Файлы CSV, TXT и GPX
Если у вас имеются данные электронных таблиц, хранящиеся в виде текстового файла с разделителями-запятыми ( .csv ), или данные, хранящиеся в текстовом файле с разделителями ( .txt ) или файле в обменном формате GPS ( .gpx ), вы можете добавлять данные на портал ArcGIS Enterprise . В списке описано использование этих файлов и содержатся ссылки и инструкции. В расположенных после списка функциональности разделах содержится информация о правильном форматировании и использовании файлов CSV, TXT и GPX на вашем портале Enterprise .
- Добавьте файлы CSV, TXT или GPX на свою карту. Map Viewer добавит информацию о местоположении, отобразит на карте пространственные объекты, соответствующие каждому элементу в файле, и сохранит информацию в карте в виде слоя. После того как файл будет добавлен на карту, можно редактировать свойства создаваемого слоя. Например, можно настраивать всплывающие окна, изменять символы, задавать диапазон видимости и удалять всплывающие окна.
- Добавьте в Map Viewer файл CSV, который не содержит информацию о местоположении, в виде таблицы. Это полезно, когда вы хотите соединить непространственные данные в Интернете – например, претензии о повреждении имущества в связи с прошедшим торнадо – с пространственными данными, например, слоем почтовых индексов, используя для этого инструмент анализа Присоединить объекты.
- Если ваш файл CSV хранится на общедоступном веб-сайте, вы можете ссылаться на него, как на веб-слой. Если в файле CSV содержится информация о координатах, обновления файла CSV будут отображены на карте. Если в файле CSV содержится информация об адресах или о местоположениях, обновления файла CSV в сети не отобразятся на карте.
- Добавьте файлы CSV на свой портал и опубликуйте их, чтобы пользователи могли загрузить эти данные.
- Если у вас есть право публикации размещенных векторных слоев, можно опубликовать данные в файлах CSV.
Файлы CSV и TXT
Файлы CSV и TXT хранят информацию в текстовом виде. В первой строчке файла задаются названия всех полей. В файлах CSV поля всегда отделены друг от друга запятыми. В файлах ТХТ поля можно разделять запятой, точкой с запятой или табуляцией. Другие разделители не поддерживаются.
Если в файле не заданы типы данных, ArcGIS Enterprise опирается на имена полей и форматирование полей для интерпретации применимых типов данных.
Поля местоположений в файлах CSV и TXT
Чтобы добавить расположенный на локальном диске файл CSV или TXT или расположенный в интернете файл CSV в качестве векторного слоя либо опубликовать локальный файл CSV как размещенный векторный слой, в файл должны быть поля с информацией о местоположении. Поля местоположений могут содержать информацию о координатах, адресе и местоположении. Первая строка должна содержать названия полей местоположений. Адреса можно сортировать по одному или нескольким полям. Координаты должны находиться в двух полях.
- долгота, широта*
- широта, долгота*
- Военная система прямоугольных координат (MGRS)
- United States National Grid (USNG)
Если Map Viewer не может определить информацию о координатах либо в файле вместо координат содержится информация об адресе или местоположении, вам будет предложено просмотреть поля местоположения и при необходимости их изменить.
Поддерживаются следующие поля:
- Широта, долгота
- Lat, Long
- Longitude83, Latitude83
- Longdecdeg, Latdecdeg
- Long_dd, Latdd
- Lng
- Y, X
- Ycenter, Xcenter
- Xcenter, Ycenter
- Point-y, Point-x
- Point-x, Point-y
- MGRS:
- USNG
- Адрес
- Город
- Штат
- ZIP
Время и дата в файлах CSV
Поля даты в файлах CSV обычно содержат дату и время в формате Всемирного координированного времени (UTC). Даты указываются в формате UTC, так как сервер ваших данных может располагаться в любой точке мира. Хранение даты и времени в местном часовом поясе приводит к всевозможным проблемам, особенно если вы или сервер ваших данных перемещаетесь в другой часовой пояс.
Всякий раз, когда отображается поле даты, дата преобразуется из времени UTC в местное время. Это выполняется с помощью запроса вашего компьютера для определения его настроек часового пояса. Например, предположим, что ваш компьютер настроен на Тихоокеанское стандартное время (PST). PST отстает от UTC на восемь часов – 10:00 часов утра по UTC соответствует 2:00 часам ночи по PST.
Когда вы публикуете размещенный векторный слой из файла CSV, можно указать часовой пояс данных. Заданный часовой пояс используется, чтобы ликвидировать смещение, поскольку ArcGIS Enterprise использует время и дату в формате UTC. Например, когда файл CSV, содержащий поля даты, публикуется с часовым поясом PST, ко всем значениям даты и времени в нем добавляется восемь часов, для конвертации в UTC.
Если поля даты в CSV содержат только значения даты, но не времени, при публикации в виде векторного слоя им присваивается значение времени, соответствующее полуночи. Поэтому, если вы не задали часовой пояс при публикации, данные будут храниться с временем, соответствующим полуночи по UTC. При просмотре данных, время конвертируется в локальное, что также может привести к изменению даты. Например, 7/28/2009 0:00 соответствует полуночи по UTC 28 июля 2009. Если вы просматриваете данные на компьютере с тихоокеанским часовым поясом, дата и время будут отображаться как 7/27/2009 16:00. Выбор часового пояса при публикации позволяет убрать этот сдвиг при просмотре данных в указанном часовом поясе.
Следующие даты поддерживаются при публикации размещённого векторного слоя из файла CSV:
Хранение множества мелких и средних файлов, как оптимально: файловая система или база данных?
Как оптимально хранить CSV файлы на сервере: в базе данных Postgres или локально на сервере, а в базе хранить просто путь к файлу (файлы будут в zip архиве и архивы размером от 5 КБ до 250кб, изредка 1-2 мб)?
В CSV файле данные из базы на основе 5-10 фильтров (в итоге возвращает от 5 до 5000 записей, где для каждой записи около 120 столбцов из разных таблиц). На фронтенде есть таблица c 5 столбцами (имя, фильтры, дата создания, столбец с иконками скачивания и удаления) , где при клике по иконке скачивания должен скачиваться архив с данными для заранее заданных фильтров (архив нужен, так как может быть много мелких файлов, до 20-40, например отдельный CSV файл для каждой компании производителя техники )
Ежемесячно будет формироваться около 5000-10000 файлов, храниться они будут 6 месяцев, после чего удаляться, то есть более 100 000 файлов в базе или файловой системе не ожидается.
Хранить готовые файлы на сервере хочу из-за скорости. Мне кажется, что гораздо быстрее повторно скачать уже сформированный файл который хранится на сервере, чем каждый раз при скачивании файла 1. отправлять запрос к базе данных с фильтрами 2. на основе отфильтрованных данных сформировать CSV файл(ы) 3. заархивировать файл(ы) и 4. затем скачать. Или я неправильно думаю?
Сам склоняюсь хранить файлы в файловой системе основываясь на данной теме: https://softwareengineering.stackexchange.com/a/150724
- Вопрос задан более года назад
- 347 просмотров
4 комментария
Простой 4 комментария
Редактируем CSV-файлы, чтобы не сломать данные

Продукты HFLabs в промышленных объемах обрабатывают данные: адреса, ФИО, реквизиты компаний и еще вагон всего. Естественно, тестировщики ежедневно с этими данными имеют дело: обновляют тест-кейсы, изучают результаты очистки. Часто заказчики дают «живую» базу, чтобы тестировщик настроил сервис под нее.
Первое, чему мы учим новых QA — сохранять данные в первозданном виде. Все по заветам: «Не навреди». В статье я расскажу, как аккуратно работать с CSV-файлами в Excel и Open Office. Советы помогут ничего не испортить, сохранить информацию после редактирования и в целом чувствовать себя увереннее.
Материал базовый, профессионалы совершенно точно заскучают.
Что такое CSV-файлы
Формат CSV используют, чтобы хранить таблицы в текстовых файлах. Данные очень часто упаковывают именно в таблицы, поэтому CSV-файлы очень популярны.

CSV-файл состоит из строк с данными и разделителей, которые обозначают границы столбцов
CSV расшифровывается как comma-separated values — «значения, разделенные запятыми». Но пусть название вас не обманет: разделителями столбцов в CSV-файле могут служить и точки с запятой, и знаки табуляции. Это все равно будет CSV-файл.
У CSV куча плюсов перед тем же форматом Excel: текстовые файлы просты как пуговица, открываются быстро, читаются на любом устройстве и в любой среде без дополнительных инструментов.
Из-за своих преимуществ CSV — сверхпопулярный формат обмена данными, хотя ему уже лет 40. CSV используют прикладные промышленные программы, в него выгружают данные из баз.
Одна беда — текстового редактора для работы с CSV мало. Еще ничего, если таблица простая: в первом поле ID одной длины, во втором дата одного формата, а в третьем какой-нибудь адрес. Но когда поля разной длины и их больше трех, начинаются мучения.

Следить за разделителями и столбцами — глаза сломаешь
Еще хуже с анализом данных — попробуй «Блокнотом» хотя бы сложить все числа в столбце. Я уж не говорю о красивых графиках.
Поэтому CSV-файлы анализируют и редактируют в Excel и аналогах: Open Office, LibreOffice и прочих.
Ветеранам, которые все же дочитали: ребята, мы знаем об анализе непосредственно в БД c помощью SQL, знаем о Tableau и Talend Open Studio. Это статья для начинающих, а на базовом уровне и небольшом объеме данных Excel с аналогами хватает.
Как Excel портит данные: из классики
Все бы ничего, но Excel, едва открыв CSV-файл, начинает свои лукавые выкрутасы. Он без спроса меняет данные так, что те приходят в негодность. Причем делает это совершенно незаметно. Из-за этого в свое время мы схватили ворох проблем.
Большинство казусов связано с тем, что программа без спроса преобразует строки с набором цифр в числа.
Округляет. Например, в исходной ячейке два телефона хранятся через запятую без пробелов: «5235834,5235835». Что сделает Excel? Лихо превратит номера́ в одно число и округлит до двух цифр после запятой: «5235834,52». Так мы потеряем второй телефон.
Приводит к экспоненциальной форме. Excel заботливо преобразует «123456789012345» в число «1,2E+15». Исходное значение потеряем напрочь.
Проблема актуальна для длинных, символов по пятнадцать, цифровых строк. Например, КЛАДР-кодов (это такой государственный идентификатор адресного объекта: го́рода, у́лицы, до́ма).
Удаляет лидирующие плюсы. Excel считает, что плюс в начале строки с цифрами — совершенно лишний символ. Мол, и так ясно, что число положительное, коль перед ним не стоит минус. Поэтому лидирующий плюс в номере «+74955235834» будет отброшен за ненадобностью — получится «74955235834». (В реальности номер пострадает еще сильнее, но для наглядности обойдусь плюсом).
Потеря плюса критична, например, если данные пойдут в стороннюю систему, а та при импорте жестко проверяет формат.
Разбивает по три цифры. Цифровую строку длиннее трех символов Excel, добрая душа, аккуратно разберет. Например, «8 495 5235834» превратит в «84 955 235 834».
Форматирование важно как минимум для телефонных номеров: пробелы отделяют коды страны и города от остального номера и друг от друга. Excel запросто нарушает правильное членение телефона.
Удаляет лидирующие нули. Строку «00523446» Excel превратит в «523446».
А в ИНН, например, первые две цифры — это код региона. Для Республики Алтай он начинается с нуля — «04». Без нуля смысл номера исказится, а проверку формата ИНН вообще не пройдет.
Меняет даты под локальные настройки. Excel с удовольствием исправит номер дома «1/2» на «01.фев». Потому что Windows подсказал, что в таком виде вам удобнее считывать даты.
Побеждаем порчу данных правильным импортом
Если серьезно, в бедах виноват не Excel целиком, а неочевидный способ импорта данных в программу.
По умолчанию Excel применяет к данным в загруженном CSV-файле тип «General» — общий. Из-за него программа распознает цифровые строки как числа. Такой порядок можно победить, используя встроенный инструмент импорта.
Запускаю встроенный в Excel механизм импорта. В меню это «Data → Get External Data → From Text».
Выбираю CSV-файл с данными, открывается диалог. В диалоге кликаю на тип файла Delimited (с разделителями). Кодировка — та, что в файле, обычно определяется автоматом. Если первая строка файла — шапка, отмечаю «My Data Has Headers».
Перехожу ко второму шагу диалога. Выбираю разделитель полей (обычно это точка с запятой — semicolon). Отключаю «Treat consecutive delimiters as one», а «Text qualifier» выставляю в «». (Text qualifier — это символ начала и конца текста. Если разделитель в CSV — запятая, то text qualifier нужен, чтобы отличать запятые внутри текста от запятых-разделителей.)
На третьем шаге выбираю формат полей, ради него все и затевалось. Для всех столбцов выставляю тип «Text». Кстати, если кликнуть на первую колонку, зажать шифт и кликнуть на последнюю, выделятся сразу все столбцы. Удобно.
Дальше Excel спросит, куда вставлять данные из CSV — можно просто нажать «OK», и данные появятся в открытом листе.
Перед импортом придется создать в Excel новый workbook
Но! Если я планирую добавлять данные в CSV через Excel, придется сделать еще кое-что.
После импорта нужно принудительно привести все-все ячейки на листе к формату «Text». Иначе новые поля приобретут все тот же тип «General».
- Нажимаю два раза Ctrl+A, Excel выбирает все ячейки на листе;
- кликаю правой кнопкой мыши;
- выбираю в контекстном меню «Format Cells»;
- в открывшемся диалоге выбираю слева тип данных «Text».
Чтобы выделить все ячейки, нужно нажать Ctrl+A два раза. Именно два, это не шутка, попробуйте
После этого, если повезет, Excel оставит исходные данные в покое. Но это не самая твердая гарантия, поэтому мы после сохранения обязательно проверяем файл через текстовый просмотрщик.
Альтернатива: Open Office Calc
Для работы с CSV-файлами я использую именно Calc. Он не то чтобы совсем не считает цифровые данные строками, но хотя бы не применяет к ним переформатирование в соответствии с региональными настройками Windows. Да и импорт попроще.
Конечно, понадобится пакет Open Office (OO). При установке он предложит переназначить на себя файлы MS Office. Не рекомендую: хоть OO достаточно функционален, он не до конца понимает хитрое микрософтовское форматирование документов.
А вот назначить OO программой по умолчанию для CSV-файлов — вполне разумно. Сделать это можно после установки пакета.
Итак, запускаем импорт данных из CSV. После двойного клика на файле Open Office показывает диалог.
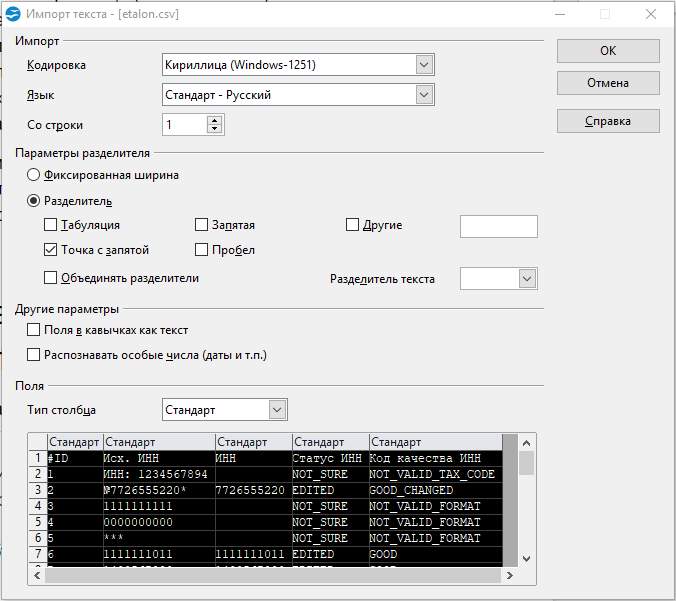
Заметьте, в OO не нужно создавать новый воркбук и принудительно запускать импорт, все само
- Кодировка — как в файле.
- «Разделитель» — точка с запятой. Естественно, если в файле разделителем выступает именно она.
- «Разделитель текста» — пустой (все то же, что в Excel).
- В разделе «Поля» кликаю в левый-верхний квадрат таблицы, подсвечиваются все колонки. Указываю тип «Текст».
Помимо Calc у нас в HFLabs популярен libreOffice, особенно под «Линуксом». И то, и другое для CSV применяют активнее, чем Excel.
Бонус-трек: проблемы при сохранении из Calc в .xlsx
Если сохраняете данные из Calc в экселевский формат .xlsx, имейте в виду — OO порой необъяснимо и масштабно теряет данные.
Белая пустошь, раскинувшаяся посередине, в оригинальном CSV-файле богато заполнена данными
Поэтому после сохранения я еще раз открываю файл и убеждаюсь, что данные на месте.
Если что-то потерялись, лечение — пересохранить из CSV в .xlsx. Или, если установлен Windows, импортнуть из CSV в Excel и сохранить оттуда.
После пересохранения обязательно еще раз проверяю, что все данные на месте и нет лишних пустых строк.
Если интересно работать с данными, посмотрите на наши вакансии. HFLabs почти всегда нужны аналитики, тестировщики, инженеры по внедрению, разработчики. Данными обеспечим так, что мало не покажется 🙂
- Блог компании HFLabs
- Информационная безопасность
- IT-стандарты
- Хранение данных
- Софт
Получение данных из файлов с разделимыми запятыми (CSV)
![]()
Файлы значений, разделенные запятыми, часто называемые CSV-файлом, — это простые текстовые файлы с строками данных, в которых каждое значение разделено запятыми. Эти типы файлов могут содержать большие объемы данных в относительно небольшом размере файла, что делает их идеальным источником данных для Power BI. Вы можете скачать пример CSV-файла.
Если у вас есть CSV-файл, пришло время попасть на сайт Power BI в качестве семантической модели, где можно начать изучение данных, создать некоторые панели мониторинга и поделиться своими аналитическими сведениями с другими пользователями.
Многие организации выводит CSV-файл с обновленными данными каждый день. Чтобы убедиться, что семантическая модель в Power BI синхронизируется с обновленным файлом, убедитесь, что файл сохранен в OneDrive с тем же именем.
Место сохранения файла имеет разницу
Локальный — если вы сохраните CSV-файл на локальном диске на компьютере или другом расположении в организации, вы можете импортировать файл в Power BI. Файл фактически останется на локальном диске, поэтому весь файл не импортируется в Power BI. Что действительно происходит, это новая семантическая модель создается в Power BI, а данные из CSV-файла загружаются в семантику модели.
OneDrive для работы или учебного заведения. Если у вас есть OneDrive для работы или учебного заведения, и вы входите в систему с той же учетной записью, что и для входа в Power BI, этот метод является наиболее эффективным способом сохранения CSV-файла и семантической модели, отчетов и панелей мониторинга в синхронизации Power BI. Так как Power BI и OneDrive находятся в облаке, Power BI подключается к файлу в OneDrive примерно каждый час. Если обнаружены изменения, семантическая модель, отчеты и панели мониторинга автоматически обновляются в Power BI.
OneDrive — персональный — если вы сохраняете файлы в своей учетной записи OneDrive, вы получите множество одинаковых преимуществ, как и в OneDrive для работы или учебного заведения. Самое большое различие заключается в том, что при первом подключении к файлу вам потребуется войти в OneDrive с учетной записью Майкрософт, которая отличается от того, что вы используете для входа в Power BI. При входе в OneDrive с учетной записью Майкрософт обязательно выберите параметр «Сохранить меня вошедшего». Таким образом, Power BI сможет подключаться к файлу примерно каждый час и убедиться, что семантическая модель в Power BI синхронизирована.
SharePoint. Сохранение файлов Power BI Desktop в SharePoint совпадает с сохранением в OneDrive для работы или учебного заведения. Самое большое различие заключается в том, как подключиться к файлу из Power BI. Вы можете указать URL-адрес или подключиться к корневой папке.
Импорт или подключение к CSV-файлу
Максимальный размер файла, который можно импортировать в Power BI, составляет 1 ГБ.
- В рабочей области Power BI выберите +Создать и нажмите кнопку «Отправить файл«.
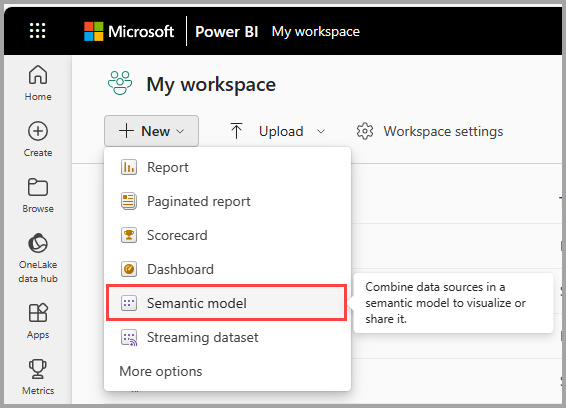
- выберите CSV.
- Перейдите к файлу, который вы хотите отправить, и нажмите кнопку «Импорт«. В главной области Power BI появится новое окно сведений о семантической модели.
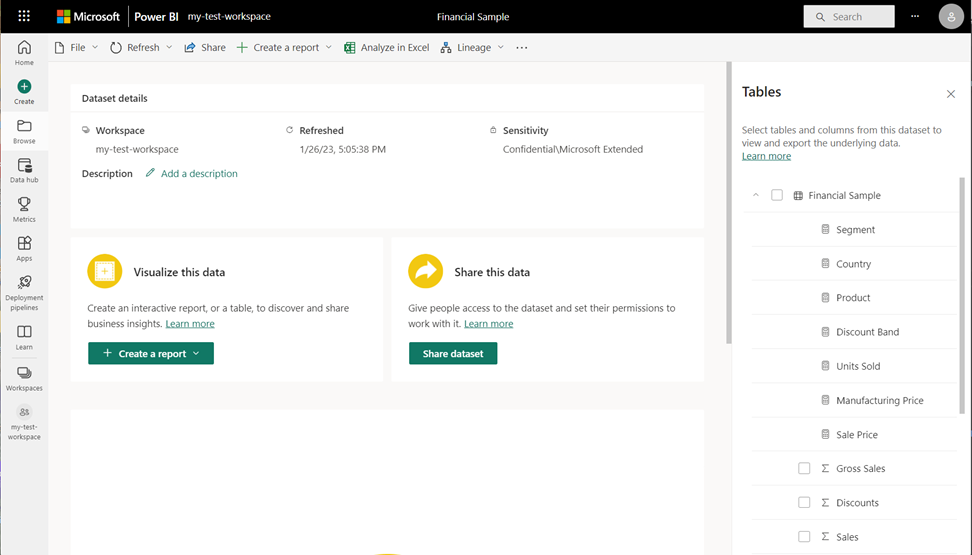
Следующие шаги
Изучите данные. После получения данных из файла в Power BI пришло время изучить. Выберите дополнительные параметры (. ) и выберите параметр в меню.
Запланируйте обновление . Если файл сохраняется на локальном диске, можно запланировать обновление, чтобы семантическая модель и отчеты в Power BI оставались актуальными. Дополнительные сведения см. в статье об обновлении данных в Power BI. Если файл сохраняется в OneDrive, Power BI автоматически синхронизируется с ним примерно каждый час.