Восстановление повреждённых файлов на основе CRC32
Нашел я недавно в закромах старый оптический диск (CD). Открыл его в проводнике и не могу зайти ни в одну папку. Протёр диск. Попробовал снова — та же оказия. Царапины на диске конечно есть, но не много и не сильные. Решил воспользоваться специальным софтом BadCopy. Половина мелких файлов восстановилась, половина нет. Большие файлы восстановились не полностью. В итоге в двух повреждённых архивах (повреждено 2% и 10%) я обнаружил один и тот же файл. При попытке его извлечь вылезала ошибка CRC. Но если в WinRAR при извлечении установить галочку «Keep broken files» (Не удалять файлы, извлечённые с ошибками), то извлекается как есть. Так как мой файл был дорог мне как воспоминание и был небольшим — всего 640 КБ, я решил заморочиться. Там же в WinRAR, кстати, можно узнать оригинальный размер файла и его CRC32.
Итак, у нас есть две повреждённые версии файла, его длина и даже его CRC32, нужно восстановить оригинал. Что может быть проще?
Спойлер: у меня на конкретно этом файле не получилось, но я определил какие должны быть условия, чтобы задача была решена, с какой вероятностью и немного о самом хэше. Оказывается, всё наоборот — это невероятно сложно.
Для начала нам потребуется допущение, что если бит в двух версиях одинаковый и находится на одном и том же месте, то в оригинале на этом же месте точно такой же бит. Вообще-то это не всегда верно: для файла уже в 3 байта с повреждением в 5% в обоих версиях вероятность что повреждённый бит окажется на одном и том же месте — те же 5%, вероятность того что биты окажутся одинаковыми 50%. Таким образом, при столь малом размере наше допущение неверно уже в 2,5%. Это недопустимо, однако иначе на эти версии вообще нельзя полагаться, а значит придётся перебирать все возможные комбинации. Но это мы тоже сделать не можем — для файла уже в 6 байт нас придётся перебрать 256^6 комбинаций, а это больше 2,8*10^14, и не просто перебрать, а вычислить для каждого хэш и сравнить с требуемым. Так что, похоже, допущение остаётся с нами, но нельзя ли его сделать строже? Можно, если учитывать одинаковые участки не по биту, а например по байту (или по несколько байт — но чем жёстче условия — тем дольше нам придётся ждать). Ок, что дальше? Перебрать просто все варианты для повреждённых участков? Нет, потому как если повреждено более 6 байт, мы опять-таки не сможем этого сделать (см. выше). Поэтому нам нужна какая-то оптимизация.
Я придумал три способа восстановления, которые оптимизируют скорость процесса, но уменьшают и без того не 100% вероятность успеха:
1. Побайтовый перебор, но перебираем не все 256 вариантов для каждого байта, а только от a до b, где а = v1 AND v2, b = v1 OR v2, где v1 и v2 — это соответствующие значения этого байта в версиях. Таким образом, если в одной версии там символ в кодировке Windows-1251 «Б», а в другой — «Ю», то мы будем перебирать не 256 вариантов, а только 32 варианта от «А» до «Я» («Ё» идёт лесом).
2. Малый побайтовый перебор — тут мы вместо 256 вариантов для каждого повреждённого байта перебираем всегда только 2 — из первой версии или из второй
3. Поинтервальный перебор — то же, что 2., но перебор идёт не кадого байта, а для всего повреждённого интервала байтов. Например, если в 100-байтном файле повреждены байты с 70-го по 75-ый, 83-91, 96-100, то нам для всего процесса восстановления потребуется перебрать всего 8 вариантов — по 2 для каждого из трёх интервалов.
А теперь статистика по этим методам (получена эмпирически и плохо экстраполирована):
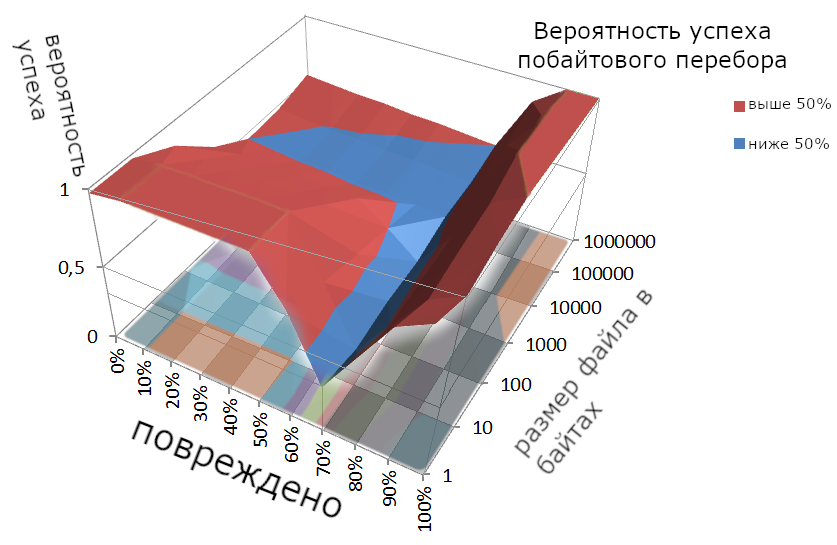
- Вероятность успеха.
Максимум на что можно рассчитывать при первом способе — 70% вероятность успеха.

Второй способ даёт успех в два раза реже.
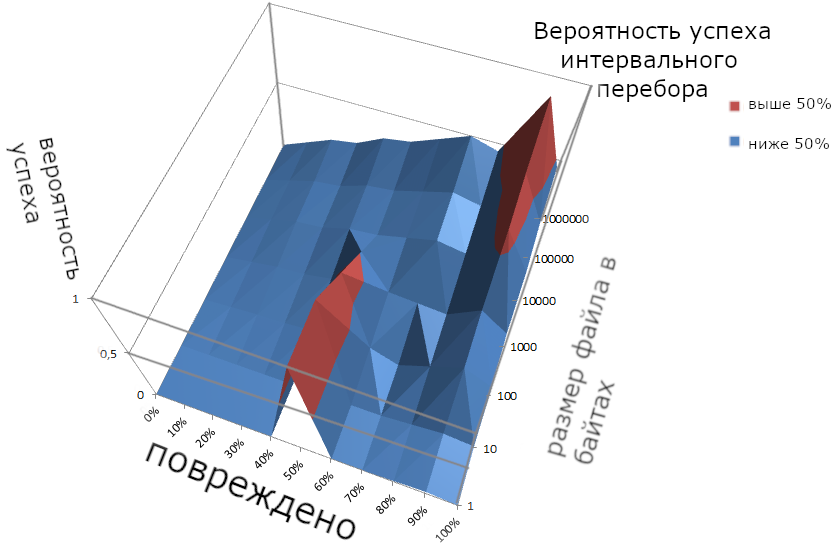
Третий способ даёт успех ещё в два раза реже.
Однако, зато «слабые» способы намного быстрее:
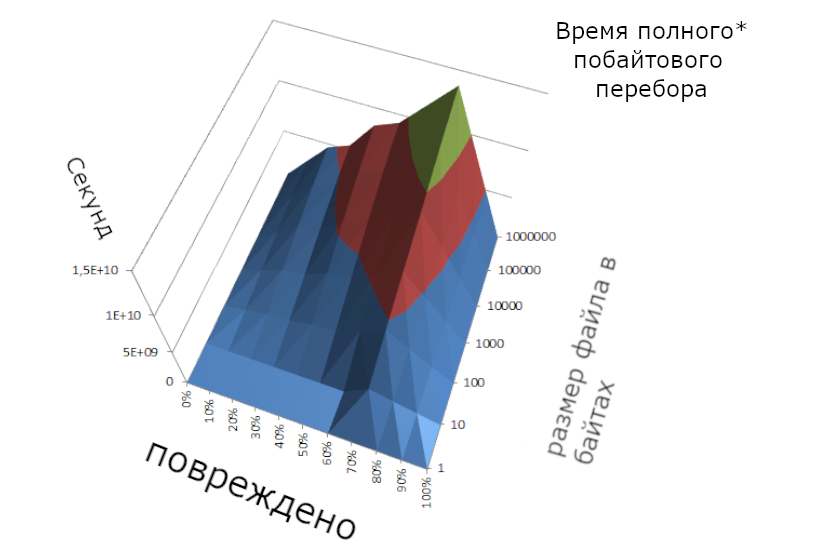
*с описанными в 1. оптимизацией. В среднем — больше 95 лет.

Тут получилось более точно передать пик при больших размерах файла, поэтому среднее время вышло немного больше — 98 лет, зато точнее (по идее у первого графика должен быть тоже такой же пик — чем больше повреждений — тем больше вариантов — тем дольше). Но всё-таки этот способ гораздо быстрее — это мы увидим далее.

В среднем два года.
*Выше и нижеуказанные значения времени были получены на одном процессоре 1.8 ГГц
Понятно, что эти огромные цифры мало общего имеют с реальностью — врят ли кто-то будет ждать 2 года, чтобы восстановить файл меньше мегабайта (разве что там написано почему смысл жизни = 42, шучу, это потому что это ASCII-код джокера), а если речь идёт о более 90 лет (две жизни), то вообще может лучше просто подождать когда компьютеры станут быстрее?
Кстати — это интересный вопрос. Согласно закону Мура, количество ядер на вычислительном элементе удваивается каждые 2 года. А так как нашу программу можно полностью распараллелить (просто в начале заранее определить для какого ядра какая область перебора), то считаем, что каждые 2 года ждать нужно в 2 раза меньше, но нужно сначала подождать эти 2 года. Так что же лучше — начать как можно раньше или как можно дольше подождать?

Если наша задача решается за 100 лет, то самое оптимальное — подождать 10 лет и через 3 года и 1,5 месяца — она решится. То есть потребуется не меньше чем 13 лет! Если для Вас это неприемлемо — то Вам не повезло родиться слишком рано. Конечно, если у Вас нет сохранения промежуточного состояния программы или сети ботов, делающих всю работу за Вас.
Однако, как я уже оговаривался ранее, такие цифры у меня получились, задействуя всего лишь 1 ядро процессора. А если задействовать 8? Уже будет меньше 13 лет! А если вычисления производить на видеокарте? Смотря на какой, но порядок для современных бюджетных видеокарт среднего класса будет всего около 2 месяцев! Как это, спросите Вы? Дело в том, что ядер на видеокарте больше в 100 раз, чем в процессоре, а их частота меньше всего в 1,5 раза. Поэтому, если нужно что-то посчитать последовательно — быстрее будет на процессоре, а если множество вычислений (более 8-16 потоков) не зависят друг от друга (например, если цвет каждого пикселя напрямую не зависит от цвета других, обучение нейросети на одном примере можно производить отдельно от другого, вычисление множества хэшей как в нашем случае или в криптовалюте и т.п.), то лучше использовать видеокарту или несколько.
Итого: не меньше 2 месяцев потребуется, чтобы восстановить файл 1МБ с менее, чем 35% вероятностью успеха на среднем ПК в 2022 году. Всё равно неутешительно.
Но и это ещё не всё. Вы можете сказать: «Подожди, а зачем нам ждать полного перебора — вдруг правильный ответ ждёт нас уже на втором проценте?» Соврешенно верно, поэтому я исследовал и это:

Я ждал максимум сутки, поэтому максимальное значение здесь равно 86400 секунд и записывал результат самого быстрого способа, который всё же дал верный результат (а это 69% успеха при условии, что Вы перепробуете все три способа) — на практике это время может быть намного больше, тем более, что если с первого раза Вы не угадали самый быстрый способ, который не подведёт, но даже так видно, что есть области где пусть не всегда, но требуемый оригинальный файл достигается за гораздо меньшее время.
Таким образом, получается, что наиболее благоприятные условия (до ~ 12 часов на одном ядре или ~ 9 минут на видеокарте — если Вы думаете, что 9 минут — это мало, то вспомните, что это для размеров меньше 1 МБ — стоит добавить парочку повреждённых байт или десяток повреждённых интервалов — и вот уже вновь 12 часов), чтобы получить верный результат будут следующими:

То есть, повреждения желательно должны быть меньше 40% либо размер файла 50 байт.
Объединяя это с предыдущими графиками получаем:

Это рекомендация по выбору самого успешного способа.
Если у Вас имеется только 24 часа на одном процессоре или 18 минут на одной видеокарте, то:

Правый нижний угол ведёт себя немного странно — это потому что при таком повреждении наше изначальное не всегда верное допущение перестаёт иметь значение. Аналогично в левом нижнем углу допущение начинает играть значительную роль. Почему только в нижних? Потому что при таком отпущенном времени на поиски до верха мы просто не доберёмся.
Выкладываю здесь свою программу: ссылка на яндекс диск.

Извлеките из двух повреждённых архивов один и тот же файл (с галочкой Keep broken files в WinRar) в папку с программой как 1 и 2 (без расширения), введите длину файла и CRC32 из архиватора
Но это ещё не всё! Если Вы сейчас попробуете восстановить так какой-нибудь файл (рядом с программой есть примеры, на которых можно поиграться, дайте знать если у Вас получится восстановить D82C64A7 как работающий exe), то Вы получите результат гораздо быстрее:

В среднем за 5,5 часов*.
, но, скорее всего, он будет не тот, что Вам нужен.
Проблема в том, что так как CRC32 имеет длину в 4 байта, то на каждые 256^4 (4 миллиарда) комбинаций в среднем будет приходиться одна, подходящая под один любой CRC32. Поэтому сложность не только в том, чтобы найти вариант, подходящий под длину и хэш, но и выявить нужный из всего множества таких. А это множество может быть очень большим:

В среднем 22 штуки.

некоторые 17 вариантов для db7d2bac и размера в 54 байта (малый побайтовый перебор)

начальные 17 вариантов и оригинал для CRC32 = 9b225956 и размера в 11 байт (побайтовый перебор). Обратите внимание на 3-й символ — первые два не меняются, и практически для каждого байта находится несколько вариантов.
Таким образом, если у Вас на сайте есть достаточное органичение на минимальную длину пароля, имеет смысл хранить и проверять не только его хэш, но и длину. Тогда подобрать или найти подходящий в радужной таблице будет в разы сложнее.
По вышеприведённой ссылке есть также исходники программы на VB6. Пробуйте перевести её на видеокарту, изобретите другой способ перебора (например, с какой-то вероятностью в каких-то байтах верить изначальному допущению, а с какой-то не верить повреждённым версиям), расширяйте её на большее количество повреждённых версий, ставьте проверку на требуемую структуру файла, оптимизируйте или как-то можно не перебирать, а вычислять варианты? — непаханное поле!
Но и это ещё не всё. Пишите комментарии — что понравилось/что нет, подписывайтесь, а если хотите поддержать такие околонаучные статьи и упоротые расчёты — можете сделать это здесь.
UPD: Скормил извлечённый .text из повреждённого exe и из такой же сигнатуры неповреждённого файла в https://www.jpeg-repair.org/ru/vg-jpeg-repair/ — показал изображения, что были внутри. Есть у кого аналог бесплатный или ещё что-то что может восстанавливать другие типы информации?
UPD2: Дело в том, что как заметил @Sap_ru считывание с CD происходит блоками в 2 КБ. Поэтому я также добавил несколько новых способов:
4. Малый поблоковый перебор — аналогичен малому побайтовому, но работает не с отдельными байтами, а с целыми блоками по 2 КБ, вследствие чего намного быстрее:

В среднем 13 лет вместо 98.

В среднем в лучшем случае 24% успеха
5. Интервальный поблоковый — аналогично. Перебирает очень мало вариантов и выполняется практически на любом файле до 1 МБ почти мгновенно.

В среднем в лучшем случае 15% успеха.
Таким образом, вот рекомендации когда их использовать:

Обратите внимание, что процент поврежденных блоков и поврежденных байтов — это разные вещи:


Однако, как выяснилось в моём случае — даже некоторые совпадающие блоки — это просто нули, которых не должно быть в сигнатуре файла, то есть в моём случае допущение оказалось не верным. Скорее всего, это касется всех архивов без информации восстановления. Однако, если у Вас другой случай или Вам нужно просто подобрать особенную коллизию (напаример, чтобы Windows не выдавал ошибку в самом начале из-за несовпадения CRC32 типа «Невозможно запустить это приложение на Вашем ПК») — пробуйте.
Поэтому я добавил ещё один способ, которому не нужно это допущение, однако он всё-таки опирается на имеющиеся версии:
6. Случайный — все повреждённые байты каждый раз принимают случайное значение, неповреждённые байты с 75% вероятностью — значение из версий, с 25% — случайное. Теоретически, так можно получить искомую коллизию при любых изначальных условиях, но за время в среднем гораздо большее 100 лет. Но может повезти 🙂
И всё-таки, скажите мне, если у Вас получится запустить D82C64A7 в примерах по ссылке (Может случайно или ещё как-то).
Также добавил автоматические рекомендации по выбору способа поиска коллизий в программу
- crc32
- поврежденное
- поврежденные файлы
- архив
- восстановление данных
- восстановление информации
- восстановление файлов
- восстановление пароля
- Занимательные задачки
- Алгоритмы
- Восстановление данных
Ошибка контрольной суммы (CRC) в WinRAR
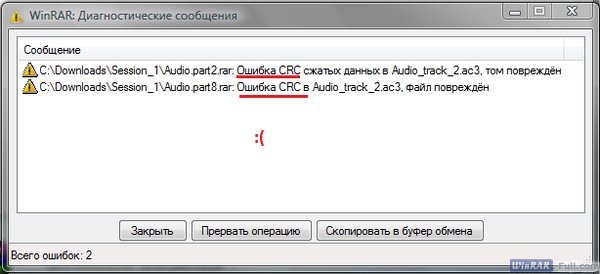
Бывает качаешь целый час большой архив с какого-нибудь сайта, пытаешься открыть его в WinRAR и получаешь сообщение: «ошибка контрольной суммы» или «ошибка CRC сжатых данных». Что делать и почему такое происходит?
Данная ошибка возникает, если во время загрузки архива были потери пакетов, то есть он скачался вроде бы полностью, но несколько байтов информации в нем не хватает или они отличаются от того, что должно быть. Потеря пакетов – частое явление при нестабильном интернет-соединении. Чем больше размер загружаемого архива и дольше происходит его скачивание – тем больше вероятность возникновения подобной ошибки.
Как решить проблему?
Есть 2 способа, с помощью которых можно исправить ошибку контрольной суммы.
Способ 1
Самое элементарное – скачать архив заново. Для скачивания лучше использовать специальную программу, загрузчик файлов, например, Download Master.
Способ 2
Можно попытаться восстановить архив с помощью встроенной функции WinRAR. В архиве может содержаться информация для восстановления, которая будет использована архиватором для «оживления» поврежденного архива.
Запустите WinRAR и через его интерфейс найдите проблемный архив. Щелкните на нем правой кнопкой мыши и выберите «восстановить архив(ы)».
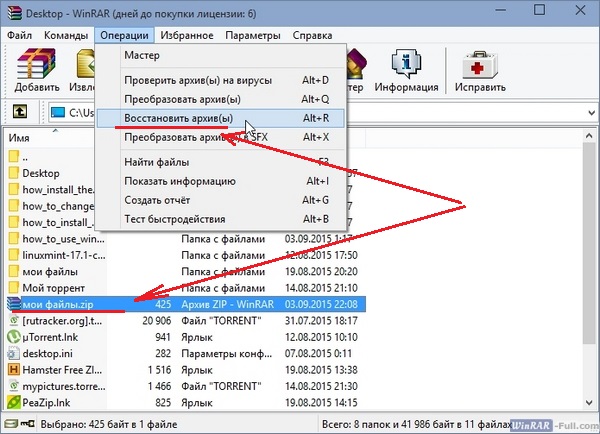
В некоторых случаях может появиться окно, предлагающее указать, какой формат у архива, который вы хотите восстановить. Укажите правильный формат файла (его расширение) и нажмите «ОК».
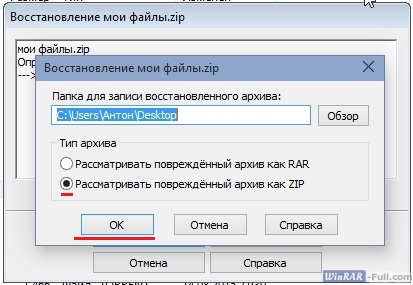
Если повезет, архив будет восстановлен.
*если ошибка CRC у вас возникает постоянно при открытии любых архивов на вашем компьютере, рекомендуем проверить оперативную память и жесткие диски на предмет потери данных, с помощью такой программы, как AIDA или обратившись к специалистам.
Winrar- what does CRC32 mean?
CRC — Cyclic Redundancy Check. Code that checks the hash of the original data against that of the copied data (roughly). If they don’t match, you have an error. the algorithm can request a resend or re-read the data. The 32 signifies that it is using the 32 bit polynomial algorithm.
>
Trending Topics
new to the marketing game questions about traffic analysis for SEO
mako34 3 hours ago in Internet Marketing
Hi guys, im new to the marketing side of things, have been a team lead and architect for startups and mobile apps. Now working to launch my app. A question . [read more]
Happy Birthday, Claude
Dan Riffle 3 days ago in Off Topic
Happy 69th birthday, Claude. I hope you live long enough to flip your age upside down.
What AI tools do you use?
PsdDude 1 day ago in AI
As a graphic designer I’m using more and more the AI features that many software now have, including Photoshop. I don’t know if it’s a bad thing or not. Which . [read more]
Dealing with 404 Errors During Website Deployment: SEO Challenges and Solutions
krithick 2 days ago in SEO
We frequently encounter 404 errors for our pages during website deployment. Our DevOps team mentioned that they restart the server, causing minimal disruption to the site. Upon checking the website . [read more]
Hitting It really Hard for 2024!! No excuses.
discrat 1 week ago in Off Topic
I have started back on intermittent fasting today. Really am pumped to get in great shape. Cardiovascular wise iam already in decent shape from Running 4 times a week. But . [read more]
Warrior Special Offers
Warrior Special Offers® (WSOs) are deals available exclusively through Warrior Forum that no one else can beat.
Что такое CRC32 в WinRar? Написано возле каждого файла
Контрольная сумма или хэш. Т. е. , некоторая буквенно-цифровая комбинация, которая зависит только от содержимого файла, но не от его названия.
Остальные ответы
контрольная сумма
Контрольная сумма.
Похожие вопросы
Ваш браузер устарел
Мы постоянно добавляем новый функционал в основной интерфейс проекта. К сожалению, старые браузеры не в состоянии качественно работать с современными программными продуктами. Для корректной работы используйте последние версии браузеров Chrome, Mozilla Firefox, Opera, Microsoft Edge или установите браузер Atom.