Классификация таблиц в реляционных базах данных по признакам целостности и избыточности данных
Обоснование статьи и некоторые ключевые понятия;
1. Справочники и связки;
1.1. Виды таблиц;
1.2. Виды справочников;
1.3. Виды связок;
2. Обобщение классификации;
2.1. Классификация в табличном виде;
2.2. Классификация в схематичном виде;
3. Некоторые комментарии по применению классификации;
3.1. Применение классификации при нормализации таблиц;
Заключение.
Обоснование статьи и некоторые ключевые понятия
Очень часто присутствовал на обучении дисциплине «Базы данных». Обучался когда-то сам… Как-то даже пришлось проводить целый курс для друзей и знакомых. Во время обучения мною было замечено, что трудности возникают уже на этапе понимания таблиц и того, как ими пользоваться. Многие просто не могли и не могут разработать простейшие базы данных. После более детального рассмотрения такого понятия как таблицы и маленькой классификации, трудности восприятия таблиц в реляционных базах данных почти всегда исчезают. Итак!
В данной статье будет рассмотрена маленькая классификация таблиц по признакам целостности и избыточности. Что это значит? Это значит, что будут приведены примеры с описанием, какую структуру таблиц можно делать, чтобы предотвращать (пытаться предотвращать) избыточность и добиваться целостности в реляционных базах данных.
Для понимания дадим краткие определения целостности и избыточности данных:
Целостность данных – это свойство способности по одним данным восстанавливать другие, при этом не теряя семантическое единство этих данных и отношения между ними (между данными).
Избыточность данных – это состояние базы данных, при котором в таблицах присутствуют лишние данные.
Целостность данных может быть нарушена в результате операций модификации данных. Если в базе данных запрещены операции удаления и обновления, то целостность может быть нарушена только в результате операции добавления, а также неправильно написанных скриптов по отображению данных.
1. Справочники и связки
1.1. Виды таблиц
Немного углубимся в маленькую классификацию таблиц по видам их структуры. Разделим таблицы на два общих вида. Первым видом будут таблицы-справочники, вторым таблицы-связки.

Рисунок 1. Справочники и связки
Информацию в таблицах можно разделить на два вида. На информацию, которая описывает объекты (субъекты), связи и информацию, которая описывает действия, процессы, события, иное.
В справочниках содержатся сведения об объектах и субъектах, связях. В связках содержатся сведения о действиях, процессах, событиях и так далее.
В связках хранятся данные, взятые из таблиц справочников. Поскольку невыгодно повторять одни и те же данные при описании объектов (субъектов) и при описании их взаимодействия, данные об объектах (субъектах) заносятся в справочники, а в таблицах-связках не хранятся данные объектов (субъектов) в чистом виде, а лишь ссылки на них (внешний ключ). Таким образом, в связках хранятся данные по взаимодействию объектов (субъектов) и ссылки на самих объектов (субъектов) (внешний ключ). Эти «ссылки» являются первичными ключами в таблицах справочниках. Но об этом потом…
Отличие справочника от связки выражается в том, что таблицы-справочники могут быть самостоятельными и независимыми (то есть, при чтении данных некоторых справочников можно в целом понять семантику), а таблицы-связки практически никогда.
1.2. Виды справочников
Справочники могут подразделяться на несколько видов. Это статичные, статично-динамичные и динамичные справочники. Разумеется, вряд ли можно назвать абсолютно статичный справочник, так как в этом мире может измениться всё. Или почти всё.
Статичный справочник – справочник, данные об объектах, субъектах, связях в котором либо никогда не подвергаются модификации после первичной модификации, либо настолько редко подвергаются модификации, что этим можно пренебречь.
Примером таких справочников могут служить список месяцев с названиями и номерами, список дней недели, список времён года, список океанов и так далее…
| Номер | Наименование |
| 1 | Январь |
| 2 | Февраль |
| 3 | Март |
| 4 | Апрель |
| 5 | Май |
| 6 | Июнь |
| 7 | Июль |
| 8 | Август |
| 9 | Сентябрь |
| 10 | Октябрь |
| 11 | Ноябрь |
| 12 | Декабрь |
Таблица 1. Пример статичных справочников
Статично-динамичный справочник – справочник, в котором хранятся данные о связях, если связи носят справочный характер. В таком справочнике могут быть внешние ключи.
Наиболее удачным примером будет таблица с такими медицинскими данными, как вес. Список человек, вес которых измеряется, изменяется не так часто. А вот данные по их весу могут меняться каждый день. Статично-динамичные справочники являются единственными справочниками, где осознанно можно повторять любую информацию. Ещё одним примером может быть справочник окладов по должностям (по коду должности).
| Код должности | Оклад | Дата обновления |
| 1001 | 12 000 | 05.02.2015 |
| 1002 | 17 000 | 01.02.2015 |
| 1003 | 11 500 | 01.02.2015 |
| 1004 | 25 450 | 01.02.2015 |
| 1005 | 10 000 | 01.02.2015 |
| 1006 | 6 000 | 04.02.2015 |
Таблица 2. Пример статично-динамичных справочников
Динамичные справочники – это таблицы, данные об объектах, субъектах, связях в которых меняются часто и используются в других таблицах. От статичных справочников отличаются только частотой модификации в них данных.
Примером таких таблиц могут быть списки проектов. На самом деле, данные об открытии или закрытии проектов могут находиться в самом справочнике проектов, что в большинстве случаев неправильно и нарушает целостность. С другой стороны, если хранить историю изменений по открытию и закрытию (приостановке) проектов, то можно получить избыточность данных. Целостность и избыточность данных будут бороться с друг другом ещё долго, также как и зима с летом.
| Код проекта | Проект | Нормативный срок выполнения | Дата добавления | Пользователь |
| PT102 | Покраска окон | 15 | 03.01.2014 | 1547 |
| PT103 | Установка дверей | 10 | 04.01.2014 | 9874 |
| PT587 | Проверка пожарных кранов | 2 | 04.01.2014 | 1456 |
| PT588 | Замена люков | 3 | 02.01.2014 | 0147 |
| PT133 | Очистка каналов | 11 | 09.02.2015 | 1547 |
Таблица 3. Пример динамичных справочников
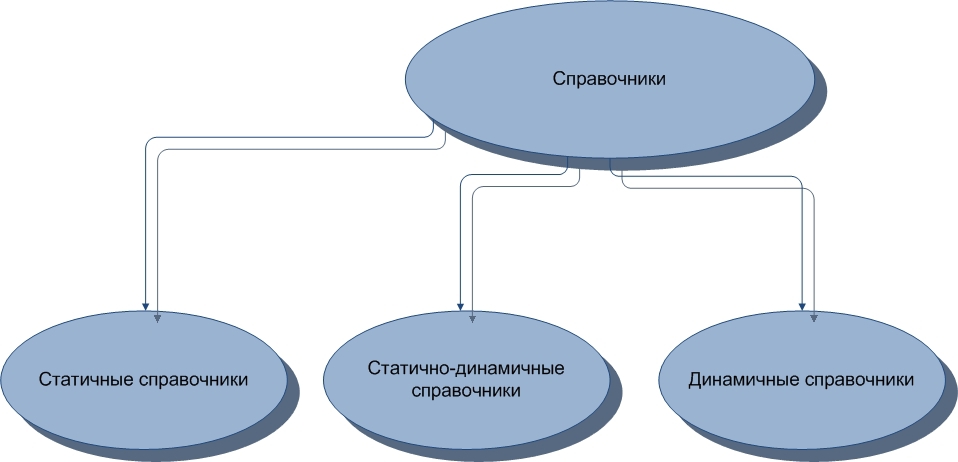
Рисунок 2. Виды справочников
1.3. Виды связок
Таблицы-связки можно разделить на два вида.
Это справочник-связка (сразу же уточним, что справочник-связка справочником не является, назван так, потому что в нём существуют поля, которые образуют справочник, но в справочник выделены быть не могут). Таблица, в которой хранятся внешние ключи, данные, которые не являются справочными и поля, содержащие данные, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник.
Примером справочника-связки будет являться таблица платёжных транзакций. Или таблица с данными о футбольном матче.
| Код транзакции | Плательщик | Получатель | Сумма | Дата | Комментарий |
| EEVS-doodi4 | 100045 | 57457 | -10 000 | 25.07.2014 | На сапоги |
| UDFD-ioeed9 | 455780 | 10024 | -900 | 24.06.2014 | NULL |
| PEDD-jdksl4 | 144770 | 56698 | -6980 | 01.01.2015 | NULL |
| FDFE-keiiii0 | 447757 | 1 | 120 | 08.07.2014 | NULL |
Таблица 4. Пример справочника-связки
И связка (да, просто связка). Это таблица в которой хранятся только внешние ключи и данные, которые нельзя отнести к справочным, например дата или значения логических полей.
Примером связки будет являться таблица автоматического логирования терминала обработки данных.
Кстати, легко догадаться, что связки почти нигде не используются, поскольку чаще всего находятся данные, которые могут быть записаны в базу, но не содержаться в справочниках, поэтому невозможно сопоставить им внешний ключ.
| Код | Код клиента | Показания счётчика | Месяц |
| 2334 | 35643 | 50 | 01.01.2015 |
| 2335 | 235673 | 49 | 01.01.2015 |
| 2335 | 436345 | 56 | 01.01.2015 |
| 2335 | 574733 | 24 | 01.01.2015 |
Таблица 5. Пример связки
Необходимо пояснить, что это за поля, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник. Примером таких полей являются поля «комментарий», «жалоба», «описание», «предложение». Словом, если приводить популярный пример, то поле «сообщение» в таблице базы данных любой социальной сети…
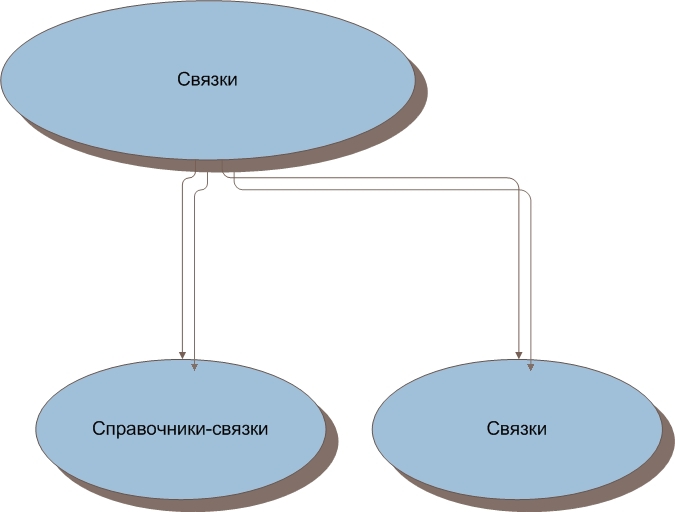
Рисунок 3. Виды связок
2. Обобщение классификации
2.1. Классификация в табличном виде
| Вид таблицы | Описание | Примеры | Плюсы (+) | Минусы(-) |
| Статичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В статичном справочнике должна содержаться информация, которая либо вообще не изменяется, либо изменяется так редко, что этим можно принебречь. На статичный справочник ссылаются (внешний ключ), когда нужно получить названия, обозначения, нормы, количественные или качественные показатели. Иное. | Справочник (наименований и номеров) месяцев. Справочник складов и цехов предприятия. Справочник правил игры. |
Иногда заменяет системные функции СУБД, позволяет более гибко работать с некоторыми данными. В случае, если меняется редко изменяемая информация, предостерегает от серьёзных последствий. | Использование таблицы с любой структурой может замедлять работу, в случае, если таблица заменяет системное хранилише. Приходится писать дополнительные функции и обработки для данной таблицы, которые не всегда правильно оптимизированны. В некоторых случаях невозможно оптимизировать. |
| Статично-динамичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах нельзя использовать внешний ключ этого справочника, однако можно использовать первичный ключ. | Справочник окладов по должностям. Справочник (размеров обуви, веса, роста, размера головы) физиологических параметров. Справочник (менеджеров, компаний) содержащий компании и менеджеров, которые эти компании обслуживают и учитывают. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник, выделенный из справочника-связки, никуда не девается и не имеет никакой реляционной связи, которая позволила бы ему превратиться в статичный или динамичный справочник. А значит, всегда избыточен. |
| Динамичный справочник | Таблица. Данные из неё берутся часто для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В динамичном справочнике должна содержаться информация, которая часто изменяется. | Справочник клиентов. Справочник поставщиков. Справочник контрагентов. Справочник менеджеров компании. Справочник работников. Справочник студентов. | Позволяет хранить динамичные данные, при этом давая возможность однозначно ссылаться на них. | Чаще всего накопительного типа и не делим, что создаёт определённую избыточность. |
| Справочник-связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. | Платёжные транзакции. Продажи. Межзаводские перемещения. График перевозок. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник-связка после нормализации превращается в связку и сводит избыточность данных к минимуму, не затрагивая целостность, однако не делим и при архивировании в текущей таблице не подлежит оптимизации. |
| Связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. Таблица не может содержать кортежей, значения атрибутов в которых являются неделимыми и не уникальными. | Автоматический лог ошибок в программе. Лог запроса сервера. Результаты трассировок. Отчёты о выгрузке и загрузке компонентов. Автоматические отчёты системы безопасности. | Связка сводит избыточность данных к минимуму, не затрагивая целостность. | Накапливаясь, является неделимой таблицей. Сложно оптимизировать. |
Таблица 6. Классификация
2.2. Классификация в схематичном виде
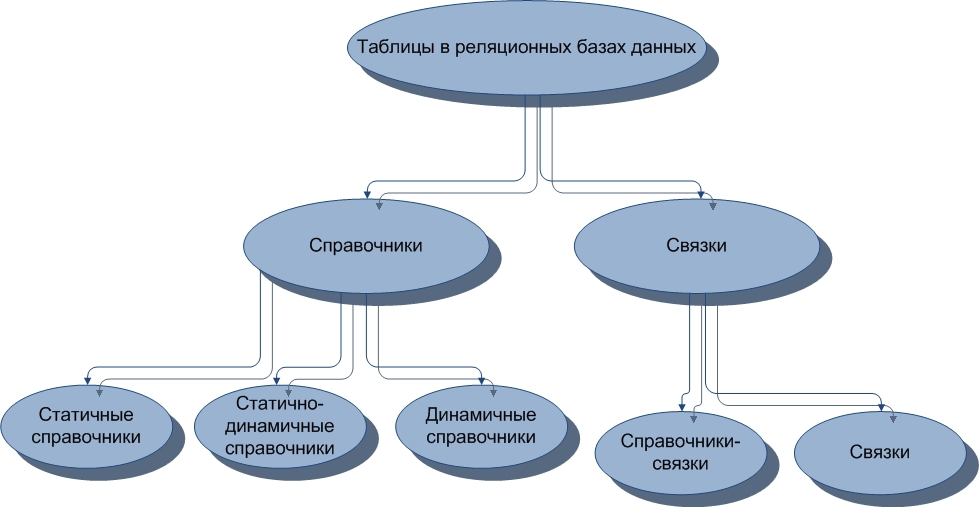
Рисунок 4. Схема классификации таблиц в реляционных базах данных по признакам целостности и избыточности данных
3. Некоторые комментарии по применению классификации
3.1. Применение классификации при нормализации таблиц
Процесс нормализации, если не учитывать некоторые этапы (Но учитывать результаты этих этапов!) — это обычное «дробление» таблиц на более мелкие таблицы с созданием реляционной связи между ними непосредственно или через промежуточные таблицы (связь «Многие ко многим»). Под реляционной связью может не всегда пониматься реляционное отношение!
Преобразование динамичного или статичного справочника в статично-динамичный справочник, а справочника-связки в связку, как и статично-динамичного справочника в справочник-связку — это ни что иное, как дробление таблиц. То есть, преобразование одного вида таблиц в другой через показанную выше классификацию в целях избежания избыточности данных — так можно определить нормализацию (один из вариантов определения).
Для примера. Пусть имеется база данных, в которой единственная операция по модификации данных — это добавление. В таком случае становится неэффективным каждый раз при изменении какого либо отдельного атрибута сущности, «копировать» остальные значения атрибутов уже в другой кортеж. В этом случае используются NULL или же создание статично-динамичного справочника, где описывается ряд атрибутов одной семантики или один атрибут, а дублируется лишь внешний ключ с первичным ключом последовательности. Этот же метод может использоваться в традиционной схеме модификации данных с обновлением и удалением данных.
Заключение
Данная классификация была создана мной на основе наблюдений при проектировании баз данных, а также исходя из прочитанной теории по проектированию в реляционных СУБД. Моим друзьям и знакомым, изучающим дисциплину «базы данных» и занимающимся проектированием баз данных, и мне эта классификация достаточно серьёзно упростила «жизнь» и позволила во многих ситуациях заранее выбрать наиболее подходящий и, как оказывалось потом, правильный вид таблицы для хранения в ней тех или иных данных.
Классификация может быть расширена разделением существующих видов в ней на подвиды (возможно, даже, добавлением новых видов). Также эта классификация показала, что лучше в некоторых ситуациях не использовать тот или иной вид таблиц. Некоторые виды таблиц из данной классификации лучше использовать реже (динамичные справочники). А некоторые пытаться заменить на другие (справочники-связки на связки).
Надеюсь, кому ни будь ещё поможет эта классификация при освоении дисциплины «Базы данных» и при проектировании баз данных в реляционных СУБД.
- разработка баз данных
- реляционные субд
- таблицы в реляционных СУБД
IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
Базы данных. Виды и типы баз данных. Структура реляционных баз данных. Проектирование баз данных. Сетевые и иерархические базы данных
- 29.08.2012
- Базы данных
- 13 комментариев
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой я уже успел рассмотреть установку и настройку MySQL сервера баз данных, а также рассмотрел способы изменения кодировок сервера MySQL при помощи команды SET NAMES и файла конфигураций my.ini. Сегодня будет краткая и если можно так сказать теоретическая статья, посвященная вопросу — что такое базы данных и какие базы данных бывают.

В этой статье я постараюсь изложить кратко какие виды и типы баз данных бывают и остановлюсь на некоторых из них более подробно. Мы поговорим о структуре иерархических баз данных, уделим внимание структуре сетевых баз данных, и более подробно остановимся на структуре реляционных базах данных, рассмотрим особенности реляционных баз данных. И в конце статьи немного затронем тему проектирования баз данных, естественно реляционных, так сервер MySQL это по сути математическая модель реляционных баз данных. Проектирование баз данных и типы данных, с которыми может работать MySQL сервер — это темы для последующих публикаций.
База данных. Математические модели, структура, определение.
Я хоть и не собираюсь на своем блоге подробно рассказывать про математические законы и теории описывающие реляционные базы данных, но принцип того, как они устроены я рассказать должен, если вас заинтересует данная тема, то вы всегда можете посетить специализированный математический ресурс или почитать соответствующую литературу, а можете всегда задать вопрос в комментариях к данной публикации, и я по мере своих возможностей постараюсь вам ответить. Как я уже говорил, тема данной статьи – реляционные базы данных. Я постараюсь ответить на вопрос, что такое реляционные базы данных простым и понятным языком. Затрону основные понятия, относящиеся к реляционным базам данных, терминологию, историю возникновения баз данных вообще и реляционных в частности.
Наверное, самое простое определения баз данных, база данных – это упорядоченное хранение какой-либо информации. То есть, информация хранится в упорядоченном или систематизированном виде. Видов систематизации, упорядочивания и хранения информации может быть множество. Каждый из способов хранения информации отвечает каким-либо специфическим требованиям или предназначен для выполнения каких-либо определенных действий. На страницах своего блога я уже писал, про язык XML, данные в XML структурируются в виде дерева с разветвлениями, узлами и корнем. Но это лишь один из множества способов хранения информации. Более подробно обо всем этом читайте в рубрике Заметки о XML и XLST.
Виды и типы баз данных
Как я уже говорил, видов и типов баз данных очень и очень много и описать их все в данной публикации я просто не смогу, но самые распространенные виды хранения информации или виды баз данных я постараюсь описать. Понятно, что база данных хранит в себе информацию о каких-то объектах, например, информацию о товаре в интернет-магазине. Любой товар в базе данных – это объект с какими-то определенными параметрами и свойствами. Перейдем к конкретным примерам.
Иерархическая база данных, структура иерархических баз данных
Иерархическая база данных – каждый объект при таком хранение информации представляется в виде определенной сущности, то есть, у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть, документ в формате XML или файловая система компьютера, пример с файловой системой компьютера я приводил, когда рассматривал структуру XML документа, в рубрике Заметки о XML.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть, базы данных, имеющие иерархическую структуру умеют очень быстро выбирать, запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию, тут можно привести пример из жизни, компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути являются объектами иерархической структуры) но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.
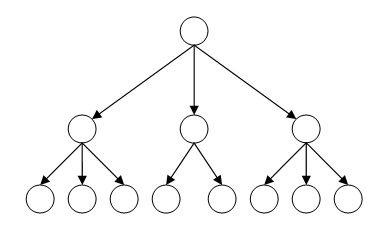
На рисунке вы можете увидеть структуру иерархической базы данных, в самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы, находящиеся на одном уровне называются братьями, ну или соседними элементами. Соответственно чем ниже уровень элемента, тем вложенность этого элемента больше.
Сетевая база данных, структура сетевых баз данных
Сетевые базы данных, являются своеобразной модификацией иерархических баз данных. Если вы внимательно смотрели на рисунок выше, то наверное обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть, элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на рисунок:
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но, в данной рубрике нас не сильно интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML, и возможно в рубрике посвященной языку расширяемой разметки, я постараюсь более подробно рассмотреть эту тему. А в рубрике посвященной MySQL нас интересуют реляционные базы данных, на которых мы и остановимся более подробно.
Реляционные базы данных, структура реляционных баз данных
Реляционные базы данных получили очень широкое распространение и многие пытаются писать огромные статьи, посвященные вопросу – почему реляционные базы данных получили такое широкое распространение, делают глубокомысленные выводы и замечания. Но на самом деле все очень просто – реляционные базы данных очень легко описываются в математике, то есть, под них очень хорошо написана математика.
Был когда-то такой математик – Эдгар Франк Кодд, умерший в 2003 году, который в восьмидесятых годах очень подробно описал структуру реляционных баз данных математическим языком. А если есть хорошо написанная математика, то соответственно есть и программная реализация. Останавливаться на биографии Э.Ф. Кодда я не буду, для этого есть различные энциклопедии. Именно благодаря Кодду реляционные базы данных стали активно развиваться. Поэтому-то, когда мы говорим базы данных, чаще всего мы подразумеваем именно реляционные базы данных.
Особенности реляционных баз данных
Главной особенностью реляционных баз данных является, то, что объекты внутри таких баз данных хранятся в виде набора двумерных таблиц. То есть, таблица состоит из набора столбцов, в котором может указываться: название, тип данных(дата, число, строка, текст и т.д.). Еще одной важной особенность реляционных БД является, то, что число столбцов фиксировано, то есть, структура базы данных известна заранее, а вот число строк или рядов в реляционных базах данных ничем не ограничено, если говорить грубо, то строки в реляционных базах данных и есть объекты, которые хранятся в базе данных.
На самом деле, базы данных – это абстрактное понятие, таблица – это всего лишь способ хранения информации, набор таблиц может быть связан логически и этот набор называют база данных. Поэтому неправильно говорить, что MySQL это база данных, база данных – это хранящаяся информация. А вот такое понятие, как СУБД – система управления базами данных, это и есть MySQL сервер, именно при помощи него мы управляем хранящимися данными. Или иначе MySQL – это программное воплощение математических идей.
Самой трудной задачей при работе с реляционными базами данных, является проектирование структуры баз данных. Проектирование структуры базы данных, заключается не только в том, чтобы создать таблицу и указать тип данных и наименование столбцов. На самом деле проектирование – это самый сложный этап при работе с базами данных. Потому что мощности ваших компьютеров ограничены. Пока данных мало, мало таблиц и строк в этих таблицах, машина будет их обрабатывать очень и очень быстро. Но, со временем количество информации будет увеличиваться, и мы получим замедление, которое будет увеличиваться, поскольку машине необходимо время на обработку тех или иных запросов(обработка информации). В прошлой статье я уже писал, что реляционные БД прежде всего ориентированы на модификацию(OLTP), то есть, добавить новую запись в таблицу – это очень простая операция для реляционной СУБД, а вот сделать выборку данных, это уже трудоемкая операция. Также есть и изменение данных, это как бы промежуточное звено между чтением и добавлением. Хотя MySQL сервер всегда можно настроить.
Проектирование базы данных
Ну что же, мы немного поговорили о достоинствах и недостатках реляционных баз данных. И теперь, вкратце, я затрону вопрос проектирования баз данных. Под проектированием я понимаю следующее: садится человек за стол, берет бумагу и ручку, и исходя из поставленной задачи, а также, исходя из достоинств и недостатков той или иной системы, в нашем случае СУБД MySQL начинает составлять структуру будущей базы данных. Требование к проектируемой базе данных обычно ставятся следующее:
- База данных должна быть как можно более компактна, то есть, неизыбыточна.
- База данных должна быть простой с точки зрения обработки.
И как вы, наверное, поняли, данные требования противоречат друг другу. Проектирование — это самый важный аспект при работе с базами данных. Обычно, проектировщик – это опытный администратор сервера баз данных, либо архитектор баз данных, с большим опытом работы. В серьезных проектах может быть несколько десятков, а то и сотен таблиц, которые связаны между собой самыми замысловатыми способами связи. Конечно, я не собираюсь углубляться в проектирование баз данных, да и не смогу это сделать, но, кое какие основы проектирования баз данных я попытаюсь осветить на страницах своего блога. Прежде чем приступить к проектированию базы данных, нужно понять, а что мы вообще собираемся проектировать. То есть, должны понять, что у нас должно получиться на выходе.
А на выходе мы должны получить так называемую диаграмму или как ее еще называют схема. Диаграмма – это определение: какая информация будет храниться, в какой таблице она будет храниться, в каком столбце какой тип данных, как называется таблица, сколько столбцов в таблице и их тип, как связаны между собой таблицы. Да, типы данных в столбцах могут быть разными, например, номер телефона или индекс можно записать, как с помощью символов, так и с помощью числового типа данных. Но появляется вопрос: какой тип данных лучше для хранения номера телефона или почтового индекса? Чисто интуитивно на этот вопрос чаще всего отвечают правильно – номер телефона в базе данных должен иметь символьный тип, а вот объяснить, почему именно символьный тип могут немногие. Объяснение очень простое, например, нам потребовались все почтовые индексы, начинающиеся на 637 или номера телефонов начинающиеся на 952, так вот, сделать такую выборку из данных имеющих числовой тип задача довольно проблематичная, а сделать такую же выборку из данных символьного типа довольно легко.
При проектировании баз данных очень часто встречаются такие задачи и поверьте, от того, как вы будете их решать, будет зависеть, то, насколько быстро будет работать ваша система, в следующей статье я продолжу вопрос проектирования баз данных.
На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru
Еще записи о создании сайтов и их продвижении, базах данных, IT-технология и сетевых протоколах
- Часть 3.2: Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты
- Архитектура СУБД. Архитектура баз данных. Логическая структура СУБД. Описание данных в базе данных. Базы данных схема данных
- 1.21 Виды и типы компьютерных сетей (сетей передачи данных) и их радиус действия. Что такое BAN, PAN, LAN, CAN, MAN, WAN?
- Нормальные формы. Избыточность данных в базе данных. Транзитивная зависимость. Проектирование баз данных
- Тема 3: Теория реляционных баз данных
- Часть 3.10: Словарь терминов реляционных баз данных
- Проектирование баз данных. Информационная избыточность. Избыточность данных в базе данных. Проблемы возникающие из-за информационной избыточности
- Часть 3.9: Проектирование баз данных: теория, компромиссы, логика, здравый смысл и предметная область
Укажите пожалуйста для чего нужны сущности типа справочник
Данное руководство устарело. Актуальное руководство: Руководство по Entity Framework Core
Последнее обновление: 31.10.2015
Если нам необходимо, чтобы при первом обращении база данных уже была заполнена некоторыми начальными значениями, то мы можем произвести ее инициализацию.
Инициализация происходит при первом обращении к контексту данных.
Для инициализации мы можем использовать один из классов инициализаторов, которые имеются в библиотеке .NET:
- CreateDatabaseIfNotExists : инициализатор, используемый по умолчанию. Он не удаляет автоматчески базу данных и данные, а в случае изменения структуры моделей и контекста данных выбрасывает исключение.
- DropCreateDatabaseIfModelChanges : данный инициализатор проверяет на соответствие моделям определения таблиц в базе данных. И если модели не соответствуют определению таблиц, то база данные пересоздается
- DropCreateDatabaseAlways : этот инициализатор будет всегда пересоздавать базу данных.
Используем один из инициализаторов. Для этого нам надо переопределить метод Seed :
class MyContextInitializer : DropCreateDatabaseAlways < protected override void Seed(MobileContext db) < Phone p1 = new Phone ; Phone p2 = new Phone ; db.Phones.Add(p1); db.Phones.Add(p2); db.SaveChanges(); > > public class Phone < public int Id < get; set; >public string Name < get; set; >public int Price < get; set; >> class MobileContext : DbContext < static MobileContext() < Database.SetInitializer(new MyContextInitializer()); > public MobileContext() : base("DefaultConnection") < >public DbSet Phones < get; set; >>
Собственно инициализатор наследуется от одного из выше рассмотренных классов, который типизируется классом контекста: DropCreateDatabaseAlways .
Все действия по инициализации происходят в методе Seed, а сама инициализация предполагает простое сохранение данных в бд с помощью контекста данных.
Чтобы инициализатор сработал, надо его вызвать. Один из способов вызова инициализатора предполагет вызов его в статическом конструкторе класса контекста:
static MobileContext() < Database.SetInitializer(new MyContextInitializer()); >
Планы видов характеристик в 1С 8.3

Данный объект платформы 1С является интересным и полезным при правильном применении. К нему прибегают разработчики в тех случаях, когда необходимо предоставить возможность заказчикам самостоятельно регулировать перечень свойств той или иной сущности. Чаще такие методы внедрения можно увидеть в компании, где в будущем планируется увеличение параметров учета чего-либо. Планы видов характеристик – отличная возможность сделать счастливым заказчика с нечетким техническим заданием.
Создаем ПВХ в 1С
Отличительная особенность объекта «План видов характеристик» заключается в возможности пользователей самостоятельно добавлять разрезы учета для элементов справочника в 1С. Разработчику нужно лишь один раз настроить ПВХ, и более пользователи не будут его беспокоить по поводу добавления характеристик справочника. План видов характеристик поможет в ситуациях, когда у сотрудников заказчика нет четкой определенности относительно свойств учитываемых элементов, а внедрение запустилось.
Еще одна ситуация, где ПВХ будет оптимальным решением – перепроверка элементов с указанием новых свойств. К примеру, в 1С номенклатуру всегда добавляли, указывая только наименование, а теперь решили, что нужно указывать цвет, длину и марку. Многие решают эту ситуацию с помощью текстового поля «Комментарий», куда заносят всю информацию через запятую. Этот путь ведет к проблеме усложнения получения правильных данных из отчетов, в отличие от добавления плана видов характеристик.
ПВХ добавляется через конфигуратор: в дереве объектов находим ветку «Планы видов характеристик» и с помощью кнопки «Добавить» создаем новый элемент. Записываем название, отражающее сущность, и с помощью поля «Тип значения характеристик» определяем, какие типы значений смогут указывать наши пользователи. Указывать можно примитивные типы, справочники, перечисления и другие ПВХ.
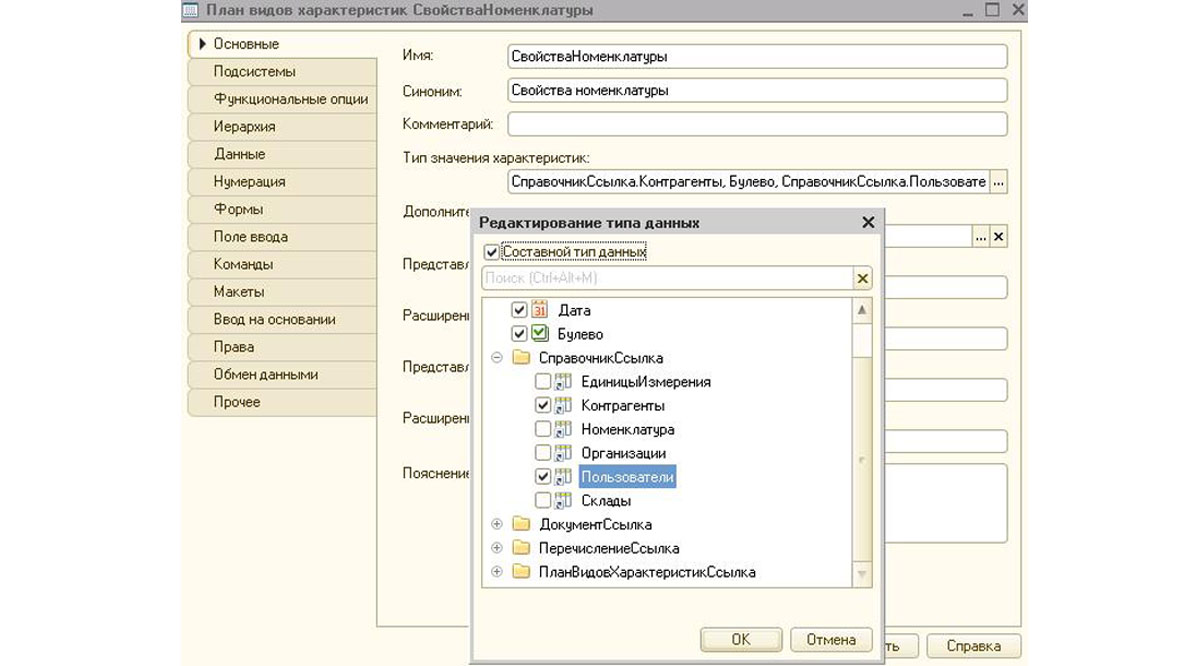
Для возможности добавлять различные характеристики и качества, которых нет в 1С, нам необходимо добавить дополнительный справочник, подчиненный созданному ПВХ. В нем будут содержаться значения качеств, которые пользователи будут добавлять в план видов характеристик. Они будут привязаны к конкретному качеству, и сотрудники компании не смогут выбрать неподходящее значение.
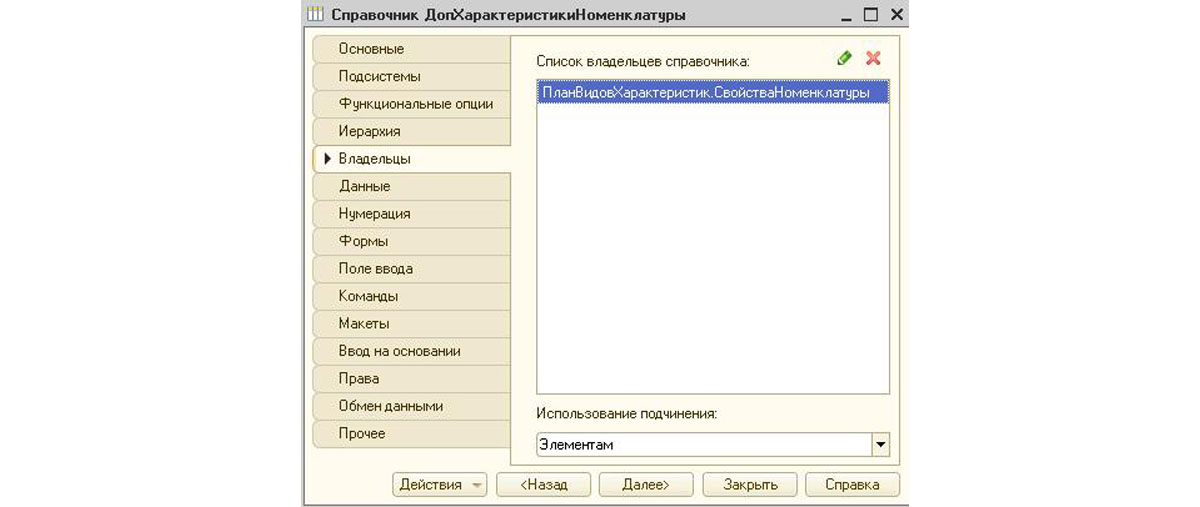
После создания подчиненного справочника в ПВХ во вкладке «Основное» нужно выбрать его в поле «Дополнительные значения характеристик». Осталось лишь создать новый регистр сведений, где и будут храниться все данные по дополнительным характеристикам, введенные пользователями. Это будет непериодический независимый РС со следующими полями (вкладка «Данные»):
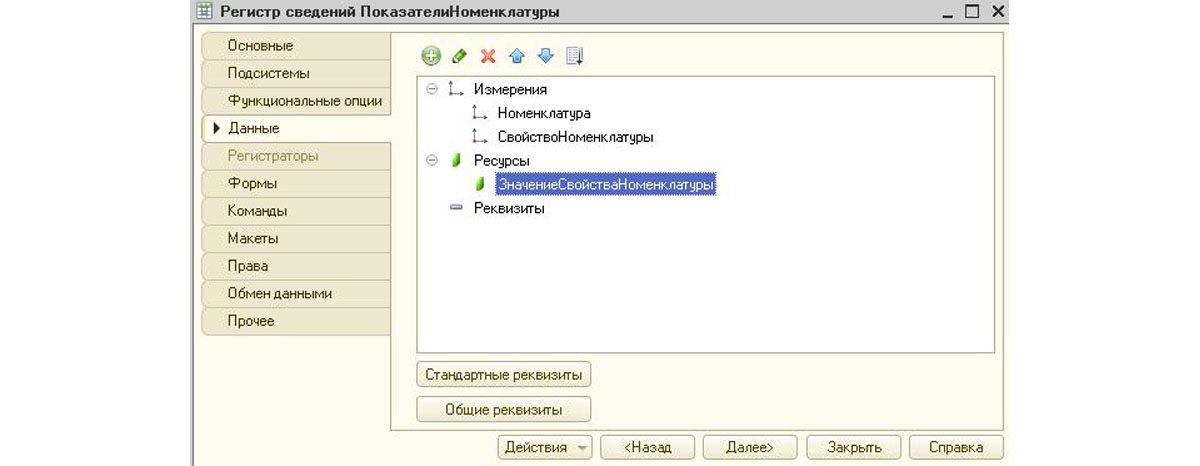
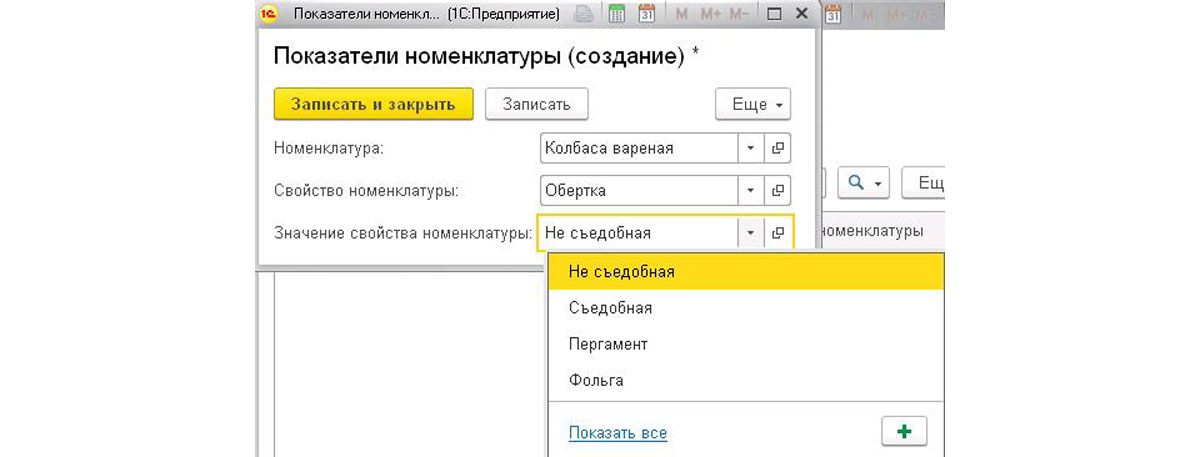
- Измерение «Номенклатура». Тип – ссылка на соответствующий справочник, отметка «Ведущее» обязательна, чтобы в 1С при открытии номенклатуры пользователь мог указывать дополнительные показатели;
- Измерение «СвойствоНоменклатуры». Тип – ссылка на созданный ПВХ;
- Ресурс «ЗначениеСвойстваНоменклатуры». Тип – Характеристика.СвойствоНоменклатуры, в свойство «Связь по типу» указываем Свойствономенклатуры. Для удобства пользователей настройте связи параметров выбора, указав отбор по владельцу (СвойствоНоменклатуры).
Проверка работоспособности
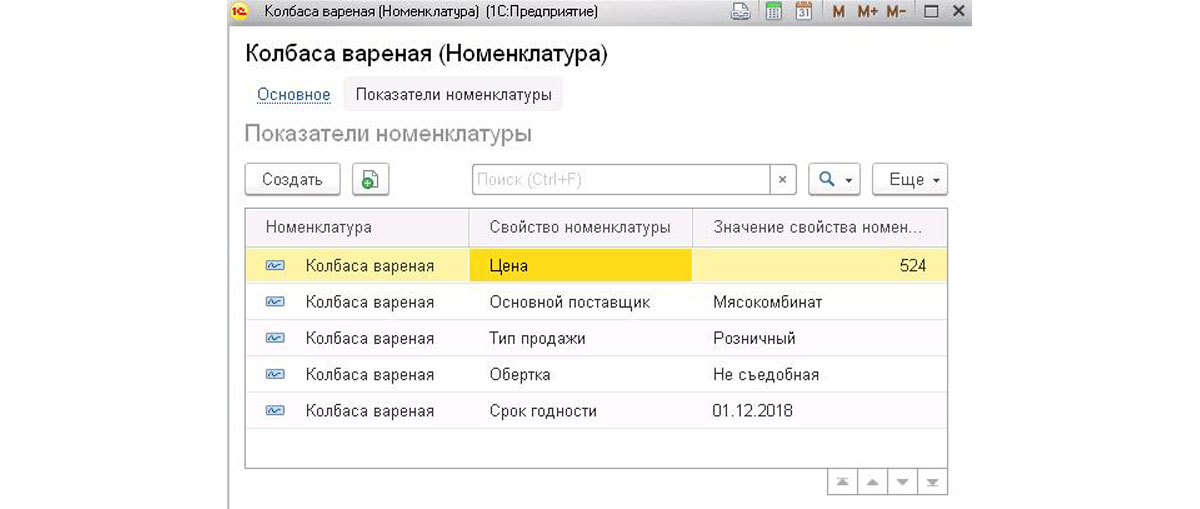
После всех вышеперечисленных настроек остается только обновить базу, настроить права и запустить 1С для проверки работоспособности всей схемы. Открыв любую номенклатуру, мы увидим сверху имя нашего регистра сведений в виде ссылки. Нажатие на нее откроет пустую таблицу из полей, созданного нами РС, с возможностью создавать в ней записи.
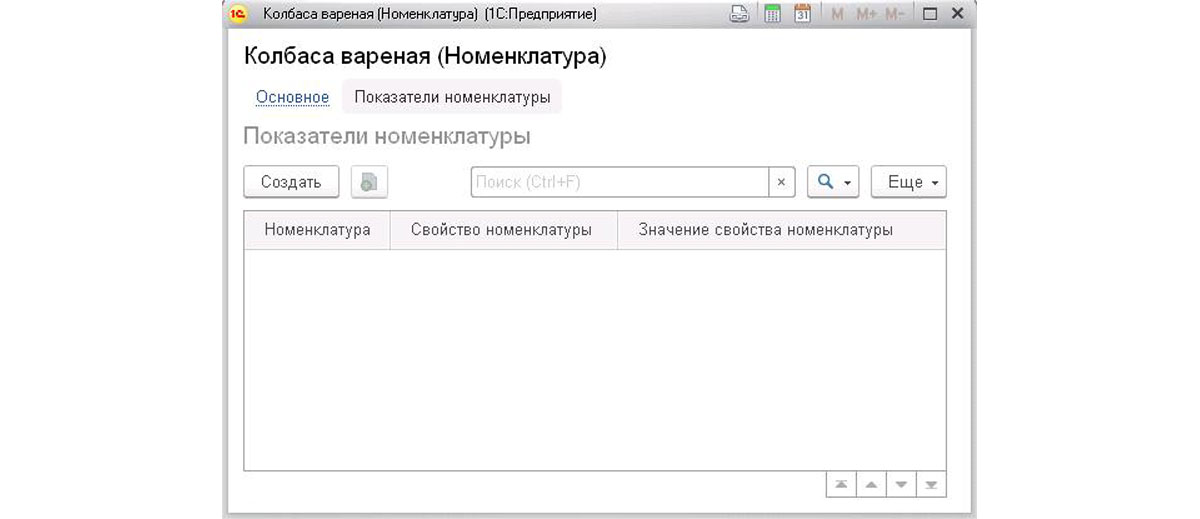
При создании 1С автоматически заполняет номенклатуру и предлагает нам определиться с нужным свойством и его значением. Причем при выборе свойства, если в списке нет нужной вам характеристики номенклатуры, есть возможность ее добавить в созданный нами ПВХ. При добавлении нового разреза укажите наименование, тип значения и обратите внимание на имя созданного справочника в виде ссылки. Если перейти по ней, то увидим все значения этого свойства, внесенные в справочник.


Создадим несколько записей в справочнике для новой характеристики номенклатуры. Обратите внимание, что при добавлении в справочник из этого меню, поле «Владелец» автоматически заполняется нужным нам свойством номенклатуры. Остается лишь вписать значение и записать новый элемент справочника. Добавив все нужные значения в справочник, закрывайте окно и выбирайте созданное свойство номенклатуры.

При попытке выбрать значение 1С предлагает вам только те данные, которые вы добавили именно для выбранного качества товара. Это обеспечит отсутствие ошибок пользователя и сделает работу в 1С удобнее по сравнению с тем, когда пришлось бы выбирать из всего перечня значений. Еще одно полезное ограничение обеспечивает сама платформа 1С – невозможно добавить два одинаковых свойства номенклатуры – появится ошибка об уже существующей записи.

Количество характеристик не ограничено, и даже если пользователи 1С будут каждый день добавлять новые свойства, вышеуказанная схема сохранит свою работоспособность. В конфигурации может появиться новый справочник и возникнет потребность указывать его элементы в виде значения свойств номенклатуры. В таких случаях достаточно лишь зайти в конфигуратор и добавить новый объект в типы значения характеристик созданного нами ПВХ. Обновив конфигурацию, мы увидим, что задача решена, и пользователи могут использовать данные нового справочника.
Помните о том, что теперь некоторые элементы справочников используются в регистре сведений и при удалении необходимо убирать ссылки на них. В противном случае стандартная процедура платформы по удалению объектов не сможет ликвидировать элемент справочника. Если все же объект удалить без поиска ссылок на него, то вместо него вы увидите надпись «Объект не найден».