Создаём свою БД на PostgreSQL из CSV

Kaggle — — платформа созданная для проведение конкурсов по исследованию данных. Организаторы выкладывают Datasets , описывают задачи , метрики по которым будут выявляться победители конкурса , призы и время проведения. Каждый желающий может выставить свою работа по этим данных , красиво описать её , показать свои умения и надеяться на победу.
Мы будем использовать Used Cars Dataset
Также мы можем посмотреть Code других участников соревнования
- подчерпнуть оттуда интересную информацию
- найти нестандартные подходы к обработке данных
- На примере других работа , научиться чему-то новому
- и даже наткнуться на
боже зачем это тут ?интересную работу по »Ускорение рабочего процесса Pandas с Modin»
Найти друзейЗаставить других сделать свою работу- Узнать ответ на интересующий тебя вопрос(есть шанс)
Перейдём к делу, Pgadmin4

pgAdmin — это платформа с открытым исходным кодом для администрирования и разработки на PostgreSQL и связанных с ней систем управления базами данных.
pgAdmin будет предложен в установке PostgreSQL, я пользуюсь 14.3. Багов и проблем не боюсь , беру самую новую версию сразу видно профессионал. Если боитесь устанавливать приложение без ведения за ручку , вам поможет интернет()_(). Уже 1000 раз было рассказывать как это делать и что за чему , так что не буду тратить наше драгоценное.
Перейдём к делу 2, Python

Python — — высокоуровневый язык программирования. и нам нужна библиотека pandas
Перейдём к делу 3, Pycharm

Pycharm — — среда разработки(IDE) созданная специально для языка программирования Python.
- Предоставляет средства для анализа кода
- графический отладчик
- инструменты для отладки юнит-тестов
- интуитивно понятный интерфейс
- очень много полезных функций для продвинутых пользователей
Начнём кодить(0)_(з)
экспорт данных + получение основной информации
для начала открываем Pycharm, создаём там новый проект и в терминале инсталлируем библиотеку pаndas Открываем терминал и пишем там pip install pandas, нажимаем enter и ждём установки.
pip install pandasДалее нам надо открыть для чтения наш файл —
import pandas as pd # загружаем наш csv car = pd.read_csv(r'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv') # просмотр первыйх 5 строк print(car.head(5)) 
видим что из-за 26 столбцов, Pycharm не подгружает всё таблицу( в дальнейшем исправим)
# Cведения о датафрейме, выходит общая информация о нём вроде заголовка, количества значений, типов данных столбцов. print(car.info())
Получаем основные данные из таблицы.
- Название всех столбцов
- Количество значений в них
- Типы данных
# загружаем нашу csv , смотрим тольна на первые 100 строк ибо долго грузиться полный файл ) car = pd.read_csv(r'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv',nrows=100) # просмотр всей таблици без ограничений колличество знаков , на строку) print(car.to_csv(None))
Получаем гигантский DF который я не могу передать как картинку , так что переходим сразу обработке этих данных
Очистка данных
Убирает лишние столбцы
Нам точно не нужны url ссылки, и пустая строка country , так же нам не надо описание автомобиля на 1000+ символов(description) Так что пишемс простой код
import pandas as pd # загружаем нашу csv car = pd.read_csv(r'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv') # удлаляем столбци с которыми не будем работать car.drop(['description', 'county', 'url', 'region_url', 'image_url', 'posting_date'], axis=1, inplace=True)drop удаления столбцов , Axis: указывает, что столбцы или строки должны быть удалены, inplace = True, он возвращает Data Frame с удаленными столбцами или None
После этого сохраняем наш изменённый df в новый файл , что бы в дальнейшем работать только с нужными данными
# сохраняем обработанный df в csv файл car.to_csv('car_info.csv')Убираем выбросы
Выбросы — — это данные, которые существенно отличаются от других наблюдений. Они могут соответствовать реальным отклонениям, но могут быть и просто ошибками
Нас интересуют выбросы в колонке price, согласитесь если цена на машину будет 5 000 000 000 долларов это будет сильно менять среднее значение цены и мешать нашим вычислениям
Находим выбросы
Узнаем самые часто встречаемые цены с помощью value_counts И_И узнаем статистику по цене в нашем df с помощью describe
print(car['price'].value_counts().iloc[:5]) print(car.price.describe())
слева видим что у нас есть 32к значений = 0, которые стоят обрезать , и множество значений цены = около 3к
справа у нас показатели зашкаливают и выдают огромные цифры. ЧТО ТО ТУТ НЕ ТАК.
А теперь сделаем грубую и ужасную профессиональную вырезку. Я называю её «и так сойдёт»(объясняю, мы как бы не готовим данные для отчётов и т.д , а просто убираем самый явный бред)
Импортируем 2 крутые штуки seaborn
pip install seaborn pip install matplotlibТеперь в шапку нашего кода добавляем
import matplotlib.pyplot as plt import seaborn as snsСтроем простецкий графии
plt.figure(figsize=(5,8)) sns.boxplot(y='price', data=car,showfliers=True) plt.show()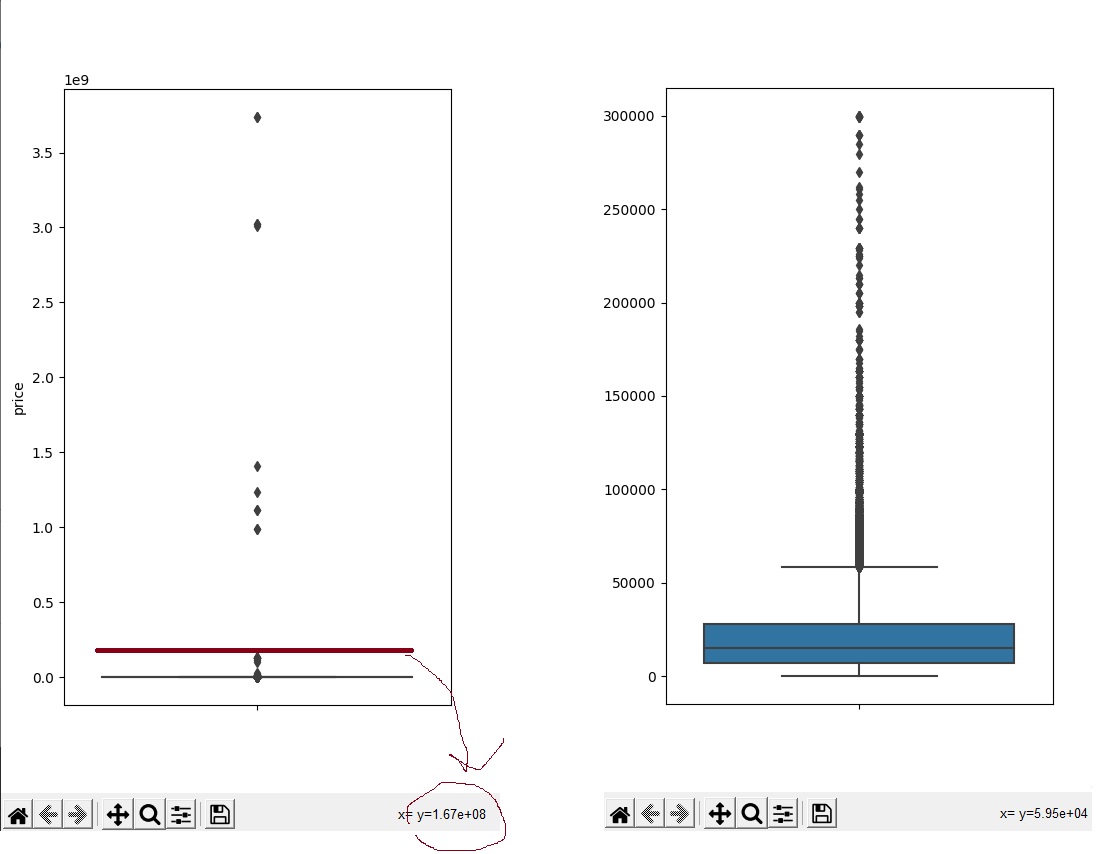
Тут мы смотря на значения Y будем постепенно обрезать наши выбросы , пока они не станут чуть-чуть адекватными( код ниже)
Убираем выбросы
# price > 300000 если труе обрезаем ( а эту цифру берём из значение Y с графика выше) car.drop(car[car.price > 300000].index, inplace = True) # + убираем все лишнии значения car.drop(car[car.price == 0].index, inplace = True)да это всё можно делать с помощью IQR (но это совершенно другая история)
И с помощью value_counts, describe проверяем похоже ли это на правду
Сохраняем то что сделали
# сохраняем обработанный df в csv файл без заголовка и интекса , для экспорта в pgadmin car.to_csv('car_info.csv', index=False)Переноcим данные в СУБД
Создаём пустую бд под экспорт
Осталось дело за малым, открываем pgAdmin4(и подключаемся к серверу)

Далее нам нужно, создать базу данных

Выбираем нашу базу данных и открываем запросник

Вводим туда простейший код
CREATE TABLE car ( car_id int8, region text, price int8, year float4, manufacture text, model text, condition_car text, cylinders text, fuel text, odometer float4, tittle_status text, transmision text, VIN text, drive text, size text, type text, paint_color text, state text, lat float4, long float4 )дааааааа — можно использовать CHARACTER VARYING , int4 , date . Но мы сейчас не про экономию места на диске
Далее нам надо импортировать наши данные в таблицу
Занимаемся экспортом данных
Находим и открываем sql Shell (psql) — терминальный интерфейс для PostgreSQL

просто нажимаем на enter везде кроме, Database(название вашей базы данных) и Пароль пользователя postgres. И у нас начинается подключение
Далее вводим команду
\COPY car FROM 'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv' DELIMITER ',' CSV HEADER;и бежим проверять в pgAdmin всё ли сработало
SELECT * FROM carЕсли увидели таблицу значит вы молодец
PostgreSQL
Одной из наиболее популярных реляционных систем баз данных является PostgreSQL. Рассмотрим, как работать с базами данных PostgreSQL в приложении на языке Python.
Перед началом работы естественно должна быть установлена сама PostgreSQL. Про установку PostgreSQL можно прочитать в соответствующей статье Установка сервера PostgreSQL.
Стандартные библиотеки Python не предоставляют встроенного функционала для работы с PostgreSQL, однако есть большое количество сторонних библиотек. Наиболее популярной из них является Psycopg 2 (официальный сайт Psycopg). Данная библиотека реализована на языке C, благодаря чему обладает сравнительно большой производительностью.
Установка psycopg
Для установки выполним в терминале следующую команду:
pip install psycopg2
После этого мы можем импортировать библиотеку в программе на Python:
import psycopg2
Подключение к серверу PostgreSQL
Для подключения к серверу PostgreSQL применяется функция connect() . Она принимает настройки подключения:
psycopg2.connect(dbname="db_name", host="db_host", user="db_user", password="db_pass", port="db_port")
Функция принимает следующие параметры:
- dbname : имя базы данных
- user : имя пользователя
- password : пароль пользователя
- host : хост/адрес сервера
- port : порт (если не указано, то используется порт по умолчанию — 5432)
При удачном подключении функция connect создает новую сессию базы данных и возвращает объект connection
Класс connection предоставляет ряд методов для работы с подключением к БД:
- close() : закрывает подключение
- cursor() : возвращает объект cursor для осуществления запросов к бд
- commit() : поддверждает транзакцию
- rollback() : откатывает транзакцию
Например, покдлючимся к стандартной базе данных «postgres» на локальном сервере PostgreSQL:
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1", port="5432") print("Подключение установлено") conn.close()
В данном случае подключение идет для встроенного пользователя по умолчанию «postgres».
Курсор и операции с данными
Метод cursor() объекта connection возвращает курсор — объект cursor , через который можно отправлять запросы к базе данных. Для этого класс cursor предоставляет ряд методов:
- execute(query, vars=None) : выполняет одну SQL-инструкцию. Через второй параметр в код SQL можно передать набор параметров в виде списка или словаря
- executemany(query, vars_list) : выполняет параметризованное SQL-инструкцию. Через второй параметр принимает наборы значений, которые передаются в выполняемый код SQL.
- callproc(procname[, parameters]) : выполняет хранимую функцию. Через второй параметр можно передать набор параметров в виде списка или словаря
- mogrify(operation[, parameters]) : возвращает код запроса SQL после привязки параметров
- fetchone() : возвращает следующую строку из полученного из БД набора строк в виде кортежа. Если строк в наборе нет, то возвращает None
- fetchmany([size=cursor.arraysize]) : возвращает набор строк в виде списка. количество возвращаемых строк передается через параметр. Если больше строк нет в наборе, то возвращается пустой список.
- fetchall() : возвращает все (оставшиеся) строки в виде списка. При отсутствии строк возвращается пустой список.
- scroll(value[, mode=’relative’]) : перемещает курсор в наборе на позицию value в соответствии с режимом mode.
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() cursor.close() # закрываем курсор conn.close() # закрываем подключение
Закрытие подключения и курсора
Стоит отметить, что оба объекта — connection и cursor могут использоваться как менеджеры контекста. То есть с помощью выражения with определить контекста. Однако если объект cursor по завершению закрывается, то объект connection НЕ закрывается:
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1", port="5432") with conn: with conn.cursor() as cursor: print("Подключение установлено") print(cursor.closed) # True - курсор закрыт # cursor.close() # нет смысла - объект cursor уже закрыт conn.close() # объект conn не закрыт, надо закрывать
Модель выполнения запросов
Перед выполнением первой команды SQL автоматически создается транзакция, в процессе которой можно выполнять различные выражения SQL с помощью методов execute/executemany курсора, но для подтверждения их выполнения необходимо вызывать метод commit() объекта connection. Условно это может выглядеть так:
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() cursor.execute(sql1) conn.commit() # реальное выполнение команд sql1 cursor.close() conn.close()
Здесь реальное выполнение условной команды sql1 производится только при выполнении метода conn.commit() . Если же надо, чтобы выражения sql автоматически выполнялись при каждом вызове метода cursor.execute() , то можно установить автокоммит с помощью свойства connection.autocommit :
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1") conn.autocommit = True # устанавливаем актокоммит cursor = conn.cursor() cursor.execute(sql1) # непосредственное выполнение команды sql1 cursor.close() conn.close()
Работа с PostgreSQL в Python

17 Ноя. 2018 , Python, 261940 просмотров, How to Work with PostgreSQL in Python
PostgreSQL, пожалуй, это самая продвинутая реляционная база данных в мире Open Source Software. По своим функциональным возможностям она не уступает коммерческой БД Oracle и на голову выше собрата MySQL.
Если вы создаёте на Python веб-приложения, то вам не избежать работы с БД. В Python самой популярной библиотекой для работы с PostgreSQL является psycopg2. Эта библиотека написана на Си на основе libpq.
Установка
Тут всё просто, выполняем команду:
pip install psycopg2Для тех, кто не хочет ставить пакет прямо в системный python, советую использовать pyenv для отдельного окружения. В Unix системах установка psycopg2 потребует наличия вспомогательных библиотек (libpq, libssl) и компилятора. Чтобы избежать сборки, используйте готовый билд:
pip install psycopg2-binary Но для production среды разработчики библиотеки рекомендуют собирать библиотеку из исходников.
Начало работы
Для выполнения запроса к базе, необходимо с ней соединиться и получить курсор:
import psycopg2 conn = psycopg2.connect(dbname='database', user='db_user', password='mypassword', host='localhost') cursor = conn.cursor() Через курсор происходит дальнейшее общение в базой.
cursor.execute('SELECT * FROM airport LIMIT 10') records = cursor.fetchall() . cursor.close() conn.close() После выполнения запроса, получить результат можно несколькими способами:
- cursor.fetchone() — возвращает 1 строку
- cursor.fetchall() — возвращает список всех строк
- cursor.fetchmany(size=5) — возвращает заданное количество строк
Также курсор является итерируемым объектом, поэтому можно так:
for row in cursor: print(row) Хорошей практикой при работе с БД является закрытие курсора и соединения. Чтобы не делать это самому, можно воспользоваться контекстным менеджером:
from contextlib import closing with closing(psycopg2.connect(. )) as conn: with conn.cursor() as cursor: cursor.execute('SELECT * FROM airport LIMIT 5') for row in cursor: print(row)
По умолчанию результат приходит в виде кортежа. Кортеж неудобен тем, что доступ происходит по индексу (изменить это можно, если использовать NamedTupleCursor ). Если хотите работать со словарём, то при вызове .cursor передайте аргумент cursor_factory :
from psycopg2.extras import DictCursor with psycopg2.connect(. ) as conn: with conn.cursor(cursor_factory=DictCursor) as cursor: . Формирование запросов
Зачастую в БД выполняются запросы, сформированные динамически. Psycopg2 прекрасно справляется с этой работой, а также берёт на себя ответственность за безопасную обработку строк во избежание атак типа SQL Injection:
cursor.execute('SELECT * FROM airport WHERE city_code = %s', ('ALA', )) for row in cursor: print(row) Метод execute вторым аргументом принимает коллекцию (кортеж, список и т.д.) или словарь. При формировании запроса необходимо помнить, что:
- Плейсхолдеры в строке запроса должны быть %s , даже если тип передаваемого значения отличается от строки, всю работу берёт на себя psycopg2.
- Не нужно обрамлять строки в одинарные кавычки.
- Если в запросе присутствует знак %, то его необходимо писать как %%.
Именованные аргументы можно писать так:
>>> cursor.execute('SELECT * FROM engine_airport WHERE city_code = %(city_code)s', ) . Модуль psycopg2.sql
Начиная с версии 2.7, в psycopg2 появился модуль sql. Его цель — упростить и обезопасить работу при формировании динамических запросов. Например, метод execute курсора не позволяет динамически подставить название таблицы.
>>> cursor.execute('SELECT * FROM %s WHERE city_code = %s', ('airport', 'ALA')) psycopg2.ProgrammingError: ОШИБКА: ошибка синтаксиса (примерное положение: "'airport'") LINE 1: SELECT * FROM 'airport' WHERE city_code = 'ALA' Это можно обойти, если сформировать запрос без участия psycopg2, но есть высокая вероятность оставить брешь (привет, SQL Injection!). Чтобы обезопасить строку, воспользуйтесь функцией psycopg2.extensions.quote_ident , но и про неё легко забыть.
from psycopg2 import sql . >>> with conn.cursor() as cursor: columns = ('country_name_ru', 'airport_name_ru', 'city_code') stmt = sql.SQL('SELECT <> FROM <> LIMIT 5').format( sql.SQL(',').join(map(sql.Identifier, columns)), sql.Identifier('airport') ) cursor.execute(stmt) for row in cursor: print(row) ('Французская Полинезия', 'Матайва', 'MVT') ('Индонезия', 'Матак', 'MWK') ('Сенегал', 'Матам', 'MAX') ('Новая Зеландия', 'Матамата', 'MTA') ('Мексика', 'Матаморос', 'MAM') Транзакции
По умолчанию транзакция создаётся до выполнения первого запроса к БД, и все последующие запросы выполняются в контексте этой транзакции. Завершить транзакцию можно несколькими способами:
- закрыв соединение conn.close()
- удалив соединение del conn
- вызвав conn.commit() или conn.rollback()
Старайтесь избегать длительных транзакций, ни к чему хорошему они не приводят. Для ситуаций, когда атомарные операции не нужны, существует свойство autocommit для connection класса. Когда значение равно True , каждый вызов execute будет моментально отражен на стороне БД (например, запись через INSERT).
with conn.cursor() as cursor: conn.autocommit = True values = [ ('ALA', 'Almaty', 'Kazakhstan'), ('TSE', 'Astana', 'Kazakhstan'), ('PDX', 'Portland', 'USA'), ] insert = sql.SQL('INSERT INTO city (code, name, country_name) VALUES <>').format( sql.SQL(',').join(map(sql.Literal, values)) ) cursor.execute(insert) Интересные записи:
- Celery: начинаем правильно
- Введение в logging на Python
- Что нового появилось в Django Channels?
- Работа с MySQL в Python
- Django Channels: работа с WebSocket и не только
- FastAPI, asyncio и multiprocessing
- Почему Python?
- Pyenv: удобный менеджер версий python
- Руководство по работе с HTTP в Python. Библиотека requests
- Обзор Python 3.9
- Python-RQ: очередь задач на базе Redis
- Введение в pandas: анализ данных на Python
- Как написать Telegram бота: практическое руководство
- Разворачиваем Django приложение в production на примере Telegram бота
- Авторизация через Telegram в Django и Python
- Django, RQ и FakeRedis
- Обзор Python 3.8
- Итоги первой встречи Python программистов в Алматы
- Интеграция Trix editor в Django
- Участие в подкасте TalkPython
- Строим Data Pipeline на Python и Luigi
- Видео презентации ETL на Python
- Авторизация через Telegram в Django приложении
Записки программиста
Мне нравится Python, а также мне нравится PostgreSQL. И вот я подумал — ей, а почему бы не использовать их вместе? 🙂 Для работы с PostgreSQL в мире Python большой популярностью пользуется пакет psycopg2. Но он, по всей видимости, до сих пор не поддерживает prepared statements. Поэтому для своих задач я пока что остановился на чуть менее популярном пакете py-postgresql. Этот пакет, как я понимаю, поддерживает все, что нужно.
Дополнение: Выяснилось, что py-postgresql не работает с последними версиями PostgreSQL. См заметку Работа с PostgreSQL на Python с помощью psycopg2.
Ставится он, как обычно, через pip. Например (но лучше пользоваться virtualenv):
sudo pip3 install py-postgresql
При изучении новой библиотеки сначала я пытаюсь поделать с ней что-нибудь в REPL. Далее я опускаю приглашение REPL’а, которое >>> .
Создание новой сессии:
import postgresql
db = postgresql. open ( ‘pq://postgres:postgres@localhost:5432/mydb’ )
В реальных скриптах, конечно же, не забываем использовать конструкцию with .
Создание схемы, выполнение простых запросов:
db. execute ( «CREATE TABLE users (id SERIAL PRIMARY KEY, »
«login CHAR(64), password CHAR(64))» )
Создание prepared statement и выполнение INSERT-запроса:
ins = db. prepare ( «INSERT INTO users (login, password) VALUES ($1, $2)» )
ins ( «afiskon» , «123» )
# (‘INSERT’, 1)
ins ( «eax» , «456» )
# (‘INSERT’, 1)
Выполнение SELECT-запроса (делаем trim, так как varchar дополняется пробелами):
db. query ( «SELECT id, trim(login), trim(password) FROM users» )
# [(1, ‘afiskon’, ‘123’), (2, ‘eax’, ‘456’)]
К полям можно обращаться как по номерам, так и по именам:
users = db. query ( «SELECT * FROM users WHERE > ) ;
users [ 0 ] [ 0 ]
# 1
users [ 0 ] [ «id» ]
# 1
users [ 0 ] [ «login» ] . strip ( )
# ‘afiskon’
Выполнение UPDATE- и DELETE-запросов:
update = db. prepare ( «UPDATE users SET password = $2 where login = $1» )
update ( «eax» , «789» )
# (‘UPDATE’, 1)
delete = db. prepare ( «DELETE FROM users WHERE > )
delete ( 3 )
# (‘DELETE’, 0)
db. query ( «DELETE FROM users WHERE > )
# (‘DELETE’, 0)
Пример выполнения транзакции:
with db. xact ( ) as xact:
db. query ( «SELECT id FROM users» )
# [(1,), (2,)]
Пример выполнения rollback:
with db. xact ( ) as xact:
db. query ( «SELECT id FROM users» )
xact. rollback ( )
Вызов хранимых процедур:
ver = db. proc ( «version()» )
ver ( )
# ‘PostgreSQL 9.5 . ‘
Работа с курсорами:
db. execute ( «DECLARE my_cursor CURSOR WITH HOLD FOR »
«SELECT id, trim(login) FROM users» )
c = db. cursor_from_id ( «my_cursor» )
c. read ( )
# [(1, ‘afiskon’), (2, ‘eax’)]
Можно ограничить количество считываемых элементов:
c. read ( 100 )
Попробуйте заполнить таблицу таким образом и повторить эксперимент:
for i in range ( 1 , 1000 ) :
ins ( «user» + str ( i ) , «pass» + str ( i ) )
И напоследок рассмотрим наброски типа более гибкой альтернативы pgbench:
import time
import threading
import postgresql
testtime = 10
nthreads = 4
def worker ( ) :
nqueries = 0
with postgresql. open ( ‘pq://eax@192.168.111.222/eax’ ) as db:
query = db. prepare ( «SELECT * FROM themes WHERE > )
starttime = time . time ( )
while time . time ( ) — starttime < testtime:
query ( )
nqueries = nqueries + 1
print ( «Thread » + str ( threading . get_ident ( ) ) + » — total » +
str ( nqueries ) + » queries executed» )
for i in range ( nthreads ) :
t = threading . Thread ( target = worker )
t. start ( )
- https://pypi.python.org/pypi/py-postgresql;
- http://pythonhosted.org/py-postgresql/;
- https://wiki.postgresql.org/wiki/Python;
А как вы нынче работаете с базами данных на Python?
Вы можете прислать свой комментарий мне на почту, или воспользоваться комментариями в Telegram-группе.