Написание драйвера Linux с работой с прикладным ПО [закрыт]
Закрыт. На этот вопрос невозможно дать объективный ответ. Ответы на него в данный момент не принимаются.
Хотите улучшить этот вопрос? Переформулируйте вопрос так, чтобы на него можно было дать ответ, основанный на фактах и цитатах.
Закрыт 6 лет назад .
Здравствуйте. Подскажите статьи/книги/треды форумов на тему написания драйверов сетевых устройств под Linux. Интересно написать драйвер, который будет взаимодействовать с обычным пользовательским приложением (наподобии FUSE, только сеть). Спасибо.
Как написать драйвер для linux
Написание драйверов под Linux: рекомендации, типичные ошибки и ловушки.
Посвящается людям, которые несли в этот мир доброту, любовь, знания.
В данной статье указываются типичные ошибки и ловушки, возникающих при написании драйверов ОС Linux, высказываются рекомендации, которые могут при этом оказаться полезными.
3. Ключевые слова для поиска: драйвер, написание, программирование, Linux, ошибки, ловушки, рекомендации, советы, практика
Данная статья написана с целью помочь программистам, начинающим писать драйверы устройств для ОС Linux. Автор понимает, что обычно люди берущиеся за написание драйверов обладают как правило достаточно высоким интеллектом и серьёзными знаниями в области программировании, что позволяет им самостоятельно без чьей-либо непосредственной помощи решить задачу любой сложности в плане программирования, в том числе и написание правильно работающих драйверов под ОС Linux. Поэтому данная статья написана лишь с целью сократить время, требуемое на решение проблем возникающих при написании драйверов под ОС Linux посредством указания типичных ошибок (большей частью из личного опыта автора), потенциально опасных мест в коде, а также высказыванием ряда рекомендаций, которых следует придерживаться при написании драйверов (и вообще при написании кода, выполняющегося на уровне ядра).
Автор надеется и будет рад если данная статья окажется кому-либо полезной т.к. по мнению автора на данный момент ощущается нехватка публикаций на данную тему. Приведённые в статье примеры относятся к ядрам версий 2.6.x, хотя автор старался (по мере возможности) не привязываться к каким-либо конкретным версиям. Необходимо также понимать, что несмотря на то, что приведены типичные симптомы, возникающие при указанных в данной статье ошибках, поведение системы/ядра может отличаться (возможно незначительно) в разных версиях ядер ОС Linux.
5. Инструменты.
Необходимый минимум инструментария:
1. magic Sys Req-клавиши
2. отладочные сообщения
3. gdb и kdb
Использование п.1 по мнению автора обязательно. Настоятельно рекомендуется (по крайней мере до времени получения правильно работающего kernelspace-кода) использовать журналируемые файловые системы. Отладочные сообщения служат для определения области кода, приведшей к ошибке. Cледует избегать (по возможности) использования отладчиков т.к. на работу с ними уходит значительное время. Хотя необходимо отметить, что как правило совсем обойтись без них нельзя поэтому следует заранее побеспокоится например о поиске патча kdb под отлаживаемое ядро и о свободном пространстве на жёстком диске (около 1Гб). Оба отладчика являются достаточно полезными (kdb в большей степени), но имеют свою специфику например: gdb позволяет следить за данными, но не может вмешиваться в работу ядра (например расставлять точки останова) при этом система функционирует как обычно; kdb позволяет выставлять точки останова но при попадании в них вся система будет остановлена и нельзя будет скажем переключится в другую консоль и посмотреть результаты какой-то программы, кроме того kdb плохо совместим с X Window. Рекомендуется (для упрощения отладки) встраивать драйверы жёстко в ядро.
Ну и в целом при анализе кода смотрите на него глазами машины (т.е. не что он должен делать, а что делает).
6. Типичные ошибки.
1) неблокируемый вызов функций.
Симптомы: код то работает, то не работает как предполагается.
Пример: регистрация нового usb-устройства. В случае вызова usb_register_dev() происходит немедленный возврат и например последующая (сразу же) заливка прошивки может закончится не успешно.
Решение: необходимо добавить временнУю задержку, которая (гарантированно) обеспечит правильное функционирование в случае выполнения некоторых действий, зависимых от действий неблокируемой функции или использовать другое решение (например, посредством переноса зависимых действий в другие методы драйвера, которые могут будут вызваны только лишь после окончания успешной регистрации устройства).
2) возвращение функцией (методом) драйвера неожидаемых значений при выполнении какого-либо системного вызова.
Симптомы: вывод ошибки ядром (например oops).
Пример: возврат методом драйвера open() (положительного) значения, полученного от вышерасположенной функции:
static int usb_device_open(struct inode *inode, struct file *file) < int retval = 0; . // some initialization retval = usb_device_init(); if ( retval
Решение: проверка возвращаемых значений на допустимость:
static int usb_device_open(struct inode *inode, struct file *file) < int retval = 0; . // some initialization retval = usb_device_init(); if ( retval < 0) info("Failed initialization"); . // failed if ( retval < 0) return retval; // success else return 0; >
(в данном случае open() должен вернуть в случае успеха нулевое значение или отрицательное в случае ошибки, возврат положительного значения приведёт к выводу ошибки ядром; это связано с тем, что перед вызовом определённого метода драйвера при выполнении системного вызова происходит выполнение некоторого кода ядра (функций), который при возвращении из метода драйвера выполняет ряд определённых действий в зависимости от возвращённого значения (какие значения допустимо возвращать зависит от системного вызова).
3) Запрос памяти, чей размер не кратен размеру страниц, у низкоуровневых функций распределения памяти (напр. __get_free_pages).
Симптомы: наиболее вероятно зависание системы вместе с отладчиком (в случае использования низкоуровневых функций), менее вероятен вывод ошибки ядром (oops) или возращение кода ошибки (это связано с тем, что как правило в низкоуровневых функциях отдаётся предпочтение производительности, чем проверкам на правильность/допустимость (не везде, а как правило в некоторых частях ядра, особенно влияющих на производительность системы)), а также возможно по причине некорректной работы низкоуровневых (вспомогательных) алгоритмов изначально не расчитанных на работу с памятью, чей размер не кратен размеру страниц). Необходимо также отметить, что как правило число таких функций невелико и обычно большинство функций из набора API, предоставляемого подсистемой памяти позволяет работать с памятью не кратной размеру страницы (например, remap_pfn_range()).
Пример:
static inline void *mem_alloc(size_t size) < void *mem; // if size is not page aligned then system will die. mem = (void *)__get_free_pages(GFP_ATOMIC, get_order(size)); . return mem; >
Решение: использование выравнивания там где это необходимо
static inline void *mem_alloc(size_t size) < void *mem; // align on page mem = (void *)__get_free_pages(GFP_ATOMIC, get_order((PAGE_ALIGN(size))); . return mem; >
4) освобождение ресурсов во время их использования.
Симптомы: от зависания и выдачи ошибки ядром до полного отсутствия каких-либо ошибок непосредственно после «досрочного» освобождения ресурсов (могут проявится позже).
Пример: отсоединение USB-устройства во время его работы, приводящее к «досрочному» освобождению памяти, выделенной под его структуру.
Решение: осуществление освобождения ресурсов, только тогда, когда в них уже нет необходимости (т.н. deffered freeing).
5) Неправильное использование механизмов синхронизации из-за ошибок в коде или по причине неправильного понимания их реализации (напр. отличие в приоритете захвата семафоров от rw-семафоров).
Симптомы: неправильная работа ПО (userspace), работающего с драйвером (как правило, выражающаяся в блокировании на уровне ядра и создание т.н. «неубиваемых» процессов/потоков, расходующих ресурсы системы).
Пример: проявление некорректной работы USB-устройства в некоторых режимах (получение синхронно/асинхронно данных с устройства) из-за (внесения) реализации сложного взаимодействия потоков ядра.
Решение: правильное использование наиболее подходящих механизмов синхронизации (для разных случаев могут использоваться разные механизмы синронизации — для правильного выбора необходимо чётко представлять их особенности и специфику; как правило очень полезна информация (директория /Documentation исходного кода ядра), описывающая особенности реализации и специфику использования механизмов синхронизации). В случае сложного взаимодйствия можно порекомендовать вынести код, отвечающий за синронизацию из kernelspace в userspace (если это приемлимо/возможно).
7. Ловушки (потенциальные ошибки).
1) отсутствие барьеров между записями в регистры устройства.
Симптомы: устройство не работает или работает не так как предполагалось (также возможно различное поведение устройства в разных системах).
Пример: запись значений в регистры устройства, с последующим стартом работы устройства (получения данных).
Решение: использование соответствующих барьеров.
2) неправильное указание флагов выделения памяти.
Симптомы: редко проявляющаяся некорректная работа или даже зависания системы.
Пример: использование GFP_KERNEL в kmalloc() в контексте прерывания.
Решение: использование GFP_ATOMIC.
3) Отсутствие проверок при захвате ресурсов (подключение большого числа устройств одного типа, интенсивно использующих какой-либо ресурс системы — например полосу пропускания USB-шины).
Симптомы: деградация системы (в плане производительности) вплоть до отстуствия реакции, некорректная работа некоторых подсистем ядра.
Пример: подключение и одновременная работа N высокоскоростных USB-устройств (где N, это максимально возможное число одновременно подключённых USB-устройств, согласно стандарту (спецификации) Universal Serial Bus Specification Revision 2.0; необходимо также учитывать, что степень реализации спецификации в ядре ОС Linux может изменяться в разных версиях ядер, например реакция на превышение пропускной способности usb-шины существенно отличается в ядрах серии 2.4.x и 2.6.x).
Решение: расчитать и ввести в драйвере ограничение на максимальное количество устройств одного типа с которыми возможна одновременная работа (например, исходя из ограничения по пропускной способности USB-шины или объёмам используемой памяти).
4) отсутствие защиты от некорректных действий (userspace-программы и пользователя напр. решившего во время работы userspace-программы, получающей данные с USB-устройства отключить его (и возможно не только отключить, но и успеть снова включить!) — т.н. «защита от дурака».
Симптомы: неправильная работа ПО (userspace), ошибки в работе ядра (например, некорректная работа USB-подсистемы), зависание системы — зависит от значительности ошибки и степени её влияния на работу системы.
Пример: отключение устройства во время его работы.
Решение: реализация «защиты от дурака» (в том числе и достаточно маловероятных действий — система должна функционировать надёжно при любых условиях).
8. Рекомендации.
1) использование стиля кодирования являющегося фактически стандартом при программировании на уровне ядра — kernel coding style.
2) использование вместо специфичных для ядра типов данных типов имеющихся в стандарте языка С (вместо __u8 следует использовать uint8_t имеющийся в C99).
3) использование стандартных интерфейсов предоставляемых той или иной подсистемой ядра (не «изобретать колесо» в случаях, когда без этого можно обойтись).
4) инициализация (обнуление) памяти в случае если её содержимое передаётся/используется в userspace.
5) после каждого изменения, вносимого в код, выполняющийся на уровне ядра необходимо провести тщательное тестирование (на правильность функционирования, в различных режимах работы, в том числе и на защиту от некорректных действий).
6) не усложняйте без необходимости код, выполняемый на уровне ядра — придерживайтесь принципа «чем проще — тем лучше».
9. Список использованных источников.
1. Documentation/CodingStyle, исходный код ядра Linux ()
2. Allessandro Rubini, Jonathan Corbet — «Linux Device Drivers», 2-nd Edition, O’Reilly
3. Arjan van de Ven — «How to NOT write kernel driver»
| ©»Linuxportal.Ru». Материалы сайта можно использовать свободно при условии сохранения этой свободы при дальнейшем распространении, если явно не указано иное | Дизайн и программирование: | Поставьте нашу кнопку: Получить код кнопки |
| Наш партнер: |
Как разработать драйвер Linux с нуля

Недавно я занимался изучением IoT и, так как мне не хватало устройств, при попытках симулировать работу прошивки я часто сталкивался с неимением нужного /dev/xxx. Так что я стал задумываться, а могу ли написать драйвер самостоятельно, чтобы заставить прошивку работать. Независимо от того, насколько сложно это будет, и удастся ли воплотить такое намерение, в любом случае вы не пожалеете, если научитесь разрабатывать драйвер Linux с нуля.
❯ Введение
Я написал серию статей, ориентированных в основном на практику, о теории там мало что говорится. Разрабатывать драйверы я научился по книге Linux Device Drivers, а код к примерам, разобранным в этой книге, выложен на GitHub.
Если начать с азов – операционная система Linux делится на пространство ядра и пользовательское пространство. Доступ к аппаратному устройству возможен только через пространство ядра, а драйвер устройства при этом может трактоваться как API, предоставляемый в пространстве ядра и позволяющий коду из пользовательского пространства обращаться к устройству.
Опираясь на эти базовые концепции, я сформулировал для себя несколько проблем, которые и побудили меня изучить разработку драйвера.
- В программировании учёба всегда начинается с программы Hello World, так как же в данном случае написать программу Hello World?
- Как драйвер генерирует файлы устройств под /dev?
- Как именно происходит доступ драйвера к имеющемуся аппаратному обеспечению?
- Как написать код, управляемый системой? Или можно извлечь драйвер без кода? Где находятся двоичные файлы, в которых хранятся драйвера? В будущем все это можно было бы опробовать, чтобы изучить, насколько безопасно конкретное устройство.
❯ Всё начинается с Hello World
Вот какой получилась моя программа Hello World:
#include #include MODULE_LICENSE("Dual BSD/GPL"); MODULE_AUTHOR("Hcamal"); int hello_init(void) < printk(KERN_INFO "Hello World\n"); return 0; >void hello_exit(void) < printk(KERN_INFO "Goodbye World\n"); >module_init(hello_init); module_exit(hello_exit);Драйвер Linux разрабатывается на языке C, причём, на таком, который не слишком мне привычен. При работе я часто пользуюсь библиотекой Libc, которая отсутствует в ядре. Поскольку драйвер – это программа, работающая в ядре, именно в ядре мы используем и библиотечные функции.
Например, printk — это функция вывода, определяемая в ядре, она аналогична printf из Libc. Но мне она в большей степени напоминает логирующую функцию из Python, так как вывод printk идёт разу в лог ядра, а этот лог можно просмотреть командой dmesg .
В коде драйвера есть ровно одна точка входа и одна точка выхода. При загрузке драйвера в ядро выполнится функция, определяемая функцией module_init , которая в вышеприведённом коде называется hello_init . При выгрузке драйвера из ядра вызывается функция, определяемая в функции module_exit , которая в вышеприведённом коде называется hello_exit .
Из показанного выше кода понятно, что, загружаясь, драйвер выводит Hello World, а выгружаясь — Goodbye World .
Кстати: MODULE_LICENSE и MODULE_AUTHOR не так важны. Здесь я не буду подробно их разбирать.
И ещё: для вывода функции printk должен добавляться переход на новую строку, иначе опорожнение буфера происходить не будет.
❯ Компилируем драйвер
Драйвер необходимо скомпилировать командой make , и соответствующий Makefile показан ниже:
ifneq ($(KERNELRELEASE),) obj-m := hello.o else KERN_DIR ?= /usr/src/linux-headers-$(shell uname -r)/ PWD := $(shell pwd) default: $(MAKE) -C $(KERN_DIR) M=$(PWD) modules endif clean: rm -rf *.o *~ core .depend .*.cmd *.ko *.mod.c .tmp_versionsВообще исходный код ядра находится в каталоге /usr/src/linux-headers-$(shell uname -r)/, например:
$ uname -r 4.4.0-135-generic/usr/src/linux-headers-4.4.0-135/ --> каталог исходного кода ядра /usr/src/linux-headers-4.4.0-135-generic/ --> каталог скомпилированного исходного кода для данного ядраА нам нужен каталог для скомпилированных исходников, а именно /usr/src/linux-headers-4.4.0-135-generic/ .
Поиск заголовочных файлов для драйверного кода осуществляется именно из этого каталога.
Параметр M=$(PWD) указывает, что вывод от компиляции драйвера попадает именно в текущий каталог.
Наконец, вот команда obj-m := hello.o , предназначенная для загрузки hello.o в hello.ko , а ko – это файл из пространства ядра.
❯ Загружаем драйвер в ядро
Вот некоторые системные команды, которые нам при этом понадобятся:
- Lsmod : просмотр модуля ядра, загружаемого в настоящий момент.
- Insmod : загрузка модуля ядра с последующим требованием прав администратора.
- Rmmod : удаление модуля.
# insmod hello.ko // Load the hello.ko module into the kernel # rmmod hello // Remove the hello module from the kernelВ старых версиях ядра таким же методом загружалось и удалялось само ядро, но в новых версиях ядра Linux здесь добавляется верификация модуля. Вот в какой ситуации мы сейчас находимся:
# insmod hello.ko insmod: ERROR: could not insert module hello.ko: Required key not availableС точки зрения безопасности актуальное ядро предполагает, что данный модуль не вызывает доверия. Чтобы этот модуль мог быть загружен, его нужно подписать доверенным сертификатом.
Это можно сделать двумя способами:
- Войти в BIOS и отключить безопасную загрузку в UEFI.
- Добавить в ядро самоподписываемый сертификат, и именно с его помощью подписать модуль драйвера (подробнее об этом написано тут).
❯ View the Results

❯ Добавляем файлы устройств под /dev
Once again, we firstly provide the code, and then explain the example code.
#include #include #include /* printk() */ #include /* kmalloc() */ #include /* everything. */ #include /* error codes */ #include /* size_t */ #include /* O_ACCMODE */ #include #include /* copy_*_user */ MODULE_LICENSE("Dual BSD/GPL"); MODULE_AUTHOR("Hcamael"); int scull_major = 0; int scull_minor = 0; int scull_nr_devs = 4; int scull_quantum = 4000; int scull_qset = 1000; struct scull_qset < void **data; struct scull_qset *next; >; struct scull_dev < struct scull_qset *data; /* Pointer to first quantum set. */ int quantum; /* The current quantum size. */ int qset; /* The current array size. */ unsigned long size; /* Amount of data stored here. */ unsigned int access_key; /* Used by sculluid and scullpriv. */ struct mutex mutex; /* Mutual exclusion semaphore. */ struct cdev cdev; /* Char device structure. */ >; struct scull_dev *scull_devices; /* allocated in scull_init_module */ /* * Follow the list. */ struct scull_qset *scull_follow(struct scull_dev *dev, int n) < struct scull_qset *qs = dev->data; /* Allocate the first qset explicitly if need be. */ if (! qs) < qs = dev->data = kmalloc(sizeof(struct scull_qset), GFP_KERNEL); if (qs == NULL) return NULL; memset(qs, 0, sizeof(struct scull_qset)); > /* Then follow the list. */ while (n--) < if (!qs->next) < qs->next = kmalloc(sizeof(struct scull_qset), GFP_KERNEL); if (qs->next == NULL) return NULL; memset(qs->next, 0, sizeof(struct scull_qset)); > qs = qs->next; continue; > return qs; > /* * Data management: read and write. */ ssize_t scull_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos) < struct scull_dev *dev = filp->private_data; struct scull_qset *dptr; /* the first listitem */ int quantum = dev->quantum, qset = dev->qset; int itemsize = quantum * qset; /* how many bytes in the listitem */ int item, s_pos, q_pos, rest; ssize_t retval = 0; if (mutex_lock_interruptible(&dev->mutex)) return -ERESTARTSYS; if (*f_pos >= dev->size) goto out; if (*f_pos + count > dev->size) count = dev->size - *f_pos; /* Find listitem, qset index, and offset in the quantum */ item = (long)*f_pos / itemsize; rest = (long)*f_pos % itemsize; s_pos = rest / quantum; q_pos = rest % quantum; /* follow the list up to the right position (defined elsewhere) */ dptr = scull_follow(dev, item); if (dptr == NULL || !dptr->data || ! dptr->data[s_pos]) goto out; /* don't fill holes */ /* read only up to the end of this quantum */ if (count > quantum - q_pos) count = quantum - q_pos; if (raw_copy_to_user(buf, dptr->data[s_pos] + q_pos, count)) < retval = -EFAULT; goto out; >*f_pos += count; retval = count; out: mutex_unlock(&dev->mutex); return retval; > ssize_t scull_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos) < struct scull_dev *dev = filp->private_data; struct scull_qset *dptr; int quantum = dev->quantum, qset = dev->qset; int itemsize = quantum * qset; int item, s_pos, q_pos, rest; ssize_t retval = -ENOMEM; /* Value used in "goto out" statements. */ if (mutex_lock_interruptible(&dev->mutex)) return -ERESTARTSYS; /* Find the list item, qset index, and offset in the quantum. */ item = (long)*f_pos / itemsize; rest = (long)*f_pos % itemsize; s_pos = rest / quantum; q_pos = rest % quantum; /* Follow the list up to the right position. */ dptr = scull_follow(dev, item); if (dptr == NULL) goto out; if (!dptr->data) < dptr->data = kmalloc(qset * sizeof(char *), GFP_KERNEL); if (!dptr->data) goto out; memset(dptr->data, 0, qset * sizeof(char *)); > if (!dptr->data[s_pos]) < dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL); if (!dptr->data[s_pos]) goto out; > /* Write only up to the end of this quantum. */ if (count > quantum - q_pos) count = quantum - q_pos; if (raw_copy_from_user(dptr->data[s_pos]+q_pos, buf, count)) < retval = -EFAULT; goto out; >*f_pos += count; retval = count; /* Update the size. */ if (dev->size < *f_pos) dev->size = *f_pos; out: mutex_unlock(&dev->mutex); return retval; > /* Beginning of the scull device implementation. */ /* * Empty out the scull device; must be called with the device * mutex held. */ int scull_trim(struct scull_dev *dev) < struct scull_qset *next, *dptr; int qset = dev->qset; /* "dev" is not-null */ int i; for (dptr = dev->data; dptr; dptr = next) < /* all the list items */ if (dptr->data) < for (i = 0; i < qset; i++) kfree(dptr->data[i]); kfree(dptr->data); dptr->data = NULL; > next = dptr->next; kfree(dptr); > dev->size = 0; dev->quantum = scull_quantum; dev->qset = scull_qset; dev->data = NULL; return 0; > int scull_release(struct inode *inode, struct file *filp) < printk(KERN_DEBUG "process %i (%s) success release minor(%u) file\n", current->pid, current->comm, iminor(inode)); return 0; > /* * Open and close */ int scull_open(struct inode *inode, struct file *filp) < struct scull_dev *dev; /* device information */ dev = container_of(inode->i_cdev, struct scull_dev, cdev); filp->private_data = dev; /* for other methods */ /* If the device was opened write-only, trim it to a length of 0. */ if ( (filp->f_flags & O_ACCMODE) == O_WRONLY) < if (mutex_lock_interruptible(&dev->mutex)) return -ERESTARTSYS; scull_trim(dev); /* Ignore errors. */ mutex_unlock(&dev->mutex); > printk(KERN_DEBUG "process %i (%s) success open minor(%u) file\n", current->pid, current->comm, iminor(inode)); return 0; > /* * The "extended" operations -- only seek. */ loff_t scull_llseek(struct file *filp, loff_t off, int whence) < struct scull_dev *dev = filp->private_data; loff_t newpos; switch(whence) < case 0: /* SEEK_SET */ newpos = off; break; case 1: /* SEEK_CUR */ newpos = filp->f_pos + off; break; case 2: /* SEEK_END */ newpos = dev->size + off; break; default: /* can't happen */ return -EINVAL; > if (newpos < 0) return -EINVAL; filp->f_pos = newpos; return newpos; > struct file_operations scull_fops = < .owner = THIS_MODULE, .llseek = scull_llseek, .read = scull_read, .write = scull_write, // .unlocked_ioctl = scull_ioctl, .open = scull_open, .release = scull_release, >; /* * Set up the char_dev structure for this device. */ static void scull_setup_cdev(struct scull_dev *dev, int index) < int err, devno = MKDEV(scull_major, scull_minor + index); cdev_init(&dev->cdev, &scull_fops); dev->cdev.owner = THIS_MODULE; dev->cdev.ops = &scull_fops; err = cdev_add (&dev->cdev, devno, 1); /* Fail gracefully if need be. */ if (err) printk(KERN_NOTICE "Error %d adding scull%d", err, index); else printk(KERN_INFO "scull: %d add success\n", index); > void scull_cleanup_module(void) < int i; dev_t devno = MKDEV(scull_major, scull_minor); /* Get rid of our char dev entries. */ if (scull_devices) < for (i = 0; i < scull_nr_devs; i++) < scull_trim(scull_devices + i); cdev_del(&scull_devices[i].cdev); >kfree(scull_devices); > /* cleanup_module is never called if registering failed. */ unregister_chrdev_region(devno, scull_nr_devs); printk(KERN_INFO "scull: cleanup success\n"); > int scull_init_module(void) < int result, i; dev_t dev = 0; /* * Get a range of minor numbers to work with, asking for a dynamic major * unless directed otherwise at load time. */ if (scull_major) < dev = MKDEV(scull_major, scull_minor); result = register_chrdev_region(dev, scull_nr_devs, "scull"); >else < result = alloc_chrdev_region(&dev, scull_minor, scull_nr_devs, "scull"); scull_major = MAJOR(dev); >if (result < 0) < printk(KERN_WARNING "scull: can't get major %d\n", scull_major); return result; >else < printk(KERN_INFO "scull: get major %d success\n", scull_major); >/* * Allocate the devices. This must be dynamic as the device number can * be specified at load time. */ scull_devices = kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL); if (!scull_devices) < result = -ENOMEM; goto fail; >memset(scull_devices, 0, scull_nr_devs * sizeof(struct scull_dev)); /* Initialize each device. */ for (i = 0; i < scull_nr_devs; i++) < scull_devices[i].quantum = scull_quantum; scull_devices[i].qset = scull_qset; mutex_init(&scull_devices[i].mutex); scull_setup_cdev(&scull_devices[i], i); >return 0; /* succeed */ fail: scull_cleanup_module(); return result; > module_init(scull_init_module); module_exit(scull_cleanup_module);❯ Классификация драйверов
Драйверы делятся на три категории: символьные устройства, блочные устройства и сетевые интерфейсы. В вышеприведённом коде было разобрано символьное устройство, а обсуждение двух других категорий выходит за рамки этой статьи.
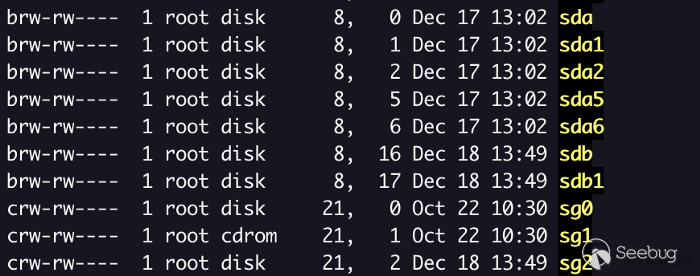
Как было показано выше, brw-rw— — строка о правах доступа для блочных устройств начинается с буквы «b», а для символьных устройств начинается с буквы «c».
❯ О старших и младших числах
Старшее число отличает один драйвер от всех остальных. В принципе, если старшее число у устройств совпадает, это означает, что они управляются одним и тем же драйвером.
В одном каталоге drive может быть создано множество устройств, и отличаться они будут младшими числами. Вместе старшее и младшее число характеризуют устройство, управляемое драйвером (как показано выше).
brw-rw---- 1 root disk 8, 0 Dec 17 13:02 sda brw-rw---- 1 root disk 8, 1 Dec 17 13:02 sda1Старшее число аппаратуры sda и sda1 это 8, а младших чисел здесь два: у одного устройства 0, а у другого 1.
❯ Как драйвер предоставляет API
Я привык считать, что /dev/xxx – это интерфейс, предоставляемый файлом, а в Linux «всё – файл». Поэтому, оперируя драйвером, мы, фактически, оперируем файлом, и именно в драйвере определяется define/open/read/write… что произойдёт с /dev/xxx . Любые мыслимые действия с API драйвера – это операции над файлами.
Какие операции над файлами здесь присутствуют? Все они определяются в структуре file_operations в заголовочном файле ядра .
В коде, приведённом выше в качестве примера:
struct file_operations scull_fops = < .owner = THIS_MODULE, .llseek = scull_llseek, .read = scull_read, .write = scull_write, .open = scull_open, .release = scull_release, >;Я определяю структуру и присваиваю её. Не считая owner, значения всех остальных членов – это указатели функций.
Затем я применяю cdev_add , чтобы зарегистрировать структуру для файловых операций под каждый драйвер, это делается в функции scull_setup_cdev .
Например, совершая операцию “open” (открыть) с устройством под управлением драйвера, я выполняю функцию scull_open, что эквивалентно «перехвату» функции open в системном вызове.
❯ Как сгенерировать нужное нам устройство под /dev
Скомпилировав вышеприведённый код, получим scull.ko , затем подпишем его и, наконец, загрузим в ядро при помощи insmod .
Проверим, удачно ли он загрузился:
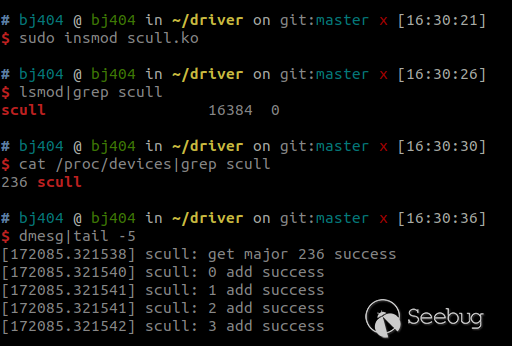
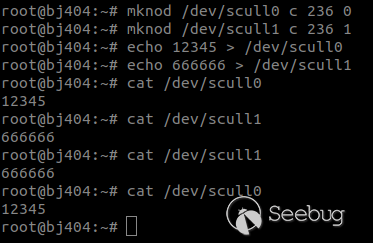
Да, драйвер устройства загрузился успешно, но он не создаёт файла устройства в каталоге /dev. Необходимо вручную воспользоваться mknod для связывания устройства:
❯ Итоги
В данном примере мы не совершали никаких операций с конкретным устройством, а просто воспользовались kmalloc , и с его помощью применили блок памяти в пространстве ядра.
Далее не буду вдаваться в детали о коде, все их можно уточнить, погуглив информацию или изучив заголовочные файлы.
В этой статье я хотел поделиться с вами, как самостоятельно научиться разрабатывать драйвера: сначала читать книги, чтобы усвоить базовые концепции, а затем искать информацию по конкретным деталям, когда дойдёт дело до практического применения.
Например, я не знаю, какой API может предоставить драйвер. Всё, что мне нужно знать – что такой API ограничивается файловыми операциями. На данный момент мне понадобятся только операциями open , close , read и write . Как делаются другие операции с файлами – можно уточнить при необходимости.
Ссылки
- github.com/jesstess/ldd4
- raw.githubusercontent.com/Hcamael/Linux_Driver_Study/master/hello.c
- jin-yang.github.io/post/kernel-modules.html
- raw.githubusercontent.com/Hcamael/Linux_Driver_Study/master/scull.c
- raw.githubusercontent.com/torvalds/linux/master/include/linux/fs.h
Как написать драйвер для linux
Что такое драйвер устройства. Создание драйвера устройства — дело достаточно трудоемкое. Запись на жесткий диск требует помещения определенных цифровых данных в определенное место, ожидания ответа на запрос о готовности жесткого диска, затем аккуратной пересылки информации. Запись на флопповод проходит еще сложнее — нужен постоянный контроль на текущим состоянием дискеты. Вместо помещения кода каждого отдельного приложения управляющего устройством, вы разделяете код между приложениями. Вам следует защитить этот код от других пользователей и использующих его программ. Если вы верно сделали это, то вы можете без смены приложений подключать или убирать устройства. Более того, вы должны иметь возможности ОС — загрузить вашу программу в память и запустить ее. Так что ОС, в сущности, — это набор привилегированных, общих и частных функций или функций аппаратного обеспечения низкого уровня,функций работы с памятью и функций контроля. Все версии UNIX имеет абстрактный способ считывания и записи на устройство. Действующие устройства представляются в виде файлов, так что одинаковые вызовы ( read(), write() и т.п.) могут быть использованы и как устройства и как файлы. Внутри ядра существует набор функций, отмеченных как файлы, вызываемые при запросе для ввода/вывода на файлы устройств, каждый из которых представляет свое устройство. Всем устройствам, контролируемым одним драйвером, дается один и тот же основной номер, и различные подномера. Эта глава описывает, как написать любой из допускаемых в Linux типов драйверов устройств : символьных, блочных, сетевых и драйверов SCSI. Она описывает, какие функции вы должны написать, как инициализировать драйверы и эффективно выделять под них память, какие функции встроены в Linux для упрощения деятельности такого рода. Создание драйвера устройств для Linux оказывается более простым чем мнится на первый взгляд, ибо оно включает в себя написание новой функции и определение ее в системе переключения файлов(VFS). Тем самым, когда доступно устройство, присущее вашему драйверу, VFS вызывает вашу функцию. Однако, вы должны помнить, что драйвер устройства является частью ядра. Это означает, что ваш драйвер запускается на уровне ядра и обладает большими возможностями : записать в любую область памяти, повредить ваш монитор или разбить вам унитаз в случае, если ваш компьютер управляет сливным баком. Также ваш драйвер будет запущен в режиме работы с ядром, а ядро Linux, как и большинство ядер UNIX, не имеет средств принудительного сброса. Это означает, что если ваш драйвер будет долго работать, не давая при этом работать другим программам, ваш компьютер может «зависнуть «. Нормальный пользовательский режим с последовательным запуском не обращается к вашему драйверу. Если вы решили написать драйвер устройства, вы должны внимательно прочитать всю эту главу, однако, нет гарантий, что эта глава не содержит ошибок, и вы не сломаете ваш компьютер, даже если будете следовать всем инструкциям. Единственный совет — сохраняйте информацию перед запуском драйвера. Драйверы пользовательского уровня. Не всегда нужно писать драйвер для устройства, особенно если за устройством следит всего одно приложение. Наиболее полезным примером этому является устройство карты памяти, однако вы можете сделать карту памяти с помощью устройств ввода/вывода (доступ к устройствам осуществляется с помощью функций inpb() и outpb()). Если вы работаете в режиме superuser, вы можете использовать функцию mmap для того, чтобы поместить вашу функцию в какую-то область памяти. С помощью этой процедуры вы сможете весьма просто работать с адресами памяти, как с обычными переменными. Если ваш драйвер использует прерывание, то вам придется работать внутри ядра, так как не существует других путей для прерываний обычных пользовательских процессов. В проекте DOSEMU однако, есть Простейший Генератор прерываний — SIG, но он работает недостаточно быстро, как это можно было ожидать от последней версии DOSEMU. Прерывание — это жестко определенная процедура. Также вы при установке своего аппаратного обеспечения вы определяете линию IRQ для физического сигнала прерываний, возникающего, когда устройство обращается к драйверу. Это происходит, когда устройство пересылает или запрашивает информацию, а также при обнаружении каких-либо исключительных ситуаций, о которых должен знать драйвер. Для обработки прерываний в ядре и для обработки сигналов на пользовательском уровне используется одна и та же структура данных — sigaction. Таким образом, где сигналы аппаратных прерываний доставляются ядру точно так же, как системные сигналы на уровне пользовательского обеспечения. Если ваш драйвер должен обращаться к нескольким процессам сразу или управлять общими ресурсами, тогда вы должны написать драйвер устройства, и драйвер пользовательского уровня вам не подходит.
2.2.1 Пример — vgalib.
Хорошим примером драйвера пользовательского уровня является библиотека vgalib. Стандартные функции read() и write() не подходят для написания действительно быстрого графического драйвера, и поэтому существует библиотека функций, которая концептуально работает как драйвер устройства, но на пользовательском уровне. Все функции, которые используют ее, должны запускать setuid, так как она использует системную функцию ioperm(). Функции, которые не запускают setuid, обладают возможностью записи в /DEV/MEM, если у вас есть группы mem или kmem, которые позволяют это, но только корневые процессы могут запускать ioperm(). Есть несколько портов ввода/вывода, относящихся к графике VGA. Vgalib дает им символические имена с помощью #define, и далее используют ioperm() для разрешения функции правильного прочтения и записи в эти порты.
if (ioperm(CRT_IC, 1, 1)) < printf("VGAlib: can't get I/O permission \n"); exit(-1); >ioperm(CRT_IM, 1, 1); ioperm(ATT_IW, 1, 1); [--]
Это требует лишь однократной проверки, так как единственной причиной нефункционирования ioperm() может быть обращение к ней не в статусе superuser или во время смены статуса. /\
\/ После вызова этой функции разрешается использование inb и outb инструкций, однако лишь с определенными портами. Эти инструкции могут быть доступны без использования прямого ассемблерного кода , но работают они лишь в случае компиляции с параметром optimization on и с ключом -0?. Для более подробных сведений читай .
После обращения в порты ввода вывода vgalib засылает информацию в область ядра следующим образом :
/* open /dev/mem */ if ((mem_fd = open(«/dev/mem», 0_RDWR) ) < 0) < prntf( "VGAlib: can' t open /dev/mem \n"); exit (-1); >/* mmap graphics memory */ if ((graph_mem = malloc(GRAPH*SIZE + (PAGE-SIZE-1))) == NULL) < printf( " VGAlib: allocation error \n "); exit (-1); >if ((unsigned long)graph_mem % PAGE_SIZE) graph_mem += PAGE_SIZE — ((unsigned long)graph_mem % PAGE_SIZE); graph_mem = (unsigned char *)mmap( (caddr_t)graph_mem, GRAPH_SIZE, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_FIXED, mem_fd, GRAPH_BASE ); if ((long)graph_mem
В начале программа открывает /dev/mem, затем выделят достаточное количество памяти для распределения на страницу, затем меняет карту памяти.
GRAPHSIZE - размер памяти vga. GRAPHBASE - адрес начала памяти VGA в /dev/mem.
Затем, записывая в адрес возвращаемый mmap(), программа осуществляет запись в память экрана.
2.2.2 Пример : Преобразование мыши.
Если вы хотите написать драйвер, работающий так же, как и драйвер на уровне ядра, но не находящийся в его области, то вы можете создать fifo (буфер — first in, first out). Обычно он помещается в директорию /dev (во время нефункционирования) и ведет себя как подключенное устройство. В частности, это используется когда вы используете мышь типа PS/2 и хотите запустить XFree86. Вы должны создать fifo, называемый /dev/mouse, и запустить программу mconv, которая, читая сигналы мыши PS/2 из /dec/psaux, пишет эквивалентные сигналы microsoft mouse в /dev/mouse. В этом случае XFree86 будет читать сигналы из /dev/mouse и функционировать также как и при подключенной microsoft mouse.
2.3 Основы драйверов устройств.
Мы будем полагать, что вы не хотите писать драйвер на пользовательском уровне, а желаете работать непосредственно в области ядра. В таком случае вам придется иметь дело с файлами .с и .h. Мы будем условно обозначать ваши труды как foo.c и foo.h.
2.3.1 Область имени (именная область).
Первое что вы должны сделать при написании драйвера — назвать устройство. Имя должно выть кратким — строка из двух — трех символов. К примеру, параллельные устройства — «lp», дисководы «fd», диски SCSI — «sd». Создавая ваш драйвер, называйте функции в нем с первыми тремя буквами избранной строки в имени. Так как мы называем его foo — функции в нем соответственно — foo_read и foo_write.
2.3.2 Выделение памяти.
- Память выделяется кусками размером степени 2, за исключением кусков больше 128 байтов, размер коих равен степени 2 за вычетом части под метку о размере. Вы можете запросить произвольный размер, однако это будет неэффективно, так как 31 байтового об’екта, к примеру, выделяется 32 байтовый кусок. Общий предел выделяемой памяти 131056 байт.
- В качестве второго аргумента kmalloc() использует приоритет. Он используется в качестве аргумента функции get_free_page(), где он используется в качестве числа определяющего момент возврата. Обычно используемый приоритет — GFP_KERNEL. Если функция может быть вызвана с помощью прерывания используйте GFP_ATOMIC и приготовьтесь к тому, что функция может не работать. Это происходит из-за того, что при использовании GFP_KERNEL kmalloc() может не быть активным в любой момент времени, что не возможно при прерывании. Можно так же использовать опцию GFP_BUFFER, которая используется для выделения ядром области буфера. В драйверах устройств она не используется.
См 2.6 для получения более подробной информации о kmalloc(), kfree() и о других полезных функциях.
-
! Существует возможность выделения виртуальной памяти с помощью vmalloc(), однако это будет описано лишь в главе VMM во время ее написания. В данный момент вам придется изучать это самостоятельно.!
2.3.3 Символьные и блочные устройства.
Существует два типа устройств в системах UN*X — символьные и блочные устройства. Для символьных устройств не предусмотрено буфера, в то время как блочные устройства имеют доступ лишь через буферную память. Блочные устройства должны быть равнодоступными, а для символьных это не обязательно, хотя и возможно. Файловая система может работать лишь в случае, если она является блочным устройством.
Общение с символьными устройствами осуществляется с помощью функций foo_read() и foo_write(). Функции foo_read() и foo_write() не могут останавливаться в процессе деятельности, поэтому блочные устройства даже не требуют использования этих функций, а вместо этого используют специальный механизм, называемый «strategy routine» — стратегическая подпрограмма. Обмен информацией происходит при помощи функций bread(), breada(), bwrite(). Эти функции, просматривая буферную память, могут вызывать «strategy routine» в зависимости от того, готово устройство или нет к приему информации (в случае записи — буфер переполнен), или же присутствует ли информация в буфере (в случае чтения ).Запрос текущего блока из буфера может быть асинхронен чтению — breada() может вначале определить график передачи информации, а затем заняться непосредственно передачей. Далее мы представим полный обзор буферной памяти(кэш). Исходные тексты для символьных устройств содержатся в /kernel/chr_drv, исходники для блочных — /kernel/blk_drv. Для простоты чтения интерфейсы у них довольно просты, за исключением функций записи и чтения. Это происходит из за определения вышеописанной «strategy routine» в случае блочных устройств и соответствующего ему определения foo_read и foo_write() для символьных устройств. Более подробно об этом в 2.4.1 и 2.5.1.
2.3.4. Прерывание или поочередное опрашивание устройств ?
Аппаратное обеспечение работает достаточно медленно. Это определяется временем получения информации, в момент получения которой процессор не занят, и находится в состоянии ожидания. Для того чтобы вывести процессор из режима работа — ожидание, вводятся ! прерывания ! — процессы, предназначенные для прерывания конкретных операций и предоставления ОС задачи по выполнению которой последняя без потерь возвращается в исходное положение.
В идеале все устройства должны обрабатываться с использованием прерываний, однако на PC и совместимых прерывания используются лишь в некоторых случаях, так что некоторые драйверы вынуждены проверять аппаратное обеспечение на готовность к приему информации.
Так же существуют аппаратные средства ( дисплей с распределенной памятью ) работающие быстрее остальных частей компьютера. В таком случае драйвер, управляемый прерываниями будет выглядеть нелепо.
В Linux cуществуют как драйверы, управляемые прерываниями так и драйверы, не использующие прерываний, и оба типа драйверов могут отключаться или включаться во время работы подпрограммы. В частности, «lp» устройство ждет готовности принтера к принятию информации и, в случае отказа, отключается на какой-то промежуток времени, чтобы затем попытаться вновь.
Это улучшает показатели системы. Однако, если вы имеете параллельную карту, поддерживающую прерывания, драйвер, используя ее, увеличит скорость работы. Существуют несколько программных отличий между драйвером, управляемым прерываниями и ждущими драйверами. Для осознания этих отличий вы должны представлять себе устройство системных вызовов UN*X. Ядро — неразделяемая задача под UN*X. В таком случае в каждом процессе находится копия ядра.
Когда процесс запускает системный запрос, он не передает управление другому процессу, а скорее меняет режим исполнения на режим ядра. В этом режиме он запускает он запускает защищенный от ошибок код ядра.
В режиме ядра процесс все еще имеет доступ к пространству памяти пользователя, как и до смены режима, что достигается с помощью макросов: get_fs_*() и memcpy_fromfs(), осуществляющих чтение из памяти, и put_fs_*() и memcpy_tofs(), осуществляющих запись. Так как процесс переходит из одного режима в другой, вопроса о помещении информации в определенную область памяти не возникает.
-
! Об’ясните, как работает verify_area(), который используется лишь в случае необусловленной защиты от записи во время работы в режиме ядра для проверки области памяти, принимающей информацию.!
Вместо отслеживания прерываний драйвер может выделять временную область для информации.Когда часть драйвера, управляемая прерыванием, заполняет эту область, она замораживает процесс,списывает информацию в пространство памяти пользователя.В блочных устройствах драйвер, создающий эту временную область, снабжен механизмом кеширования, что не предусмотрено в символьных устройствах.
2.3.5. Механизмы замораживания и активизации.
Начнем с об»яснения механизма заморозки и его использования. Это включает в себя то, что процесс, будучи в замороженном состоянии (не функционирует), в какой — то момент времени можно активизировать, а затем опять заморозить (приостановить )!
Возможно, лучший способ понять механизм замораживания и активизации в Linux — изучение исходного текста функции __sleep_on(), использующейся для описания функций sleep_on() и interruptible_sleep_on().
static inline void __sleep_on(struct wait_queue **p, int state) < unsigned long flags; struct wait_queue wait = < current, NULL >; if (!p) return; if (current == task[0]) panic ( "task[0] trying to sleep"); current->state = state; add_wait_queue(p, &wait); save_flags(flags); sti(); schedule(); remove_wait_queue(p, &wait); restore_flags(flags); >
wait_queue — циклический список указателей на структуры задач, определенные в как
struct wait_queue < struct task_struct * task; struct wait_queue * next; >;
Меткой состояния процесса в данном случае является или TASK_INTERRAPTIBLE, или TASK_UNINTERRAPTIBLE, в зависимости от того, может ли заморозка процесса прерываться такими вещами, как системные вызовы.Вообще говоря, механизм заморозки необходимо прерывать лишь в случае медленных устройств, так как такое устройство может приостановить на достаточно длительный срок работу всей системы. add_wait_queue() отключает прерывание, создает новый элемент структуры wait_queue, определенной в начале функции как список p.Затем она восстанавливает в исходное положение метку о состоянии процесса.
save_flags() — макрос, сохраняющий флаги процессов, задаваемых в виде аргументов. Это делается для фиксации предыдущего положения метки состояния процесса. Таким образом, функция restore_flags() может восстанавливать положение метки.
Функция sti() затем разрешает прерывания, а schedule() выбирает для выполнения следующий процесс. Задача не может быть избранной для выполнения, пока метка не будет находиться в состоянии TASK_RUNNING.
Это достигается с помощью функции wake_up(),примененной к задаче, ждущей в структуре p своей очереди.
Затем процесс исключает себя из wait_queue,восстанавливает состояние положения прерывания с помощью restore_flags() и завершает работу.
Для определения очередности запросов на ресурсы в структуру wait_queue введены указатели на задачи, использующие этот ресурс. В таком случае, когда несколько задач запрашивают один и тот же ресурс одновременно, задачи, не получившие доступ к ресурсу, замораживаются в wait_queue.По окончании работы текущей задачи активизируется следующая задача из wait_queue,относящаяся к этому ресурсу с помощью функций wake_up() или wake_up_interruptible().
Если вы хотите понять последовательность разморозки задач или более детально изучить механизм заморозки, вам нужно купить одну из книг, предложенных в приложении А и просмотреть !mutual exclusion! и !deadlock!.
2.3.5.1.Усложненный механизм заморозки.
Если механизм sleep_on()/wake_up() в Linux не удовлетворяет вашим требованиям, вы можете усовершенствовать его. В качестве примера тому можете посмотреть серийный драйвер устройства (/kernel/chr_drv/serial.c), функцию
block_til_ready(), которая представляет собой несколько измененные add_wait_queue() и schedule()
2.3.6. VFS.
VFS — Virtual Filesystem Switch (Система виртуального переключения файловой системы ) — механизм, позволяющий Linux поддерживать сразу несколько файловых систем. В первой версии Linux доступ к файловой системе осуществляется через подпрограммы, работающие с файловой системой minix. Для обеспечения возможности работы с другой файловой системой ее вызовы переопределяются как функции знакомой Linux системы файлов. Это делается с помощью программы, содержащей структуру указателей на функции, представляющие все возможные действия с файловой системой. Вызывает интерес структура file_operations :
From /usr/include/linux/fs.h: struct file_operations < int (*lseek) (struct inode *, struct file *, off_t, int); int (*read) (struct inode *, struct file *, char *, int); int (*write) (struct inode *, struct file *, char *, int); int (*readdir) (struct inode *, struct file *, struct dirent *, int count); int (*select) (struct inode *, struct file *, int, select_table *); int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned int); int (*mmap) (struct inode *, struct file *, unsigned long, size_t, int, unsigned long); int (*open) (struct inode *, struct file *); void (*release) (struct inode *, struct file *); >;
Эта структура содержит список функций, нужных для создания драйвера.
2.3.6.1. Функция lseek().
Функция вызывается, когда в специальном файле, представляющем устройство, появляется системный вызов lseek().Это функция перехода текущей позиции на заданное смещение.Ей задается четыре аргумента :
struct inode * inode - Указатель на структуру inode для этого устройства. struct file * file - Указатель на файловую структуру для данного устройства. off_t offset - Смещение от ! origin !. int origin 0 = смещение от начала. 1 = смещение от текущей позиции. 2 = смещение от конца.
lseek() возвращает -errno в случае ошибки или положительное смещение после выполнения.
Если lseek() отсутствует, ядро автоматически изменяет элемент file -> f_pos.При origin = 2 в случае file -> f_inode = NULL ему присваивается значение -EINVAL,иначе file -> fpos принимает значение file -> f_inode -> i_size + offset.Поэтому в случае возврата ошибки устройства системным вызовом lseek() вы должны использовать функцию lseek для определения этой ошибки.
2.3.6.2. Функции read() и write().
Функции read() и write() осуществляют обмен информацией с устройством, посылая на него строку символов.Если функции read() и write() отсутствуют в структуре file_operatios, определенной в ядре, то в случае символьного устройства одноименные вызовы будут возвращать -EINVAL.В случае блочных устройств функции не определяются, так как VFS будет общаться с устройством через механизм обработки буфера, вызывающий «strategy routine». См. 2.5.2 для более подробного изучения устройства механизма работы с буфером.
- struct inode * inode
— Указатель на структуру inode специального файла устройства, доступного для использования непосредственно пользователем. В частности, вы можете найти подномер файла при помощи конструкции unsigned int minor = MINOR(inode -> i_rdev); Определение макроса MINOR находится в , так же, как и масса других нужных определений. Для получения более подробной информации см. fs.h. Более подробное описание представлено в 2.6. Для определения типа файла может быть использована inode -> i_mode. - struct file * file
— Указатель на файловую структуру этого устройства. - char * buf
— Буфер символов для чтения и записи. Он расположен в пространстве памяти пользователя, и доступ к нему осуществляется с помощью макросов get_fs*(), put_fs*() и memcpu*fs(), описанных в 2.6. Пространство памяти пользователя не доступно во время прерывания, так что если ваш драйвер управляется прерываниями, вам придется списывать содержание буфера в очередь (queue). - int count
— Число символов, записанных или читаемых из buf. count — размер буфера, так что с помощью него легко определить последний символ buf, даже если буфер не заканчивается NULL.
2.3.6.3 Функция readdir().
Еще один элемент структуры file_operations, используемый для описания файловых систем так же, как драйверы устройств. Функция не нуждается в предопределении. Ядро возвращает -ENOTDIR в случае вызова readdir() из специального файла устройства.
2.3.6.4 Функция select().
- struct inode * inode
— Указатель на структуру inode устройства. - struct file * file
— Указатель на файловую структуру устройства. - int sel_type
— Тип совершаемого действия
SEL_IN — чтение
SEL_OUT — запись
SEL_EX — удаление - select_table * wait
— Если wait = NULL, функция select() проверяет, готово ли устройство, и возвращается в случае отсутствия готовности. Если wait не равен NULL, select() замораживает процесс и ждет, пока устройство не будет готово. Функция select_wait() делает то же, что и select() при wait = NULL.
2.3.6.5 Функция ioctl().
- struct inode * inode
— Указатель на inode структуру данного устройства; - struct file * file
— Указатель на файловую структуру устройства; - unsigned int cmd
— Команда, над которой осуществляется контроль; - unsigned int arg
— Это аргумент для команды, определяется пользователем. В случае, если он вида (void *), он может быть использован как указатель на область пользователя, обычно находящуюся в регистре fs. - Возвращаемое значение :
-errno в случае ошибки, все другие значения определяются пользователем.
- FIOCLEX 0x5451
Устанавливает бит «закрытие для запуска» - FIONCLEX 0x5450
Очищает бит «закрытие для запуска» - FIONBIO 0x5421
Если аргумент не равен 0, устанавливает O_NONBLOCK, иначе очищает O_NONBLOCK. - FIOASYNC 0x5421
Если аргумент не равен 0, устанавливает O_SYNC, иначе очищает O_SYNC. Пока еще не описано, но для полноты вставлено в ядро.
Помните, что вам надо учитывать эти четыре номера при написании своих ioctl(), так как они могут быть несовместимы между собой, откуда в программе может возникнуть тяжело обнаруживаемая ошибка.
2.3.6.6.Функция mmap().
- struct inode *inode
— Указатель на inode - struct file *file
— Указатель на файловую структуру - unsigned long addr
— Начальный адрес блока, используемого mmap() - size_t len — Общая длина блока.
- int prot — Принимает значения:
PROT_READ читаемый кусок
PROT_WRITE перезаписываемый кусок
PROT_EXEC кусок, доступный для запуска
PROT_NONE недоступный кусок - unsigned long off
— Внутрифайловое смещение, от которого производится перестановка. Этот адрес будет переставлен на адрес addr.
[В описании распределения памяти описано, как функции интерфейса Менеджера виртуальной памяти могут быть использованы mmap().]
2.3.6.7. Функции open() и release().
- struct inode *inode
— Указатель на inode - struct file *file
— Указатель на файловую структуру
Функция вызывается после открытия специальных файлов устройств. Она является механизмом слежения за последовательностью выполняемых действий. Если устройством пользуется лишь один процесс, функция open() закроет устройство любым доступным в данный момент способом, обычно устанавливая нужный бит в положение «занято». Если процесс уже использует устройство (бит уже установлен), open() возвращает -EBUSY.
Если же устройство необходимо нескольким процессам, эта функция обладает возможностью любой очередности.
Если устройство не существует, open() вернет -ENODEV.
Функция release() вызывается лишь тогда, когда процесс закрывает последний файловый дескриптор. release() может переустанавливать бит «занято». После вызова release(), вы можете очистить куски выделенной kmalloc() памятью под очереди процессов.
2.3.6.8 Функция init().
Эта функция не входит в file_operations но вам придется использовать ее, так как именно она регистрирует file_operations с содержащейся там VFS — — без нее запросы на драйвер будут находится в беспорядочном состоянии. Эта функция запускается во время загрузки и самоконфигурирования ядра. init() получает переменную с адресом конца используемой памяти. Затем она обнаруживает все устройства, выделяет память, исходя из их общего числа, сохраняет полезные адреса и возвращает новый адрес конца используемой памяти. Функцию init() вы должны вызывать из определенного места. Для символьных устройств это /kernel/cdr_dev/mem.c. В общем случае функции надо задавать лишь переменную memory_start.
- int major — основной номер устройства.
- srtring name — имя устройства.
- адрес #DEVICE#_fops структуры file_operations.
После окончания работы функции, файлы становятся доступными для VFS, и она по надобности переключает устройство с одного вызова на другой.
Функция init() обычно выводит сведения о найденном аппаратном обеспечении и информацию о драйвере.Это делается с использованием функции printk().
2.4 Cимвольные устройства.
2.4.1. Инициализация.
- int major — основной номер драйвера.
- char *name — имя драйвера оно может быть изменено, но не имеет практического применения.
- struct file_operations *fops — адрес определенной вами file_operations.
- Возвращаемые значения : 0 — в случае если указанным основным номером ни одно устройство более не обладает. не 0 в случае некорректного вызова.
2.4.2 Прерывания или последовательный вызов ?
В драйверах, не использующих прерывания, легко пишутся функции foo_read() и foo_write() :
static int foo_write(struct inode * inode, struct file * file, char * buf, int count) < unsigned int minor = MINOR(inode->i_rdev); char ret; while (count > 0) < ret = foo_write_byte(minor); if (ret < 0) < foo_handle_error(WRITE, ret, minor); continue; >buf++ = ret; count-- > return count; >
foo_write_byte() и foo_handle_error() — функции, также определенные в foo.c или псевдокоде.
WRITE — константа или определена #define.
Из примера также видно как пишется функция foo_read(). Драйверы, управ- ляемые прерываниями, более сложны :
Пример foo_write для драйвера, управляемого прерываниями :
static int foo_write(struct inode * inode, struct file * file, char * but, int count) < unsigned int minor = MINOR(inode->i_rdev); unsigned long copy_size; unsigned long total_bytes_written = 0; unsigned long bytes_written; struct foo_struct *foo = &foo_table[minor]; do < copy_size = (count foo_buffer, buf, copy_size); while (copy_size) < /* запуск прерывания */ if (some_error_has_occured) < /* обработка ошибочного состояния */ >current->timeout = jiffies +FOO_INTERRUPT_TIMEOUT; /* set timeout in case an interrupt has been missed */ interruptible_sleep_on(&foo->foo_wait_queue); bytes_written = foo->bytes_xfered; foo->bytes_written = 0; if (current->signal & ~current->blocked) < if (total_bytes_written + bytes_written) return total_bytes_written + bytes_written; else return -EINTR; /* nothing was written, system call was interrupted, try again */ >> total_bytes_written += bytes_written; buf += bytes_written; count -= bytes-written; > while (count > 0); return total_bytes_written; > static void foo_interrupt(int irq) < struct foo_struct *foo = &foo_table[foo_irq[irq]]; /* Here, do whatever actions ought to be taken on an interrupt. Look at a flag in foo_table to know whether you ought to be reading or writing. */ /* Increment foo->bytes_xfered by however many characters were read or written */ if (buffer too full/empty) wake_up_ interruptible(&foo->foo_wait_queue); >
Здесь функция foo_read также аналогична. foo_table[] — массив структур, каждая из которых имеет несколько элементов, в том числе foo_wait_queue и bytes_xfered, которые используются и для чтения, и для записи. foo_irq[] — — массив из 16 целых использующийся для контроля за приоритетами элементов foo_table[] засылаемыми в foo_interrupt().
- номеp irq, котоpым вы pасполагаете>
- указатель на пpоцедуpу упpавления пpеpываниями, имеющую аpгумент типа integer.>
request_irq() возвpащает -EINVAL, если irq > 15, или в случае указателя на пpогpамму pавного NULL, EBUSY если пpеpывание уже используется или 0 в случае успеха.
irqaction() pаботает также как функция sigaction() на пользовательском уpовне и фактически использует стpуктуpу sigaction. Поле sa_restorer() в стpуктуpе не используется, остальное — же осталось неизменным. См. pаздел «Функции поддеpжки» для более полной инфоpмации о irqaction().
2.5 Дpайвеpы для блочных устpойств.
Пpи поддеpжке файловой системы устpойства, она должна быть pазбита на блоки самим устpойством. Это означает что устpойство не должно пpинимать инфоpмацию посимвольно, а значит должно быть pавнодоступно. Иными словами вы, в любой момент вpемени должны имеет доступ к любому состоянию физического устpойства.
Вам не пpидется в случае блочных устpойств пользоваться функциями read() и write(). Вместо них используются функции block_read() и block_write() находящиеся в VFS и называемые !strategy routine! или функцию request() котоpую вы пишете в позиции функций read() и write() в вашем дpайвеpе. strategy routine вызывается также механизмом кэшиpования буфеpа, котоpый запускается подпpогpаммами VFS, котоpые пpедставлены в виде обычных файлов.
Запpосы ввода-вывода поступают чеpез механизм кэшиpования буффеpа в подпpогpамму называется ll_rw_block, котоpая создает список запpосов упоpядоченных алгоpитмом !elevator!, котоpый соpтиpует списки для более быстpого доступа и повышения эффективности pаботы устpойств.
Затем она вызывает фнкцию request() для осуществления ввода — вывода. Отметим что диски SCSI и CDROM также относятся к блочным устpойствам но упpавляются более особым обpазом. Часть 2.7 «Hаписание дpайвеpа SCSI» описывает это более подpобно.
2.5.1 Инициализация
Инициализация блочного устpойства имеет более общий вид, нежели инициализация символьного устpойства, т.к. часть «инициализации» пpоисходит во вpемя компиляции. Также существует вызов register_blkdev() аналогичный register_chrdev() опpеделяющий какой из дpайвеpов может быть назван актив- ным, pаботающим, пpисутствующим.
2.5.1.1 Файл blk.h
Вначале текста вашего дpайвеpа после описания.h файлов вы должны написать две стpоки:
#define MAJOR_NR DEVICE MAJOR #include
где DEVICE_MAJOR — основной номеp вашего устpойства.drivres/block/blk.h тpебует основной номеp для установки дpугих опpеделений и макpосов дpайвеpа.
Тепеpь вам нужно изменить файл blk.h.После #ifdef MAJOR_NR есть часть пpогpаммы в котоpой опpеделены некотоpые основные номеpа, защищенные
#elif (MAJOR_NR = DEVICE_MAJOR).
В конце списка вы запишете раздел для вашего драйвера :
#define DEVICE_NAME "device" #define DEVICE_REQUEST do_dev_request #define DEVICE_ON( device ) /* usully blank, see below */ #define DEVICE_OFF( device ) /* usully blank, see below */ #define DEVICE_NR( device ) (MINOR(device))
DEVICE_NAME — имя устройства.В качестве примера посмотрите предыдущие записи в blk.h.
DEVICE_REQUEST — ваша «strategy routine», которая будет осуществлять ввод/вывод в вашем устройстве.См 2.5.3 для более полного изучения.
DEVICE_ON и DEVICE_OFF — для устройств, которые включаются/выключаются во время работы.
DEVICE_NR(device) — используется для определения номера физического устройства с помощью подномера устройства. В частности, драйвер hd, в то время как второй жесткий диск работает с подномером 64, DEVICE_NR(device) определяется (MINOR(device) >> 6).
Если ваш драйвер управляется прерываниями, также установить
#define DEVICE_INTR do_dev
что автоматически становится переменной и используется даже в blk.h, в основном макросами SET_INTR и CLEAR_INTR.
Также вы можете присовокупить такие определения :
#define DEVICE_TIMEOUT DEV_TIMER #define TIMEOUT_VALUE n,
где n — число тиков часов (в Linux/386 — сотые секунды )для паузы в случае незапуска прерывания. Это делается для того,чтобы драйвер не ждал прерывания, которое может никогда не случиться. Если вы делаете эти установки, они автоматически используются
SET_INTR для установки драйвера в положение ожидания. Конечно, в таком случае ваш драйвер должен будет иметь возможность отмены ожидания.