Как проверить данные во фрейме Pandas с помощью Pandera
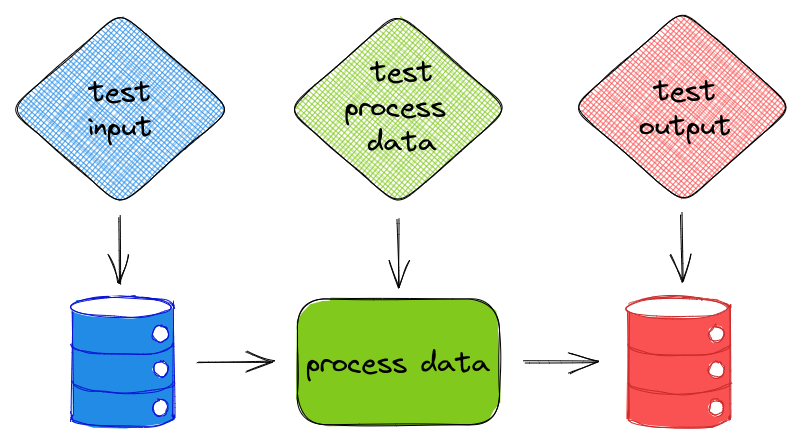
В науке о данных важно тестировать не только функции, но и данные, чтобы убедиться, что они работают так, как вы ожидали. Материалом о простой библиотеке Pandera для валидации фреймов данных Pandas делимся к старту флагманского курса по Data Science.
Чтобы установить Pandera, в терминале наберите:
pip install panderaВведение
Начнём с простого набора данных, чтобы понять, как работает Pandera:
import pandas as pd fruits = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store": ["Aldi", "Walmart", "Walmart", "Aldi"], "price": [2, 1, 3, 4], >) fruits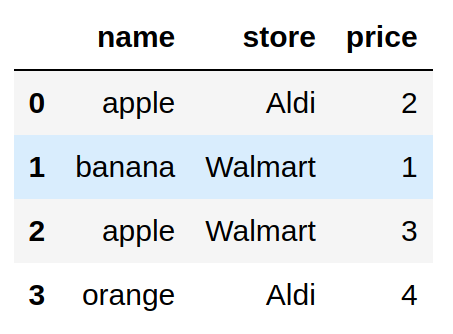
Представьте: ваш менеджер сказал вам, что в наборе данных могут храниться только определённые фрукты, а значение их цены должно быть меньше 4:
available_fruits = ["apple", "banana", "orange"] nearby_stores = ["Aldi", "Walmart"]Проверка данных вручную может занять много времени, особенно когда их много. Есть ли способ автоматизировать проверку? Да, здесь и пригодится Pandera:
- создадим тесты всего набора данных с помощью DataFrameSchema;
- тесты для каждой колонки — при помощи Column;
- тип теста определим при помощи Check.
import pandera as pa from pandera import Column, Check schema = pa.DataFrameSchema( < "name": Column(str, Check.isin(available_fruits)), "store": Column(str, Check.isin(nearby_stores)), "price": Column(int, Check.less_than(4)), >) schema.validate(fruits)SchemaError: failed element-wise validator 0: failure cases: index failure_case 0 3 4Поясню этот код:
- «name»: Column(str, Check.isin(available_fruits)) проверяет, имеет ли столбец name тип string и все ли значения столбца name находятся внутри указанного списка;
- «price»: Column(int, Check.less_than(4)) проверяет, все ли значения в столбце price имеют тип int и меньше 4;
- не все значения в столбце price меньше 4, поэтому тест не проходит.
Другие встроенные методы Checks вы найдёте здесь.
Настраиваемые проверки
Проверки можно писать и через лямбда-выражения. В коде ниже Check(lambda price: sum(price) < 20) проверяет, меньше ли 20 сумма в price.
schema = pa.DataFrameSchema( < "name": Column(str, Check.isin(available_fruits)), "store": Column(str, Check.isin(nearby_stores)), "price": Column( int, [Check.less_than(5), Check(lambda price: sum(price) < 20)] ), >) schema.validate(fruits)SchemaModel
Когда тесты сложные, чище код сделают не словари, а классы данных. К счастью, Pandera позволяет создавать тесты с классами данных.
from pandera.typing import Series class Schema(pa.SchemaModel): name: Series[str] = pa.Field(isin=available_fruits) store: Series[str] = pa.Field(isin=nearby_stores) price: Series[int] = pa.Field(le=5) @pa.check("price") def price_sum_lt_20(cls, price: Series[int]) -> Series[bool]: return sum(price) < 20 Schema.validate(fruits)Декоратор валидации
Проверка ввода
Как тестировать входные значения функции? Прямолинейный подход — добавить schema.validate(input) прямо в функцию:
fruits = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store": ["Aldi", "Walmart", "Walmart", "Aldi"], "price": [2, 1, 3, 4], >) schema = pa.DataFrameSchema( < "name": Column(str, Check.isin(available_fruits)), "store": Column(str, Check.isin(nearby_stores)), "price": Column(int, Check.less_than(5)), >) def get_total_price(fruits: pd.DataFrame, schema: pa.DataFrameSchema): validated = schema.validate(fruits) return validated["price"].sum() get_total_price(fruits, schema)Но он осложняет тестирование. Функция get_total_price имеет аргументы fruits and schema, а значит, в тест функции нужно включить оба:
def test_get_total_price(): fruits = pd.DataFrame() # Need to include schema in the unit test schema = pa.DataFrameSchema( < "name": Column(str, Check.isin(available_fruits)), "store": Column(str, Check.isin(nearby_stores)), "price": Column(int, Check.less_than(5)), >) assert get_total_price(fruits, schema) == 3Функция test_get_total_price проверяет и данные, и функцию. Модульный тест должен проверять только одну вещь, поэтому включение проверки данных внутри функции — не идеальное решение.
Эту проблему Pandera решает декоратором check_input. Аргумент декоратора применяется в валидации входных значений:
from pandera import check_input @check_input(schema) def get_total_price(fruits: pd.DataFrame): return fruits.price.sum() get_total_price(fruits)Если входное значение некорректно, Pandera поднимает исключение до обработки значения в функции:
fruits = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store": ["Aldi", "Walmart", "Walmart", "Aldi"], "price": ["2", "1", "3", "4"], >) @check_input(schema) def get_total_price(fruits: pd.DataFrame): return fruits.price.sum() get_total_price(fruits)SchemaError: error in check_input decorator of function 'get_total_price': expected series 'price' to have type int64, got objectТакая проверка до обработки в функции экономит много времени.
Проверка вывода
Для проверки вывода можно использовать декоратор check_output:
from pandera import check_output fruits_nearby = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store": ["Aldi", "Walmart", "Walmart", "Aldi"], "price": [2, 1, 3, 4], >) fruits_faraway = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store": ["Whole Foods", "Whole Foods", "Schnucks", "Schnucks"], "price": [3, 2, 4, 5], >) out_schema = pa.DataFrameSchema( ) @check_output(out_schema) def combine_fruits(fruits_nearby: pd.DataFrame, fruits_faraway: pd.DataFrame): fruits = pd.concat([fruits_nearby, fruits_faraway]) return fruits combine_fruits(fruits_nearby, fruits_faraway)Проверка ввода и вывода
Проверить входные и выходные данные можно с помощью декоратора check_io:
from pandera import check_io in_schema = pa.DataFrameSchema() out_schema = pa.DataFrameSchema( ) @check_io(fruits_nearby=in_schema, fruits_faraway=in_schema, out=out_schema) def combine_fruits(fruits_nearby: pd.DataFrame, fruits_faraway: pd.DataFrame): fruits = pd.concat([fruits_nearby, fruits_faraway]) return fruits combine_fruits(fruits_nearby, fruits_faraway)Другие аргументы проверки столбцов
Null
По умолчанию Pandera выдаёт ошибку, если в проверяемом столбце есть Null. Если нулевые значения допустимы, в класс Column добавьте nullable=True:
import numpy as np fruits = fruits = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store": ["Aldi", "Walmart", "Walmart", np.nan], "price": [2, 1, 3, 4], >) schema = pa.DataFrameSchema( < "name": Column(str, Check.isin(available_fruits)), "store": Column(str, Check.isin(nearby_stores), nullable=True), "price": Column(int, Check.less_than(5)), >) schema.validate(fruits)Дубликаты
По умолчанию дубликаты допустимы. Чтобы они поднимали исключение, добавьте аргумент allow_duplicates=False:
schema = pa.DataFrameSchema( < "name": Column(str, Check.isin(available_fruits)), "store": Column( str, Check.isin(nearby_stores), nullable=True, allow_duplicates=False ), "price": Column(int, Check.less_than(5)), >) schema.validate(fruits)SchemaError: series 'store' contains duplicate values:
Преобразование типов данных
Аргумент coerce=True изменяет тип данных столбца, если тип не удовлетворяет условию проверки.
В коде ниже тип данных цены изменён с целого на строку:
fruits = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store": ["Aldi", "Walmart", "Walmart", "Aldi"], "price": [2, 1, 3, 4], >) schema = pa.DataFrameSchema() validated = schema.validate(fruits) validated.dtypesname object store object price object dtype: objectСопоставление шаблонов
Что, если мы хотим изменить все столбцы, которые начинаются со слова store?
favorite_stores = ["Aldi", "Walmart", "Whole Foods", "Schnucks"] fruits = pd.DataFrame( < "name": ["apple", "banana", "apple", "orange"], "store_nearby": ["Aldi", "Walmart", "Walmart", "Aldi"], "store_far": ["Whole Foods", "Schnucks", "Whole Foods", "Schnucks"], >)Pandera позволяет нам применять одни и те же проверки к нескольким столбцам с определённым шаблоном, вот так: regex=True:
schema = pa.DataFrameSchema( < "name": Column(str, Check.isin(available_fruits)), "store_+": Column(str, Check.isin(favorite_stores), regex=True), >) schema.validate(fruits)Экспорт и загрузка из файла YAML
Экспорт в YAML
YAML — отличный способ показать свои тесты коллегам, не знающим Python. Сохранить все проверки в файле YAML можно с помощью метода schema.to_yaml():
from pathlib import Path # Get a YAML object yaml_schema = schema.to_yaml() # Save to a file f = Path("schema.yml") f.touch() f.write_text(yaml_schema)Файл schema.yml должен выглядеть примерно так:
schema_type: dataframe version: 0.7.0 columns: name: dtype: str nullable: false checks: isin: - apple - banana - orange allow_duplicates: true coerce: false required: true regex: false store: dtype: str nullable: true checks: isin: - Aldi - Walmart allow_duplicates: false coerce: false required: true regex: false price: dtype: int64 nullable: false checks: less_than: 5 allow_duplicates: true coerce: false required: true regex: false checks: null index: null coerce: false strict: falseЗагрузка из YAML
Чтобы загрузить файл, используйте pa.io.from_yaml(yaml_schema):
with f.open() as file: yaml_schema = file.read() schema = pa.io.from_yaml(yaml_schema)Заключение
Поздравляю! Вы только что узнали, как использовать Pandera для проверки вашего набора данных. Поскольку в науке о данных данные являются важным аспектом проекта, валидация входных и выходных ваших функций позволит сократить количество ошибок на всех этапах работы. Не стесняйтесь форкать исходный код для этой статьи.
А мы поможем вам прокачать навыки или с самого начала освоить профессию, востребованную в любое время:
- Профессия Data Scientist
- Профессия Data Analyst

Краткий каталог курсов и профессий
Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
- Профессия iOS-разработчик
- Профессия Android-разработчик
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
- Курс «Алгоритмы и структуры данных»
- Профессия C++ разработчик
- Профессия Этичный хакер
А также
Изменение типа столбца в pandas
Часто возникает необходимость изменить тип данных столбцов в DataFrame. Например, при создании DataFrame из списка списков, типы данных столбцов определяются автоматически, что может не всегда соответствовать ожидаемому.
table = [ ['a', '1.2', '4.2' ], ['b', '70', '0.03'], ['x', '5', '0' ], ] df = pd.DataFrame(table)
В этом примере, все столбцы будут иметь тип данных object, хотя второй и третий столбцы содержат числовые значения, которые мы хотели бы иметь в виде чисел с плавающей точкой.
Изменение типа данных столбцов после создания DataFrame
Если DataFrame уже создан, то для изменения типа данных столбцов можно использовать метод astype() .
df[1] = df[1].astype(float) df[2] = df[2].astype(float)
Здесь мы преобразовали второй и третий столбцы в числа с плавающей точкой.
Задание типа данных столбцов при создании DataFrame
Также типы данных столбцов можно задать сразу при создании DataFrame, используя параметр dtype в функции pd.DataFrame() .
df = pd.DataFrame(table, dtype=float)
Однако, в этом случае все столбцы будут иметь заданный тип данных, что может вызвать ошибки, если в некоторых столбцах содержатся нечисловые данные.
Динамическое изменение типа данных столбцов
Если в DataFrame много столбцов и неизвестно, какие из них нужно преобразовать, можно использовать метод apply() , который применяет указанную функцию к каждому столбцу.
df = df.apply(lambda col: col.astype(float) if col.str.replace('.','').str.isdigit().all() else col)
В этом примере мы применяем функцию, которая проверяет, содержат ли все строки в столбце только числовые символы, и если это так, преобразует столбец в числа с плавающей точкой.
Таким образом, есть несколько способов изменить тип данных столбцов в pandas DataFrame, и выбор конкретного метода зависит от конкретной ситуации.
Как определить тип столбца, чтобы затем осуществить действия по условию?
Все данные имеют тип object в данном столбце (проверила через df.info() ).
Есть пример таблица CSV, над которой нужно совершать преобразования:
Категория 1 |Категория 2|Показатель_1|Показатель_2| ______________|___________|____________|____________| A1_AAA_aaa-11 |ZZZ_1_aaa_1|2 |3 _____________ |___________|____________|____________| 111111-111 |ZZZ_2_aaa_b|1 |1 ______________|___________|____________|_____________ 222222-222 |AAA_s_12a_2|1 |4 ______________|___________|____________|_____________ 333333-333 |AAA_s_12a_2|2 |3 ______________|___________|____________|_____________ B1_BBB_bbb-11 |CCC_s_12a_2|0 |0 Значит, после преобразования будет получена новая таблица таблица такого вида (Результат):
Категория по буквам |Категория по аббривиатуре|Сумма показателей| ____________________|_________________________|_________________| Буквенная |ZZZ | 5 | ______________|_________________________|_________________| Численная |ZZZ | 2 ______________|_________________________|_________________| Численная |AAA | 10 ______________|_________________________|_________________| Буквенная |CCC | 0 | Работаем с Pandas: основные понятия и реальные данные
Разбираемся в том, как работает библиотека Pandas и проводим первый анализ данных.

Иллюстрация: Катя Павловская для Skillbox Media

Антон Яценко
Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Python используют для анализа данных и машинного обучения, подключая к нему различные библиотеки: Pandas, Matplotlib, NumPy, TensorFlow и другие. Каждая из них используется для решения конкретных задач.
Сегодня мы поговорим про Pandas: узнаем, для чего нужна эта библиотека, как импортировать её в Python, а также проанализируем свой первый датасет и выясним, в какой стране самый быстрый и самый медленный интернет.
Для чего нужна библиотека Pandas в Python
Pandas — главная библиотека в Python для работы с данными. Её активно используют аналитики данных и дата-сайентисты. Библиотека была создана в 2008 году компанией AQR Capital, а в 2009 году она стала проектом с открытым исходным кодом с поддержкой большого комьюнити.
Вот для каких задач используют библиотеку:
Аналитика данных: продуктовая, маркетинговая и другая. Работа с любыми данными требует анализа и подготовки: необходимо удалить или заполнить пропуски, отфильтровать, отсортировать или каким-то образом изменить данные. Pandas в Python позволяет быстро выполнить все эти действия, а в большинстве случаев ещё и автоматизировать их.
Data science и работа с большими данными. Pandas помогает подготовить и провести первичный анализ данных, чтобы потом использовать их в машинном или глубоком обучении.
Статистика. Библиотека поддерживает основные статистические методы, которые необходимы для работы с данными. Например, расчёт средних значений, их распределения по квантилям и другие.
Работа с Pandas
Для анализа данных и машинного обучения обычно используются особые инструменты: Google Colab или Jupyter Notebook. Это специализированные IDE, позволяющие работать с данными пошагово и итеративно, без необходимости создавать полноценное приложение.
В этой статье мы посмотрим на Google Colab, облачное решение для работы с данными, которое можно запустить в браузере на любом устройстве: десктопе, ноутбуке, планшете или даже смартфоне.
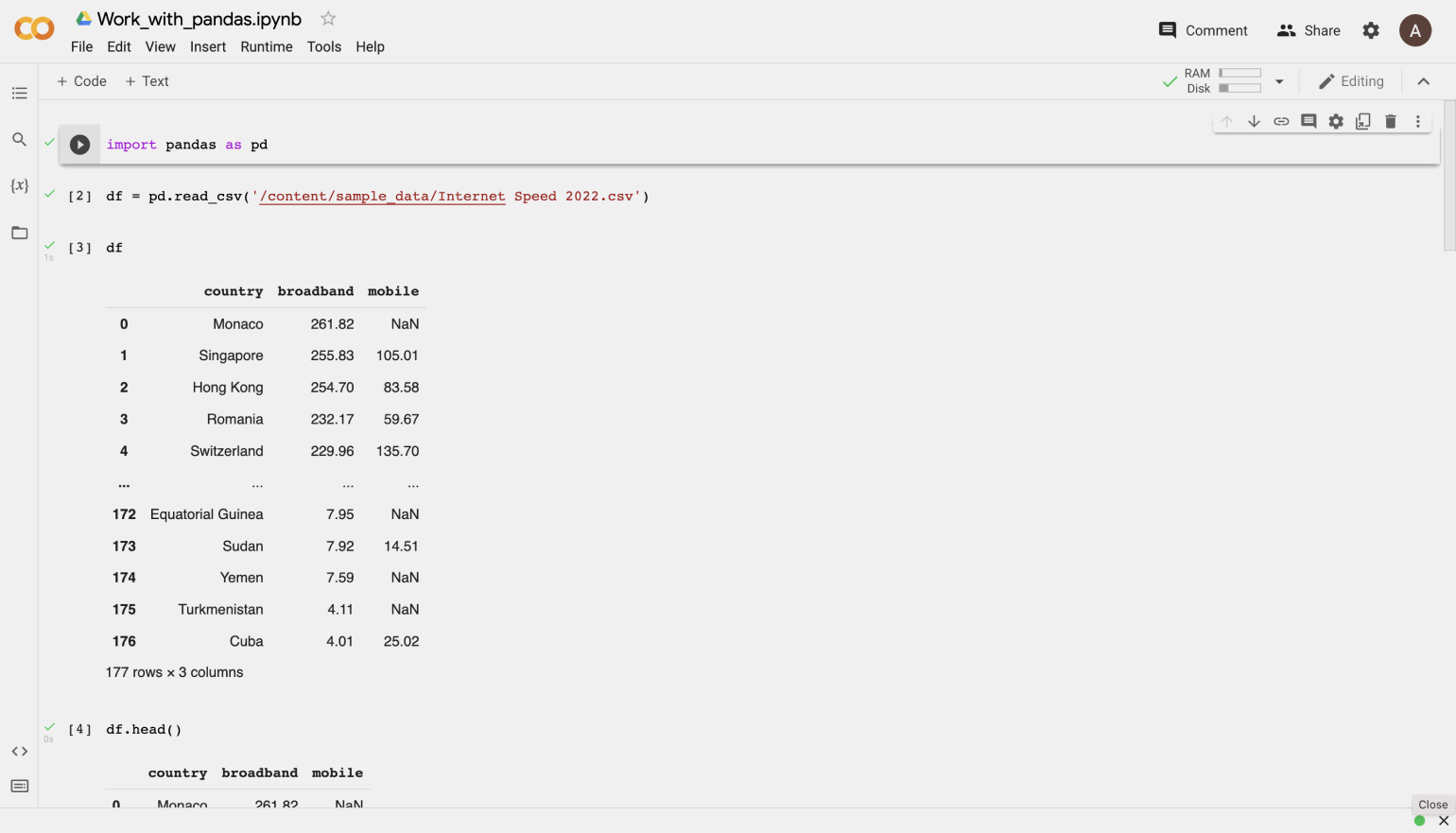
Каждая строчка кода на скриншоте — это одно действие, результат которого Google Colab и Jupyter Notebook сразу демонстрируют пользователю. Это удобно в задачах, связанных с аналитикой и data science.
Устанавливать Pandas при работе с Jupyter Notebook или Colab не требуется. Это стандартная библиотека, которая уже будет доступна сразу после их запуска. Останется только импортировать её в ваш код.

Series отображается в виде таблицы с индексами элементов в первом столбце и значениями во втором.
DataFrame — основной тип данных в Pandas, вокруг которого строится вся работа. Его можно представить в виде обычной таблицы с любым количеством столбцов и строк. Внутри ячеек такой «таблицы» могут быть данные самого разного типа: числовые, булевы, строковые и так далее.
У DataFrame есть и индексы строк, и индексы столбцов. Это позволяет удобно сортировать и фильтровать данные, а также быстро находить нужные ячейки.
Создадим простой DataFrame с помощью словаря и посмотрим на его отображение:
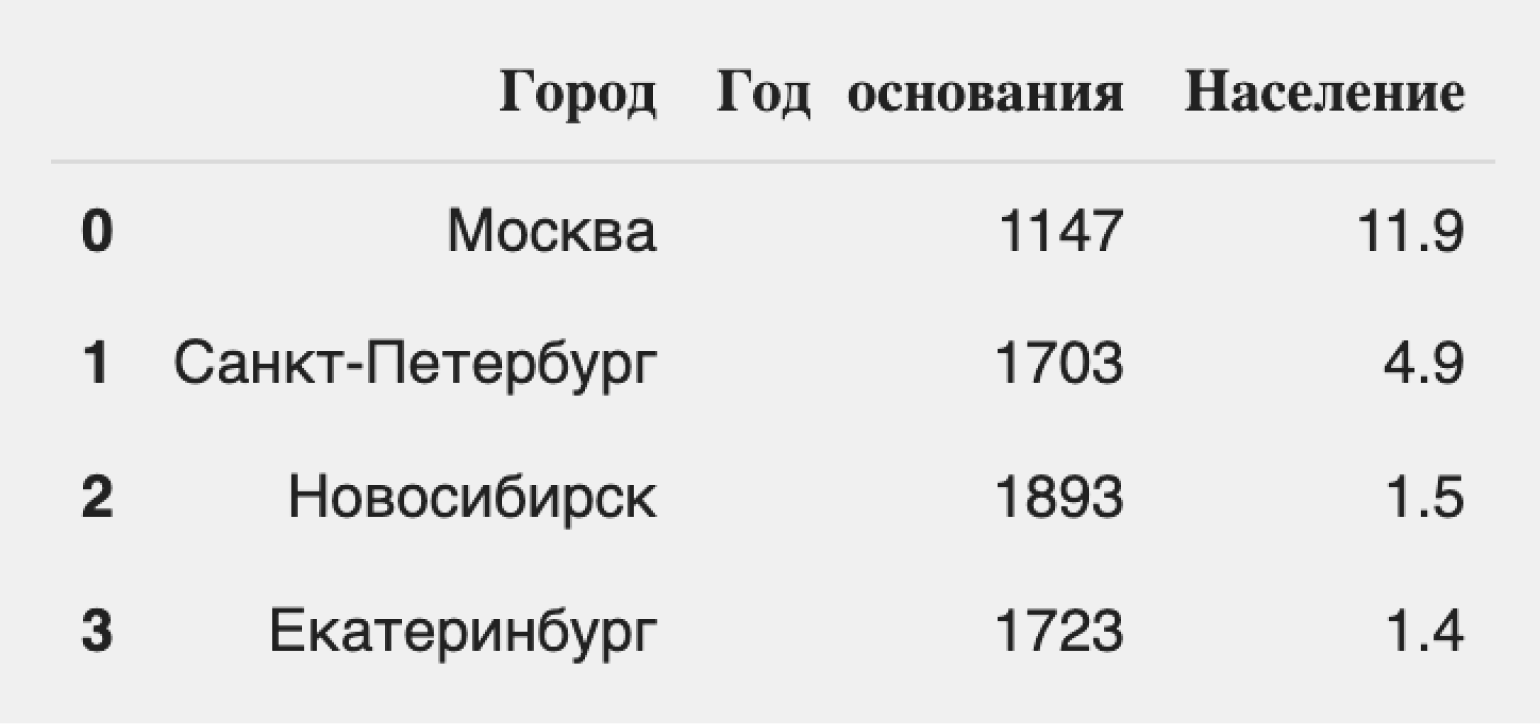
Мы видим таблицу, строки которой имеют индексы от 0 до 3, а «индексы» столбцов соответствуют их названиям. Легко заметить, что DataFrame состоит из трёх Series: «Город», «Год основания» и «Население». Оба типа индексов можно использовать для навигации по данным.

Импорт данных
Pandas позволяет импортировать данные разными способами. Например, прочесть их из словаря, списка или кортежа. Самый популярный способ — это работа с файлами .csv, которые часто применяются в анализе данных. Для импорта используют команду pd.read_csv().
read_csv имеет несколько параметров для управления импортом:
- sep — позволяет явно указать разделитель, который используется в импортируемом файле. По умолчанию значение равно ,, что соответствует разделителю данных в файлах формата .csv. Этот параметр полезен при нестандартных разделителях в исходном файле, например табуляции или точки с запятой;
- dtype — позволяет явно указать на тип данных в столбцах. Полезно в тех случаях, когда формат данных автоматически определился неверно. Например, даты часто импортируются в виде строковых переменных, хотя для них существует отдельный тип.
Подробно параметры, позволяющие настроить импорт, описаны в документации.
Давайте импортируем датасет с информацией о скорости мобильного и стационарного интернета в отдельных странах. Готовый датасет скачиваем с Kaggle. Параметры для read_csv не указываем, так как наши данные уже подготовлены для анализа.
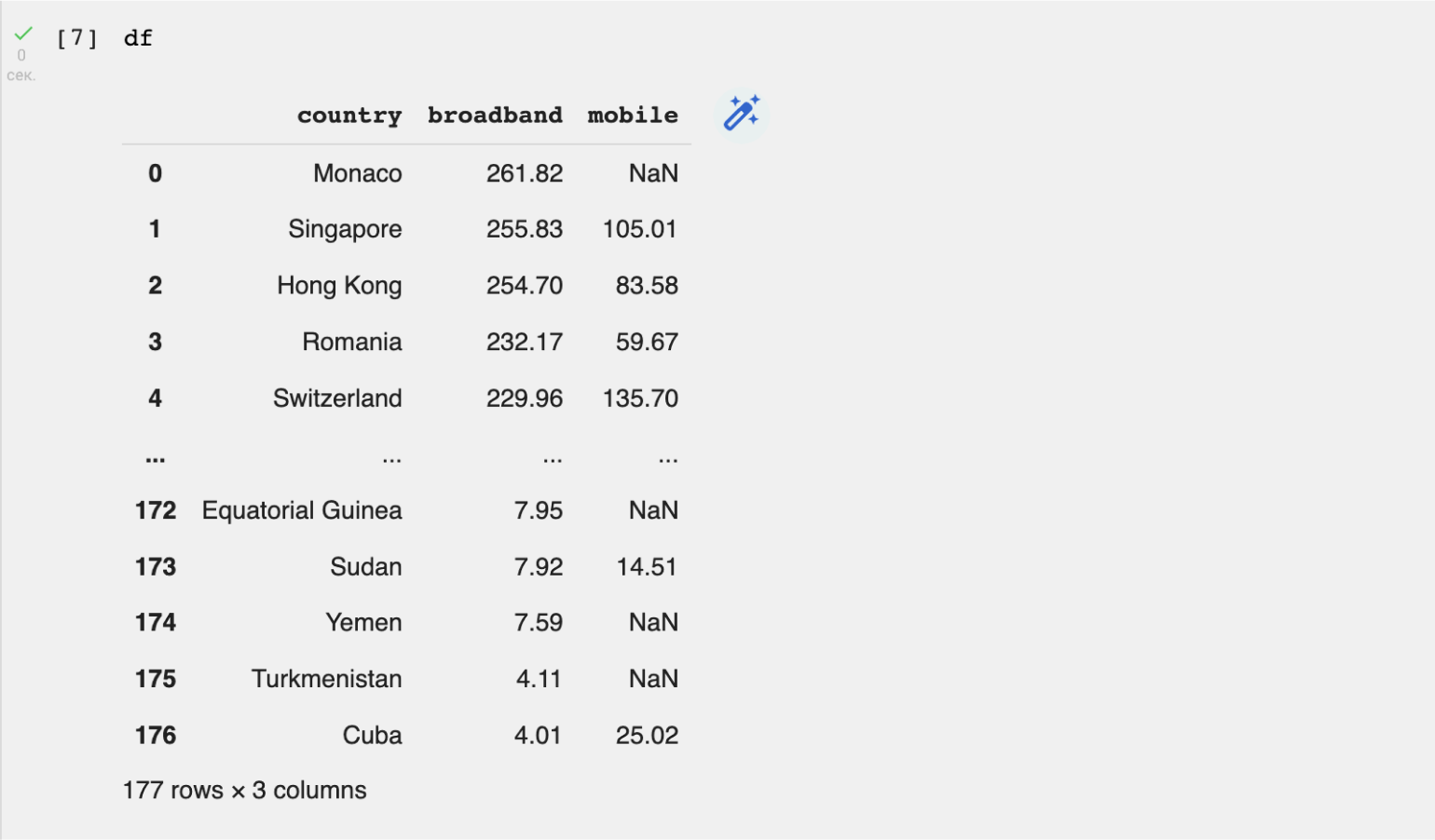
В верхней части таблицы мы видим названия столбцов: country (страна), broadband (средняя скорость интернета) и mobile (средняя скорость мобильного интернета). Слева указаны индексы — от 0 до 176. То есть всего у нас 177 строк. В нижней части таблицы Pandas отображает и эту информацию.
Выводить таблицу полностью необязательно. Для первого знакомства с данными достаточно показать пять первых или пять последних строк. Сделать это можно с помощью df.head() или df.tail() соответственно. В скобках можно указать число строк, которое требуется указать. По умолчанию параметр равен 5.

Так намного удобнее. Мы можем сразу увидеть названия столбцов и тип данных в столбцах. Также в некоторых ячейках мы видим значение NaN — к нему мы вернёмся позже.
Изучаем данные и описываем их
Теперь нам надо изучить импортированные данные. Действовать будем пошагово.
Шаг 1. Проверяем тип данных в таблице. Это поможет понять, в каком виде представлена информация в датасете — а иногда и найти аномалии. Например, даты могут быть сохранены в виде строк, что неудобно для последующего анализа. Проверить это можно с помощью стандартного метода:

- столбец country представляет собой тип object. Это тип данных для строковых и смешанных значений;
- столбцы broadband и mobile имеют тип данных float, то есть относятся к числам с плавающей точкой.
Шаг 2. Быстро оцениваем данные и делаем предварительные выводы. Сделать это можно очень просто: для этого в Pandas существует специальный метод describe(). Он показывает среднее со стандартным отклонением, максимальные, минимальные значения переменных и их разделение по квантилям.
Посмотрим на этот метод в деле:

Пройдёмся по каждой строчке:
- count — это количество заполненных строк в каждом столбце. Мы видим, что в столбце с данными о скорости мобильного интернета есть пропуски.
- mean — среднее значение скорости обычного и мобильного интернета. Уже можно сделать вывод, что мобильный интернет в большинстве стран медленнее, чем кабельный.
- std — стандартное отклонение. Важный статистический показатель, показывающий разброс значений.
- min и max — минимальное и максимальное значение.
- 25%, 50% и 75% — значения скорости интернета по процентилям. Если не углубляться в статистику, то процентиль — это число, которое показывает распределение значений в выборке. Например, в выборке с мобильным интернетом процентиль 25% показывает, что 25% от всех значений скорости интернета меньше, чем 24,4.
Обратите внимание, что этот метод работает только для чисел. Информация для столбца с названиями стран отсутствует.
Какой вывод делаем? Проводной интернет в большинстве стран работает быстрее, чем мобильный. При этом скорость проводного интернета в 75% случаев не превышает 110 Мбит/сек, а мобильного — 69 Мбит/сек.
Шаг 3. Сортируем и фильтруем записи. В нашем датафрейме данные уже отсортированы от большего к меньшему по скорости проводного интернета. Попробуем найти страну с наилучшим мобильным интернетом. Для этого используем стандартный метод sort_values, который принимает два параметра:
- название столбца, по которому происходит сортировка, — обязательно должно быть заключено в одинарные или двойные кавычки;
- параметр ascending= — указывает на тип сортировки. Если мы хотим отсортировать значения от большего к меньшему, то параметру присваиваем False. Для сортировки от меньшего к большему используем True.
Перейдём к коду:
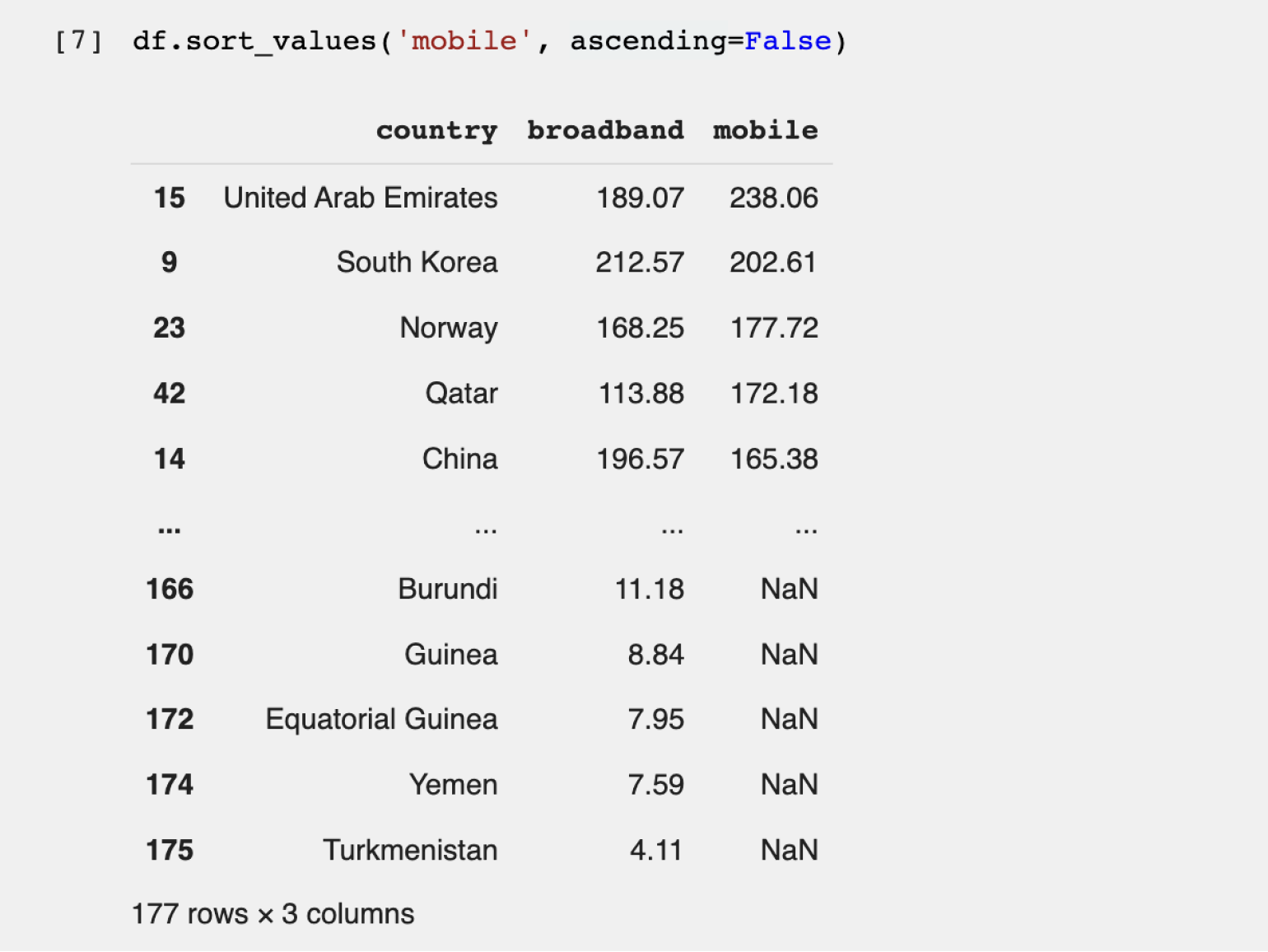
Теперь рейтинг стран другой — пятёрка лидеров поменялась (потому что мы отсортировали данные по другому значению). Мы выяснили, что самый быстрый мобильный интернет в ОАЭ.
Но есть нюанс. Если вернуться к первоначальной таблице, отсортированной по скорости проводного интернета, можно заметить, что у лидера — Монако — во втором столбце написано NaN. NaN в Python указывает на отсутствие данных. Поэтому мы не знаем скорость мобильного интернета в Монако из этого датасета и не можем сделать однозначный вывод о лидерах в мире мобильной связи.
Попробуем отфильтровать значения, убрав страны с неизвестной скоростью мобильного интернета, и посмотрим на худшие по показателю страны (если оставить NaN, он будет засорять «дно» таблицы и увидеть реальные значения по самому медленному мобильному интернету будет сложновато).
В Pandas существуют различные способы фильтрации для удаления NaN. Мы воспользуемся методом dropna(), который удаляет все строки с пропусками. Важно, что удаляется полностью строка, содержащая NaN, а не только ячейки с пропущенными значениями в столбце с пропусками.
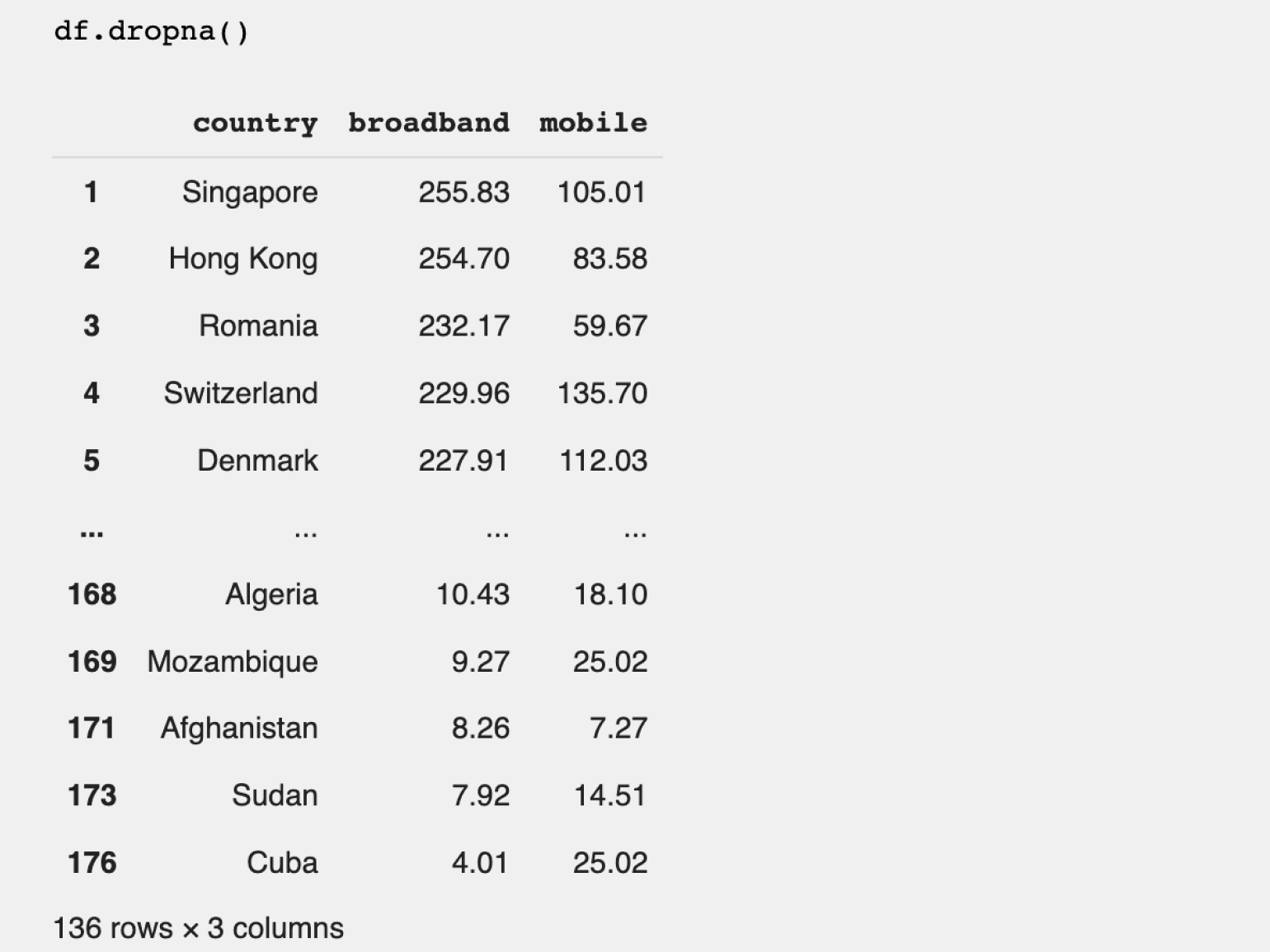
Количество строк в датафрейме при удалении пустых данных уменьшилось до 136. Если вернуться ко второму шагу, то можно увидеть, что это соответствует количеству заполненных строк в столбце mobile в начальном датафрейме.
Сохраним результат в новый датафрейм и назовём его df_without_nan. Изначальный DataFrame стараемся не менять, так как он ещё может нам понадобиться.
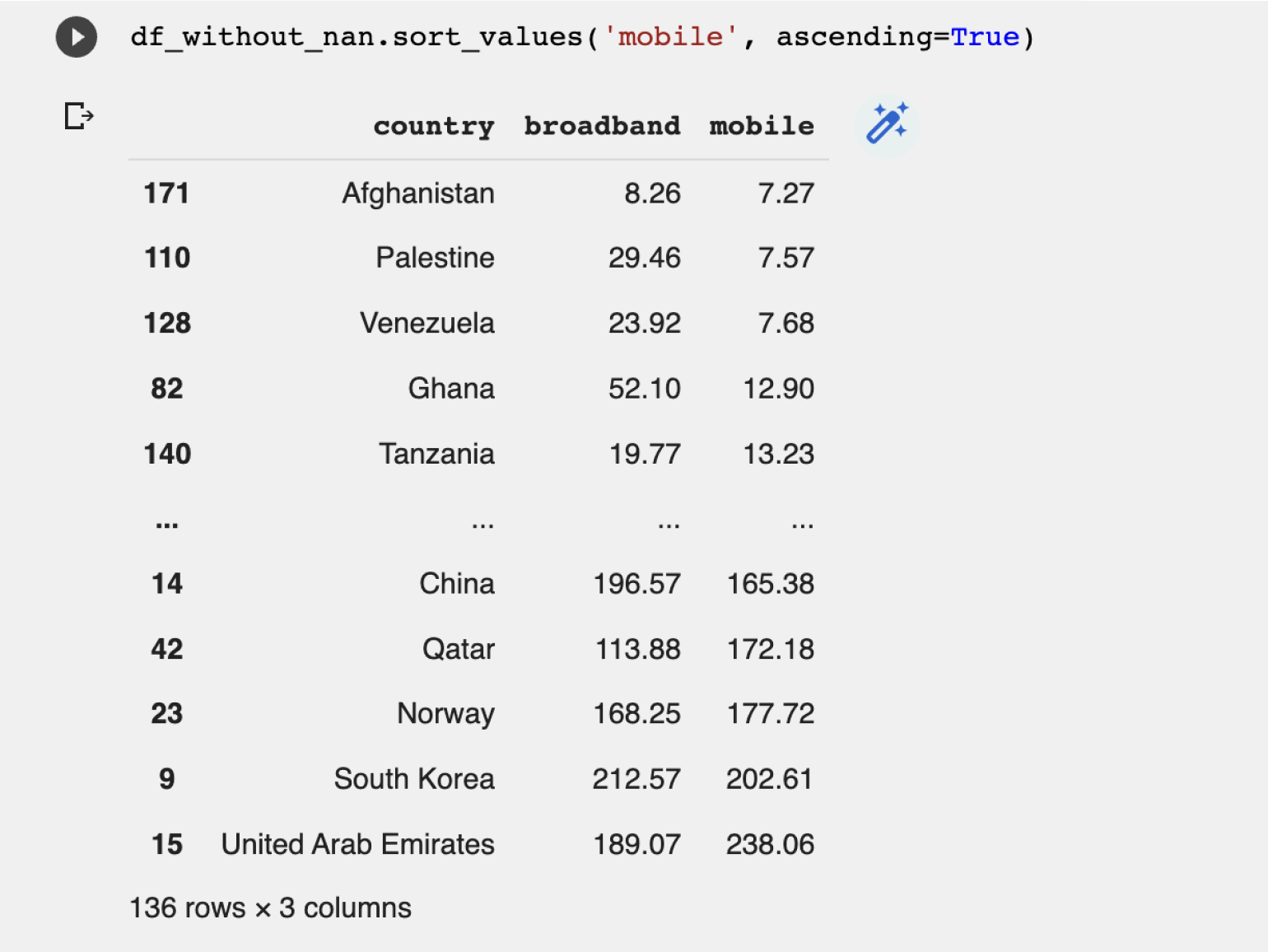
Худший мобильный интернет в Афганистане с небольшим отставанием от Палестины и Венесуэлы.
Что дальше?
Pandas в Python — мощная библиотека для анализа данных. В этой статье мы прошли по базовым операциям. Подробнее про работу библиотеки можно узнать в документации. Углубиться в работу с библиотекой можно благодаря специализированным книгам:
- «Изучаем pandas. Высокопроизводительная обработка и анализ данных в Python» Майкла Хейдта и Артёма Груздева;
- «Thinking in Pandas: How to Use the Python Data Analysis Library the Right Way», Hannah Stepanek;
- «Hands-On Data Analysis with Pandas: Efficiently perform data collection, wrangling, analysis, and visualization using Python», Stefanie Molin.
Читайте также:
- Библиотеки в программировании: для чего нужны и какими бывают
- Тест: угадайте, где эзотерические языки программирования, а где — нет
- Как начать программировать на Python: экспресс-гайд