Сводные таблицы в Pandas — швейцарский нож для аналитиков
Привет, Хабр! Меня зовут Панчин Денис, это мой первый пост и я хочу Вам рассказать о работе с сводными таблицами в Pandas. Сводные таблицы хорошо известны всем аналитикам по Excel. Это прекрасный инструмент, который помогает быстро получить различную информацию по массиву данных. Рассмотрим реализацию и тонкости сводных таблиц в Pandas.
Блокнот можно открыть здесь.
Использовать будем только столбцы ‘region’ (субъект РФ), ‘municipality’ (муниципальное образование), ‘year’ (год), ‘birth’ (число родившихся на 1000 человек населения), ‘wage’ (cреднемесячная номинальная начисленная заработная плата, руб.). Сразу оговорюсь, что Москва и Санкт-Петербург являются отдельными субъектами Российской Федерации и в этом датафрейме отсутствуют.
import pandas as pd import numpy as np df = pd.read_csv('Krupnie_goroda-RF_1985-2019_187_09.12.21/data.csv', sep=';') df = df[['region', 'municipality', 'year', 'birth', 'wage']] df.sample(7)Минимальную статистику можно получить использовав метод describe(include = ‘all’). Мы видим что у нас 4109 строки, по 81 региону и 202 городам. Средняя рождаемость на 1000 человек 11,39, минимальная — 3,4, максимальная — 36,1.
df.describe(include = 'all')Агрегирование
Если объяснять простыми словами, то агрегирование — это процесс приведения некого большого массива значений к некому сжатому по определенному параметру массиву значений. Например, среднее, медиана, количество, сумма.
df[['birth', 'wage']].agg(['mean', 'median', 'min', 'max'])Groupby
Но средняя температура по больнице нам не интересна, мы хотим знать победителей в лицо. Допустим нам нужно посмотреть средние значения с группировкой по городам и субъектам РФ. Для этого закономерно используем метод groupby([‘region’, ‘municipality’]).agg(‘mean’).
df_groupby = df.groupby(['region', 'municipality']).agg('mean') df_groupby.head(7)Обратите внимание, что колонки region и municipality стали индексами.
На этом мы не успокаиваемся и пытаемся выжать больше стат.данных: среднее, медиану, минимум, максимум.
agg_func_math = < 'birth': ['mean', 'median', 'min', 'max'], 'wage': ['mean', 'median', 'min', 'max'] >df.groupby(['region', 'municipality']).agg(agg_func_math).head(7)Посмотрим топ городов по зарплатам.
df.groupby(['region', 'municipality']).agg('mean').sort_values(by='wage', ascending=False).head(7)А что если посмотреть данные в разрезе по годам.
Pivot table
Ответим на этот вопрос чуть позже, а пока создадим сводную таблицу аналогичную той, что мы уже делали ранее.
df_pivot_table = df.pivot_table(index=['region', 'municipality']) df_pivot_table.head(7)Уже на этом этапе видно, что сводная таблица достаточно умная и сама агрегировала данные и посчитала средние значения.
Но если мы захотим расширить таблицу новыми значениями — медианой, то увидим, что конечный результат по структуре будет отличаться от того, что мы делали при использовании метода groupby.
df_pivot_table = df.pivot_table(index=['region', 'municipality'], values=['birth', 'wage'], aggfunc=[np.mean, np.median]) df_pivot_table.head(7)Так мы плавно подошли к тем преимуществам, которые делает сводные таблицы швейцарским ножом для аналитиков. Если используя groupby мы «укрупняли» строки по городам, то сейчас мы можем «развернуть» столбец, например, ‘year’ (год) и посмотреть данные в разрезе по годам.
df_pivot_table = df.pivot_table(index=['region', 'municipality'], values='birth', columns='year') df_pivot_table.head(7)И, конечно, данные в сводной таблице можно фильтровать. Создадим сводную таблицу и оставим в ней данные по городам, в которых рождаемость на 1000 человек превышает 12, зарплата выше 40.000 и отсортируем всё по убыванию рождаемости.
df2 = df.pivot_table(index=['region', 'municipality']) df2.query("`birth`>12 and `wage`>40000").sort_values(by='birth', ascending=False)Pivot
Всё было замечательно, но в Pandas кроме pivot_table есть ещё просто pivot. Посмотрим что это за зверь и чем они отличаются.
Создадим pivot: рождаемость в разрезе по регионам и годам.
df_pivot = df.pivot(index='region', values='birth', columns='year') df_pivot.head(7)Мы получили ошибку «Index contains duplicate entries, cannot reshape«. Что-то не так с индексами, попробуем создать pivot с индексами по городам, а не регионам.
df_pivot = df.pivot(index='municipality', values='birth', columns='year') df_pivot.head(7)Всё получилось. Как мы уже заметили всё дело в индексах. На самом деле всё в повторяющихся индексах. Как мы видели ранее в датафрейме есть позиции с несколькими городами в рамках одного субъекта, так получаются дублированные данные индексов с которыми не умеет работать pivot.
Вывод
Groupby, pivot и pivot_table удобные и привычные инструменты для работы с данными. Groupby позволяет кодом в одну строку получить агрегированные и сортированные данные, а pivot и pivot_table работать в более глубоком разрезе. Pivot_table предпочтителен, т.к. не ограничивает вас в уникальности значений в столбце индекса. И, конечно, все эти данные можно фильтровать под ваши запросы.
Сводные таблицы в Python

Сводные таблицы (pivot table) – невероятно удобный инструмент для анализа табличных данных. Эта статья рассказывает о том, как использовать элегантную функциональность сводных таблиц, реализованную в библиотеке Pandas, для исследования и анализа данных.
Возможность создавать сводные таблицы присутствует в электронных таблицах и других программах, оперирующих табличными данными. Сводная таблица принимает на входе данные из отдельных столбцов и группирует их, формируя двумерную таблицу, реализующую многомерное обобщение данных. Чтобы ощутить разницу между сводной таблицей и операцией GroupBy, можно представить себе сводную таблицу, как многомерный вариант агрегации посредством GroupBy. То есть данные разделяются, преобразуются и объединяются, но при этом разделение и объединение осуществляются не по одномерному индексу, а по двумерной сетке.
Преимущества сводных таблиц
Для примеров в этом разделе, мы будем использовать набор данных о пассажирах «Титаника», доступный посредством библиотеки seaborn.
import numpy as np import pandas as pd import seaborn as sns titanic = sns.load_dataset('titanic')
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
Этот набор данных содержит обширную информацию о каждом пассажире того злополучного рейса, в том числе пол, возраст, класс, стоимость билета и многое другое.
Реализация сводной таблицы вручную
Чтобы изучить эти данные, возможно, потребуется сгруппировать пассажиров по таким параметрам, как пол, выжил или нет, или на основании какой-либо комбинации параметров. Если вы прочитали предыдущий раздел, у вас может появиться искушение применить к этим данным операцию GroupBy. Например, давайте вычислим процент выживших для каждого пола:
titanic.groupby('sex')[['survived']].mean()
| survived | |
|---|---|
| sex | |
| female | 0.742038 |
| male | 0.188908 |
Сразу же можно сделать вывод о том, что из каждых четырех женщин, находившихся на борту, выжили три, в то время как из каждых пяти мужчин выжил только один!
Это интересная информация, но мы можем пойти дальше и выяснить взаимосвязь между показателем выживаемости и двумя другими параметрами, такими как пол и, например, класс. Используя терминологию GroupBy, мы могли бы сформулировать последовательность наших действий следующим образом: группируем по (group by) классу и полу, отбираем (select) выживших, применяем (apply) агрегацию по среднему, объединяем (combine) результирующие группы и преобразуем (unstack) иерархический индекс, чтобы раскрыть скрытую многомерность. Выразим это в коде:
titanic.groupby(['sex', 'class'])['survived'].aggregate('mean').unstack()
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
Теперь мы имеем четкое представление о том, как пол и класс повлияли на выживаемость, но код становится немного громоздким. Хотя каждый шаг этой последовательности вполне понятен в свете рассмотренных выше инструментов, тем не менее длинную строку кода достаточно трудно читать и использовать. Подобные операции широко распространены, в связи с чем библиотека Pandas имеет в своем составе специальный метод pivot_table, лаконично реализующий данный тип многомерной агрегации.
Синтаксис сводных таблиц
Ниже представлен эквивалент рассмотренной выше операции, реализованный с помощью метода pivot_table объекта DataFrame:
titanic.pivot_table('survived', index='sex', columns='class')
Это выражение намного легче читается, по сравнению с эквивалентным выражением для GroupBy, и дает тот же результат. Как можно было ожидать, в случае трансатлантического рейса начала 20-го века, больше шансов выжить было у женщин и пассажиров более высоких классов. Женщины из первого класса спаслись почти все (привет, Кейт!), в то время как из каждых десяти мужчин с билетами третьего класса выжил только один (прости, Лео!).
Многоуровневые сводные таблицы
Точно так же, как при использовании GroupBy, группирование в сводной таблице может иметь несколько уровней и задаваться посредством различных параметров. Например, в качестве третьего измерения нас может заинтересовать возраст. Мы разделим возраст на интервалы, с помощью функции pd.cut:
age = pd.cut(titanic['age'], [0, 18, 80]) titanic.pivot_table('survived', ['sex', age], 'class')
| class | First | Second | Third | |
|---|---|---|---|---|
| sex | age | |||
| female | (0, 18] | 0.909091 | 1.000000 | 0.511628 |
| (18, 80] | 0.972973 | 0.900000 | 0.423729 | |
| male | (0, 18] | 0.800000 | 0.600000 | 0.215686 |
| (18, 80] | 0.375000 | 0.071429 | 0.133663 |
Мы можем сделать то же самое со столбцами. Давайте добавим информацию о стоимости билета, используя функцию pd.qcut, чтобы автоматически рассчитать квантили:
fare = pd.qcut(titanic['fare'], 2) titanic.pivot_table('survived', ['sex', age], [fare, 'class'])
| fare | (14.454, 512.329] | [0, 14.454] | |||||
|---|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third | |
| sex | age | ||||||
| female | (0, 18] | 0.909091 | 1.000000 | 0.318182 | NaN | 1.000000 | 0.714286 |
| (18, 80] | 0.972973 | 0.914286 | 0.391304 | NaN | 0.880000 | 0.444444 | |
| male | (0, 18] | 0.800000 | 0.818182 | 0.178571 | NaN | 0.000000 | 0.260870 |
| (18, 80] | 0.391304 | 0.030303 | 0.192308 | 0 | 0.098039 | 0.125000 | |
В результате получим четырехмерную агрегацию, демонстрирующую взаимосвязь между соответствующими величинами.
Дополнительные параметры сводной таблицы
Полная сигнатура вызова метода pivot_table объекта DataFrame является следующей:
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True)
Выше мы рассмотрели три первых параметра. Теперь давайте обсудим остальные. Параметры fill_value и dropna задают способ обработки отсутствующих данных. Их использование не вызывает затруднений, поэтому мы не будем приводить примеры.
Параметр aggfunc задает тип агрегации. По умолчанию его значение равно ‘mean‘. Как и в случае GroupBy, тип агрегации можно задать либо с помощью предопределенной строки (например, ‘sum’, ‘mean’, ‘count’, ‘min’, ‘max’ и др.), либо посредством функции, реализующей агрегацию (например, np.sum(), min(), sum() и др.). Кроме того, этот параметр может быть задан в виде словаря, отображающего столбцы на любые из желаемых значений, перечисленных выше:
titanic.pivot_table(index='sex', columns='class', aggfunc=)
| fare | survived | |||||
|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third |
| sex | ||||||
| female | 106.125798 | 21.970121 | 16.118810 | 91 | 70 | 72 |
| male | 67.226127 | 19.741782 | 12.661633 | 45 | 17 | 47 |
Обратите внимание, в данном случае мы не задали параметр values, потому что он задается автоматически, когда параметр aggfunc представлен в виде отображения.
Иногда требуется вычислить обобщенные значения по каждой группе. Это можно сделать с помощью параметра margins:
titanic.pivot_table('survived', index='sex', columns='class', margins=True)
| class | First | Second | Third | All |
|---|---|---|---|---|
| sex | ||||
| female | 0.968085 | 0.921053 | 0.500000 | 0.742038 |
| male | 0.368852 | 0.157407 | 0.135447 | 0.188908 |
| All | 0.629630 | 0.472826 | 0.242363 | 0.383838 |
Представленный выше код автоматически дает нам процент выживших в зависимости от пола без учета класса, в зависимости от класса без учета пола, а также общий процент выживших, составляющий 38%.
Пример. Данные о рождаемости
В качестве более интересного примера давайте рассмотрим свободно доступные данные о рождаемости в США, предоставленные Центрами по контролю и профилактике заболеваний (Centers for Disease Control and Prevention, CDC). Данные можно загрузить по ссылке: https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv.
Этот набор данных был детально проанализирован группой Эндрю Джелмана (Andrew Gelman). Подробности можно найти в этой статье.
# shell command to download the data: !curl -O https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv births = pd.read_csv('births.csv')
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 258k 100 258k 0 0 1935k 0 --:--:-- --:--:-- --:--:-- 1943k
--------------------------------------------------------------------------- NameError Traceback (most recent call last) in () 2 get_ipython().system(u'curl -O https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv'>) 3 ----> 4 births = pd.read_csv('births.csv') NameError: name 'pd' is not defined
Набор данных имеет достаточно простую структуру: количество новорожденных сгруппировано по дате и полу.
births.head()
| year | month | day | gender | births | |
|---|---|---|---|---|---|
| 0 | 1969 | 1 | 1 | F | 4046 |
| 1 | 1969 | 1 | 1 | M | 4440 |
| 2 | 1969 | 1 | 2 | F | 4454 |
| 3 | 1969 | 1 | 2 | M | 4548 |
| 4 | 1969 | 1 | 3 | F | 4548 |
Детально разобраться в этих данных нам поможет сводная таблица. Давайте добавим столбец «decade» (десятилетие) и посмотрим, как изменялось количество новорожденных каждого пола в зависимости от десятилетия:
births['decade'] = 10 * (births['year'] // 10) births.pivot_table('births', index='decade', columns='gender', aggfunc='sum')
| gender | F | M |
|---|---|---|
| decade | ||
| 1960 | 1753634 | 1846572 |
| 1970 | 16263075 | 17121550 |
| 1980 | 18310351 | 19243452 |
| 1990 | 19479454 | 20420553 |
| 2000 | 18229309 | 19106428 |
Сразу же видно, что в каждом десятилетии количество новорожденных мальчиков превышает количество новорожденных девочек. Чтобы подробнее изучить эту тенденцию, давайте визуализируем общее количество новорожденных по годам с помощью встроенных в библиотеку Pandas инструментов визуализации:
%matplotlib inline import matplotlib.pyplot as plt sns.set() # use seaborn styles births.pivot_table('births', index='year', columns='gender', aggfunc='sum').plot() plt.ylabel('total births per year');
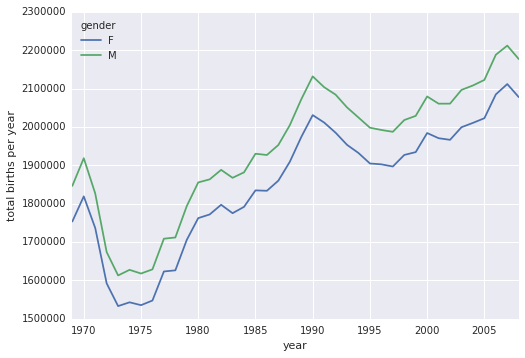
С помощью простой сводной таблицы и метода plot(), мы быстро получаем наглядное представление о динамике рождаемости мальчиков и девочек в зависимости от года. При оценке на глаз видно, что в течение последних 50-ти лет количество новорожденных мальчиков примерно на 5% превышало количество новорожденных девочек.
Продолжаем исследование данных
Хотя это необязательно относится к сводным таблицам, тем не менее существует дополнительная интересная информация, которую мы можем извлечь из этого набора данных с помощью рассмотренных инструментов библиотеки Pandas. Необходимо начать с очистки данных, чтобы избавиться от аномальных значений, связанных с несуществующими датами, такими как 31-е июня или 99-е июня. Мы удалим все аномальные значения с помощью операции робастного ограничения среднеквадратичного отклонения (robust sigma-clipping):
# Some data is mis-reported; e.g. June 31st, etc. # remove these outliers via robust sigma-clipping quartiles = np.percentile(births['births'], [25, 50, 75]) mu = quartiles[1] sig = 0.7413 * (quartiles[2] - quartiles[0]) births = births.query('(births > @mu - 5 * @sig) & (births < @mu + 5 * @sig)')
Затем преобразуем значения в столбце «day» к целочисленному типу. Исходно эти значения являются строками, потому что некоторые из них представляют собой строку «null»:
# set 'day' column to integer; it originally was a string due to nulls births['day'] = births['day'].astype(int)
Наконец, мы можем объединить день, месяц и год, чтобы создать индекс «date» (дата). Это позволит нам легко вычислить день недели, соответствующий каждой строке:
# create a datetime index from the year, month, day births.index = pd.to_datetime(10000 * births.year + 100 * births.month + births.day, format='%Y%m%d') births['dayofweek'] = births.index.dayofweek
Теперь можно визуализировать динамику рождаемости по дням недели для разных десятилетий:
import matplotlib.pyplot as plt import matplotlib as mpl births.pivot_table('births', index='dayofweek', columns='decade', aggfunc='mean').plot() plt.gca().set_xticklabels(['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun']) plt.ylabel('mean births by day');
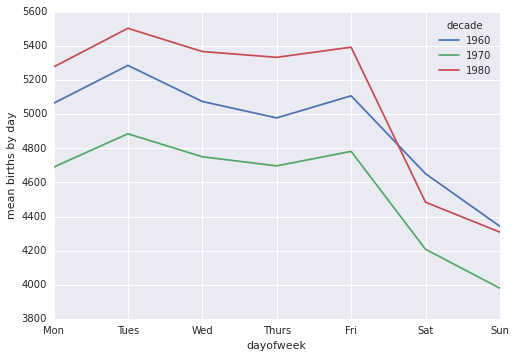
Очевидно, что в будние дни на свет появилось немного больше новорожденных, чем в выходные! Обратите внимание, 1990-е и 2000-е годы отсутствуют, потому что, начиная с 1989 года, в отчетах CDC присутствует только количество новорожденных по месяцам, а не по дням.
Давайте визуализируем еще один интересный показатель – среднее количество новорожденных, приходящееся на каждый день года. Мы можем реализовать это, создав массив дат для определенного года, выбрав при этом високосный год, чтобы учесть 29-е февраля.
# Choose a leap year to display births by date dates = [pd.datetime(2012, month, day) for (month, day) in zip(births['month'], births['day'])]
Теперь сгруппируем данные по дню года и визуализируем результат. Дополнительно выведем на график подписи для тех дней, на которые приходятся некоторые праздники, отмечаемые в США:
# Plot the results fig, ax = plt.subplots(figsize=(8, 6)) births.pivot_table('births', dates).plot(ax=ax) # Label the plot ax.text('2012-1-1', 3950, "New Year's Day") ax.text('2012-7-4', 4250, "Independence Day", ha='center') ax.text('2012-9-4', 4850, "Labor Day", ha='center') ax.text('2012-10-31', 4600, "Halloween", ha='right') ax.text('2012-11-25', 4450, "Thanksgiving", ha='center') ax.text('2012-12-25', 3800, "Christmas", ha='right') ax.set(title='USA births by day of year (1969-1988)', ylabel='average daily births', xlim=('2011-12-20','2013-1-10'), ylim=(3700, 5400)); # Format the x axis with centered month labels ax.xaxis.set_major_locator(mpl.dates.MonthLocator()) ax.xaxis.set_minor_locator(mpl.dates.MonthLocator(bymonthday=15)) ax.xaxis.set_major_formatter(plt.NullFormatter()) ax.xaxis.set_minor_formatter(mpl.dates.DateFormatter('%h'));
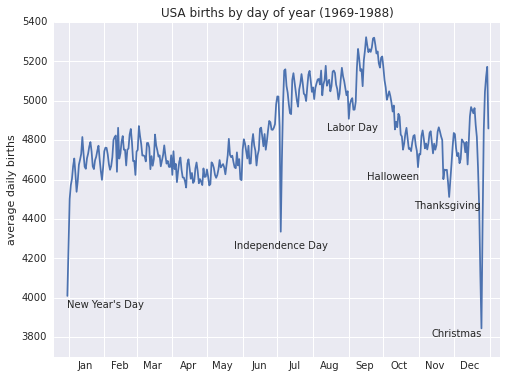
Низкая рождаемость в праздничные дни впечатляет, но это скорее результат выбора даты для плановых или вынужденных родов, чем следствие каких-либо глубоких психосоматических причин.
Эта небольшая статья должна дать вам хорошее представление о том, как разнообразные инструменты из библиотеки Pandas могут быть объединены вместе и использованы для извлечения информации из различных наборов данных. В следующих статьях мы рассмотрим более сложные подходы к анализу этих и других данных!
Pandas: как создать сводную таблицу с суммой значений
Вы можете использовать следующий базовый синтаксис для создания сводной таблицы в pandas, которая отображает сумму значений в определенных столбцах:
pd.pivot_table(df, values='col1', index='col2', columns='col3', aggfunc='sum') В следующем примере показано, как использовать этот синтаксис на практике.
Пример: создание сводной таблицы Pandas с суммой значений
Предположим, у нас есть следующий кадр данных pandas, который содержит информацию о различных баскетболистах:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team position points 0 A G 4 1 A G 4 2 A F 6 3 A F 8 4 B G 9 5 B F 5 6 B F 5 7 B F 12 В следующем коде показано, как создать сводную таблицу в pandas, которая показывает сумму значений «баллов» для каждой «команды» и «позиции» в DataFrame:
#create pivot table df_pivot = pd.pivot_table(df, values='points', index='team', columns='position', aggfunc='sum') #view pivot table print(df_pivot) position F G team A 14 8 B 22 9 Из вывода мы видим:
- Игроки команды A на позиции F набрали в общей сложности 14 очков.
- Игроки команды А на позиции G набрали в сумме 8 очков.
- Игроки команды B на позиции F набрали в общей сложности 22 очка.
- Игроки команды B на позиции G набрали в сумме 9 очков.
Обратите внимание, что мы также можем использовать аргумент margin для отображения сумм маржи в сводной таблице:
#create pivot table with margins df_pivot = pd.pivot_table(df, values='points', index='team', columns='position', aggfunc='sum', margins= True , margins_name='Sum') #view pivot table print(df_pivot) position F G Sum team A 14 8 22 B 22 9 31 Sum 36 17 53 В сводной таблице теперь отображаются суммы строк и суммы столбцов.
Примечание.Полную документацию по функции pandas pivot_table() можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Введение в pandas: анализ данных на Python

4 Март 2017 , Python, 751184 просмотров, Introduction to pandas: data analytics in Python
pandas это высокоуровневая Python библиотека для анализа данных. Почему я её называю высокоуровневой, потому что построена она поверх более низкоуровневой библиотеки NumPy (написана на Си), что является большим плюсом в производительности. В экосистеме Python, pandas является наиболее продвинутой и быстроразвивающейся библиотекой для обработки и анализа данных. В своей работе мне приходится пользоваться ею практически каждый день, поэтому я пишу эту краткую заметку для того, чтобы в будущем ссылаться к ней, если вдруг что-то забуду. Также надеюсь, что читателям блога заметка поможет в решении их собственных задач с помощью pandas, и послужит небольшим введением в возможности этой библиотеки.
DataFrame и Series
Чтобы эффективно работать с pandas, необходимо освоить самые главные структуры данных библиотеки: DataFrame и Series. Без понимания что они из себя представляют, невозможно в дальнейшем проводить качественный анализ.
Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
>>> import pandas as pd >>> my_series = pd.Series([5, 6, 7, 8, 9, 10]) >>> my_series 0 5 1 6 2 7 3 8 4 9 5 10 dtype: int64 >>> В строковом представлении объекта Series, индекс находится слева, а сам элемент справа. Если индекс явно не задан, то pandas автоматически создаёт RangeIndex от 0 до N-1, где N общее количество элементов. Также стоит обратить, что у Series есть тип хранимых элементов, в нашем случае это int64, т.к. мы передали целочисленные значения.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
>>> my_series.index RangeIndex(start=0, stop=6, step=1) >>> my_series.values array([ 5, 6, 7, 8, 9, 10], dtype=int64) Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
>>> my_series[4] 9 Индексы можно задавать явно:
>>> my_series2 = pd.Series([5, 6, 7, 8, 9, 10], index=['a', 'b', 'c', 'd', 'e', 'f']) >>> my_series2['f'] 10 Делать выборку по нескольким индексам и осуществлять групповое присваивание:
>>> my_series2[['a', 'b', 'f']] a 5 b 6 f 10 dtype: int64 >>> my_series2[['a', 'b', 'f']] = 0 >>> my_series2 a 0 b 0 c 7 d 8 e 9 f 0 dtype: int64 Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
>>> my_series2[my_series2 > 0] c 7 d 8 e 9 dtype: int64 >>> my_series2[my_series2 > 0] * 2 c 14 d 16 e 18 dtype: int64 Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
>>> my_series3 = pd.Series() >>> my_series3 a 5 b 6 c 7 d 8 dtype: int64 >>> 'd' in my_series3 True У объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
>>> my_series3.name = 'numbers' >>> my_series3.index.name = 'letters' >>> my_series3 letters a 5 b 6 c 7 d 8 Name: numbers, dtype: int64 Индекс можно поменять "на лету", присвоив список атрибуту index объекта Series
>>> my_series3.index = ['A', 'B', 'C', 'D'] >>> my_series3 A 5 B 6 C 7 D 8 Name: numbers, dtype: int64 Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
>>> df = pd.DataFrame(< . 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], . 'population': [17.04, 143.5, 9.5, 45.5], . 'square': [2724902, 17125191, 207600, 603628] . >) >>> df country population square 0 Kazakhstan 17.04 2724902 1 Russia 143.50 17125191 2 Belarus 9.50 207600 3 Ukraine 45.50 603628 Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
>>> df['country'] 0 Kazakhstan 1 Russia 2 Belarus 3 Ukraine Name: country, dtype: object >>> type(df['country'])
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
>>> df.columns Index([u'country', u'population', u'square'], dtype='object') >>> df.index RangeIndex(start=0, stop=4, step=1) В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или "на лету":
>>> df = pd.DataFrame(< . 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], . 'population': [17.04, 143.5, 9.5, 45.5], . 'square': [2724902, 17125191, 207600, 603628] . >, index=['KZ', 'RU', 'BY', 'UA']) >>> df country population square KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628 >>> df.index = ['KZ', 'RU', 'BY', 'UA'] >>> df.index.name = 'Country Code' >>> df country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628 Как видно, индексу было задано имя - Country Code. Отмечу, что объекты Series из DataFrame будут иметь те же индексы, что и объект DataFrame:
>>> df['country'] Country Code KZ Kazakhstan RU Russia BY Belarus UA Ukraine Name: country, dtype: object Доступ к строкам по индексу возможен несколькими способами:
- .loc - используется для доступа по строковой метке
- .iloc - используется для доступа по числовому значению (начиная от 0)
>>> df.loc['KZ'] country Kazakhstan population 17.04 square 2724902 Name: KZ, dtype: object >>> df.iloc[0] country Kazakhstan population 17.04 square 2724902 Name: KZ, dtype: object Можно делать выборку по индексу и интересующим колонкам:
>>> df.loc[['KZ', 'RU'], 'population'] Country Code KZ 17.04 RU 143.50 Name: population, dtype: float64 Как можно заметить, .loc в квадратных скобках принимает 2 аргумента: интересующий индекс, в том числе поддерживается слайсинг и колонки.
>>> df.loc['KZ':'BY', :] country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 Фильтровать DataFrame с помощью т.н. булевых массивов:
>>> df[df.population > 10][['country', 'square']] country square Country Code KZ Kazakhstan 2724902 RU Russia 17125191 UA Ukraine 603628 Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df['population'] это одно и то же.
Сбросить индексы можно вот так:
>>> df.reset_index() Country Code country population square 0 KZ Kazakhstan 17.04 2724902 1 RU Russia 143.50 17125191 2 BY Belarus 9.50 207600 3 UA Ukraine 45.50 603628 pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
>>> df['density'] = df['population'] / df['square'] * 1000000 >>> df country population square density Country Code KZ Kazakhstan 17.04 2724902 6.253436 RU Russia 143.50 17125191 8.379469 BY Belarus 9.50 207600 45.761079 UA Ukraine 45.50 603628 75.377550 Не нравится новый столбец? Не проблема, удалим его:
>>> df.drop(['density'], axis='columns') country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628 Особо ленивые могут просто написать del df['density'].
Переименовывать столбцы нужно через метод rename:
>>> df = df.rename(columns=) >>> df country_code country population square 0 KZ Kazakhstan 17.04 2724902 1 RU Russia 143.50 17125191 2 BY Belarus 9.50 207600 3 UA Ukraine 45.50 603628
В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
Чтение и запись данных
pandas поддерживает все самые популярные форматы хранения данных: csv, excel, sql, буфер обмена, html и многое другое:
Чаще всего приходится работать с csv-файлами. Например, чтобы сохранить наш DataFrame со странами, достаточно написать:
>>> df.to_csv('filename.csv')Функции to_csv ещё передаются различные аргументы (например, символ разделителя между колонками) о которых подробнее можно узнать в официальной документации.
Считать данные из csv-файла и превратить в DataFrame можно функцией read_csv.
>>> df = pd.read_csv('filename.csv', sep=',') Аргумент sep указывает разделитесь столбцов. Существует ещё масса способов сформировать DataFrame из различных источников, но наиболее часто используют CSV, Excel и SQL. Например, с помощью функции read_sql, pandas может выполнить SQL запрос и на основе ответа от базы данных сформировать необходимый DataFrame. За более подробной информацией стоит обратиться к официальной документации.
Группировка и агрегирование в pandas
Группировка данных один из самых часто используемых методов при анализе данных. В pandas за группировку отвечает метод .groupby. Я долго думал какой пример будет наиболее наглядным, чтобы продемонстрировать группировку, решил взять стандартный набор данных (dataset), использующийся во всех курсах про анализ данных — данные о пассажирах Титаника. Скачать CSV файл можно тут.
>>> titanic_df = pd.read_csv('titanic.csv') >>> print(titanic_df.head()) PassengerID Name PClass Age \ 0 1 Allen, Miss Elisabeth Walton 1st 29.00 1 2 Allison, Miss Helen Loraine 1st 2.00 2 3 Allison, Mr Hudson Joshua Creighton 1st 30.00 3 4 Allison, Mrs Hudson JC (Bessie Waldo Daniels) 1st 25.00 4 5 Allison, Master Hudson Trevor 1st 0.92 Sex Survived SexCode 0 female 1 1 1 female 0 1 2 male 0 0 3 female 0 1 4 male 1 0 Необходимо подсчитать, сколько женщин и мужчин выжило, а сколько нет. В этом нам поможет метод .groupby.
>>> print(titanic_df.groupby(['Sex', 'Survived'])['PassengerID'].count()) Sex Survived female 0 154 1 308 male 0 709 1 142 Name: PassengerID, dtype: int64 А теперь проанализируем в разрезе класса кабины:
>>> print(titanic_df.groupby(['PClass', 'Survived'])['PassengerID'].count()) PClass Survived * 0 1 1st 0 129 1 193 2nd 0 160 1 119 3rd 0 573 1 138 Name: PassengerID, dtype: int64 Сводные таблицы в pandas
Термин "сводная таблица" хорошо известен тем, кто не по наслышке знаком с инструментом Microsoft Excel или любым иным, предназначенным для обработки и анализа данных. В pandas сводные таблицы строятся через метод .pivot_table. За основу возьмём всё тот же пример с Титаником. Например, перед нами стоит задача посчитать сколько всего женщин и мужчин было в конкретном классе корабля:
>>> titanic_df = pd.read_csv('titanic.csv') >>> pvt = titanic_df.pivot_table(index=['Sex'], columns=['PClass'], values='Name', aggfunc='count') В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
>>> print(pvt.loc['female', ['1st', '2nd', '3rd']]) PClass 1st 143.0 2nd 107.0 3rd 212.0 Name: female, dtype: float64 Всё очень просто.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
>>> import pandas as pd >>> df = pd.read_csv('apple.csv', index_col='Date', parse_dates=True) >>> df = df.sort_index() >>> print(df.info()) DatetimeIndex: 1258 entries, 2017-02-22 to 2012-02-23 Data columns (total 6 columns): Open 1258 non-null float64 High 1258 non-null float64 Low 1258 non-null float64 Close 1258 non-null float64 Volume 1258 non-null int64 Adj Close 1258 non-null float64 dtypes: float64(5), int64(1) memory usage: 68.8 KB Здесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
>>> df.loc['2012-Feb', 'Close'].mean() 528.4820021999999 А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
>>> df.loc['2012-Feb':'2015-Feb', 'Close'].mean() 430.43968317018414 А что если нам нужно узнать среднюю цену закрытия по неделям?!
>>> df.resample('W')['Close'].mean() Date 2012-02-26 519.399979 2012-03-04 538.652008 2012-03-11 536.254004 2012-03-18 576.161993 2012-03-25 600.990001 2012-04-01 609.698003 2012-04-08 626.484993 2012-04-15 623.773999 2012-04-22 591.718002 2012-04-29 590.536005 2012-05-06 579.831995 2012-05-13 568.814001 2012-05-20 543.593996 2012-05-27 563.283995 2012-06-03 572.539994 2012-06-10 570.124002 2012-06-17 573.029991 2012-06-24 583.739993 2012-07-01 574.070004 2012-07-08 601.937489 2012-07-15 606.080008 2012-07-22 607.746011 2012-07-29 587.951999 2012-08-05 607.217999 2012-08-12 621.150003 2012-08-19 635.394003 2012-08-26 663.185999 2012-09-02 670.611995 2012-09-09 675.477503 2012-09-16 673.476007 . 2016-08-07 105.934003 2016-08-14 108.258000 2016-08-21 109.304001 2016-08-28 107.980000 2016-09-04 106.676001 2016-09-11 106.177498 2016-09-18 111.129999 2016-09-25 113.606001 2016-10-02 113.029999 2016-10-09 113.303999 2016-10-16 116.860000 2016-10-23 117.160001 2016-10-30 115.938000 2016-11-06 111.057999 2016-11-13 109.714000 2016-11-20 108.563999 2016-11-27 111.637503 2016-12-04 110.587999 2016-12-11 111.231999 2016-12-18 115.094002 2016-12-25 116.691998 2017-01-01 116.642502 2017-01-08 116.672501 2017-01-15 119.228000 2017-01-22 119.942499 2017-01-29 121.164000 2017-02-05 125.867999 2017-02-12 131.679996 2017-02-19 134.978000 2017-02-26 136.904999 Freq: W-SUN, Name: Close, dtype: float64 Resampling мощный инструмент при работе с временными рядами (time series), помогающий переформировать выборку так, как удобно вам. Метод resample первым аргументом принимает строку rule. Все доступные значения можно найти в документации.
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
>>> import matplotlib.pyplot as plt >>> new_sample_df = df.loc['2012-Feb':'2017-Feb', ['Close']] >>> new_sample_df.plot() >>> plt.show() И видим вот такую картину:
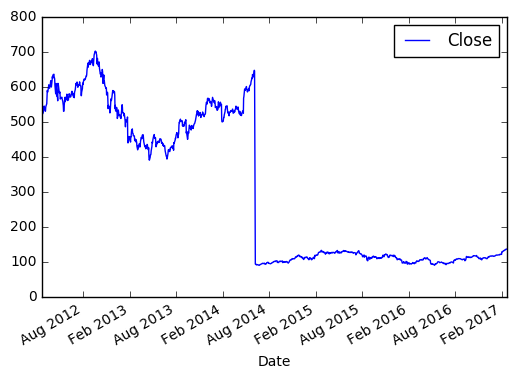
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 😉
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.
Полезные ссылки
- pandas cheatsheet
- Официальная документация pandas
- Почему Python
- Python Data Science Handbook
Интересные записи:
- Работа с MySQL в Python
- Django Channels: работа с WebSocket и не только
- Руководство по работе с HTTP в Python. Библиотека requests
- Что нового появилось в Django Channels?
- Pyenv: удобный менеджер версий python
- Celery: начинаем правильно
- FastAPI, asyncio и multiprocessing
- Почему Python?
- Обзор Python 3.9
- Введение в logging на Python
- Работа с PostgreSQL в Python
- Python-RQ: очередь задач на базе Redis
- Как написать Telegram бота: практическое руководство
- Разворачиваем Django приложение в production на примере Telegram бота
- Авторизация через Telegram в Django и Python
- Django, RQ и FakeRedis
- Обзор Python 3.8
- Итоги первой встречи Python программистов в Алматы
- Интеграция Trix editor в Django
- Участие в подкасте TalkPython
- Строим Data Pipeline на Python и Luigi
- Видео презентации ETL на Python
- Авторизация через Telegram в Django приложении