Razdel — сегментация русскоязычного текста на токены и предложения
Python-библиотека Razdel — часть проекта Natasha, делит русскоязычный текст на токены и предложения.
>>> from razdel import tokenize, sentenize >>> text = 'Кружка-термос на 0.5л (50/64 см³, 516;. )' >>> tokens = list(tokenize(text)) >>> tokens [Substring(start=0, stop=13, text='Кружка-термос'), Substring(start=14, stop=16, text='на'), Substring(start=17, stop=20, text='0.5'), Substring(start=20, stop=21, text='л'), Substring(start=22, stop=23, text='(') . ] >>> text = ''' . - "Так в чем же дело?" - "Не ра-ду-ют". . И т. д. и т. п. В общем, вся газета . ''' >>> list(sentenize(text)) [Substring(start=1, stop=23, text='- "Так в чем же дело?"'), Substring(start=24, stop=40, text='- "Не ра-ду-ют".'), Substring(start=41, stop=56, text='И т. д. и т. п.'), Substring(start=57, stop=76, text='В общем, вся газета')]
Скорость и качество сопоставимы или выше, чем у других открытых решений.
| Ошибки на 1000 токенов | Время обработки, секунды | |
|---|---|---|
| Regexp-baseline | 19 | 0.5 |
| SpaCy | 17 | 5.4 |
| NLTK | 130 | 3.1 |
| MyStem | 19 | 4.5 |
| Moses | 11 | 1.9 |
| SegTok | 12 | 2.1 |
| SpaCy Russian Tokenizer | 8 | 46.4 |
| RuTokenizer | 15 | 1.0 |
| Razdel | 7 | 2.6 |
| Ошибки на 1000 предложений | Время обработки, секунды | |
|---|---|---|
| Regexp-baseline | 76 | 0.7 |
| SegTok | 381 | 10.8 |
| Moses | 166 | 7.0 |
| NLTK | 57 | 7.1 |
| DeepPavlov | 41 | 8.5 |
| Razdel | 43 | 4.8 |
Число ошибок среднее по 4 датасетам: SynTagRus, OpenCorpora, GICRYA and RNC. Подробнее в репозитории Razdel.
В чём сложность?
В русском языке предложения обычно заканчиваются точкой, вопросительным или восклицательным знаком. Просто разделим текст регулярным выражением [. ]\s+ . Такое решение даст 76 ошибок на 1000 предложений.
… любая площадка с аудиторией от 3 тыс.| |человек является блогером.
… над ними с конца XVII в.| |стоял бей;
… в Камерном музыкальном театре им.| |Б.А. Покровского.
В след за операми «Идоменей» В.А.| |Моцарта – Р.| |Штрауса …
2.| |думал будет в финское консульство красивая длинная очередь …
г.| |билеты на поезда российских железных дорог …
В конце предложения многоточие, смайлик.
Кто предложит способ избавления от минусов — тому спасибо :)| |Посмотрел, призадумался…| |Вот это уже более неприятно, поскольку содержательность нарушится.
Цитаты, прямая речь, в конце предложения кавычка.
— невесты у вас в городе есть?»| |«Кому и кобыла невеста».
«Как хорошо, что я не такой!»| |Сейчас при переводе сделал фрейдстскую ошибку:»идология».
Razdel учитывает эти нюансы, сокращает число ошибок до 43 на 1000 предложений.
С токенами аналогичная ситуация. Хорошее базовое решение даёт регулярное выражение [а-яё-]+|[0-9]+|[^а-яё0-9 ] , оно делает 19 ошибок на 1000 токенов.
… В конце 1980|-х — начале 1990|-х … БС-|3 можно отметить слегка меньшую массу (3|,|6 т) — да и умерла.|.|. Понял ли девку, сокол?|!
Razdel сокращает число ошибок до 7 на 1000 токенов.
Принцип работы
Система построена на правилах. Принцип сегментации на токены и предложения одинаковый.
Сбор кандидатов
Находим в тексте всех кандидатов на конец предложения: точки, многоточия, скобки, кавычки.
6.| |Наиболее частый и при этом высоко оцененный вариант ответов «я рада»| |(13 высказываний, 25 баллов)| |– ситуации получения одобрения и поощрения.| |7.| |Примечательно, что в ответе «я знаю»| |оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»|;| |присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни»| |и «рано или поздно придется рожать»|.| |Составители: В.| |П.| |Головин, Ф.| |В.| |Заничев, А.| |Л.| |Расторгуев, Р.| |В.| |Савко, И.| |И.| |Тучков.
Для токенов дробим текст на атомы. Внутри атома точно не проходит граница токена.
В| |конце| |1980|-|х| |-| |начале| |1990|-|х| БС|-|3| |можно| |отметить| |слегка| |меньшую| |массу| |(|3|,|6| |т|)| |—| |да| |и| |умерла|.|.|.| |Понял| |ли| |девку|,| |сокол|?|!
Объединение
Последовательно обходим кандидатов на разделение, убираем лишние. Используем список эвристик.
Элемент списка. Разделитель — точка или скобка, слева число или буква.
6.| |Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения. 7.| |Примечательно, что в ответе «я знаю» …
Инициалы. Разделитель — точка, слева одна заглавная буква.
… Составители: В.| |П.| |Головин, Ф.| |В.| |Заничев, А.| |Л.| |Расторгуев, Р.| |В.| |Савко, И.| |И.| |Тучков.
Справа от разделителя нет пробела.
… но лишь раз встречается ответ «я женщина»|; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать»|.
Перед закрывающей кавычкой или скобкой нет знака конца предложения, это не цитата и не прямая речь.
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада»| |(13 высказываний, 25 баллов)| |– ситуации получения одобрения и поощрения. … «один брак – это всё, что меня ждет в этой жизни»| |и «рано или поздно придется рожать».
В результате остаётся два разделителя, считаем их концами предложений.
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения.| |7. Примечательно, что в ответе «я знаю» оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать».| |Составители: В. П. Головин, Ф. В. Заничев, А. Л. Расторгуев, Р. В. Савко, И. И. Тучков.
Для токенов процедура аналогичная, правила другие.
Дробь или рациональное число.
— да и умерла.|.|. Понял ли девку, сокол?|!
Вокруг дефиса нет пробелов, это не начало прямой речи.
В конце 1980|-|х — начале 1990|-|х БС|-|3 можно отметить …
Всё что осталось считаем границами токенов.
В| |конце| |1980-х| |-| |начале| |1990-х| БС-3| |можно| |отметить| |слегка| |меньшую| |массу| |(|3,6| |т|)| |—| |да| |и| |умерла|. | |Понял| |ли| |девку|,| |сокол|?!
Ограничения
Правила в Razdel оптимизированы для аккуратно написанных текстов с правильной пунктуацией. Решение хорошо работает с новостными статьями, художественными текстами. На постах из социальных сетей, расшифровках телефонных разговоров качество ниже.
Если между предложениями нет пробела или в конце нет точки или предложение начинается с маленькой буквы, Razdel сделает ошибку.
Использование
natural_language_processing — чат пользователей, разработчиков проекта.

- alex@alexkuk.ru
- alexkuk
- kuk
Лаборатория разрабатывает сервисы и коробочные продукты с использованием технологии Natasha, оказывает услуги анализа данных для российских компаний.
Разделить текст на несколько столбцов в Excel с помощью Python

В различных случаях вам может понадобиться разбить текст в столбце на несколько столбцов на листе Excel. Критерием разделения может быть пробел, запятая, специальный символ и т. д. В этой статье вы узнаете, как разбить текст на столбцы на листе Excel с помощью Python. Он автоматизирует функцию «Текст в столбцы» MS Excel.
- Python API для преобразования текста в столбцы Excel
- Разделить текст на столбцы в Excel с помощью Python
Python API для преобразования текста в столбцы Excel#
Чтобы разделить текст в одном столбце на несколько столбцов на листе Excel, мы будем использовать Aspose.Cells для Python через Java. Это мощный и многофункциональный API, который позволяет создавать, изменять и преобразовывать файлы Excel с помощью Python. Вы можете установить API, используя следующую команду pip.
pip install aspose-cells Разделить текст на столбцы в Excel с помощью Python#
Ниже приведены шаги для разделения текста на столбцы в Excel с использованием Python.
- Сначала загрузите файл Excel с помощью класса Workbook.
- Получите ссылку на рабочий лист, где вы хотите разделить текст.
- Добавьте значения в ячейки (необязательно).
- Создайте экземпляр класса TxtLoadOptions и укажите символ разделения с помощью метода TxtLoadOptions.setSeparator(value).
- Разделить текст на столбец с помощью метода Worksheet.getCells().textToColumns(int row, int column, int totalRows, TxtLoadOptions options).
- Наконец, сохраните файл Excel, используя метод Workbook.save(fileName, SaveFormat.XLSX).
В следующем примере кода показано, как выполнить операцию преобразования текста в столбцы Excel в Python.
# Open Workbook workbook = Workbook("workbook.xlsx") # Access the first worksheet worksheet = workbook.getWorksheets().get(0) # Add people name in column A. Fast name and Last name are separated by space. worksheet.getCells().get("A1").putValue("John Teal") worksheet.getCells().get("A2").putValue("Peter Graham") worksheet.getCells().get("A3").putValue("Brady Cortez") worksheet.getCells().get("A4").putValue("Mack Nick") worksheet.getCells().get("A5").putValue("Hsu Lee") # Create text load options with space as separator. txtLoadOptions = TxtLoadOptions() txtLoadOptions.setSeparator(' ') # Split the column A into two columns using TextToColumns() method. # Now column A will have first name and column B will have second name. worksheet.getCells().textToColumns(0, 0, 5, txtLoadOptions) # Save the excel file. workbook.save("TextToColumns.xlsx") Выход#
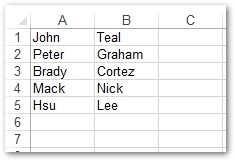
Получите бесплатную лицензию API#
Вы можете получить временную лицензию, чтобы использовать API без ограничений пробной версии.
Вывод#
В этой статье вы узнали, как разделить текст на столбцы в Excel с помощью Python. Точнее, вы видели, как разделить текст в столбце на несколько столбцов в Excel с помощью Python. Вы можете узнать больше об Aspose.Cells для Python через Java, используя документацию. Если у вас возникнут вопросы, свяжитесь с нами через наш форум.
Смотрите также#
- Aspose.Cells Product Family
- Excel Text to Column in Python
- Python Text to Column in Excel
- Split Text to Columns in Excel using Python
Как в Python разбить строку на символы
3 простых способа, которые можно использовать в работе и пет-проектах.

Иллюстрация: Оля Ежак для Skillbox Media

Дмитрий Зверев
Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
А зачем, собственно, в Python разбивать строки на символы? Например, для того, чтобы проверять правильность пароля и почты клиента, когда он регистрируется в онлайн-сервисе.
Скажем, на нашем сайте есть требование: в пароле должны быть как минимум одна заглавная, одна строчная буква и одна цифра. Мы можем написать скрипт на Python, который проверяет каждый символ и выносит вердикт: верный пароль или нет.
Если вы ещё не знакомы с Python, советуем прочитать нашу статью, в которой мы рассказываем, как быстро и бесплатно изучить этот замечательный язык программирования.
Циклы for и while, или метод «в лоб»
Как работает: проходит по каждому символу в строке и добавляет его в отдельный список.
Самый примитивный способ поделить строку на символы — сделать это с помощью циклов. Выбираем нужные символы из строки и складываем в список.
Выглядит это так:

Генераторы списков — то же, что и for, но короче
Как работает: делает то же самое, что и цикл for, но записывается всего в одну строчку.
password = 'f#da94AAd' symbols = [symbol for symbol in password] print(symbols)
['f', '#', 'd', 'a', '9', '4', 'A', 'A', 'd']
Здесь мы использовали встроенную в Python возможность — list comprehension. Термин сложно перевести на русский, поэтому его называют генератором списков.
Суть простая — это обычный цикл for, который записывается в одну строчку. Чтобы понять, как он работает, перепишем код выше в виде обычного цикла for:
# symbols = [symbol for symbol in password] symbols = [] for symbol in password: symbols += symbol
В короткой записи мы указываем, из какого списка берём элементы — in password, как будем именовать текущий элемент — for symbol, и что делаем с самим элементом — просто сохранять в неизменном виде: symbol.
�� Генераторы списков позволяют записывать длинный цикл for в одну строку. Это полезно, когда не нужно сильно изменять данные, а нужно просто сохранить их.
Функция list — для самых продуктивных
Как работает: делает то же самое, что и циклы for и while, но сокращает количество строк кода.
Когда не хотим писать даже пару строк кода, но разложить строку на символы всё ещё нужно, на помощь приходит функция list. Она превращает набор элементов в список:
password = 'f#da94AAd' symbols = list(password) print(symbols)
['f', '#', 'd', 'a', '9', '4', 'A', 'A', 'd']
Получили такой же результат, но использовали всего одну строку кода. Очень неплохо.
Проверим работу функции проверки пароля:
if check_password(symbols): print('Пароль верный') else: print('Пароль неверный')
'Пароль верный'
�� Функция list — самая лаконичная. Чтобы получить список символов, из которых состоит строка, достаточно просто вызвать функцию со строкой в качестве аргумента.
Что запомнить
Выделим главные тезисы из статьи:
- использование циклов for и while — это самый простой, но не самый эффективный способ достать из строки все символы;
- генераторы списков — это удобная и короткая замена цикла for;
- применение функции list — самый короткий способ разбить строку на символы.
Читайте также:
- Словари в Python: что нужно знать и как пользоваться
- «Прошёл модуль курса и начал рассылать резюме»: музыкант, который стал питонистом
- Создаём первую игру на Python и Pygame
Как разбить текст на абзацы с помощью Python

В этой статье будет представлен подход, использованный мной в проекте, посвященном реферированию подкастов. Корректное реферирование текста всегда начинается с разделения его на смысловые части — абзацы.
Общий подход
Нам предстоит превратить текст в нечто понятное машине, т.е. в векторы. В практике обработки естественного языка векторное представление текста называется эмбеддингом (встраиванием). Есть два способа его проведения.
- Использование текстов, похожих на те, которые, как можно предположить, будут приняты функцией.
- Применение предварительно обученной модели эмбеддинга.
Второй вариант реализуется быстрее и позволяет достичь приемлемых результатов. Существует несколько предварительно обученных моделей эмбеддинга. Выберем одну из представленных тут.
Остановим свой выбор на модели эмбеддинга с наилучшим показателем общей производительности — all-mpnet-base-v2 .
Начнем с того, что загрузим все необходимые пакеты, необходимые для работы.
# Сначала импортируем самые важные библиотеки
import pandas as pd
import numpy as np
# Библиотека для импорта предварительно обученной модели по эмбеддингу предложений
from sentence_transformers import SentenceTransformer
# Вычисление сходств между предложениями
from sklearn.metrics.pairwise import cosine_similarity
# Библиотека для визуализации
import seaborn as sns
import matplotlib.pyplot as plt
# Пакет для поиска локальных минимумов
from scipy.signal import argrelextrema
Шаг 1. Эмбеддинг
Предварительно обученная модель значительно облегчит задачу. Предположим, что у нас есть случайный текст.
Let me tell you a little story. When I was a little kid I really liked to play football. I wanted to be like Messi and play at Camp Nou. However, I was really bad at it and now I’m not training at Camp Nou. I’m writing a medium article on chunking text.
Позвольте мне рассказать небольшую историю. Когда я был маленьким, я очень любил играть в футбол. Я хотел быть похожим на Месси и играть на стадионе “Камп Ноу”. Однако у меня очень плохо получалось, и сейчас я не тренируюсь на “Камп Ноу”. Я пишу статью на Medium о разбивке текста на части.
Нам нужно превратить этот текст в векторное представление:
# Загрузка модели (не пытайтесь делать это в домашних условиях, процесс может занять некоторое время из-за размера в 420 мб)
model = SentenceTransformer('all-mpnet-base-v2')
# Разделение текста на предложения
sentences = text.split('. ')
# Эмбеддинг предложений
embeddings = model.encode(sentences)
print(embeddings.shape)
>> (5, 768)
Свершилось чудо: 5 предложений обычного текста превратились в 768-мерную среду! Что это дает? Теперь предложения стали векторами и можно проверить, насколько близки (то есть похожи) эти векторы в 768 измерениях. Для этого используем простейший способ — скалярное произведение.
Шаг 2. Скалярное произведение/мера подобия
Выражаясь простым языком, скалярное произведение показывает, насколько один вектор совпадает с другим. Если два вектора (предложения) направлены в одну сторону, считается, что они похожи. Проверим это на практике.
# Выбор строки (предложения) и всех столбцов first_sentence = embeddings[0,:] second_sentence = embeddings[1,:] third_sentence = embeddings[2,:] fourth_sentence = embeddings[3,:] fifth_sentence = embeddings[4,:] # Насколько похожи второе и третье предложения print(f'Dot product of second and third sentence is ') print(f'Dot product of third and fourth sentence is ') print(f'Dot product of fourth and fith sentence is ') >> Скалярное произведение второго и третьего предложений составляет 0.4578239619731903 >> Скалярное произведение третьего и четвертого предложений составляет 0.4315364956855774 >> Скалярное произведение четвертого и пятого предложений составляет -0.07396048307418823 # Напоминание о тексте 2. Когда я был маленьким, я очень любил играть в футбол. 3. Я хотел быть похожим на Месси и играть на стадионе “Камп Ноу”. 4. Однако у меня очень плохо получалось, и сейчас я не тренируюсь на “Камп Ноу”. 5. Я пишу статью на Medium о разбивке текста на части.
Это впечатляющий результат, учитывая, что было использовано всего несколько строк кода. Как видите, 5-е предложение идет в другом направлении, чем 4-е (-0,07). Модель успешно отличила смысл предложения об эмбеддинге от предложений о футболе.
Однако есть гораздо лучший способ увидеть сходство предложений сразу — создать матрицу подобия. В Sklearn есть удобная функция для вычисления меры подобия — cosine_similarity . Почему не стоит использовать скалярное произведение? Хороший вопрос. Если векторы имеют одинаковую длину (величину), нет никакой разницы между скалярным произведением и мерой подобия. Я показал скалярное произведение только для того, чтобы объяснить, как это работает “под капотом”.
# Создание матрицы подобия
similarities = cosine_similarity(embeddings)
# Построение графика, отражающего полученный результат
sns.heatmap(similarities,annot=True).set_title('Cosine similarities matrix');
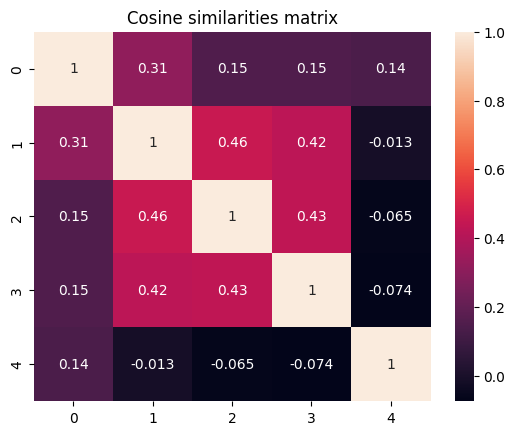
Здесь можно заметить интересную закономерность. Красный квадрат в середине — это часть текста, где сообщается о футболе. А как это будет выглядеть, если дважды поменять тему сообщения? Создадим новый текст и построим граф результатов.
Let me tell you a little story. When I was a little kid I really liked to play football. I wanted to be like Messi and play at Camp Nou. However, I was really bad at it and now I’m not training at Camp Nou. I’m writing a medium article on embeddings. In this article, I want to show how are we going to split a text into parts. We first embed sentences. Then we compute sentence similarities. After that, we detect the split point in the text. After finishing this process we will go play chess with friends.
Позвольте мне рассказать небольшую историю. Когда я был маленьким, я очень любил играть в футбол. Я хотел быть похожим на Месси и играть на стадионе “Камп Ноу”. Однако у меня очень плохо получалось, и сейчас я не тренируюсь на “Камп Ноу”. Я пишу статью на Medium о разбивке текста на части. В этой статье я хочу показать, как разделить текст на части. Сначала выполняется векторное представление предложений. Затем вычисляется мера подобия предложений. Потом определяются точки разделения в тексте. По завершении этого процесса мы пойдем играть в шахматы с друзьями.
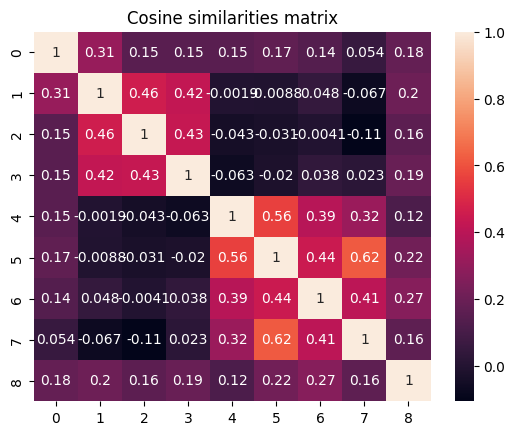
Наверняка вы уже уловили закономерность, заметив две разные темы и их точки разделения.
Шаг 3. Определение точек разделения
То, что легко увидеть человеку, не всегда легко заметить компьютеру. Поэтому нужно создать некий паттерн, который поможет ему различать эти точки разделения.
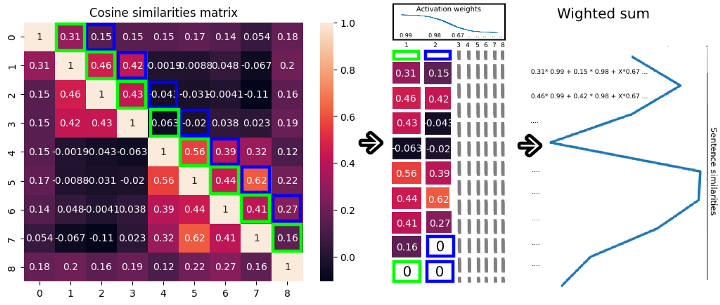
- Возьмем каждую диагональ справа от главной диагонали, которая будет являться подобием некоторых предложений со следующими предложениями.
- Перед каждым предложением стоит разное количество предложений, поэтому нужно заполнить каждую диагональ нулями в конце, чтобы они были одинаковой длины.
- Сложим эти диагонали в новую матрицу, чтобы применить активацию.
- Применим веса активации к каждой строке, чтобы самые близкие предложения имели наибольший вес, определяющий подобие. В данном случае будем использовать в качестве активации обратную сигмоиду с нулевым хвостом (в коде это будет более понятно).
- Вычислим взвешенную сумму каждой строки, чтобы создать векторное представление подобия каждого предложения ближайшим предложениям в тексте.
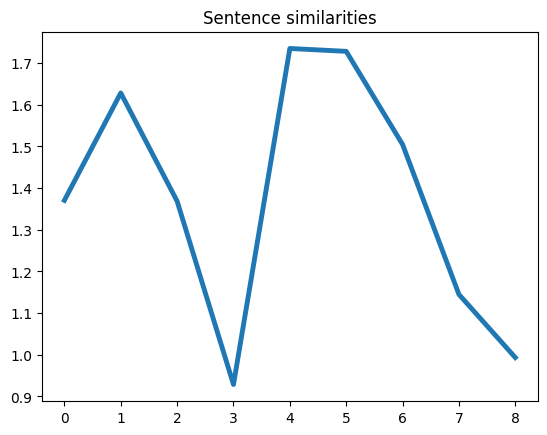
Это более простое для понимания представление потока данных текста. И снова видим, что 4-е предложение с индексом 3 является точкой разделения. Теперь переходим к заключительной части.
6. Найдем относительные векторные минимумы.
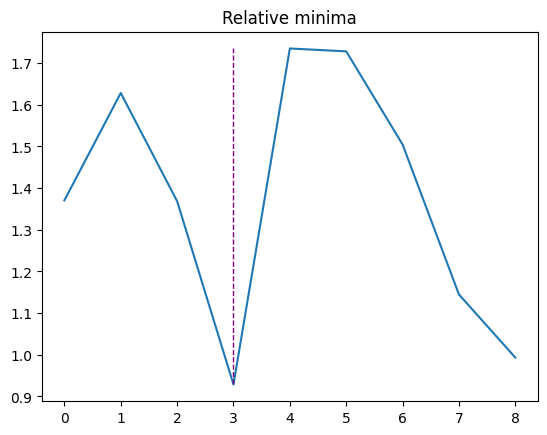
“Графически относительные экстремумы — это вершины и впадины графа функции, причем вершины — это точки относительных максимумов, а впадины — точки относительных минимумов. Сочетание относительных максимумов и минимумов называется относительным экстремумом”. Более подробная информация — по ссылке.
Вот код для выполнения всех шагов:
def rev_sigmoid(x:float)->float: return (1 / (1 + math.exp(0.5*x))) def activate_similarities(similarities:np.array, p_size=10)->np.array: """ Функция возвращает список взвешенных сумм активированных сходств предложений Аргументы: similarities (numpy array): это должна быть квадратная матрица, где каждое предложение соответствует другому согласно мере подобия. p_size (int): количество предложений используется для расчета взвешенной суммы Возврат: list: список взвешенных сумм """ # Чтобы создать веса для сигмоидной функции, сначала нужно создать пространство. P_size определяет количество используемых предложений и размер вектора весов. x = np.linspace(-10,10,p_size) # Затем необходимо применить функцию активации к созданному пространству y = np.vectorize(rev_sigmoid) # Поскольку мы применяем активацию только к количеству предложений p_size, мы должны добавить нули, чтобы пренебречь эффектом каждого дополнительного предложения, а для соответствия длине вектора мы умножим activation_weights = np.pad(y(x),(0,similarities.shape[0]-p_size)) ### 1. Возьмите каждую диагональ справа от главной диагонали diagonals = [similarities.diagonal(each) for each in range(0,similarities.shape[0])] ### 2. Заполните каждую диагональ нулями в конце. Поскольку каждая диагональ имеет разную длину, мы должны проводить заполнение нулями в конце. diagonals = [np.pad(each, (0,similarities.shape[0]-len(each))) for each in diagonals] ### 3. Сложите эти диагонали в новую матрицу diagonals = np.stack(diagonals) ### 4. Примените веса активации к каждой строке. Умножьте сходства на активацию. diagonals = diagonals * activation_weights.reshape(-1,1) ### 5. Рассчитайте взвешенную сумму активированных сходств activated_similarities = np.sum(diagonals, axis=0) return activated_similarities # Применим нашу функцию. Длинные предложения: рекомендую использовать 10 или более предложений activated_similarities = activate_similarities(similarities, p_size=5) # Создадим пустую фигуру для графика fig, ax = plt.subplots() ### 6. Найдите относительные минимумы вектора. Все локальные минимумы следует сохранить в переменной с помощью функции argrelextrema minmimas = argrelextrema(activated_similarities, np.less, order=2) # Параметр order управляет частотой разделений. Я бы не рекомендовал изменять его. # Постройте график потока текста с активированными сходствами sns.lineplot(y=activated_similarities, x=range(len(activated_similarities)), ax=ax).set_title('Relative minimas'); # Теперь проведем вертикальные линии, чтобы увидеть, где было создано разделение plt.vlines(x=minmimas, ymin=min(activated_similarities), ymax=max(activated_similarities), colors='purple', ls='--', lw=1, label='vline_multiple - full height')
Алгоритм в действии
Теперь от небольшого текста перейдем к выполнению практической задачи — разбивке на части транскриптов длинных видео и подкастов. Во время последней презентации проекта один из наших преподавателей спросил, можем ли мы сделать реферирование для этого видео.
Работа с длинными текстами
Я еще не упомянул одну важную деталь: при работе с длинными текстами вы столкнетесь с тем, что очень короткие предложения создают неожиданные точки смены. Чем короче предложение, тем меньше у него возможностей подобия. Чем короче текст, тем меньше информации он содержит -> меньше возможных вариантов подобия может быть найдено.
Есть множество способов решения этой проблемы, но для наглядности воспользуемся самым простым решением — сократим очень длинные предложения и уменьшим количество очень коротких.
# Определение длины каждого предложения
sentece_length = [len(each) for each in sentences]
# Определение самого длинного выброса
long = np.mean(sentece_length) + np.std(sentece_length) *2
# Определение самого короткого выброса
short = np.mean(sentece_length) - np.std(sentece_length) *2
# Сокращение длинных предложений
text = ''
for each in sentences:
if len(each) > long:
# Заменим все запятые точками
comma_splitted = each.replace(',', '.')
else:
text+= f'. '
sentences = text.split('. ')
# Теперь объединим короткие.
text = ''
for each in sentences:
if len(each) < short:
text+= f' '
else:
text+= f'. '
Теперь выполним следующие шаги.
1. Проведем эмбеддинг в отношении предложений и рассчитаем меру подобия.
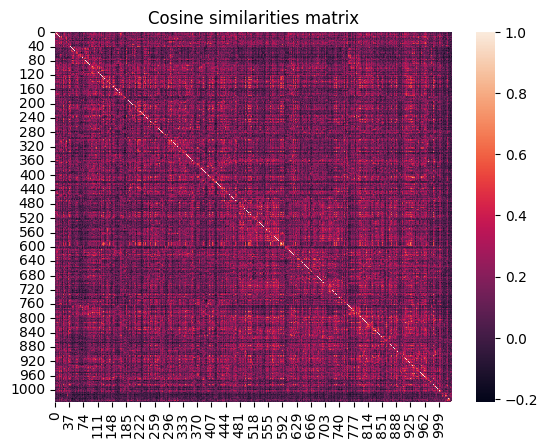
2. Определим точки разделения.
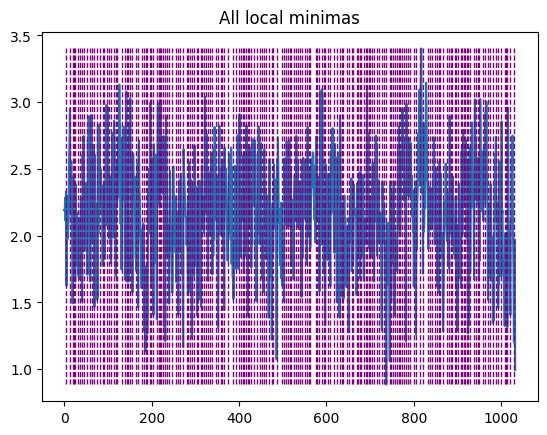
Увеличим масштаб некоторых частей, чтобы можно было реально увидеть картину.
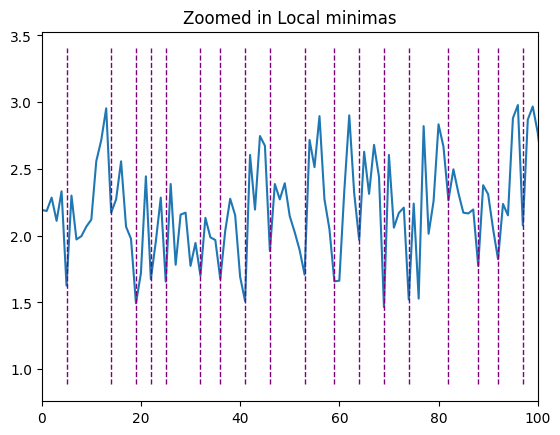
Шаг 4. Создание текста, разбитого на абзацы
После получения точек разделения осталось самое простое, но самое важное — внедрить их в текст.
# Получение порядкового номера предложений, которые находятся в точках разделения
split_points = [each for each in minmimas[0]]
# Создание пустой строки
text = ''
for num,each in enumerate(sentences):
# Проверьте, является ли предложение минимумом (точкой разделения)
if num in split_points:
# Если да, то добавьте точку в конец предложения и абзац перед ним.
text+=f'\n\n . '
else:
# Если это обычное предложение, просто поставьте точку в конце и продолжайте добавлять предложения.
text+=f'. '
Теперь у нас есть разбитый на абзацы текст, состоящий из 1000 предложений.
Окончательный результат
Посмотрим на фрагменты сделанных разбиений, чтобы проверить, имеет ли это смысл.
В 1625 году итальянский дворянин по имени Пьетро де ла Валет отправился в путешествие по Ближнему Востоку … В то время путешествие по этому региону было очень опасным. Османская и Персидская империи находились в состоянии войны, сражаясь за то, кто будет править в Багдаде … хороших кирпичей, большинство из которых были отмечены какими-то неизвестными буквами, которые оказались очень древними. — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — Они ушли в темноте ночи и бежали в безопасное место. Через пустыню …. Что означают символы на этих разбитых кусках глины. И если здесь когда-то стоял такой великий город, что с ним могло случиться. Меня зовут Пол Купер, и вы слушаете подкаст “Падение цивилизации”. В каждой серии я рассматриваю одну из цивилизаций прошлого, которая поднялась к славе, а затем рухнула, обратившись в прах истории. Я хотел бы знать, что у них было общего. Что привело к их падению. — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Каждый абзац отделяется новой строкой, каждое новое место в тексте отделяется знаком “ — — “, а содержание абзацев сокращается знаком “…”.
Как видите, разделение первых двух абзацев приемлемо, хотя они раскрывают одну и ту же мысль. Разделение вторых двух абзацев в месте, где автор представляется, совершенно точное. Так что в целом можно сказать, что работа проделана довольно хорошо.
Хотя она не всегда идеальна: иногда пропускается точка разделения на одно или два предложения, как здесь:
Затем я проснулся, как обескровленный человек, который бродит один в пустыне. Еще раз спасибо, что слушаете подкаст “Падение цивилизации”. Я хотел бы поблагодарить моих актеров озвучки этой серии. Ре Бригнелла, Джейка Барретта Миллса, Шема Джейкобса, Ника Брэдли и Эмили Джонсон. Я люблю читать ваши комментарии в Twitter, поэтому прощу вас поделиться своим мнением. Вы можете подписаться на меня (Paul M). Этот подкаст удается поддерживать только благодаря помощи наших щедрых подписчиков на Patreon. Вы помогаете мне работать, покрывать расходы и поддерживать подкаст без рекламы. … Если вам понравился этот подкаст, перейдите на Patreon.com.
Здесь, как видите, в первом абзаце первое предложение оказалось по ошибке, однако следующие два абзаца отлично разделены, поскольку второй — это благодарность актерам озвучки, а третий — благодарность сторонникам Patreon.
- 3 приема для определения функций в Python
- Поиск и устранение утечек памяти в Python
- Овладей Python, создавая реальные приложения. Часть 7
Читайте нас в Telegram, VK и Дзен