Процессы в Linux
Данной теме посвящено много статей, но в Сети мало сугубо практических статей. О какой именно практике идет речь, вы узнаете прочитав эту статью. Правда, одной только практикой нам не обойтись — вдруг вы не читали всю эту серую массу теории, которую можно найти в Сети.
Немного теории
- программа на стадии выполнения
- «объект», которому выделено процессорное время
- асинхронная работа
- состояния выполнения
- состояния ожидания
- состояния готовности
Выполнение — это активное состояние, во время которого процесс обладает всеми необходимыми ему ресурсами. В этом состоянии процесс непосредственно выполняется процессором.
Ожидание — это пассивное состояние, во время которого процесс заблокирован, он не может быть выполнен, потому что ожидает какое-то событие, например, ввода данных или освобождения нужного ему устройства.
Готовность — это тоже пассивное состояние, процесс тоже заблокирован, но в отличие от состояния ожидания, он заблокирован не по внутренним причинам (ведь ожидание ввода данных — это внутренняя, «личная» проблема процесса — он может ведь и не ожидать ввода данных и свободно выполняться — никто ему не мешает), а по внешним, независящим от процесса, причинам. Когда процесс может перейти в состояние готовности? Предположим, что наш процесс выполнялся до ввода данных. До этого момента он был в состоянии выполнения, потом перешел в состояние ожидания — ему нужно подождать, пока мы введем нужную для работы процесса информацию. Затем процесс хотел уже перейти в состояние выполнения, так как все необходимые ему данные уже введены, но не тут-то было: так как он не единственный процесс в системе, пока он был в состоянии ожидания, его «место под солнцем» занято — процессор выполняет другой процесс. Тогда нашему процессу ничего не остается как перейти в состояние готовности: ждать ему нечего, а выполняться он тоже не может.
Из состояния готовности процесс может перейти только в состояние выполнения. В состоянии выполнения может находится только один процесс на один процессор. Если у вас n-процессорная машина, у вас одновременно в состоянии выполнения могут быть n процессов.
Из состояния выполнения процесс может перейти либо в состояние ожидания или состояние готовности. Почему процесс может оказаться в состоянии ожидания, мы уже знаем — ему просто нужны дополнительные данные или он ожидает освобождения какого-нибудь ресурса, например, устройства или файла. В состояние готовности процесс может перейти, если во время его выполнения, квант времени выполнения «вышел». Другими словами, в операционной системе есть специальная программа — планировщик, которая следит за тем, чтобы все процессы выполнялись отведенное им время. Например, у нас есть три процесса. Один из них находится в состоянии выполнения. Два других — в состоянии готовности. Планировщик следит за временем выполнения первого процесса, если «время вышло», планировщик переводит процесс 1 в состояние готовности, а процесс 2 — в состояние выполнения. Затем, когда, время отведенное, на выполнение процесса 2, закончится, процесс 2 перейдет в состояние готовности, а процесс 3 — в состояние выполнения.
Диаграмма модели трех состояний представлена на рисунке 1.
Рисунок 1. Модель трех состояний
Более сложная модель — это модель, состоящая из пяти состояний. В этой модели появилось два дополнительных состояния: рождение процесса и смерть процесса. Рождение процесса — это пассивное состояние, когда самого процесса еще нет, но уже готова структура для появления процесса. Как говорится в афоризме: «Мало найти хорошее место, надо его еще застолбить», так вот во время рождения как раз и происходит «застолбление» этого места. Смерть процесса — самого процесса уже нет, но может случиться, что его «место», то есть структура, осталась в списке процессов. Такие процессы называются зобми и о них мы еще поговорим в этой статье.
Диаграмма модели пяти состояний представлена на рисунке 2.
Рисунок 2. Модель пяти состояний
- Создание процесса — это переход из состояния рождения в состояние готовности
- Уничтожение процесса — это переход из состояния выполнения в состояние смерти
- Восстановление процесса — переход из состояния готовности в состояние выполнения
- Изменение приоритета процесса — переход из выполнения в готовность
- Блокирование процесса — переход в состояние ожидания из состояния выполнения
- Пробуждение процесса — переход из состояния ожидания в состояние готовности
- Запуск процесса (или его выбор) — переход из состояния готовности в состояние выполнения
- Присвоить процессу имя
- Добавить информацию о процессе в список процессов
- Определить приоритет процесса
- Сформировать блок управления процессом
- Предоставить процессу нужные ему ресурсы
Подробнее о списке процессов, приоритете и обо всем остальном мы еще поговорим, а сейчас нужно сказать пару слов об иерархии процессов. Процесс не может взяться из ниоткуда: его обязательно должен запустить какой-то процесс. Процесс, запущенный другим процессом, называется дочерним (child) процессом или потомком. Процесс, который запустил процесс называется родительским (parent), родителем или просто — предком. У каждого процесса есть два атрибута — PID (Process ID) — идентификатор процесса и PPID (Parent Process ID) — идентификатор родительского процесса.
Процессы создают иерархию в виде дерева. Самым «главным» предком, то есть процессом, стоящим на вершине этого дерева, является процесс init (PID=1).
На мой взгляд, приведенной теории вполне достаточно, чтобы перейти к практике, а именно — «пощупать» все состояния процессов. Конечно, мы не рассмотрели системные вызовы fork(), exec(), exit(), kill() и многие другие, но в Сети предостаточно информации об этом. Тем более, что про эти вызовы вы можете прочитать в справочной системе Linux, введя команду man fork. Правда, там написано на всеми любимом English, так что за переводом (если он вам нужен) все-таки придется обратиться за помощью к WWW.
Практика
Для наблюдения за процессами мы будем использовать программу top.
15:03:11 up 58 min, 4 users, load average: 0,02, 0,01, 0,00 52 processes: 51 sleeping, 1 running, 0 zombie, 0 stopped CPU states: 0,8% user, 0,6% system, 0,0% nice, 0,0% iowait, 98,3% idle Mem: 127560k av, 124696k used, 2864k free, 0k shrd, 660k buff 13460k active, 17580k inactive Swap: 152576k av, 8952k used, 143624k free 28892k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 3097 den 15 0 1128 1128 832 R 2,8 0,8 0:00 top 1 root 8 0 120 84 60 S 0,0 0,0 0:04 init 2 root 12 0 0 0 0 SW 0,0 0,0 0:00 keventd 3 root 19 19 0 0 0 SWN 0,0 0,0 0:00 ksoftirqd_CPU0 .
Полный вывод программы я по понятным причинам урезал. Рассмотрим по порядку весь вывод программы. В первой строке программа сообщает текущее время, время работы системы ( 58 min), количество зарегистрированных (login) пользователей (4 users), общая средняя загрузка системы (load average).
Примечание. Общей средней загрузкой системы называется среднее число процессов, находящихся в состоянии выполнения (R) или в состоянии ожидания (D). Общая средняя загрузка измеряется каждые 1, 5 и 15 минут.
Во второй строке вывода программы top сообщается, что в списке процессов находятся 52 процесса, из них 51 спит (состояние готовности или ожидания), 1 выполняется (у меня только 1 процессор), 0 процессов зомби и 0 остановленных процессов.
В третьей-пятой строках приводится информация о загрузке процессора, использования памяти и файла подкачки. Нас данная информация не очень интересует, поэтому переходим сразу к таблице процессов.
В таблице отображается различная информация о процессе. Нас сейчас интересуют колонки PID (идентификатор процесса), USER (пользователь, запустивший процесс), STAT (состояние процесса) и COMMAND (команда, которая была введена для запуска процесса).
-
R — процесс выполняется или готов к выполнению (состояние готовности)
- D — процесс в «беспробудном сне» — ожидает дискового ввода/вывода
- T — процесс остановлен (stopped) или трассируется отладчиком
- S — процесс в состоянии ожидания (sleeping)
- Z — процесс-зобми
- < — процесс с отрицательным значением nice
- N — процесс с положительным значением nice (о команде nice мы поговорим позже)
Давайте просмотрим, когда же процесс находится в каждом состоянии. Создайте файл process — это обыкновенный bash-сценарий
#!/bin/bash x=1 while [ $x -lt 10 ] do x=2 done
Сделайте этот файл исполнимым chmod +x ./process и запустите его ./process. Теперь перейдите на другую консоль (ALT + Fn) и введите команду ps -a | grep process. Вы увидите следующий вывод команды ps:
4035 pts/1 00:00:15 process
Данный вывод означает, что нашему процессу присвоен идентификатор процесса 4035. Теперь введите команду top -p 4035
15:30:15 up 1:25, 6 users, load average: 0,44, 0,19, 0,07 1 processes: 0 sleeping, 1 running, 0 zombie, 0 stopped CPU states: 2,3% user, 0,6% system, 0,0% nice, 0,0% iowait, 96,8% idle Mem: 127560k av, 124496k used, 3064k free, 0k shrd, 1208k buff 15200k active, 16400k inactive Swap: 152576k av, 15676k used, 136900k free 27548k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 4035 den 15 0 1320 1320 988 R 99,9 1,0 0:31 process
Обратите внимание на колонку состояния нашего процесса. Она содержит значение R, которое означает, что в данный момент выполняется процесс с номером 4035.
Теперь приостановим наш процесс — состояние T. Перейдите на консоль, на которой запущен ./process и нажмите Ctrl + Z. Вы увидите сообщение Stopped.
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 4035 den 9 0 1320 1320 988 T 0,0 1,0 0:51 process
Теперь попробуем «усыпить» наш процесс. Для этого нужно сначала «убить» его: kill 4035. Затем добавить перед циклом while в сценарии ./process строку sleep 10m, которая означает, что процесс будет спать 10 минут. После этого опять запустите команду ps -a | grep process, чтобы узнать PID процесса, а затем — команду top -p PID. Вы увидите в колонке состояния букву S, что означает, что процесс находится в состоянии ожидания или готовности — попросту говоря «спит».
Мы вплотную подошли к самому интересному — созданию процесса-зомби. Во многих статьях, посвященных процессам, пишется «зомби = не жив, не мертв». А что это означает на самом деле? При завершении процесса должна удаляться его структура из списка процессов. Иногда процесс уже завершился, но его имя еще не удалено из списка процессов. В этом случае процесс становится зомби — его уже нет, но мы его видим в таблице команды top. Такое может произойти, если процесс-потомок (дочерний процесс) завершился раньше, чем этого ожидал процесс-родитель. Сейчас мы напишем программу, порождающую зомби, который будет существовать 8 секунд. Процесс-родитель будет ожидать завершения процесса-потомка через 10 секунд, а процесс-потомок завершить через 2 секунды.
#include <unistd.h> #include <signal.h> #include <stdlib.h> #include <sys/wait.h> #include <stdio.h> int main() < int pid; int status, died; pid=fork(); switch(pid) < case -1: printf("can't fork\n"); exit(-1); case 0 : printf(" I'm the child of PID %d\n", getppid()); printf(" My PID is %d\n", getpid()); // Ждем 2 секунды и завершаемся, следующую строку я закомментировал // чтобы зомби "прожил" на 2 секунды больше // sleep(2); exit(0); default: printf("I'm the parent.\n"); printf(" My PID is %d\n", getpid()); // Ждем завершения дочернего процесса через 10 секунд, а потом убиваем его sleep(10); if (pid & 1) kill(pid,SIGKILL); died= wait(&status); >>
Для компиляции данной программы нам нужен компилятор gcc:
gcc -o zombie zombie.c
Для тех, у кого не установлен компилятор, скомпилированная программа доступна отсюда.
После того, как программа будет откомпилирована, запустите ее: ./zombie. Программа выведет следующую информацию:
I'm the parent My PID is 1147 I'm the child of PID 1147 My PID is 1148
Запомните последний номер и быстро переключайтесь на другую консоль. Затем введите команду top -p 1148
16:04:22 up 2 min, 3 users, load average: 0,10, 0,10, 0,04 1 processes: 0 sleeping, 0 running, 1 zombie, 0 stopped CPU states: 4,5% user, 7,6% system, 0,0% nice, 0,0% iowait, 87,8% idle Mem: 127560k av, 76992k used, 50568k free, 0k shrd, 3872k buff 24280k active, 19328k inactive Swap: 152576k av, 0k used, 152576k free 39704k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND 1148 den 17 0 0 0 0 Z 0,0 0,0 0:00 zombie <defunct>
Мы видим, что в списке процессов появился 1 зомби (STAT=Z), который проживет аж 10 секунд.
Мы уже рассмотрели все возможные состояния процессов. Осталось только рассмотреть команду для повышения приоритета процесса — это команда nice. Повысить приоритет команды может только пользователь root, указав соответствующий коэффициент понижения. Для увеличения приоритета нужно указать отрицательный коэффициент, например, nice -5 process
Передача, хранение и обработка информации
Процессы, связанные с поиском, хранением, передачей, обработкой и использованием информации, называются информационными процессами. Теперь остановимся на основных информационных процессах.
1. Поиск. Поиск информации — это извлечение хранимой информации. Методы поиска информации: непосредственное наблюдение; общение со специалистами по интересующему вас вопросу; чтение соответствующей литературы; просмотр видео, телепрограмм; прослушивание радиопередач, аудиокассет; работа в библиотеках и архивах; запрос к информационным системам, базам и банкам компьютерных данных; другие методы. Понять, что искать, столкнувшись с той или иной жизненной ситуацией, осуществить процесс поиска — вот умения, которые становятся решающими на пороге третьего тысячелетия.
2. Сбор и хранение. Сбор информации не является самоцелью. Чтобы полученная информация могла использоваться, причем многократно, необходимо ее хранить. Хранение информации — это способ распространения информации в пространстве и времени. Способ хранения информации зависит от ее носителя (книга- библиотека, картина- музей, фотография- альбом). ЭВМ предназначена для компактного хранения информации с возможностью быстрого доступа к ней. Информационная система — это хранилище информации, снабженное процедурами ввода, поиска и размещения и выдачи информации. Наличие таких процедур- главная особенность информационных систем, отличающих их от простых скоплений информационных материалов. Например, личная библиотека, в которой может ориентироваться только ее владелец, информационной системой не является. В публичных же библиотеках порядок размещения книг всегда строго определенный. Благодаря ему поиск и выдача книг, а также размещение новых поступлений представляет собой стандартные, формализованные процедуры.
3. Передача. В процессе передачи информации обязательно участвуют источник и приемник информации: первый передает информацию, второй ее получает. Между ними действует канал передачи информации — канал связи. Канал связи — совокупность технических устройств, обеспечивающих передачу сигнала от источника к получателю.
Кодирующее устройство — устройство, предназначенное для преобразования исходного сообщения источника к виду, удобному для передачи.
Декодирующее устройство — устройство для преобразования кодированного сообщения в исходное. Деятельность людей всегда связана с передачей информации. В процессе передачи информация может теряться и искажаться: искажение звука в телефоне, атмосферные помехи в радио, искажение или затемнение изображения в телевидении, ошибки при передачи в телеграфе. Эти помехи, или, как их называют специалисты, шумы, искажают информацию. К счастью, существует наука, разрабатывающая способы защиты информации — криптология.
Каналы передачи сообщений характеризуются пропускной способностью и помехозащищенностью. Каналы передачи данных делятся на симплексные (с передачей информации только в одну сторону (телевидение)) и дуплексные (по которым возможно передавать информацию в оба направления (телефон, телеграф)). По каналу могут одновременно передаваться несколько сообщений. Каждое из этих сообщений выделяется (отделяется от других) с помощью специальных фильтров. Например, возможна фильтрация по частоте передаваемых сообщений, как это делается в радиоканалах. Пропускная способность канала определяется максимальным количеством символов, передаваемых ему в отсутствии помех. Эта характеристика зависит от физических свойств канала. Для повышения помехозащищенности канала используются специальные методы передачи сообщений, уменьшающие влияние шумов. Например, вводят лишние символы. Эти символы не несут действительного содержания, но используются для контроля правильности сообщения при получении. С точки зрения теории информации все то, что делает литературный язык красочным, гибким, богатым оттенками, многоплановым, многозначным,- избыточность. Например, как избыточно с таких позиций письмо Татьяны к Онегину. Сколько в нем информационных излишеств для краткого и всем понятного сообщения «Я Вас люблю!»
4. Обработка. Обработка информации — преобразование информации из одного вида в другой, осуществляемое по строгим формальным правилам. Примеры обработки информации
| Примеры | Входная информация | Выходная информация | Правило |
|---|---|---|---|
| Таблица умножения | Множители | Произведение | Правила арифметики |
| Определение времени полета рейса «Москва-Ялта» | Время вылета из Москвы и время прилета в Ялту | Время в пути | Математическая формула |
| Отгадывание слова в игре «Поле чудес» | Количество букв в слове и тема | Отгаданное слово | Формально не определено |
| Получение секретных сведений | Шифровка от резидента | Дешифрованный текст | Свое в каждом конкретном случае |
| Постановка диагноза болезни | Жалобы пациента + результаты анализов | Диагноз | Знание + опыт врача |
Обработка информации по принципу «черного ящика» — процесс, в котором пользователю важна и необходима лишь входная и выходная информация, но правила, по которым происходит преобразование, его не интересуют и не принимаются во внимание. «Черный ящик» — это система, в которой внешнему наблюдателю доступны лишь информация на входе и на выходе этой системы, а строение и внутренние процессы неизвестны.
5. Использование. Информация используется при принятии решений. Достоверность, полнота, объективность полученной информации обеспечат вам возможность принять правильное решение. Ваша способность ясно и доступно излагать информацию пригодится в общении с окружающими. Умение общаться, то есть обмениваться информацией, становится одним главных умений человека в современном мире. Компьютерная грамотность предполагает: знание назначения и пользовательских характеристик основных устройств компьютера; Знание основных видов программного обеспечения и типов пользовательских интерфейсов; умение производить поиск, хранение, обработку текстовой, графической, числовой информации с помощью соответствующего программного обеспечения. Информационная культура пользователя включает в себя: понимание закономерностей информационных процессов; знание основ компьютерной грамотности; технические навыки взаимодействия с компьютером; эффективное применение компьютера как инструмента; привычку своевременно обращаться к компьютеру при решении задач из любой области, основанную на владении компьютерными технологиями; применение полученной информации в практической деятельности.
6. Защита. Защитой информации называется предотвращение: доступа к информации лицам, не имеющим соответствующего разрешения (несанкционированный, нелегальный доступ); непредумышленного или недозволенного использования, изменения или разрушения информации. Под защитой информации, в более широком смысле, понимают комплекс организационных, правовых и технических мер по предотвращению угроз информационной безопасности и устранению их последствий.
14. Процессы №1: Информация о процессах №1
Как мы уже выяснили, программы хранятся в файловой системе на накопителе – т.е. жёстком диске или ssd. Когда мы запускаем программу, она загружается в оперативную память, так как скорость чтения с жёсткого диска или даже ssd относительно низкая, а процессор работает на больших скоростях. Как правило, большие программы загружаются в оперативную память не полностью, а по мере необходимости. При этом, для каждой программы создаётся иллюзия, что она – единственная в оперативной памяти, то есть для неё создаётся так называемая «виртуальная память». Также программы при запуске загружают какие-то файлы, будь то файлы настроек или пользовательские файлы – как например, если мы запускаем nano file, то в память загружаются как сам /usr/bin/nano, его настройки — /etc/nanorc и ~/.nanorc, всякие библиотеки, необходимые для работы nano и сам файл, который мы открываем. Кроме этого также запускаемой программе передаются переменные окружения и ещё много всего. Ну и находясь в оперативке, эта программа делает какие-то вычисления с помощью центрального процессора, обрабатывает данные и сохраняет на диске. И совокупность всего этого называется процессом.
Иногда одной программе нужно бывает выполнить несколько операций параллельно. Представьте себе сложное математическое уравнение – есть всякие скобки, умножения и прочее. Такое уравнение можно разделить на составляющие и компьютер может разом выполнить все составляющие, а потом, используя результаты, получить простое уравнение и выполнить его. Или, допустим, веб сервер – к нему обращаются много клиентов, и каждого из них он должен обслужить и желательно параллельно. Для этого один процесс может разделяться на так называемые потоки – все они используют общую виртуальную память. У каждого процесса есть как минимум один поток.
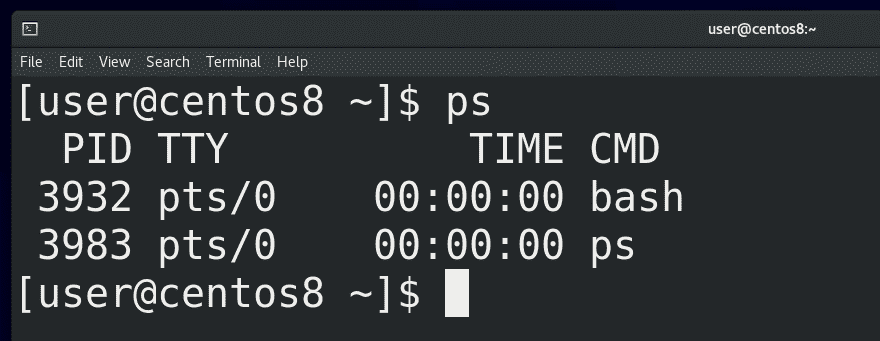
И так, выполняемая программа – это процесс. Начнём с того, что администратору важно видеть список процессов. Для этого есть несколько способов, начнём с утилиты ps. Если просто запустить:
мы увидим список процессов, запущенных в этом терминале. Как вы заметили, вывелось 2 строчки – bash и ps. При том, что ps у нас выполнился за какие-то доли секунды, он у нас всё равно виден в выводе – потому что он делает эдакий скриншот процессов именно в момент выполнения, поэтому и видит сам себя.
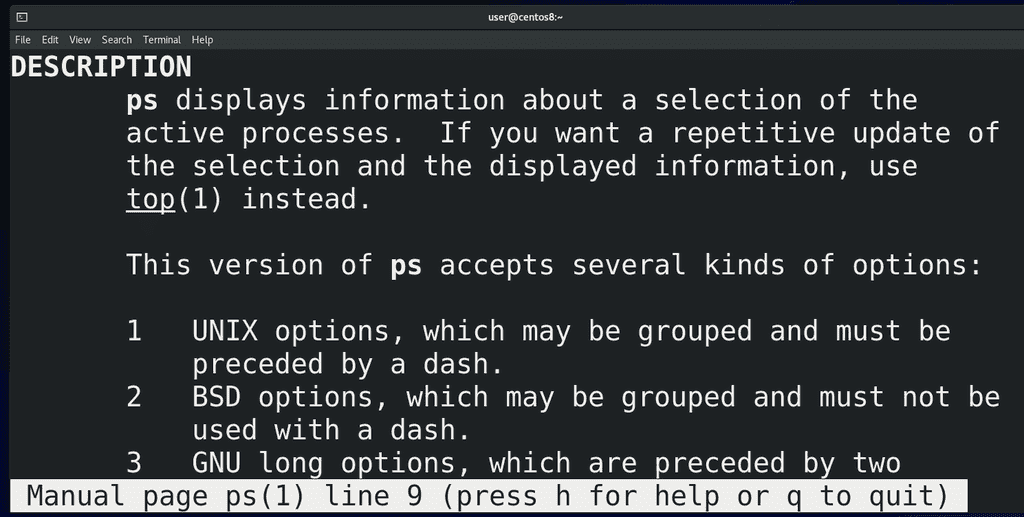
Вообще, ps работает с 3 видами ключей: юниксовыми – они обычно начинаются на один дефис (-), BSD-шные – вовсе без дефиса и GNU-шные – как правило это слова, поэтому, чтобы не счесть их за комбинацию букв, используется два дефиса. Если посмотреть документацию:
man ps
можно заметить очень много дублирующихся ключей. Но документация по ps огромная, да и все ключи знать не нужно. Достаточно выучить какую-то одну комбинацию, которая подойдёт в большинстве случаев:
ps -ef
а если вам понадобится что-то конкретное, то всегда можно погуглить или найти в мане.
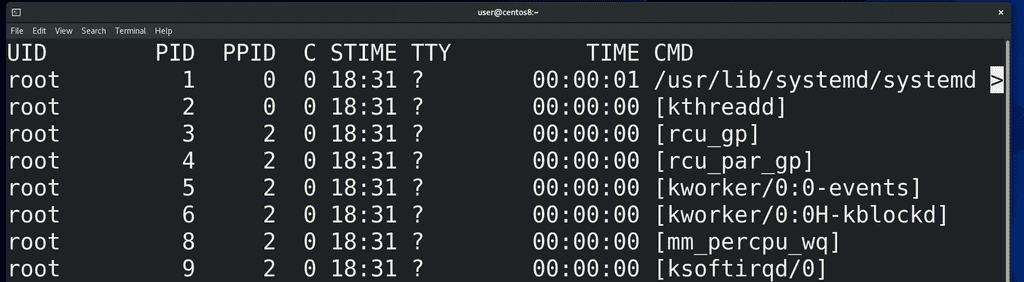
Как видите, вывод у ps довольно большой и не помещается на экране, поэтому урезается сбоку. Чтобы мы могли нормально прочесть, мы можем передать вывод ps команде less. Правда по умолчанию less переносит текст на новые строки, из-за чего сбиваются столбцы, поэтому less лучше использовать с ключом -S, который не переносит строки. В итоге:
ps -ef | less -S
Давайте разберём, что означают ключи и как читать вывод. Ключ -e выводит все процессы всех пользователей:
ps -e
Да, процессы запускаются от имени пользователей. От этого зависит какие права будут у процесса. Допустим, если я запускаю программу nano от пользователя user, то программа сможет работать с моими файлами. А ключ f:
ps -f
показывает чуть больше информации о процессе. Давайте пройдёмся по столбикам:
ps -ef | less -S
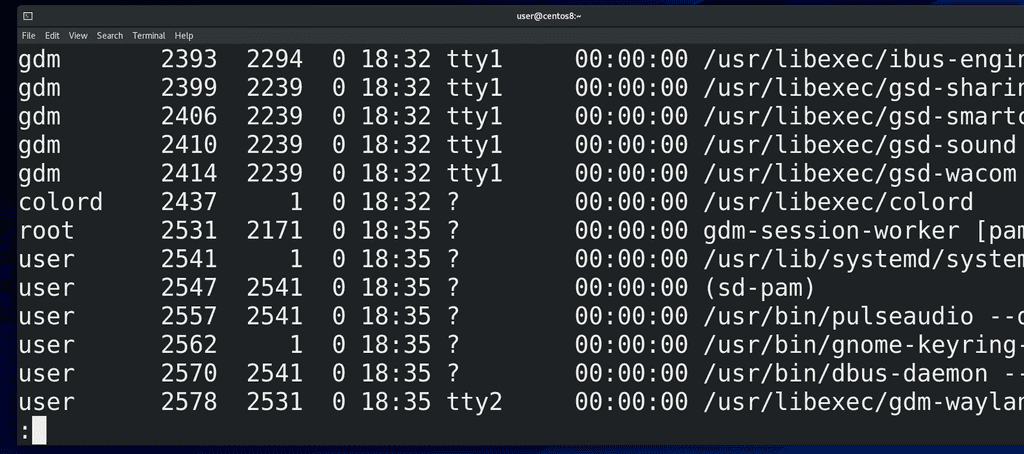
Первое – UID – user id — пользователь, который запустил процесс. Большинство процессов в системе запущены от пользователя root – его также называют суперпользователем – это юзер, у которого есть все права на систему. По возможности, люди стараются не использовать рута везде. Если у программы будет какой-то баг или уязвимость и если она запущена от рута, то программа может сильно навредить системе. Поэтому для программ, которые не требуют особых прав, обычно создают сервисных пользователей. Как правило при установке программы она сама всё это настраивает. Ну и наконец у нас тут есть программы, запущенные от нашего пользователя. Как видите, я вроде ничего кроме эмулятора терминала не запускал, а в системе уже пару сотен процессов.
Второй столбик – PID – process id – идентификатор процесса. Он уникальный для каждого процесса, но совпадает для потоков одного процесса. Когда программа завершается, она освобождает номер и через какое-то время другая программа может использовать этот номер. С помощью этих номеров мы можем управлять процессами.
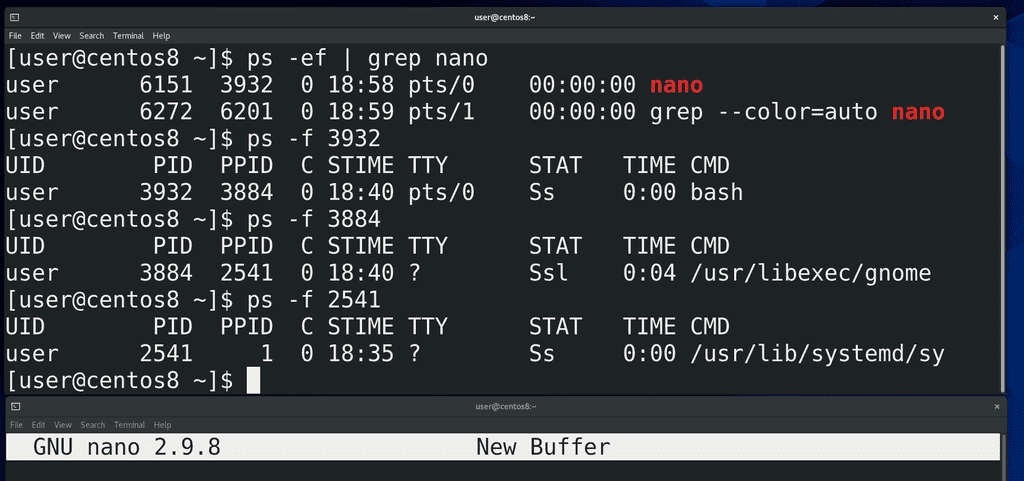
Третий столбик – PPID – parent process id – идентификатор родительского процесса. Почти все процессы в системе были запущены каким-то другим процессом. Допустим, когда мы запускаем эмулятор терминала, а в нём nano – то родительским процессом для nano является bash, который запущен в этом эмуляторе терминала:
ps -ef | grep nano
Родительским процессом для этого bash:
ps -f ppid
является gnome — процесс рабочего окружения. Родительским процессом для него является systemd — первый процесс. О systemd мы ещё поговорим.
Четвёртый столбик – C – использование процессора данным процессом. Много где у нас нули, но давайте запустим какое-нибудь тяжёлое приложение, допустим, firefox, найдём этот процесс:
ps -ef | grep firefox | less -S
и увидим, что для него это значение отличается от нуля.
Дальше — TTY – от слова телетайп. На хабре есть неплохая статья, объясняющая разницу между телетайпом, консолью, терминалом и т.п. А ps в этом столбике говорит, с каким терминалом ассоциируется данный процесс. Обычно, процесс, запущенный системой и не требующий графики, вывода информации на экран, не связан ни с каким терминалом. Процессы, требующие графики, завязаны на каком-нибудь виртуальном терминале – о них мы говорили ранее. Можно заметить, что тут указано tty1 и tty2 – если нажать правый ctrl + f1 или ctrl+f2, можно увидеть, что именно здесь у нас запущен графический интерфейс. При переходе на ctrl+f3 и далее открывается виртуальный терминал. А для эмуляторов терминала здесь могут быть значения pts/0, pts/1, pts/2 и т.п.

Ещё одно поле – TIME – это сколько времени процессор потратил на работу с данным процессом. Вы можете заметить, что здесь сплошные нули – потому что большинство этих процессов не требуют и секунды процессорного времени. Но если немного поработать с тем же браузером, то это время будет расти:
ps -ef | grep firefox
Кстати, чтобы мне не приходилось постоянно запускать эту команду, я могу использовать команду watсh:
watch "ps -ef | grep firefox"
Эта команда будет каждые 2 секунды запускать указанную команду. И так мы видим, что параметр TIME для нашего браузера постоянно увеличивается.
Ну и последнее – CMD – это команда, которая запустила процесс. Некоторые значения в квадратных скобках – для таких процессов ps не смог найти аргументов – обычно это процессы самого ядра.
Ладно, с выводом ps разобрались. Теперь мы знаем, где найти информацию о процессах. Но, помните, я говорил, что в Unix подобных системах придерживаются идеи «Всё есть файл»? И даже процессы у нас представлены в виде файлов. Но хранить информацию о процессах на жёстком диске нецелесообразно – какие-то процессы существуют доли секунд, какие-то появляются и удаляются сотнями – жёсткий диск не подходит для такого. А вот в оперативной памяти информацию о процессах можно спокойно хранить и представлять в виде файлов. Но раз уж речь идёт о файлах, то нам нужна файловая система. И вот ядро действительно создаёт так называемую виртуальную файловую систему, которая существует только в оперативной памяти.
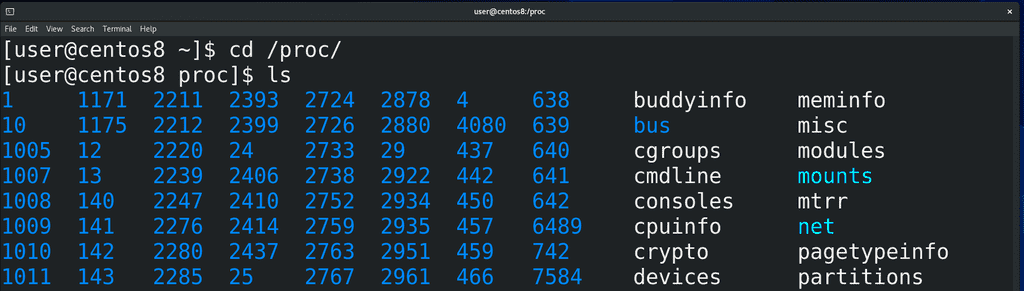
Вообще, этих виртуальных файловых систем несколько, они используются для разных задач, мы о них поговорим в другой раз. Сейчас нас интересует файловая система procfs. Она примонтирована в директорию /proc:
cd /proc ls
Если посмотреть содержимое этой директории, мы увидим кучу директорий и файлов. Директории вам ничего не напоминают? Именно, это номера процессов, т.е. pid-ы. Ядро операционной системы генерирует эту информацию налету, стоит нам посмотреть – мы увидим актуальную информацию.
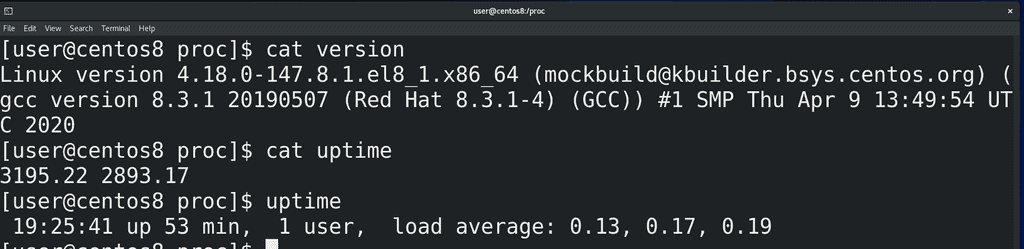
В этой директории кроме директорий процессов есть много других файлов – допустим, version:
сat version
показывает нам информацию о версии ядра или uptime:
cat uptime
информацию о том, сколько секунд включена система. Ну в секундах непонятно, поэтому легче использовать утилиту uptime. Кстати, постарайтесь самостоятельно найти, что означает второе значение в файле /proc/uptime и напишите в комментариях так, чтобы было понятно всем.
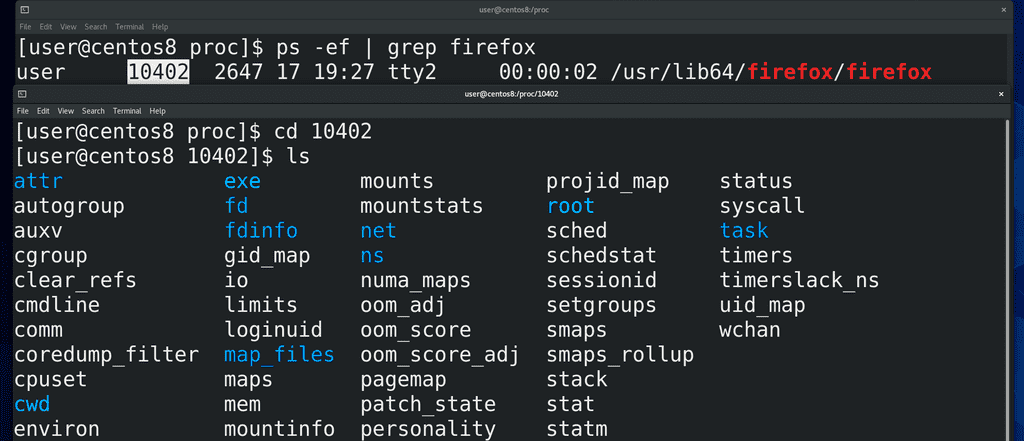
Ну и давайте посмотрим, что же такого в директориях процессов. Найдём pid процесса, допустим того-же firefox:
ps -ef | grep firefox
и зайдём в эту директорию:
сd pid ls
Тут у нас тоже куча файлов, которые относятся к нашему процессу. Эти файлы нужны не столько для людей, сколько для программ.
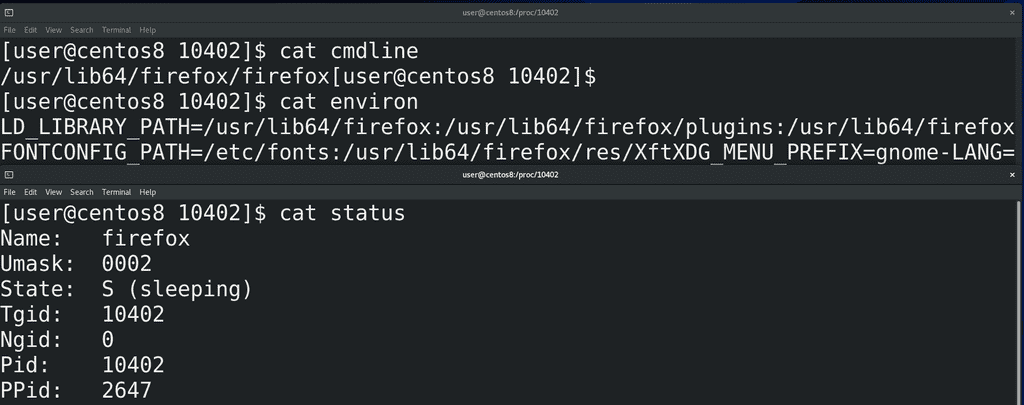
Какие-то из этих файлов и мы можем прочесть. Например, cmdline:
cat cmdline
Тут отображена команда, которая запустила процесс. Или environ:
cat environ
те переменные, которые передались процессу при запуске. Или status:
cat status
Какие-то из этих строчек понятны, а какие-то без гугла не разберёшь. Знать всё это не нужно, но, со временем, углубляясь в теорию или сталкиваясь с какими-то проблемами, вы начнёте разбираться в этих файлах.
© Copyright 2021, GNU Linux Pro, CC-BY-SA-4.0. Ревизия 5f665cc2 .
Изучаем процессы в Linux

В этой статье я хотел бы рассказать о том, какой жизненный путь проходят процессы в семействе ОС Linux. В теории и на примерах я рассмотрю как процессы рождаются и умирают, немного расскажу о механике системных вызовов и сигналов.
Данная статья в большей мере рассчитана на новичков в системном программировании и тех, кто просто хочет узнать немного больше о том, как работают процессы в Linux.
Всё написанное ниже справедливо к Debian Linux с ядром 4.15.0.
Введение
Системное программное обеспечение взаимодействует с ядром системы посредством специальных функций — системных вызовов. В редких случаях существует альтернативный API, например, procfs или sysfs, выполненные в виде виртуальных файловых систем.
Атрибуты процесса
Процесс в ядре представляется просто как структура с множеством полей (определение структуры можно прочитать здесь).
Но так как статья посвящена системному программированию, а не разработке ядра, то несколько абстрагируемся и просто акцентируем внимание на важных для нас полях процесса:
- Идентификатор процесса (pid)
- Открытые файловые дескрипторы (fd)
- Обработчики сигналов (signal handler)
- Текущий рабочий каталог (cwd)
- Переменные окружения (environ)
- Код возврата
Жизненный цикл процесса
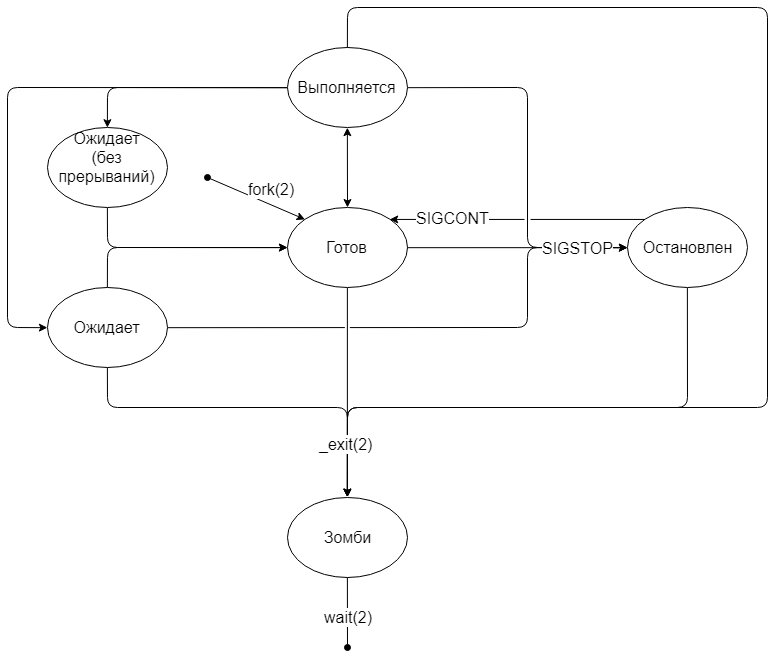
Рождение процесса
Только один процесс в системе рождается особенным способом — init — он порождается непосредственно ядром. Все остальные процессы появляются путём дублирования текущего процесса с помощью системного вызова fork(2) . После выполнения fork(2) получаем два практически идентичных процесса за исключением следующих пунктов:
- fork(2) возвращает родителю PID ребёнка, ребёнку возвращается 0;
- У ребёнка меняется PPID (Parent Process Id) на PID родителя.
Пример простой бесполезной программы с fork(2)
#include #include #include #include #include int main() < int pid = fork(); switch(pid) < case -1: perror("fork"); return -1; case 0: // Child printf("my pid = %i, returned pid = %i\n", getpid(), pid); break; default: // Parent printf("my pid = %i, returned pid = %i\n", getpid(), pid); break; >return 0; > $ gcc test.c && ./a.out my pid = 15594, returned pid = 15595 my pid = 15595, returned pid = 0 Состояние «готов»
Сразу после выполнения fork(2) переходит в состояние «готов».
Фактически, процесс стоит в очереди и ждёт, когда планировщик (scheduler) в ядре даст процессу выполняться на процессоре.
Состояние «выполняется»
Как только планировщик поставил процесс на выполнение, началось состояние «выполняется». Процесс может выполняться весь предложенный промежуток (квант) времени, а может уступить место другим процессам, воспользовавшись системным вывозом sched_yield .
Перерождение в другую программу
В некоторых программах реализована логика, в которой родительский процесс создает дочерний для решения какой-либо задачи. Ребёнок в данном случае решает какую-то конкретную проблему, а родитель лишь делегирует своим детям задачи. Например, веб-сервер при входящем подключении создаёт ребёнка и передаёт обработку подключения ему.
Однако, если нужно запустить другую программу, то необходимо прибегнуть к системному вызову execve(2) :
int execve(const char *filename, char *const argv[], char *const envp[]); или библиотечным вызовам execl(3), execlp(3), execle(3), execv(3), execvp(3), execvpe(3) :
int execl(const char *path, const char *arg, . /* (char *) NULL */); int execlp(const char *file, const char *arg, . /* (char *) NULL */); int execle(const char *path, const char *arg, . /*, (char *) NULL, char * const envp[] */); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execvpe(const char *file, char *const argv[], char *const envp[]); Все из перечисленных вызовов выполняют программу, путь до которой указан в первом аргументе. В случае успеха управление передаётся загруженной программе и в исходную уже не возвращается. При этом у загруженной программы остаются все поля структуры процесса, кроме файловых дескрипторов, помеченных как O_CLOEXEC , они закроются.
Как не путаться во всех этих вызовах и выбирать нужный? Достаточно постичь логику именования:
- Все вызовы начинаются с exec
- Пятая буква определяет вид передачи аргументов:
- l обозначает list, все параметры передаются как arg1, arg2, . NULL
- v обозначает vector, все параметры передаются в нуль-терминированном массиве;
Пример вызова /bin/cat —help через execve
#define _GNU_SOURCE #include int main() < char* args[] = < "/bin/cat", "--help", NULL >; execve("/bin/cat", args, environ); // Unreachable return 1; >$ gcc test.c && ./a.out Usage: /bin/cat [OPTION]. [FILE]. Concatenate FILE(s) to standard output. *Вывод обрезан*Семейство вызовов exec* позволяет запускать скрипты с правами на исполнение и начинающиеся с последовательности шебанг (#!).
Пример запуска скрипта с подмененным PATH c помощью execle
#define _GNU_SOURCE #include int main() < char* e[] = ; execle("/tmp/test.sh", "test.sh", NULL, e); // Unreachable return 1; >$ cat test.sh #!/bin/bash echo $0 echo $PATH $ gcc test.c && ./a.out /tmp/test.sh /habr:/rulezЕсть соглашение, которое подразумевает, что argv[0] совпадает с нулевым аргументов для функций семейства exec*. Однако, это можно нарушить.
Пример, когда cat становится dog с помощью execlp
#define _GNU_SOURCE #include int main() < execlp("cat", "dog", "--help", NULL); // Unreachable return 1; >$ gcc test.c && ./a.out Usage: dog [OPTION]. [FILE]. *Вывод обрезан*Любопытный читатель может заметить, что в сигнатуре функции int main(int argc, char* argv[]) есть число — количество аргументов, но в семействе функций exec* ничего такого не передаётся. Почему? Потому что при запуске программы управление передаётся не сразу в main. Перед этим выполняются некоторые действия, определённые glibc, в том числе подсчёт argc.
Состояние «ожидает»
Некоторые системные вызовы могут выполняться долго, например, ввод-вывод. В таких случаях процесс переходит в состояние «ожидает». Как только системный вызов будет выполнен, ядро переведёт процесс в состояние «готов».
В Linux так же существует состояние «ожидает», в котором процесс не реагирует на сигналы прерывания. В этом состоянии процесс становится «неубиваемым», а все пришедшие сигналы встают в очередь до тех пор, пока процесс не выйдет из этого состояния.
Ядро само выбирает, в какое из состояний перевести процесс. Чаще всего в состояние «ожидает (без прерываний)» попадают процессы, которые запрашивают ввод-вывод. Особенно заметно это при использовании удалённого диска (NFS) с не очень быстрым интернетом.Состояние «остановлен»
В любой момент можно приостановить выполнение процесса, отправив ему сигнал SIGSTOP. Процесс перейдёт в состояние «остановлен» и будет находиться там до тех пор, пока ему не придёт сигнал продолжать работу (SIGCONT) или умереть (SIGKILL). Остальные сигналы будут поставлены в очередь.
Завершение процесса
Ни одна программа не умеет завершаться сама. Они могут лишь попросить систему об этом с помощью системного вызова _exit или быть завершенными системой из-за ошибки. Даже когда возвращаешь число из main() , всё равно неявно вызывается _exit .
Хотя аргумент системного вызова принимает значение типа int, в качестве кода возврата берется лишь младший байт числа.Состояние «зомби»
Сразу после того, как процесс завершился (неважно, корректно или нет), ядро записывает информацию о том, как завершился процесс и переводит его в состояние «зомби». Иными словами, зомби — это завершившийся процесс, но память о нём всё ещё хранится в ядре.
Более того, это второе состояние, в котором процесс может смело игнорировать сигнал SIGKILL, ведь что мертво не может умереть ещё раз.Забытье
Код возврата и причина завершения процесса всё ещё хранится в ядре и её нужно оттуда забрать. Для этого можно воспользоваться соответствующими системными вызовами:
pid_t wait(int *wstatus); /* Аналогично waitpid(-1, wstatus, 0) */ pid_t waitpid(pid_t pid, int *wstatus, int options);Вся информация о завершении процесса влезает в тип данных int. Для получения кода возврата и причины завершения программы используются макросы, описанные в man-странице waitpid(2) .
Пример корректного завершения и получения кода возврата
#include #include #include #include #include int main() < int pid = fork(); switch(pid) < case -1: perror("fork"); return -1; case 0: // Child return 13; default: < // Parent int status; waitpid(pid, &status, 0); printf("exit normally? %s\n", (WIFEXITED(status) ? "true" : "false")); printf("child exitcode = %i\n", WEXITSTATUS(status)); break; >> return 0; >$ gcc test.c && ./a.out exit normally? true child exitcode = 13Пример некорректного завершения
Передача argv[0] как NULL приводит к падению.
#include #include #include #include #include int main() < int pid = fork(); switch(pid) < case -1: perror("fork"); return -1; case 0: // Child execl("/bin/cat", NULL); return 13; default: < // Parent int status; waitpid(pid, &status, 0); if(WIFEXITED(status)) < printf("Exit normally with code %i\n", WEXITSTATUS(status)); >if(WIFSIGNALED(status)) < printf("killed with signal %i\n", WTERMSIG(status)); >break; > > return 0; >$ gcc test.c && ./a.out killed with signal 6Бывают случаи, при которых родитель завершается раньше, чем ребёнок. В таких случаях родителем ребёнка станет init и он применит вызов wait(2) , когда придёт время.
После того, как родитель забрал информацию о смерти ребёнка, ядро стирает всю информацию о ребёнке, чтобы на его место вскоре пришёл другой процесс.
Благодарности
Спасибо Саше «Al» за редактуру и помощь в оформлении;
Спасибо Саше «Reisse» за понятные ответы на сложные вопросы.
Они стойко перенесли напавшее на меня вдохновение и напавший на них шквал моих вопросов.
- linux
- системное программирование
- Системное программирование
- C
- Разработка под Linux