Установка Jupyter Notebook на компьютере и ее подключение к Apache Spark в HDInsight
Из этой статьи вы узнаете, как установить Jupyter Notebook с пользовательскими ядрами PySpark (для Python) и Apache Spark (для Scala) с помощью магических команд Spark, а затем подключить эту записную книжку к кластеру HDInsight.
Для установки Jupyter и подключения к Apache Spark в HDInsight необходимо выполнить четыре основных шага.
- Настроить кластер Spark.
- Установить Jupyter Notebook.
- Установите ядра PySpark и Spark с помощью волшебной команды Spark.
- Настройте волшебную команду Spark для доступа к кластеру Spark в HDInsight.
Дополнительные сведения о пользовательских ядрах и магических командах Spark см. в разделе Ядра, доступные для Jupyter Notebook с кластерами Apache Spark Linux в HDInsight.
Предварительные требования
- Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark. Локальная записная книжка подключается к кластеру HDInsight.
- Опыт работы с записными книжками Jupyter с Spark в HDInsight.
Установка Jupyter Notebook на компьютер
Перед установкой Jupyter Notebook необходимо установить Python. Дистрибутив Anaconda установит как Python, так и Jupyter Notebook.
Скачайте установщик Anaconda для своей платформы и запустите программу установки. В мастере установки укажите параметр для добавления Anaconda в переменную PATH. См. также Установка Jupyter с помощью Anaconda.
Установка магических команд Spark
- Введите команду pip install sparkmagic==0.13.1 , чтобы установить магические команды Spark для кластеров HDInsight версии 3.6 и 4.0. См. также документацию по sparkmagic.
- Убедитесь, что мини-приложение ipywidgets установлено правильно. Для этого выполните следующую команду:
jupyter nbextension enable --py --sys-prefix widgetsnbextension Установка ядер PySpark и Spark
- Определите место установки sparkmagic с помощью следующей команды:
pip show sparkmagic | Ядро | Get-Help |
|---|---|
| Spark | jupyter-kernelspec install sparkmagic/kernels/sparkkernel |
| SparkR | jupyter-kernelspec install sparkmagic/kernels/sparkrkernel |
| PySpark | jupyter-kernelspec install sparkmagic/kernels/pysparkkernel |
| PySpark3 | jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel |
jupyter serverextension enable --py sparkmagic Настройка волшебной команды Spark для подключения к кластеру HDInsight Spark
В этом разделе вы настроите подключение магической команды Spark, установленной ранее, к кластеру Apache Spark.
-
Запустите оболочку Python с помощью следующей команды:
python import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit() < "kernel_python_credentials" : < "username": "", "base64_password": "", "url": "https://.azurehdinsight.net/livy" >, "kernel_scala_credentials" : < "username": "", "base64_password": "", "url": "https://.azurehdinsight.net/livy" >, "custom_headers" : < "X-Requested-By": "livy" >, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 > | Значение шаблона | Новое значение |
|---|---|
| Имя для входа в кластер, значение по умолчанию — admin . | |
| Имя кластера | |
| Фактический пароль в кодировке Base64. Сгенерировать пароль в кодировке base64 можно здесь: https://www.url-encode-decode.com/base64-encode-decode/. | |
| «livy_server_heartbeat_timeout_seconds»: 60 | При использовании sparkmagic 0.12.7 (кластеры версии 3.5 и 3.6) не заменяйте. При использовании sparkmagic 0.2.3 (кластеры версии 3.4) замените на «should_heartbeat»: true . |
Полный пример файла можно просмотреть в образце config.json.
Совет Сигналы пульса отправляются, чтобы предотвратить утечку сеансов. При переходе в спящий режим или завершении работы компьютера пульс не отправляется, что приводит к очистке сеанса. Если вы хотите отключить такое поведение для кластеров версии 3.4, то можете настроить для параметра Livy livy.server.interactive.heartbeat.timeout значение 0 с помощью пользовательского интерфейса Ambari. Если для кластеров версии 3.5 не настроить соответствующую конфигурацию, приведенную выше, то сеанс не будет удален.
jupyter notebook 
Убедитесь, что вы можете использовать магическую команду Spark, доступную вместе с ядрами. Выполните следующие шаги. а. Создайте новую записную книжку. В правом верхнем углу щелкните Создать. Должны отобразиться ядро по умолчанию Python 2 или Python 3 и установленные ядра. Фактические значения могут отличаться в зависимости от выбранных вариантов установки. Выберите PySpark.
Важно! Щелкнув Создать, проверьте оболочку на наличие ошибок. Если отображается сообщение об ошибке TypeError: __init__() got an unexpected keyword argument ‘io_loop’ , возможно, возникла известная проблема с определенными версиями Tornado. Если это так, завершите работу ядра, а затем перейдите на использование более ранней версии установки Tornado с помощью следующей команды: pip install tornado==4.5.3 .
b. Запустите следующий фрагмент кода.
%%sql SELECT * FROM hivesampletable LIMIT 5 Зачем устанавливать Jupyter на моем компьютере?
Причины, по которым требуется установить на компьютер Jupyter и подключить к кластеру Apache Spark в HDInsight.
- Предоставляет возможность создавать записные книжки локально, тестировать приложение в работающем кластере, а затем отправлять записные книжки в кластер. Для отправки записных книжек в кластер можно отправить их с помощью Jupyter Notebook, которая запущена на кластере, или сохранить их в папке /HdiNotebooks в учетной записи хранения, связанной с кластером. Дополнительные сведения о хранении записных книжек в кластере см. в разделе Где хранятся записные книжки Jupyter.
- С помощью локально доступных записных книжек вы сможете подключиться к различным кластерам Spark в зависимости от потребностей вашего приложения.
- Можно использовать GitHub для реализации системы управления версиями, чтобы контролировать версии записных книжек. Вы также можете создать среду совместной работы, в которой несколько пользователей будут работать с одной записной книжкой.
- Вы можете работать с записными книжками локально даже без кластера. Кластер нужен только для тестирования записных книжек, но не обязателен для ручного управления записными книжками или средой разработки.
- Возможно, вам будет проще настроить локальную среду разработки, чем настраивать установку Jupyter в кластере. Вы можете спокойно пользоваться любым программным обеспечением, установленным локально, не настраивая удаленные кластеры.
Если Jupyter установлен на локальном компьютере, несколько пользователей могут одновременно запустить одну и ту же записную книжку в одном кластере Spark. В такой ситуации создаются несколько сеансов Livy. Если вы столкнетесь с проблемами и начнете их отладку, вам будет сложно определить, какой сеанс Livy какому пользователю принадлежит.
Дальнейшие действия
- Обзор: Spark в Azure HDInsight
- Ядра для Jupyter Notebook в Apache Spark
- Использование внешних пакетов с Jupyter Notebook в Apache Spark
Действия с библиотеками в образах Jupyter Server
В каждом образе Jupyter Server и базовом образе для задач обучения есть предустановленный набор библиотек (см. Список образов для Jupyter Server , Библиотеки в базовых образах для деплоев ).
В инструкции описано, как узнать, какие библиотеки установлены, как установить и обновить библиотеки.
Получение списка библиотек, установленных в образе Jupyter Server
Чтобы увидеть список библиотек, установленных в образе Jupyter Server:
- Создайте или подключитесь к уже существующему Jupyter Notebook.
- В ячейке Jupyter Notebook выполните следующую команду:
pip list
Получение списка библиотек, установленных в базовом образе
Чтобы увидеть список библиотек, установленных в базовых образах, выполните последовательность действий, как описано в разделе Актуализация списка библиотек в базовых образах .
Установка дополнительных библиотек в Jupyter Server
Для установки дополнительных библиотек выполните команду в ячейке ноутбука:
!pip install
Где package_name — наименование библиотеки, которую предполагается установить, а version — версия данной библиотеки.
После установки библиотеки выполните следующую команду для проверки:
!pip list | grep
В Jupyter Server есть каталоги, в которых хранятся служебные и пользовательские файлы:
- /home/user — каталог, уникальный для каждого Jupyter Server.
- /home/jovyan — каталог, общий для всех Jupyter Server, созданных в рамках одного воркспейса.
Если устанавливать библиотеки с помощью команды pip install , то зависимости будут установлены в каталог /home/jovyan/.img-xxxxx .
При постановке Jupyter Server на паузу этот каталог остается, при остановке (удалении) каталог удаляется. При удалении Jupyter Server все библиотеки, которые установлены с помощью команды pip install , удаляются вместе с каталогом /home/user .
Для использования требуемого набора библиотек можно создать и использовать кастомный Docker-образ. Подробнее см. Способ 1. Обучение из Jupyter Server с GPU .
Jupyter Server называется test-img-dir , в нем командой pip install glances установили библиотеку. Установленная библиотека с требуемыми зависимостями будет находиться в каталоге /home/jovyan/.imgenv-test-img-dir-0/lib/python3.7/site-packages .
Обратите внимание на то, что в образ Jupyter Server jupyter-cuda10.1-tf2.3.0-gpu можно дополнительно установить библиотеку DeepSpeed. Для этого:
- Создайте или подключитесь к уже существующему Jupyter Notebook.
- Запустите командную строку ( New → Terminal ).
- Выполните команду ниже. Библиотека установится в соответствующий каталог.
cd /tmp && git clone https://github.com/microsoft/DeepSpeed.git && cd DeepSpeed && \ pip install cpufeature && \ DS_BUILD_SPARSE_ATTN=1 DS_BUILD_CPU_ADAM=1 /tmp/DeepSpeed/install.sh
Установка дополнительных библиотек в базовый образ
Пользователи могут установить дополнительные библиотеки в базовые образы. Для сборки таких кастомных образов используются средства функции client_lib . Подробнее см. Способ 1. Обучение из Jupyter Server с GPU .
Обновление версий библиотек в Jupyter Server
Чтобы обновить версию установленной библиотеки, выполните команду:
pip install --upgrade
Ранее установленная версия библиотеки обновится.
Пример переустановки версии torch приведен ниже.
pip install --no-cache-dir torch===1.5.0+cu101 torchvision==0.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
Не рекомендуется менять версию базовых пакетов — Horovod, TensorFlow, Apex, MXNet, TensorBoard, KServe, PyTorch.
Обновление версий библиотек в базовых образах
Для обновления версий библиотек, установленных в базовом образе, внесите модули и их версии в файл requirements.txt и соберите кастомный образ с использованием этого файла. Подробнее см. Способ 1. Обучение из Jupyter Server с GPU .
Актуализация списка библиотек в базовых образах
Список базовых образов и версий предустановленных библиотек в данных образах может периодически обновляться (См. Образы для Jupyter Server ). Пользователи могут получить перечень актуальных версий библиотек. Для этого необходимо выполнить последовательность действий, описанную ниже.
- Создайте или подключитесь к уже существующему Jupyter Notebook.
- Выберите подключение к Jupyter Notebook или JupyterLab. Рабочий каталог, из которого будут запускаться файлы, — /home/jovyan/ .
- Создайте в рабочем каталоге файл test.py следующего содержания:
import subprocess if __name__ == '__main__': cmd = 'pip freeze' subprocess.run(cmd, shell=True)
import client_lib
job = client_lib.Job(base_image='your base image', script = '/home/jovyan/test.py', n_workers=1, instance_type='your isntance_type', processes_per_worker=1 )
Для получения значения instance_type воспользуйтесь инструкцией .
job.submit()
import time while True: job.logs() time.sleep(5)
- Создать Jupyter Server
- Образы для Jupyter Server
- Образы для деплоев
- Образы для задач обучения
Python. Урок 6. Работа с IPython и Jupyter Notebook


IPython представляет собой мощный инструмент для работы с языком Python. Базовые компоненты IPython – это интерактивная оболочка для с широким набором возможностей и ядро для Jupyter. Jupyter notebook является графической веб-оболочкой для IPython, которая расширяет идею консольного подхода к интерактивным вычислениям.
Основные отличительные особенности данной платформы – это комплексная интроспекция объектов, сохранение истории ввода на протяжении всех сеансов, кэширование выходных результатов, расширяемая система “магических” команд, логирование сессии, дополнительный командный синтаксис, подсветка кода, доступ к системной оболочке, стыковка с pdb отладчиком и Python профайлером.
IPython позволяет подключаться множеству клиентов к одному вычислительному ядру и, благодаря своей архитектуре, может работать в параллельном кластере.
В Jupyter notebook вы можете разрабатывать, документировать и выполнять приложения на языке Python, он состоит из двух компонентов: веб-приложение, запускаемое в браузере, и ноутбуки – файлы, в которых можно работать с исходным кодом программы, запускать его, вводить и выводить данные и т.п.
Веб приложение позволяет:
- редактировать Python код в браузере, с подсветкой синтаксиса, автоотступами и автодополнением;
- запускать код в браузере;
- отображать результаты вычислений с медиа представлением (схемы, графики);
- работать с языком разметки Markdown и LaTeX.
Ноутбуки – это файлы, в которых сохраняются исходный код, входные и выходные данные, полученные в рамках сессии. Фактически, он является записью вашей работы, но при этом позволяет заново выполнить код, присутствующий на нем. Ноутбуки можно экспортировать в форматы PDF, HTML.
Установка и запуск
Jupyter Notebook входит в состав Anaconda. Описание процесса установки можно найти в первом уроке. Для запуска Jupyter Notebook перейдите в папку Scripts (она находится внутри каталога, в котором установлена Anaconda) и в командной строке наберите:
> ipython notebook
В результате будет запущена оболочка в браузере.

Примеры работы
Будем следовать правилу: лучше один раз увидеть… Рассмотрим несколько примеров, выполнив которые, вы сразу поймете принцип работы с Jupyter notebook.
Запустите Jupyter notebook и создайте папку для наших примеров, для этого нажмите на New в правой части экрана и выберите в выпадающем списке Folder.

По умолчанию папке присваивается имя “Untitled folder”, переименуем ее в “notebooks”: поставьте галочку напротив имени папки и нажмите на кнопку “Rename”.

Зайдите в эту папку и создайте в ней ноутбук, воспользовавшись той же кнопкой New, только на этот раз нужно выбрать “Python [Root]”.

В результате будет создан ноутбук.

.
Код на языке Python или текст в нотации Markdown нужно вводить в ячейки:
![]()
Если это код Python, то на панели инструментов нужно выставить свойство “Code”.

Если это Markdown текст – выставить “Markdown”.

Для начал решим простую арифметическую задачу: выставите свойство “Code”, введите в ячейке “2 + 3” без кавычек и нажмите Ctrl+Enter или Shift+Enter, в первом случае введенный вами код будет выполнен интерпретатором Python, во втором – будет выполнен код и создана новая ячейка, которая расположится уровнем ниже так, как показано на рисунке.

Если у вас получилось это сделать, выполните еще несколько примеров.

Основные элементы интерфейса Jupyter notebook
У каждого ноутбука есть имя, оно отображается в верхней части экрана. Для изменения имени нажмите на его текущее имя и введите новое.

Из элементов интерфейса можно выделить, панель меню:
![]()
![]()
и рабочее поле с ячейками:

Ноутбук может находиться в одном из двух режимов – это режим правки (Edit mode) и командный режим (Command mode). Текущий режим отображается на панели меню в правой части, в режиме правки появляется изображение карандаша, отсутствие этой иконки значит, что ноутбук находится в командном режиме.

Для открытия справки по сочетаниям клавиш нажмите “Help->Keyboard Shortcuts”

В самой правой части панели меню находится индикатор загруженности ядра Python. Если ядро находится в режиме ожидания, то индикатор представляет собой окружность.

Если оно выполняет какую-то задачу, то изображение измениться на закрашенный круг.
Запуск и прерывание выполнения кода
Если ваша программа зависла, то можно прервать ее выполнение выбрав на панели меню пункт Kernel -> Interrupt.
Для добавления новой ячейки используйте Insert->Insert Cell Above и Insert->Insert Cell Below.
Для запуска ячейки используете команды из меню Cell, либо следующие сочетания клавиш:
Ctrl+Enter – выполнить содержимое ячейки.
Shift+Enter – выполнить содержимое ячейки и перейти на ячейку ниже.
Alt+Enter – выполнить содержимое ячейки и вставить новую ячейку ниже.
Как сделать ноутбук доступным для других людей?
Существует несколько способов поделиться своим ноутбуком с другими людьми, причем так, чтобы им было удобно с ним работать:
- передать непосредственно файл ноутбука, имеющий расширение “.ipynb”, при этом открыть его можно только с помощью Jupyter Notebook;
- сконвертировать ноутбук в html;
- использовать https://gist.github.com/ ;
- использовать http://nbviewer.jupyter.org/.
Вывод изображений в ноутбуке
Печать изображений может пригодиться в том случае, если вы используете библиотеку matplotlib для построения графиков. По умолчанию, графики не выводятся в рабочее поле ноутбука. Для того, чтобы графики отображались, необходимо ввести и выполнить следующую команду:
%matplotlib inline
Пример вывода графика представлен на рисунке ниже.

Магия
Важной частью функционала Jupyter Notebook является поддержка магии. Под магией в IPython понимаются дополнительные команды, выполняемые в рамках оболочки, которые облегчают процесс разработки и расширяют ваши возможности. Список доступных магических команд можно получить с помощью команды
%lsmagic

Для работы с переменными окружения используется команда %env.

Запуск Python кода из “.py” файлов, а также из других ноутбуков – файлов с расширением “.ipynb”, осуществляется с помощью команды %run.

Для измерения времени работы кода используйте %%time и %timeit.
%%time позволяет получить информацию о времени работы кода в рамках одной ячейки.

%timeit запускает переданный ей код 100000 раз (по умолчанию) и выводит информацию среднем значении трех наиболее быстрых прогонах.

Информацию по остальным магическим командам можете найти здесь:
Интересные примеры ноутбуков, в которых довольно полно раскрыты возможности Jupyter Notebook можно найти в ресурсах, перечисленных ниже.
P.S.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. На нашем сайте вы можете найти вводные уроки по этой теме. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
Раздел: Python Уроки по Python Метки: Python, Уроки Python
Python. Урок 6. Работа с IPython и Jupyter Notebook : 4 комментария
- Уведомление: Adopting IPython & Jupyter For Selenium Testing: Plan, Write, Validate Tests in Python | Shakuro
- Михаил Филиппов 17.01.2021 ” это интерактивная оболочка для с широким набором возможностей ”
после ДЛЯ пропало слово
- Ксения 30.10.2023 Сначала прописать activate baze, затем jupyter notebook. Также можно вызвать Anaconda Navigator и из него Jupiter Notebook
Где хранятся модули в Python?

Система модулей даёт возможность логически организовать код на Python. Кроме того, группирование в модули значительно облегчает сам процесс написания кода, плюс делает его более понятным. В этой статье поговорим, что такое модуль в Python, где он хранится и как обрабатывается.
Модуль в Python — это файл, в котором содержится код на Python. Любой модуль в Python может включать в себя переменные, объявления функций и классов. Вдобавок ко всемe, в модуле может содержаться исполняемый код.
Команда import в Python
Позволяет использовать любой файл Python в качестве модуля в другом файле. Синтаксис прост:
import module_1[, module_2[. module_N]Как только Python-интерпретатор встречает команду import, он выполняет импорт модуля, если он есть в пути поиска Python. Что касается пути поиска Python, то речь идёт о списке директорий, в которых интерпретатор выполняет поиск перед загрузкой модуля. Посмотрите на пример кода при использовании модуля math:
import math # Используем функцию sqrt из модуля math print (math.sqrt(9)) # Печатаем значение переменной pi, определенной в math print (math.pi)Помните, что модуль загружается только один раз, вне зависимости от того, какое количество раз вы его импортировали. Таким образом исключается цикличное выполнение содержимого модуля.
Команда from . import
Команда from . import даёт возможность выполнить импорт не всего модуля целиком, а лишь конкретного его содержимого:
# Импортируем из модуля math функцию sqrt from math import sqrt # Выводим результат выполнения функции sqrt. # Нам больше незачем указывать имя модуля print (sqrt(144)) # Но мы уже не можем получить из модуля то, что не импортировали print (pi) # Выдаст ошибкуОбратите внимание, что выражение from . import не импортирует модуль полностью, а лишь предоставляет доступ к объектам, указанным нами.
Команда from . import *
Также в Python мы можем импортировать из модуля переменные, классы и функции за один раз. Чтобы это выполнить, применяется конструкция from . import *:
from math import * # Теперь у нас есть доступ ко всем функция и переменным, определенным в модуле math print (sqrt(121)) print (pi) print (e)Использовать данную конструкцию нужно осторожно, ведь при импорте нескольких модулей можно запутаться в собственном коде.
Так где хранятся модули в Python?
При импорте модуля, интерпретатор Python пытается найти модуль в следующих местах: 1. Директория, где находится файл, в котором вызывается команда импорта. 2. Директория, определённая в консольной переменной PYTHONPATH (если модуль не найден с первого раза). 3. Путь, заданный по умолчанию (если модуль не найден в предыдущих двух случаях).
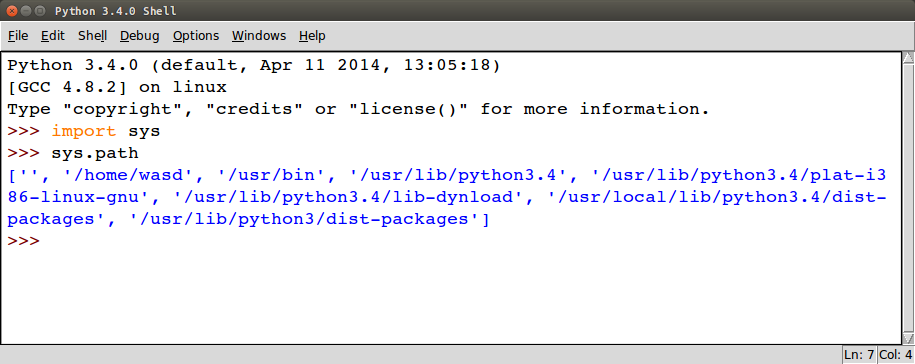
Что касается пути поиска, то он сохраняется в переменной path в системном модуле sys. А переменная sys.path включает в себя все 3 вышеописанных места поиска.
Получаем список всех модулей Python
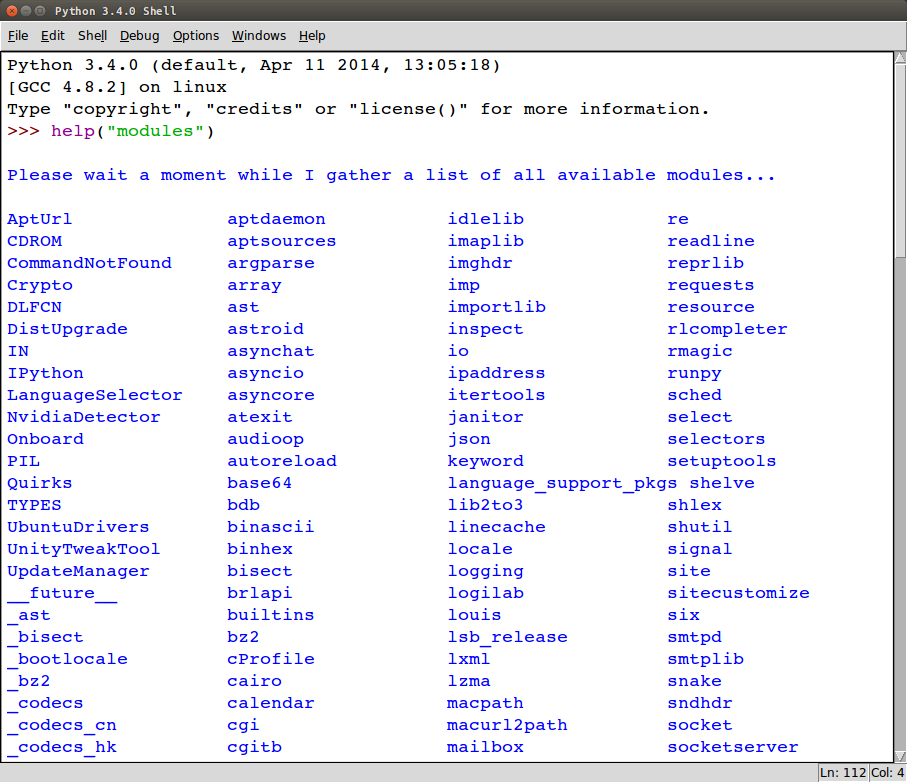
Чтобы получить полный список модулей, установленных на ПК, используют команду help("modules") .
Создаём свой модуль в Python
Для создания собственного модуля в Python нужно сохранить ваш скрипт с расширением .py. После этого он станет доступным в любом другом файле. Давайте создадим 2 файла: module_1.py и module_2.py, а потом сохраним их в одной директории. В первом файле запишем:
def hello(): print ("Hello from module_1")А во втором вызовем функцию:
from module_1 import hello hello()После выполнения кода 2-го файла получим:
Hello from module_1Функция dir() в Python
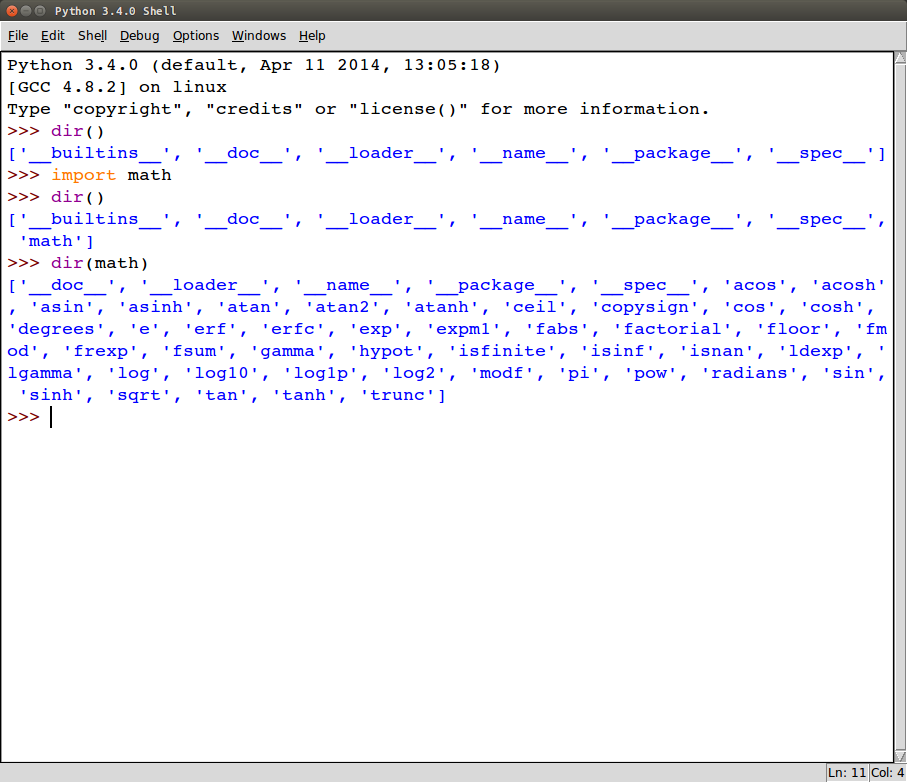
Возвратит отсортированный список строк с содержанием всех имён, определенных в модуле.
# на данный момент нам доступны лишь встроенные функции dir() # импортируем модуль math import math # теперь модуль math в списке доступных имен dir() # получим имена, определенные в модуле math dir(math)
Пакеты модулей в Python
Несколько файлов-модулей с кодом можно объединить в пакеты модулей. Пакет модулей — это директория, включающая в себя несколько отдельных файлов-скриптов.
Представьте, что у нас следующая структура:
|_ my_file.py |_ my_package |_ __init__.py |_ inside_file.pyВ файле inside_file.py определена некоторая функция foo. В итоге, дабы получить доступ к этой функции, в файле my_file нужно выполнить:
from my_package.inside_file import fooТакже нужно обратить внимание на то, есть ли внутри директории my_package файл init.py. Это может быть и пустой файл, сообщающий Python, что директория является пакетом модулей. В Python 3 включать файл init.py в пакет модулей уже не обязательно, но мы рекомендуем всё же делать это, чтобы обеспечить обратную совместимость.