Подсчет данных при помощи запроса
В этой статье объясняется, как подсчитать данные, возвращаемые запросом, в Access. Например, в форме или отчете можно подсчитать количество элементов в одном или нескольких полях таблицы или элементах управления. Вы также можете вычислять средние значения, находить наибольшее и наименьшее значения, самую давнюю и самую последнюю дату. Кроме того, в Access предусмотрено средство, называемое строкой итогов, с помощью которого можно подсчитывать данные в таблице, не изменяя структуру запроса.
Выберите нужное действие
- Способы подсчета данных
- Подсчет данных с помощью строки итогов
- Подсчет данных с помощью итогового запроса
- Справочные сведения об агрегатных функциях
Способы подсчета данных
Подсчитать количество элементов в поле (столбце значений) можно с помощью функции Число. Функция Число принадлежит к ряду функций, называемых агрегатными. Агрегатные функции выполняют вычисления со столбцами данных и возвращают единственное значение. Кроме функции Число, в Access есть следующие агрегатные функции:
- Сумма для суммирования столбцов чисел;
- Среднее для вычисления среднего значения в столбце чисел;
- Максимум для нахождения наибольшего значения в поле;
- Минимум для нахождения наименьшего значения в поле;
- Стандартное отклонение для оценки разброса значений относительно среднего значения;
- Дисперсия для вычисления статистической дисперсии всех значений в столбце.
В Access предусмотрено два способа добавления функции Count и других агрегатных функций в запрос. Вы можете:
- Открыть запрос в режиме таблицы и добавить строку итогов. Строка итогов позволяет использовать агрегатные функции в одном или нескольких столбцах в результатах запроса без необходимости изменять его структуру.
- Создать итоговый запрос. В итоговом запросе вычисляются промежуточные итоги по группам записей. Например, если вы хотите вычислить промежуточную сумму всех продаж по городам или по кварталам, следует использовать итоговый запрос для группировки записей по нужной категории, а затем просуммировать все объемы продаж. С другой стороны, с помощью строки итогов можно вычислить общий итог для одного или нескольких столбцов (полей) данных.
Примечание: Ниже в разделах этой статьи подробно описано применение функции Сумма, однако следует помнить, что вы можете использовать другие агрегатные функции в строках итогов и запросах. Дополнительные сведения об использовании других агрегатных функций см. ниже в разделе Справочные сведения об агрегатных функциях.
Дополнительные сведения о способах использования других агрегатных функций см. в разделе Отображение итогов по столбцу в таблице.
В следующих разделах описаны шаги, которые следует выполнить, чтобы добавить строку итогов, а также описывается использование итогового запроса для подсчета данных. Следует обратить внимание на то, что функция Число работает с большим числом типов данных, чем другие агрегатные функции. Функцию Число можно использовать для любого типа полей, кроме тех, которые содержат сложные повторяющиеся скалярные данные, например поле с многозначными списками.
С другой стороны, многие агрегатные функции работают только с данными в полях, имеющих определенный тип данных. Например, функция Сумма работает только с типами данных «Число», «Действительное» и «Денежный». Дополнительные сведения о типах данных, требуемых для каждой функции, см. ниже в разделе Справочные сведения об агрегатных функциях.
Общие сведения о типах данных см. в статье Изменение типа данных для поля.
Подсчет данных с помощью строки итогов
Чтобы добавить в запрос строку итогов, откройте его в режиме таблицы, добавьте строку, а затем выберите функцию Число или другую агрегатную функцию, например Сумма, Минимум, Максимум или Среднее. В этом разделе объясняется, как создать простой запрос на выборку и добавить строку итогов.
Создание простого запроса на выборку
- На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
- Дважды щелкните таблицу или таблицы, которые вы хотите использовать в запросе, а затем нажмите кнопку Закрыть. Выбранные таблицы отображаются в виде окон в верхней части конструктора запросов. На рисунке показана типичная таблица в конструкторе запросов.
- Дважды щелкните поля таблицы, которые вы хотите использовать в запросе. Вы можете включить поля, содержащие описательные данные, например имена и описания, но следует обязательно добавить поле, содержащее подсчитываемые значения. Каждое поле отображается в столбце в бланке запроса.
- На вкладке Конструктор запросов в группе Результаты нажмите кнопку Выполнить. Результаты запроса отображаются в режиме таблицы.
- При необходимости переключитесь в Конструктор и скорректируйте запрос. Для этого щелкните правой кнопкой мыши вкладку документа для запроса и выберите команду Конструктор. После этого можно изменить запрос, добавив или удалив поля таблицы. Чтобы удалить поле, выберите столбец в бланке запроса и нажмите клавишу DELETE.
- При необходимости вы можете сохранить запрос.
Добавление строки итогов
- Откройте запрос в режиме таблицы. Щелкните правой кнопкой мыши вкладку документа для запроса и выберите пункт Представление таблицы. -или- Дважды щелкните запрос в области навигации. Запрос будет выполнен, а его результаты будут загружены в таблицу.
- На вкладке Главная в группе Записи нажмите кнопку Итоги. Под последней строкой данных в таблице появится новая строка Итог.
- В строке Итог щелкните поле, по которому вы хотите выполнить подсчет, и выберите в списке функцию Count.
Скрытие строки итогов
- На вкладке Главная в группе Записи нажмите кнопку Итоги.
Дополнительные сведения об использовании строки итогов см. в разделе Отображение итогов по столбцу в таблице.
Подсчет данных с помощью итогового запроса
Когда нужно подсчитать некоторые или все записи, возвращаемые запросом, то вместо строки итогов можно воспользоваться итоговым запросом. Например, вы можете подсчитать общее число сделок или число сделок в отдельном городе.
Как правило, итоговый запрос применяется вместо строки итогов тогда, когда требуется использовать значение результата в другой части базы данных, например в отчете.
Подсчет всех записей в запросе
- На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
- Дважды щелкните таблицу, которую вы хотите использовать в запросе, и нажмите кнопку Закрыть. Таблица появится в окне в верхней части конструктора запросов.
- Дважды щелкните поля, которые вы хотите использовать в запросе, и убедитесь, что вы включили поле, которое нужно подсчитать. Можно подсчитать поля большинства типов данных, исключение — поля, содержащие сложные повторяющиеся скалярные данные, такие как поля многозначных списков.
- На вкладке Конструктор запросов в группе Показать и скрыть щелкните Итоги. В бланке появится строка Итог, а в строке для каждого поля запроса будет указано Группировка.
- В строке Итог щелкните поле, по которому вы хотите выполнить подсчет, и выберите в списке функцию Count.
- На вкладке Конструктор запросов в группе Результаты нажмите кнопку Выполнить. Результаты запроса отображаются в режиме таблицы.
- При необходимости вы можете сохранить запрос.
Подсчет записей в группе или категории
- На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
- Дважды щелкните таблицу или таблицы, которые вы хотите использовать в запросе, а затем нажмите кнопку Закрыть. Таблица (или таблицы) появится в окне в верхней части конструктора запросов.
- Дважды щелкните поле, содержащее данные категории, а также поле, значения в котором вы хотите подсчитать. Запрос не может содержать других описательных полей.
- На вкладке Конструктор запросов в группе Показать и скрыть щелкните Итоги. В бланке появится строка Итог, а в строке для каждого поля запроса будет указано Группировка.
- В строке Итог щелкните поле, по которому вы хотите выполнить подсчет, и выберите в списке функцию Count.
- На вкладке Конструктор запросов в группе Результаты нажмите кнопку Выполнить. Результаты запроса отображаются в режиме таблицы.
- При необходимости вы можете сохранить запрос.
Справочные сведения об агрегатных функциях
В следующей таблице перечислены и отписаны агрегатные функции Access, которые можно использовать в строке итогов и в запросах. Помните, что в Access предусмотрено больше агрегатных функций для запросов, чем для строки итогов.
Поддерживаемые типы данных
Суммирует элементы в столбце. Подходит только для числовых и денежных данных.
«Число», «Действительное», «Денежный»
Вычисляет среднее значение для столбца. Столбец должен содержать числовые или денежные величины или значения даты или времени. Функция игнорирует пустые значения.
«Число», «Действительное», «Денежный», «Дата/время»
Подсчитывает число элементов в столбце.
Все типы данных, за исключением сложных повторяющихся скалярных данных, таких как столбец многозначных списков.
Дополнительные сведения о многозначных списках см. в статье Создание или удаление многозначного поля.
Возвращает элемент, имеющий наибольшее значение. Для текстовых данных наибольшим будет последнее по алфавиту значение, причем Access не учитывает регистр. Функция игнорирует пустые значения.
«Число», «Действительное», «Денежный», «Дата/время»
Возвращает элемент, имеющий наименьшее значение. Для текстовых данных наименьшим будет первое по алфавиту значение, причем Access не учитывает регистр. Функция игнорирует пустые значения.
«Число», «Действительное», «Денежный», «Дата/время»
Стандартное отклонение
Показывает, насколько значения отклоняются от среднего.
Дополнительные сведения об этой функции см. в статье Отображение итогов по столбцу в таблице.
«Число», «Действительное», «Денежный»
Вычисляет статистическую дисперсию для всех значений в столбце. Подходит только для числовых и денежных данных. Если таблица содержит менее двух строк, Access возвращает пустое значение.
Дополнительные сведения о функциях для расчета дисперсии см. в разделе Отображение итогов по столбцу в таблице.
«Число», «Действительное», «Денежный»
Учимся применять оконные функции


Оконные функции — это мощнейший инструмент аналитика, который с легкостью помогает решать множество задач.
Если вам нужно произвести вычисление над заданным набором строк, объединенных каким-то одним признаком, например идентификатором клиента, вам на помощь придут именно они.
Можно сравнить их с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов, а также для расчетов различных моделей атрибуции.
Принцип работы
У вас может возникнуть вопрос – «Что значит оконные?»
При обычном запросе, все множество строк обрабатывается как бы единым «цельным куском», для которого считаются агрегаты. А при использовании оконных функций, запрос делится на части (окна) и уже для каждой из отдельных частей считаются свои агрегаты.
Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
SELECT Название функции (столбец для вычислений) OVER ( PARTITION BY столбец для группировки ORDER BY столбец для сортировки ROWS или RANGE выражение для ограничения строк в пределах группы )
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:

OVER()
Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER() AS 'Sum' FROM Orders

Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
PARTITION BY
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' FROM Orders

Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
ORDER BY
Попробуем отсортировать значения внутри окна при помощи ORDER BY:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Medium) AS 'Sum' FROM Orders
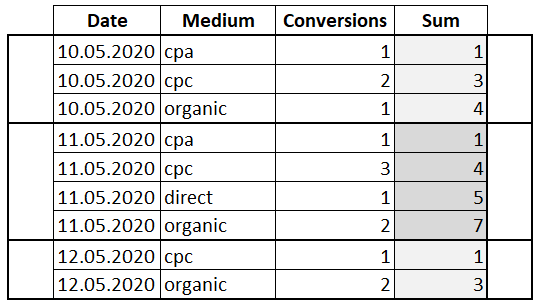
К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке;
- BETWEEN«граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна;
- «Значение»PRECEDING – определяет число строк перед текущей строкой (не допускается в предложении RANGE).;
- «Значение»FOLLOWING — определяет число строк после текущей строки (не допускается в предложении RANGE).
Разберем на примере:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date ORDER BY Conversions ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS 'Sum' FROM Orders
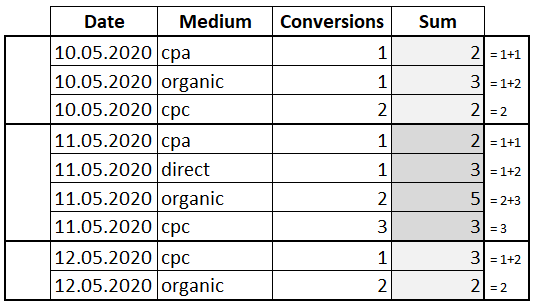
В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:
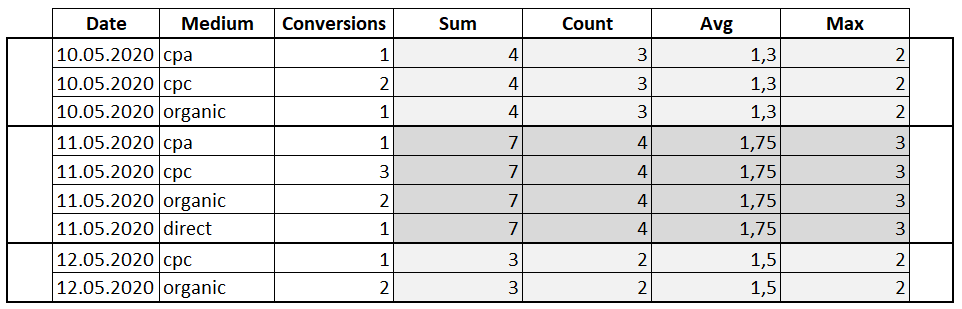
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' , COUNT(Conversions) OVER(PARTITION BY Date) AS 'Count' , AVG(Conversions) OVER(PARTITION BY Date) AS 'Avg' , MAX(Conversions) OVER(PARTITION BY Date) AS 'Max' , MIN(Conversions) OVER(PARTITION BY Date) AS 'Min' FROM Orders
Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
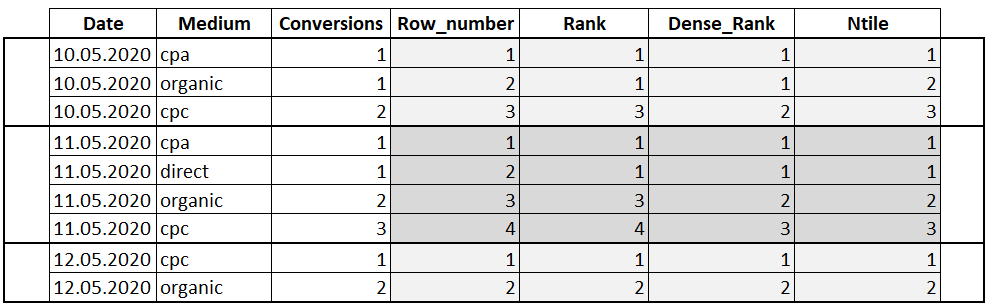
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
SELECT Date , Medium , Conversions , ROW_NUMBER() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Row_number' , RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Rank' , DENSE_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Dense_Rank' , NTILE(3) OVER(PARTITION BY Date ORDER BY Conversions) AS 'Ntile' FROM Orders
Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
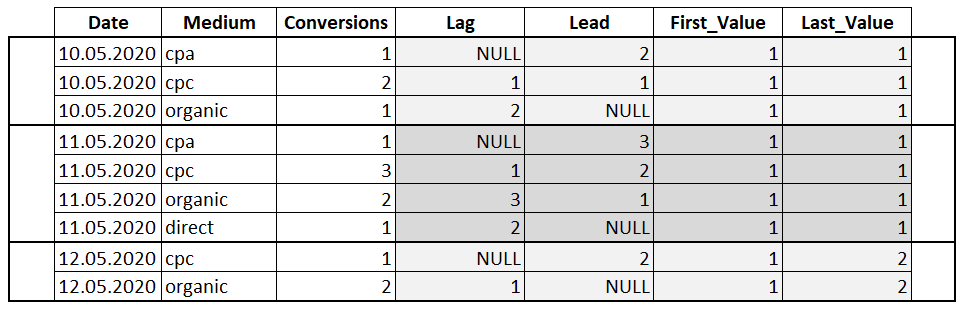
- LAG илиLEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
SELECT Date , Medium , Conversions , LAG(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lag' , LEAD(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lead' , FIRST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'First_Value' , LAST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Last_Value' FROM Orders
Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить (в этой статье я рассказываю как посчитать медиану, благодаря этой функции);
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.
SELECT Date , Medium , Conversions , CUME_DIST() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Cume_Dist' , PERCENT_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Percent_Rank' , PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Cont' , PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Disc' FROM Orders

Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.
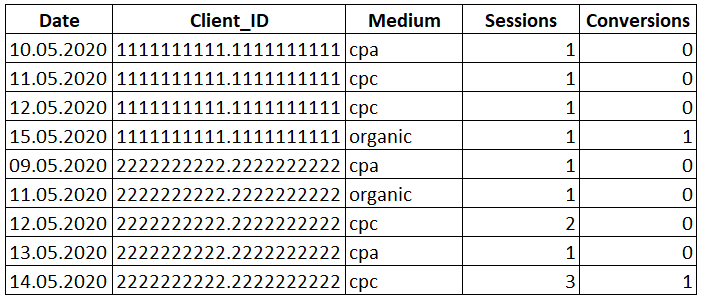
Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders
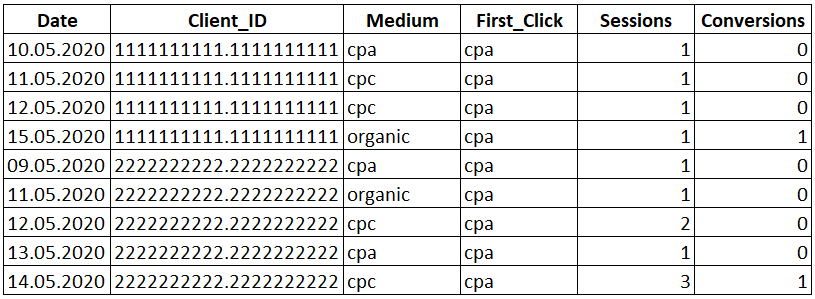
Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.
WITH First AS ( SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders ) SELECT First_Click , SUM(Conversions) AS 'Conversions' FROM First GROUP BY First_Click

С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
SELECT Date , Client_ID , Medium -- Присваиваем ранг в зависимости от близости к дате конверсии , DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks' , Sessions , Conversions FROM Orders
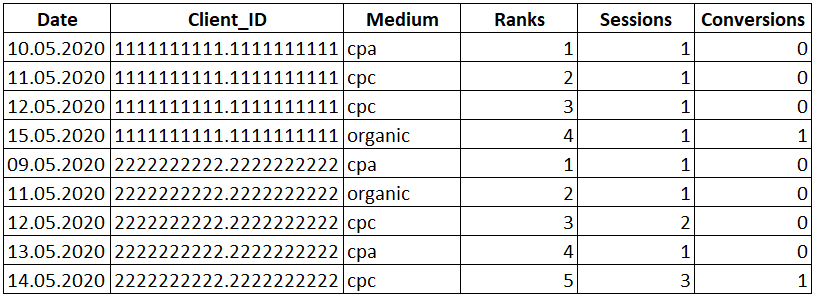
Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.
SELECT Date , Client_ID , Medium -- Делим ранг определенной строки на сумму рангов по пользователю , ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay' , Sessions , Conversions FROM ( SELECT Date , Client_ID , Medium -- Присваиваем ранг в зависимости от близости к дате конверсии , DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks' , Sessions , Conversions FROM Orders ) rank_table

Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.
WITH Ranks AS ( SELECT Date , Client_ID , Medium -- Делим ранг определенной строки на сумму рангов по пользователю , ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay' , Sessions , Conversions FROM ( SELECT Date , Client_ID , Medium -- Присваиваем ранг в зависимости от близости к дате конверсии , DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks' , Sessions , Conversions FROM Orders ) rank_table ) SELECT Medium , SUM(Time_Decay) AS 'Value' , SUM(Conversions) AS 'Conversions' FROM Ranks GROUP BY Medium ORDER BY Value DESC
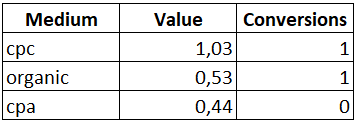
Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Полезные ссылки:
- SELECT — предложение OVER (Transact-SQL)
- Как работать с оконными функциями в Google BigQuery — подробное руководство
- Модель атрибуции на основе онлайн/офлайн данных в Google BigQuery
Функция COUNT (Transact-SQL)
Эта функция возвращает количество элементов, найденных в группе. Функция COUNT работает подобно функции COUNT_BIG. Эти функции различаются только типами данных в возвращаемых значениях. Функция COUNT всегда возвращает значение типа данных int. Функция COUNT_BIG всегда возвращает значение типа данных bigint.
Синтаксис
Синтаксис функции агрегирования
COUNT ( < [ [ ALL | DISTINCT ] expression ] | * >) Синтаксис функции аналитики
COUNT ( [ ALL ] < expression | * >) OVER ( [ ] ) Сведения о синтаксисе Transact-SQL для SQL Server 2014 (12.x) и более ранних версиях см . в документации по предыдущим версиям.
Аргументы
ВСЕ
Применяет агрегатную функцию ко всем значениям. Аргумент ALL используется по умолчанию.
DISTINCT
Указывает, что функция COUNT возвращает количество уникальных значений, не равных NULL.
выражение
Выражение любого типа, кромеimage, ntext и text. COUNT не поддерживает агрегатные функции или вложенные запросы в выражении.
Указывает, что функция COUNT должна учитывать все строки, чтобы определить общее количество строк таблицы для возврата. COUNT(*) не принимает параметров и не поддерживает использование DISTINCT. COUNT(*) не требует параметра выражения, так как по определению он не использует сведения о определенном столбце. Функция COUNT(*) возвращает количество строк в указанной таблице с учетом повторяющихся строк. Она подсчитывает каждую строку отдельно. При этом учитываются и строки, содержащие значения NULL.
OVER ( [ partition_by_clause ] [ order_by_clause ] [ ROW_or_RANGE_clause ] )
partition_by_clause делит результирующий набор, полученный с помощью предложения FROM , на секции, к которым применяется функция COUNT . Если этот параметр не указан, функция обрабатывает все строки результирующего набора запроса как отдельные группы. order_by_clause определяет логический порядок выполнения операции. Дополнительные сведения см . в предложении OVER (Transact-SQL ).
Типы возвращаемых данных
- int NOT NULL , ANSI_WARNINGS если имеет значение ON , однако SQL Server всегда будет обрабатывать COUNT выражения как int NULL в метаданных, если только не упакованы в ISNULL .
- int NULL , если ANSI_WARNINGS имеет значение OFF .
Замечания
- COUNT(*) без GROUP BY возврата карта inality (количество строк) в наборе результатов. К ним относятся строки, состоящие из всех NULL значений и дубликатов.
- COUNT(*) при GROUP BY возврате числа строк в каждой группе. Сюда входят NULL значения и дубликаты.
- COUNT(ALL ) вычисляет выражение для каждой строки в группе и возвращает количество ненулевого значения.
- COUNT(DISTINCT *expression*) вычисляет выражение для каждой строки в группе и возвращает количество уникальных, ненулевого значения.
COUNT — это детерминированная функция, если она используется без предложений OVER и ORDER BY. Она не детерминирована при использовании с предложениями OVER и ORDER BY. Дополнительные сведения см. в разделе детерминированные и недетерминированные функции.
ARITHABORT и ANSI_WARNINGS .
Если COUNT имеет возвращаемое значение, превышающее максимальное значение int (то есть 2 31-1 или 2 147 483 647), COUNT функция завершится ошибкой из-за целочисленного переполнения. При COUNT переполнении и параметрах ARITHABORT OFF COUNT ANSI_WARNINGS возвращается. NULL В противном случае, если или есть, ANSI_WARNINGS ARITHABORT ON запрос будет прерваться, и будет вызвана ошибка арифметического переполнения. Msg 8115, Level 16, State 2; Arithmetic overflow error converting expression to data type int. Чтобы правильно обрабатывать эти большие результаты, используйте COUNT_BIG вместо этого, что возвращает bigint.
Если оба ARITHABORT и ANSI_WARNINGS есть ON , вы можете безопасно упаковать COUNT сайты вызовов, ISNULL( , 0 ) чтобы принудить тип выражения вместо int NOT NULL int NULL . Упаковка COUNT в ISNULL означает, что любая ошибка переполнения будет автоматически подавляться, что должно быть рассмотрено для правильности.
Примеры
А. Использование COUNT и DISTINCT
В этом примере возвращается количество различных названий, которые может хранить сотрудник Adventure Works Cycles.
SELECT COUNT(DISTINCT Title) FROM HumanResources.Employee; GO ----------- 67 (1 row(s) affected) B. Использование COUNT(*)
В этом примере возвращается общее количество сотрудников Adventure Works Cycles.
SELECT COUNT(*) FROM HumanResources.Employee; GO ----------- 290 (1 row(s) affected) C. Использование COUNT(*) с другими агрегатами
В этом примере показано, что функция COUNT(*) работает с другими статистическими функциями в списке SELECT . В примере используется база данных AdventureWorks2022.
SELECT COUNT(*), AVG(Bonus) FROM Sales.SalesPerson WHERE SalesQuota > 25000; GO ----------- --------------------- 14 3472.1428 (1 row(s) affected) D. Использование предложения OVER
В этом примере используются MAX AVG MIN функции и COUNT функции с OVER предложением для возврата агрегированных значений для каждого отдела в таблице базы данных HumanResources.Department AdventureWorks2022.
SELECT DISTINCT Name , MIN(Rate) OVER (PARTITION BY edh.DepartmentID) AS MinSalary , MAX(Rate) OVER (PARTITION BY edh.DepartmentID) AS MaxSalary , AVG(Rate) OVER (PARTITION BY edh.DepartmentID) AS AvgSalary , COUNT(edh.BusinessEntityID) OVER (PARTITION BY edh.DepartmentID) AS EmployeesPerDept FROM HumanResources.EmployeePayHistory AS eph JOIN HumanResources.EmployeeDepartmentHistory AS edh ON eph.BusinessEntityID = edh.BusinessEntityID JOIN HumanResources.Department AS d ON d.DepartmentID = edh.DepartmentID WHERE edh.EndDate IS NULL ORDER BY Name; Name MinSalary MaxSalary AvgSalary EmployeesPerDept ----------------------------- --------------------- --------------------- --------------------- ---------------- Document Control 10.25 17.7885 14.3884 5 Engineering 32.6923 63.4615 40.1442 6 Executive 39.06 125.50 68.3034 4 Facilities and Maintenance 9.25 24.0385 13.0316 7 Finance 13.4615 43.2692 23.935 10 Human Resources 13.9423 27.1394 18.0248 6 Information Services 27.4038 50.4808 34.1586 10 Marketing 13.4615 37.50 18.4318 11 Production 6.50 84.1346 13.5537 195 Production Control 8.62 24.5192 16.7746 8 Purchasing 9.86 30.00 18.0202 14 Quality Assurance 10.5769 28.8462 15.4647 6 Research and Development 40.8654 50.4808 43.6731 4 Sales 23.0769 72.1154 29.9719 18 Shipping and Receiving 9.00 19.2308 10.8718 6 Tool Design 8.62 29.8462 23.5054 6 (16 row(s) affected) Примеры: Azure Synapse Analytics и система платформы аналитики (PDW)
Д. Использование COUNT и DISTINCT
В этом примере функция возвращает количество различных должностей, которые может иметь конкретный сотрудник компании.
USE ssawPDW; SELECT COUNT(DISTINCT Title) FROM dbo.DimEmployee; F. Использование COUNT(*)
В этом примере функция возвращает общее количество строк в таблице dbo.DimEmployee .
USE ssawPDW; SELECT COUNT(*) FROM dbo.DimEmployee; G. Использование COUNT(*) с другими агрегатами
В этом примере функция COUNT(*) работает с другими статистическими функциями в списке SELECT . Запрос возвращает количество торговых представителей с годовой квотой продаж более 500 000 долл. США и их среднюю квоту продаж.
USE ssawPDW; SELECT COUNT(EmployeeKey) AS TotalCount, AVG(SalesAmountQuota) AS [Average Sales Quota] FROM dbo.FactSalesQuota WHERE SalesAmountQuota > 500000 AND CalendarYear = 2001; TotalCount Average Sales Quota ---------- ------------------- 10 683800.0000 H. Использование COUNT с ПОМОЩЬЮ HAVING
В этом примере функция COUNT используется с предложением HAVING , чтобы получить список подразделений компании, в каждом из которых работает более 15 сотрудников.
USE ssawPDW; SELECT DepartmentName, COUNT(EmployeeKey)AS EmployeesInDept FROM dbo.DimEmployee GROUP BY DepartmentName HAVING COUNT(EmployeeKey) > 15; DepartmentName EmployeesInDept -------------- --------------- Sales 18 Production 179 I. Использование COUNT с OVER
В этом примере функция COUNT используется с предложением OVER , чтобы получить количество продуктов, содержащихся в каждом из указанных заказов на продажу.
USE ssawPDW; SELECT DISTINCT COUNT(ProductKey) OVER(PARTITION BY SalesOrderNumber) AS ProductCount , SalesOrderNumber FROM dbo.FactInternetSales WHERE SalesOrderNumber IN (N'SO53115',N'SO55981'); ProductCount SalesOrderID ------------ ----------------- 3 SO53115 1 SO55981 См. также
- Агрегатные функции (Transact-SQL)
- COUNT_BIG (Transact-SQL)
- Предложение OVER (Transact-SQL)
SQL — Урок 8. Группировка записей и функция COUNT()
Давайте вспомним, какие сообщения и в каких темах у нас имеются. Для этого можно воспользоваться привычным запросом:
А что, если нам надо лишь узнать сколько сообщений на форуме имеется. Для этого можно воспользоваться встроенной функцией COUNT(). Эта функция подсчитывает число строк. Причем, если в качестве аргумента этой функции выступает *, то подсчитываются все строки таблицы. А если в качестве аргумента указывается имя столбца, то подсчитываются только те строки, которые имеют значение в указанном столбце.
В нашем примере оба аргумента дадут одинаковый результат, т.к. все столбцы таблицы имеют тип NOT NULL. Давайте напишем запрос, используя в качестве аргумента столбец id_topic:
SELECT COUNT(id_topic) FROM posts;
Итак, в наших темах имеется 4 сообщения. Но что, если мы хотим узнать сколько сообщений имеется в каждой теме. Для этого нам понадобится сгруппировать наши сообщения по темам и вычислить для каждой группы количество сообщений. Для группировки в SQL используется оператор GROUP BY. Наш запрос теперь будет выглядеть так:
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic;
Оператор GROUP BY указывает СУБД сгруппировать данные по столбцу id_topic (т.е. каждая тема — отдельная группа) и для каждой группы подсчитать количество строк:
Ну вот, в теме с у нас 3 сообщения, а с — одно. Кстати, если бы в поле id_topic были возможны отсутствия значений, то такие строки были бы объединены в отдельную группу со значением NULL.
Предположим, что нас интересуют только те группы, в которых больше двух сообщений. В обычном запросе мы указали бы условие с помощью оператора WHERE, но этот оператор умеет работать только со строками, а для групп те же функции выполняет оператор HAVING:
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic HAVING COUNT(id_topic) > 2;
В результате имеем:
В уроке 4 мы рассматривали, какие условия можно задавать оператором WHERE, те же условия можно задавать и оператором HAVING, только надо запомнить, что WHERE фильтрует строки, а HAVING — группы.
Итак, сегодня мы узнали, как создавать группы и как подсчитать количество строк в таблице и в группах. Вообще вместе с оператором GROUP BY можно использовать и другие встроенные функции, но их мы будем изучать позже.
Научись программировать на Python прямо сейчас!
- Научись программировать на Python прямо сейчас
- Бесплатный курс
Если этот сайт оказался вам полезен, пожалуйста, посмотрите другие наши статьи и разделы.