает указатель стека SP. Если спустя какое-то время нам понадобилось восстановить исходное содержимое сохраненных в стеке регистров, мы должны выполнить команды выгрузки из стека pop (вытолкнуть):
Состояние стека после выполнения первой команды показано на рис. 1.10, г, а после второй — на рис. 1.10, д. Для правильного восстановления содержимого регистров выгрузка из стека должна выполняться в порядке, строго противоположном загрузке — сначала выгружается элемент, загруженный последним, затем предыдущий элемент и т.д.
Совсем не обязательно при восстановлении данных помещать их туда, где они были перед сохранением. Например, можно поместить в стек содержимое DS, а извлечь его оттуда в другой сегментный регистр — ES;
Это распространенный прием для перенесения содержимого одного регистра в другой, особенно, если второй регистр — сегментный.
Обратите внимание (см. рис 1.10) на то, что после выгрузки сохраненных в стеке данных они физически не стерлись, а остались в области стека на своих местах. Правда, при «стандартной» работе со стеком они оказываются недоступными. Действительно, поскольку указатель стека SP указывает под дно стека, стек считается пустым; очередная команда push поместит новое данное на место сохраненного ранее содержимого АХ, затерев его. Однако пока стек физически не затерт, сохраненными и уже выбранными из него данными можно пользоваться, если помнить, в каком порядке они расположены в стеке. Этот прием часто используется при работе с подпрограммами.
Какого размера должен быть стек? Это зависит от того, насколько интенсивно он используется в программе. Если, например, планируется хранить в стеке массив объемом 10 000 байт, то стек должен быть не меньше этого размера. При этом надо иметь в виду, что в ряде случаев стек автоматически используется системой, в частности, при выполнении команды прерывания int 21h. По этой команде сначала процессор помещает в стек адрес возврата, а затем DOS отправляет туда же содержимое регистров и другую информацию, относящуюся к прерванной программе. Поэтому, даже если программа совсем не использует стек, он все же должен присутствовать в программе и иметь размер не менее нескольких десятков слов. В нашем первом примере мы отвели под стек 128 слов, что безусловно достаточно.
Fore kc .ru
Рефераты, дипломы, курсовые, выпускные и квалификационные работы, диссертации, учебники, учебные пособия, лекции, методические пособия и рекомендации, программы и курсы обучения, публикации из профильных изданий
Как работать со стеком в ассемблере
Стек — это динамическая структура данных, которая хранит важную информация о программе, включая локальные переменные, информацию о подпрограммах и временные данные. В архитектуре x86-64 стек реализуется с помощью сегмента стека. Процессор x86-64 управляет стеком через регистр RSP (указатель стека). Когда программа начинает выполняться, операционная система инициализирует регистр RSP адресом последней ячейки памяти в сегменте стека. В процессе работы программы данные записываются в сегмент стека или, наоборот, извлекаются из стека.
Стек растет от больших адресов к меньшим, то есть при добавлении в стек данных, адрес добавляемых данных будет уменьшаться. При запуске программы обычно стек выровнен по 8-байтовой границе. Например, RSP может хранить адрес 0x0000009BA9EFF9A8 (адрес оканчивается на 8).
Для добавления данных в стек применяется инструкция push , которая имеет следующий синтаксис:
push reg16 push reg64 push mem16 push mem64 pushw constant16 push constant32 ; расширяется до 64 бит
Итак, мы можем добавить в стек значения 16- и 64-разрядного регистра, 16- и 64-разрядной переменной и 16- и 32-разрядной константы (32-битная констранта расширяется до 64 бит).
При выполнении инструкции push от значения регистра RSP вычитается размер операнда. А по адресу, который хранится в стеке, помещается значение операнда.
RSP = RSP - размер операнда [RSP] = значение операнда
Инструкция pop позволяет, наоборот, взять из стека значение, адрес которого хранится в текущий момент в регистре RSP . Эта инструкция имеет следующий синтаксис
pop reg16 pop reg64 pop memory16 pop memory64
Инструкция в качестве операнда получает место, куда надо сохранить данные из стека. Это может быть или 16- и 64-разрядный регистр, или 16- и 64-разрядная переменная. При выполнении этой инструкции в операнд помещается значение, которое хранится в адресе из RSP. А само значение RSP увеличивается на размер операнда:
operand = [RSP] RSP = RSP + размер операнда
Например, возьмем следующую программу:
.code main proc mov rdx, 15 push rdx ; в конец стека помещаем содержимое регистра RDX pop rax ; значение из конца стека помещаем в регистр RAX ret main endp end
Допустим, регистр RSP содержит изначально адрес 00FF_FFF8h.
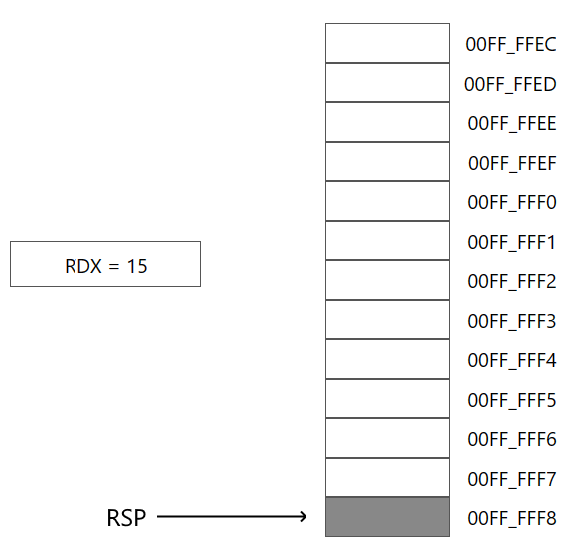
Пусть в регистре RDX хранится некоторое значение, которое с помощи инструкции push заталкивается в стек:
push rdx
В результате в последующие 8 байт начиная с адреса, который хранится в RSP, помещается значение из регистра RDX (в данном случае число 15). А в регистр RSP будет помещен адрес RSP-8, то есть условно 00FF_FFF0h и сохранит текущее значение регистра RDX в ячейках памяти начиная с 00FF_FFF0h по 00FF_FFF7h, то есть займет 8 байт.
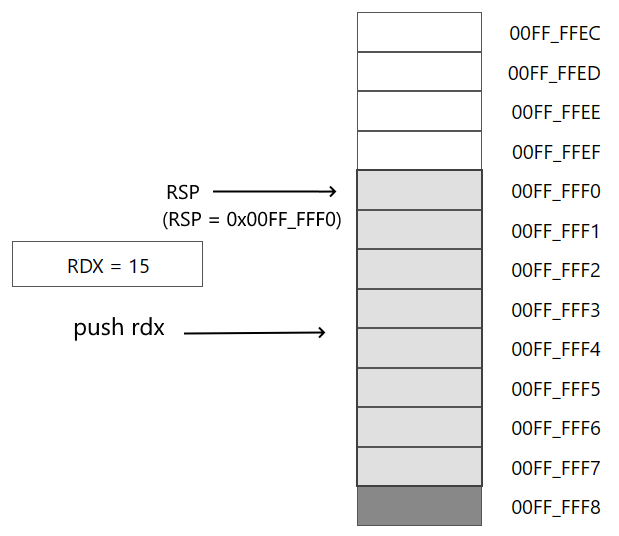
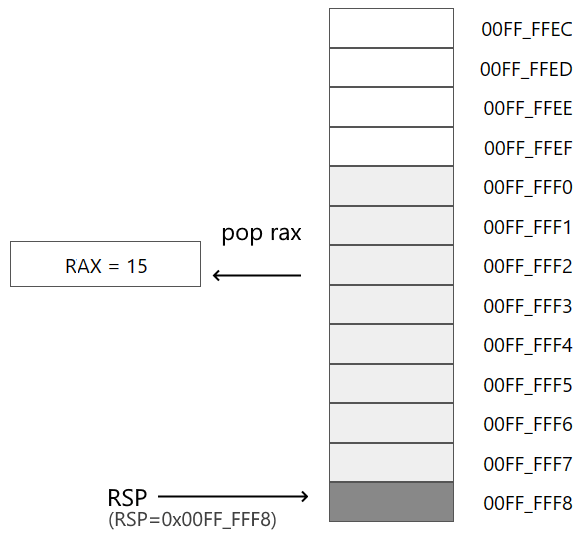
Затем извлекаем из стека значение по адресу, который хранится в RSP, в регистр RAX:
pop rax
В результате в RAX помещается число из стека (в данном случае число 15). А в регистр RSP будет помещен адрес RSP+8, то есть условно 00FF_FFF0h.
Принцип LIFO и сохранение регистров в стек
Наиболее распространенное использование команд push и pop — это сохранение значений регистров во время промежуточных вычислений. Поскольку регистры — лучшее место для хранения временных значений, и регистры также могут потребоваться для других операций, поэтому в процессе программы легко исчерпать регистры. Инструкции push и pop позволяют сохранить начальные значения регистров при старте программы, а при завершении программы восстановить эти значения.
Следует учитывать, что стек представляет структуру LIFO (Last In, First Out или Последний вошел, первый вышел), что значит, что получение данных из стека происходит в порядке, обратном их добавлению. Рассмотрим следующую программу:
.code main proc mov rax, 11 mov rdx, 33 push rax push rdx pop rax pop rdx ret main endp end
Допустим, в самом начале программы до добавления данных стек регистр RSP хранит адрес 00FF_FFF8.
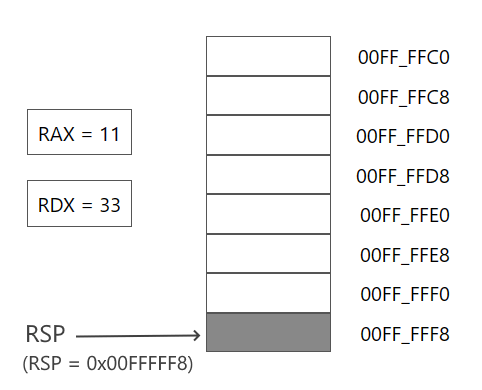
Затем добавляем в стек значение регистра RAX:
push rax
Адрес в RSP смещается на 8 байтов и указывает на адрес значения из регистра RAX
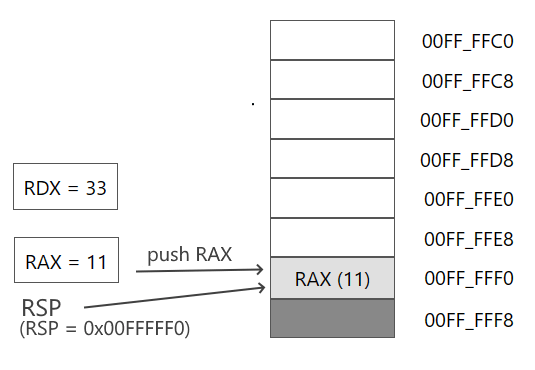
Далее добавляем в стек значение регистра RDX:
push rdx
Адрес в RSP смещается на 8 байтов и указывает на адрес значения из регистра RDX
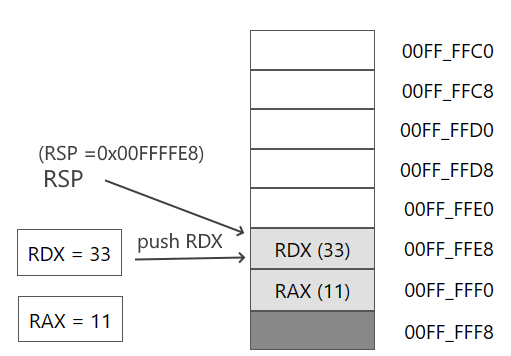
После добавления мы последовательно извлекаем данные. Первая инструкция извлекает данные, на которые указывает регистр RSP, в регистр RAX:
pop rax
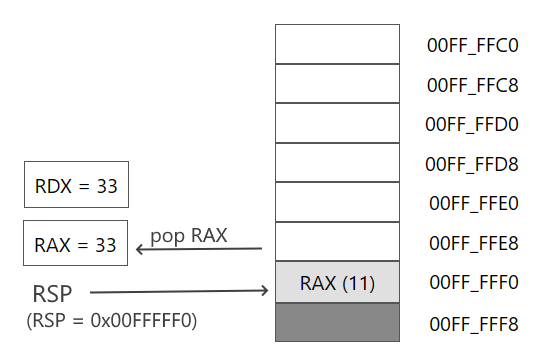
Однако поскольку RSP перед операцией извлечения указывал на адрес последнего добавленного значения — значения регистра RDX, то регистр RAX получит значение регистра RDX. Соответственно при последующей инструкции pop:
pop rdx
Регистр RDX получить значение регистра RAX, которое было в регистре RAX до добавления в стек.
Поэтому если мы хотим восстановить начальные значения регистров, то нам надо извлекать значения в порядке, обратном добавлению
push rax push rdx pop rdx ; Последним добавлено значение RDX, поэтому сначала извлекаем в RDX pop rax
В любом случае стоит помнить, что количество инструкций push и pop должно быть равно, сколько раз мы добавили данные в стек, столько раз мы должны получить данные из стека.
Сохранение флагов состояния
Ассемблер предоставляет дополнительную пару инструкций pushfq и popfq для сохранения и восстановления соответственно регистра RFLAGS (и всех флагов состояния). Например:
.code main proc pushfq ; сохраняем значения флагов mov al, 255 add al, 2 ; 255 + 2 = 257 - флаг CF будет установлен popfq ; восстанавливаем значения флагов jc set ; если флаг CF установлен, переход к метке set mov rax, 0 ret set: mov rax, 1 ret main endp end
Здесь инструкцией pushfq сначала сохраняем флаги. По умолчанию флаг переноса CF будет равен 0.
Затем выполняем сложение 255 + 2, что даст 257 и что очевидно за пределы разрядности регистра AL, соответственно будет установлен флаг переноса CF. Далее с помощью инструкции jc set переходим к метке set, если флаг CF установлен. Однако перед этой инструкцией мы восстанавливаем флаги — popfq . То есть флаг CF получит свое значение 0, и никакого перехода к метке set не произойдет.
Восстановление стека без извлечения данных
При завершении программы следует восстановить адрес в RSP. Как выше было показано, для этого мы можем использовать инструкцию pop . Однако может сложиться ситуация, что данные не требуется извлекать из стека. Например, в зависимости от некоторых условий данные могут понадобиться, а могут не понадобиться. Если данные не нужны, извлекать каждые 8 байт отдельно с помощью инструкции pop не имеет смысла, особенно если надо извлечь много данных из стека. И в этом случае мы можем восстановить адрес в RSP, просто прибавив нужное значение — смещение относительно начального адреса. Например:
.code main proc mov rax, 2 mov rdx, 3 push rax push rdx add rsp, 16 ; прибавляем к адресу в RSP 16 байт ret main endp end
Здесь в стек помещаем значения двух регистров — RAX и RDX, то есть адрес в RSP уменьшится на 16 байт (совокупный размер двух регистров). И чтобы быстро восстановить стек, прибавляем к адресу в RSP 16 байт:
add rsp, 16
Подобным образом можно вычитать из адреса в RSP определенное число, тем самым резервируя в стеке некоторое пространство:
.code main proc sub rsp, 16 ; смещаем адрес в RSP на 16 байт mov rax, 2 add rsp, 16 ; восстанавливаем адрес в RSP ret main endp end
Вычитание определенного количество байтов из стека может потребоваться при взаимодействии с некоторыми внешними функциями, например, на языках C/С++ для резервирования места для параметров функций или для выравнивания стека. Так, до вызова функций в Windows в соответствии с Microsoft ABI стек должен быть выровнен по 16-байтовой границе. При использовании инструкции push для сохранения значения регистра перед вызовом внешней функции надо убедиться, адрес RSP кратен 16 байтам.
Косвенная адресация в стеке
Как и в случае с любым другим регистром, в отношении регистра стека RSP можно использовать косвенную адресацию и обращаться к данным в стеке без смещения указателя RSP. Например:
.code main proc sub rsp, 16 ; резервируем в стеке 16 байт mov rdx, 11 mov [rsp], rdx ; помещаем в стек значение регистра RDX mov rax, [rsp] ; в RAX помещаем значение по адресу из RSP - число 11 add rsp, 16 ; восстанавливаем указатель стека ret main endp end
В данном случае в стек помещаем число из регистра RDX — число 11.
mov [rsp], rdx
Подобную форму размещения данных в стеке можно рассматривать как альтернативу инструкции push , если нам не надо изменять значение указателя стека RSP. То есть мы можем сохранить таким образом данные по адресу в RSP, но после этого RSP продолжает хранить тот же адрес.
Далее в регистр RAX помещаем значение, которое располагается по адресу из RSP. Фактически это тот адрес, где располагается число 11.
mov rax, [rsp]
Аналогично можно применять смещения и масштабирование. Например:
.code main proc push 12 push 13 push 14 mov rax, [rsp + 8] ; [rsp + 8] - адрес значения 13 ; извлекаем сохраненные значения в r8, r9, r10 pop r8 pop r9 pop r10 ret main endp end
Здесь в стек последовательно помещаются три числа 12, 13, 14. Каждое число будет занимать 8 байт. После добавления адрес в RSP будет указывать на адрес последнего добавленного числа — 14. И чтобы, например, получить предыдущее число — 13, нам надо к адресу в RSP прибавить 8. И в данном случае получаем это число в регистр RAX.
mov rax, [rsp + 8]
Соотвественно чтобы получить из стека первое число — 12, надо к адресу в RSP прибавить 16:
mov rax, [rsp + 16]
.code main proc sub rsp, 16 ; резервируем в стеке 16 байт mov rbx, 12 mov rdx, 13 mov [rsp], rbx ; помещаем значение из RBX по адресу RSP mov [rsp+8], rdx ; помещаем значение из RDX по адресу RSP+8 mov rax, [rsp] ; в RAX помещаем значение по адресу из RSP add rax, [rsp+8] ; складываем с числом из RSP+8 add rsp, 16 ; восстанавливаем данные из стека ret main endp end
Здесь по адресу RSP располагается значение региста RBX, а по адресу RSP+8 — регистра RDX. В RAX извлекаем значение по адресу RSP (12), и затем складываем его со значением из RSP+8 (13). Таким образом, в RAX будет число 25.
Ограничения места в стеке
По умолчанию данные в стеке занимают то место, которое соответствует размеру регистра. Так, инструкция mov [rsp], rbx помещала в стек 8 байт из RBX. То есть данные в стеке занимали 8 байт. Однако в примере выше в RBX хранится число, для которого достаточно и 1 байта, для него не требуется аж 8 байт. Пространство в стеке расходуется не экономично. В этом случае с помощью преобразования данных мы можем явным образом указать, сколько байтов мы хотим использовать в стеке
.code main proc sub rsp, 16 ; резервируем в стеке 16 байт mov rbx, 11 mov rdx, 12 mov [rsp], bl ; помещаем байт из BL по адресу RSP mov [rsp+1], dl ; помещаем байт из DL по адресу RSP+1 movzx rax, byte ptr [rsp] ; в AL помещаем значение по адресу из RSP add al, byte ptr [rsp+1] ; складываем с числом из RSP+1 add rsp, 16 ; восстанавливаем данные из стека ret main endp end
Здесь в RAX извлекаем только один байт:
movzx rax, byte ptr [rsp]
Затем добавляем в AL еще один байт из стека, который хранится по адресу RSP+1:
add al, byte ptr [rsp+1]
Преобразования данных могут быть особенно актуальны, если необходимо поместить в стек непосредственный операнд:
.code main proc sub rsp, 16 ; резервируем в стеке 16 байт mov qword ptr [rsp], 11 ; в стек помещаем число 11 - оно занимает 8 байт mov word ptr [rsp+8], 15 ; по адресу в RSP+8 помещаем 2-байтное число 15 mov rax, qword ptr [rsp] ; RAX = 11 add ax, word ptr [rsp+8] ; складываем с числом из RSP+8 add rsp, 16 ; восстанавливаем данные из стека ret main endp end
Здесь сначала помещаем в стек число 11, которое будет занисать 8 байт, так как мы приводим к типу qword:
mov qword ptr [rsp], 11
Затем по адресу RSP+2 помещаем число 15, которое будет занимать 2 байта:
mov word ptr [rsp+8], 15
Затем извлекаем эти данные и складываем их:
mov rax, qword ptr [rsp] ; RAX = 11 add ax, word ptr [rsp+8] ; складываем с числом из RSP+8
Стоит обратить внимание, что тип извлекаемых данных соответствует размеру регистра, либо при извлечение 1 байта применется операция расширения movzx/movsx . Некорректное извлечение может привести к некорректным результатам:
.code main proc sub rsp, 16 ; резервируем в стеке 16 байт mov byte ptr [rsp], 10 ; по адресу в RSP помещаем число 10 mov byte ptr [rsp+1], 11 ; по адресу в RSP+1 помещаем число 11 mov rax, [rsp] ; RAX = ? add rsp, 16 ; восстанавливаем данные из стека ret main endp end
Здесь в стек последовательно помещаем два байта — числа 10 и 11. Затем извлекам из стека данные. Но обратите внимание как идет извлечение
mov rax, [rsp] ; RAX = ?
Какое число окажется в регистре RAX? Здесь в регистр RAX из стека скопируются 8 байт, из которых первые два байта — это числа 10 и 11, остальные 6 байт неопределены. Соответственно результат в RAX неопределен. И чтобы взять только нужную нам порцию данных, следует использовать преобразование типов:
.code main proc sub rsp, 16 ; резервируем в стеке 16 байт mov byte ptr [rsp], 10 ; по адресу в RSP помещаем число 10 mov byte ptr [rsp+1], 11 ; по адресу в RSP+1 помещаем число 11 movzx rax, byte ptr [rsp] ; RAX = 10 add rsp, 16 ; восстанавливаем данные из стека ret main endp end
Расположение данных в стеке
Может возникнуть вопрос, как числа размером более одного байта сохраняются в стеке? Рассмотрим следующую программу:
.code main proc mov rdx, 0102030405060708h ; в RDX 8-байтное число push rdx ; сохраняем число из RDX в стек movzx rax, byte ptr [rsp] ; в RAX сохраняем 1 байт по адресу в RSP pop rdx ; извлекаем число из стека в RDX ret main endp end
Здесь в регистр RDX сохраняем 16-ричное число 0x0102030405060708 . Далее это число помещаем в стек.
Затем с помощью инструкции movzx помещаем в RAX 1 байт, извлеченный из стека по адресу который хранится в RSP. Чему будет равен этот байт — 0, 1 или 8?
При добавлении в стек старшие биты числа располагаются по старшим адресам, а младшие биты по младшим адресам:
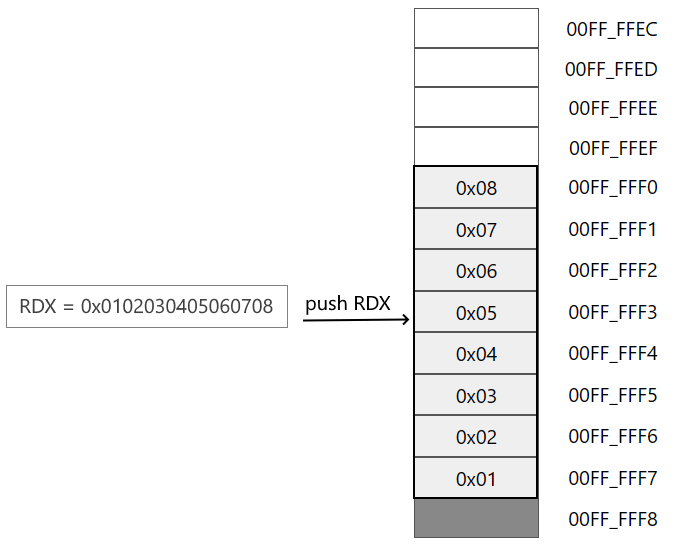
Соответственно в регистре RAX окажется число 0х08
Аналогично, если мы хотим получить старший байт 8-битного числа, то мы можем сместиться относительно адреса RSP вниз на 7 байт (то есть RSP+7):
movzx rax, byte ptr [rsp+7] ; RAX = 0x01
FasmWorld Программирование на ассемблере FASM для начинающих и не только
Стеком называется структура данных, организованная по принципу LIFO («Last In — First Out» или «последним пришёл — первым ушёл»). Стек является неотъемлемой частью архитектуры процессора и поддерживается на аппаратном уровне: в процессоре есть специальные регистры (SS, BP, SP) и команды для работы со стеком.
Обычно стек используется для сохранения адресов возврата и передачи аргументов при вызове процедур (о процедурах в следующей части), также в нём выделяется память для локальных переменных. Кроме того, в стеке можно временно сохранять значения регистров.
Схема организации стека в процессоре 8086 показана на рисунке:

Стек располагается в оперативной памяти в сегменте стека, и поэтому адресуется относительно сегментного регистра SS. Шириной стека называется размер элементов, которые можно помещать в него или извлекать. В нашем случае ширина стека равна двум байтам или 16 битам. Регистр SP (указатель стека) содержит адрес последнего добавленного элемента. Этот адрес также называется вершиной стека. Противоположный конец стека называется дном ��
Дно стека находится в верхних адресах памяти. При добавлении новых элементов в стек значение регистра SP уменьшается, то есть стек растёт в сторону младших адресов. Как вы помните, для COM-программ данные, код и стек находятся в одном и том же сегменте, поэтому если постараться, стек может разрастись и затереть часть данных и кода (надеюсь, с вами такой беды не случится :)).
Для стека существуют всего две основные операции:
- добавление элемента на вершину стека (PUSH);
- извлечение элемента с вершины стека (POP);
Добавление элемента в стек
Выполняется командой PUSH. У этой команды один операнд, который может быть непосредственным значением, 16-битным регистром (в том числе сегментым) или 16-битной переменной в памяти. Команда работает следующим образом:
- значение в регистре SP уменьшается на 2 (так как ширина стека — 16 бит или 2 байта);
- операнд помещается в память по адресу в SP.

push -5 ;Поместить -5 в стек push ax ;Поместить AX в стек push ds ;Поместить DS в стек push [x] ;Поместить x в стек (x объявлен как слово) push word [bx] ;Поместить в стек слово по адресу в BX
push -5 ;Поместить -5 в стек push ax ;Поместить AX в стек push ds ;Поместить DS в стек push [x] ;Поместить x в стек (x объявлен как слово) push word [bx] ;Поместить в стек слово по адресу в BX
Существуют ещё 2 команды для добавления в стек. Команда PUSHF помещает в стек содержимое регистра флагов. Команда PUSHA помещает в стек содержимое всех регистров общего назначения в следующем порядке: АХ, СХ, DX, ВХ, SP, BP, SI, DI (значение DI будет на вершине стека). Значение SP помещается то, которое было до выполнения команды. Обе эти команды не имеют операндов.
Извлечение элемента из стека
Выполняется командой POP. У этой команды также один операнд, который может быть 16-битным регистром (в том числе сегментым, но кроме CS) или 16-битной переменной в памяти. Команда работает следующим образом:
- операнд читается из памяти по адресу в SP;
- значение в регистре SP увеличивается на 2.
Обратите внимание, что извлеченный из стека элемент не обнуляется и не затирается в памяти, а просто остаётся как мусор. Он будет перезаписан при помещении нового значения в стек.

pop cx ;Поместить значение из стека в CX pop es ;Поместить значение из стека в ES pop [x] ;Поместить значение из стека в переменную x pop word [di] ;Поместить значение из стека в слово по адресу в DI
pop cx ;Поместить значение из стека в CX pop es ;Поместить значение из стека в ES pop [x] ;Поместить значение из стека в переменную x pop word [di] ;Поместить значение из стека в слово по адресу в DI
Соответственно, есть ещё 2 команды. POPF помещает значение с вершины стека в регистр флагов. POPA восстанавливает из стека все регистры общего назначения (но при этом значение для SP игнорируется).
Пример программы
Имеется двумерный массив — таблица 16-битных значений со знаком размером n строк на m столбцов. Программа вычисляет сумму элементов каждой строки и сохраняет результат в массиве sum. Первый элемент массива будет содержать сумму элементов первой строки, второй элемент — сумму элементов второй строки и так далее.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
use16 ;Генерировать 16-битный код org 100h ;Программа начинается с адреса 100h jmp start ;Переход к метке start ;---------------------------------------------------------------------- ; Данные n db 4 ;Количество строк m db 5 ;Количество столбцов ;Двумерный массив - таблица c данными table: dw 12,45, 0,82,34 dw 46,-5,87,11,56 dw 35,21,77,90,-9 dw 44,13,-1,99,32 sum rw 4 ;Массив для сумм каждой строки ;---------------------------------------------------------------------- start: movzx cx,[n] ;Счётчик строк mov bx,table ;BX = адрес таблицы mov di,sum ;DI = адрес массива для сумм xor si,si ;SI = смещение элемента от начала таблицы rows: xor ax,ax ;Обнуление AX. В AX будет считаться сумма push cx ;Сохранение значения CX movzx cx,[m] ;Инициализация CX для цикла по строке calc_sum: add ax,[bx+si] ;Прибавление элемента строки add si,2 ;SI = смещение следующего элемента loop calc_sum ;Цикл суммирования строки pop cx ;Восстановление значения CX mov [di],ax ;Сохранение суммы строки add di,2 ;DI = адрес следующей ячейки для суммы строки loop rows ;Цикл по всем строкам таблицы mov ax,4C00h ;\ int 21h ;/ Завершение программы
use16 ;Генерировать 16-битный код org 100h ;Программа начинается с адреса 100h jmp start ;Переход к метке start ;———————————————————————- ; Данные n db 4 ;Количество строк m db 5 ;Количество столбцов ;Двумерный массив — таблица c данными table: dw 12,45, 0,82,34 dw 46,-5,87,11,56 dw 35,21,77,90,-9 dw 44,13,-1,99,32 sum rw 4 ;Массив для сумм каждой строки ;———————————————————————- start: movzx cx,[n] ;Счётчик строк mov bx,table ;BX = адрес таблицы mov di,sum ;DI = адрес массива для сумм xor si,si ;SI = смещение элемента от начала таблицы rows: xor ax,ax ;Обнуление AX. В AX будет считаться сумма push cx ;Сохранение значения CX movzx cx,[m] ;Инициализация CX для цикла по строке calc_sum: add ax,[bx+si] ;Прибавление элемента строки add si,2 ;SI = смещение следующего элемента loop calc_sum ;Цикл суммирования строки pop cx ;Восстановление значения CX mov [di],ax ;Сохранение суммы строки add di,2 ;DI = адрес следующей ячейки для суммы строки loop rows ;Цикл по всем строкам таблицы mov ax,4C00h ;\ int 21h ;/ Завершение программы
Как видите, в программе два вложенных цикла: внешний и внутренний. Внешний цикл — это цикл по строкам таблицы. Внутренний цикл вычисляет сумму элементов строки. Стек здесь используется для временного хранения счётчика внешнего цикла. Перед началом внутреннего цикла CX сохраняется в стеке, а после завершения восстанавливается. Такой приём можно использовать для программирования и большего количества вложенных циклов.
Turbo Debugger
В отладчике Turbo Debugger стек отображается в нижней правой области окна CPU. Левый столбец чисел — адреса, правый — данные. Треугольник указывает на вершину стека, то есть на тот адрес, который содержится в регистре SP. Если запустить программу в отладчике, то можно увидеть, как работают команды «push cx» и «pop cx».

Упражнение
Объявите в программе строку «$!olleH». Напишите код для переворачивания строки с использованием стека (в цикле поместите каждый символ в стек, а затем извлеките в обратном порядке). Выведите полученную строку на экран. Свои результаты пишите в комментариях ��