Теория нейронных сетей
 Обобщение данных в нейронных сетях
Обобщение данных в нейронных сетях

Разложение bias-variance
Способность нейронной сети к обобщению, переобучение, обучающая, валидационная и тестовая выборки, риск для квадратичной функции потерь, разложение bias-variance, связь сложности нейронной сети и способности к обобщению

Кросс-валидация
Оценка точности нейросетевой модели, кросс-валидация, метод Монте-Карло, k-fold, holdout, leave-one-out кросс-валидация, стратификация выборки при кросс-валидации, внутренняя кросс-валидация

Методы регуляризации нейронных сетей
Подходы к повышению обобщающей способности нейронной сети, методы регуляризации нейронных сетей, L1 и L2 регуляризация весов, отбор признаков при обучении нейронной сети, ранний останов процедуры обучения, аугментация данных, инъекция шума

Dropout и Batch normailzation
Идея dropout-регуляризации слоёв нейронной сети, обучение dropout-слоя, dropout как крайний случай бэггинга, проблема смещения информационного потока в нейронных сетях (internal covariate shift), идея batch-нормализации скрытых слоёв нейронной сети, обучение batch normailzation-слоя, обратное распространение ошибки через batch normailzation-слой
Сверточные нейронные сети
Сверточная нейронная сеть (англ. convolutional neural network, CNN) — специальная архитектура нейронных сетей, предложенная Яном Лекуном [1] , изначально нацеленная на эффективное распознавание изображений.
Свертка
Рисунок 1.Пример свертки двух матриц размера 5×5 и 3×3
Свертка (англ. convolution) — операция над парой матриц [math]A[/math] (размера [math]n_x\times n_y[/math] ) и [math]B[/math] (размера [math]m_x \times m_y[/math] ), результатом которой является матрица [math]C = A * B[/math] размера [math](n_x-m_x+1)\times (n_y-m_y+1)[/math] . Каждый элемент результата вычисляется как скалярное произведение матрицы [math]B[/math] и некоторой подматрицы [math]A[/math] такого же размера (подматрица определяется положением элемента в результате). То есть, [math]C_ = \sum_^\sum_^A_B_[/math] . На Рисунке 1 можно видеть, как матрица [math]B[/math] «двигается» по матрице [math]A[/math] , и в каждом положении считается скалярное произведение матрицы [math]B[/math] и той части матрицы [math]A[/math] , на которую она сейчас наложена. Получившееся число записывается в соответствующий элемент результата.
Логический смысл свертки такой — чем больше величина элемента свертки, тем больше эта часть матрицы [math]A[/math] была похожа на матрицу [math]B[/math] (похожа в смысле скалярного произведения). Поэтому матрицу [math]A[/math] называют изображением, а матрицу [math]B[/math] — фильтром или образцом.
Структура сверточной нейронной сети
В сверточной нейронной сети выходы промежуточных слоев образуют матрицу (изображение) или набор матриц (несколько слоёв изображения). Так, например, на вход сверточной нейронной сети можно подавать три слоя изображения (R-, G-, B-каналы изображения). Основными видами слоев в сверточной нейронной сети являются сверточные слои (англ. convolutional layer), пулинговые слои (англ. pooling layer) и полносвязные слои (англ. fully-connected layer).
Сверточный слой
Рисунок 2.Пример свертки двух матриц с дополнением нулями и сдвигом 2
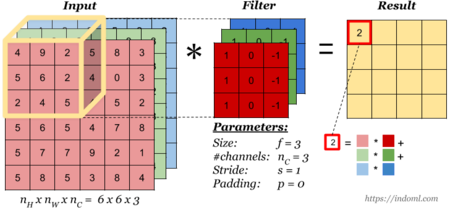
Рисунок 3.Пример свертки с трехмерным ядром
Сверточный слой нейронной сети представляет из себя применение операции свертки к выходам с предыдущего слоя, где веса ядра свертки являются обучаемыми параметрами. Еще один обучаемый вес используется в качестве константного сдвига (англ. bias). При этом есть несколько важных деталей:
- В одном сверточном слое может быть несколько сверток. В этом случае для каждой свертки на выходе получится своё изображение. Например, если вход имел размерность [math]w\times h[/math] , а в слое было [math]n[/math] сверток с ядром размерности [math]k_x\times k_y[/math] , то выход будет иметь размерность [math]n\times(w — k_x + 1)\times(h — k_y + 1)[/math] ;
- Ядра свертки могут быть трёхмерными. Свертка трехмерного входа с трехмерным ядром происходит аналогично, просто скалярное произведение считается еще и по всем слоям изображения. Например, для усреднения информации о цветах исходного изображения, на первом слое можно использовать свертку размерности [math]3\times w \times h[/math] . На выходе такого слоя будет уже одно изображение (вместо трёх);
- Можно заметить, что применение операции свертки уменьшает изображение. Также пиксели, которые находятся на границе изображения участвуют в меньшем количестве сверток, чем внутренние. В связи с этим в сверточных слоях используется дополнение изображения (англ. padding). Выходы с предыдущего слоя дополняются пикселями так, чтобы после свертки сохранился размер изображения. Такие свертки называют одинаковыми (англ. same convolution), а свертки без дополнения изображения называются правильными (англ. valid convolution). Среди способов, которыми можно заполнить новые пиксели, можно выделить следующие:
- zero shift: 00[ABC]00 ;
- border extension: AA[ABC]CC ;
- mirror shift: BA[ABC]CB ;
- cyclic shift: BC[ABC]AB .
- Еще одним параметром сверточного слоя является сдвиг (англ. stride). Хоть обычно свертка применяется подряд для каждого пикселя, иногда используется сдвиг, отличный от единицы — скалярное произведение считается не со всеми возможными положениями ядра, а только с положениями, кратными некоторому сдвигу [math]s[/math] . Тогда, если если вход имел размерность [math]w\times h[/math] , а ядро свертки имело размерность [math]k_x\times k_y[/math] и использовался сдвиг [math]s[/math] , то выход будет иметь размерность [math]\lfloor\frac+ 1\rfloor\times\lfloor\frac+ 1\rfloor[/math] .
Пулинговый слой

Рисунок 4. Пример операции пулинга с функцией максимума
Пулинговый слой призван снижать размерность изображения. Исходное изображение делится на блоки размером [math]w\times h[/math] и для каждого блока вычисляется некоторая функция. Чаще всего используется функция максимума (англ. max pooling) или (взвешенного) среднего (англ. (weighted) average pooling). Обучаемых параметров у этого слоя нет. Основные цели пулингового слоя:
- уменьшение изображения, чтобы последующие свертки оперировали над большей областью исходного изображения;
- увеличение инвариантности выхода сети по отношению к малому переносу входа;
- ускорение вычислений.
Inception module
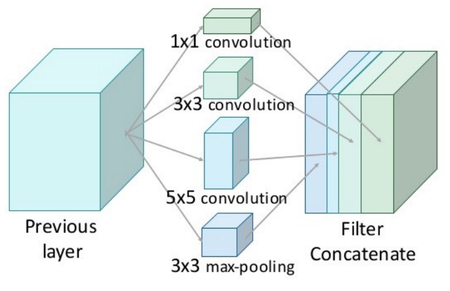
Рисунок 5.Inception module
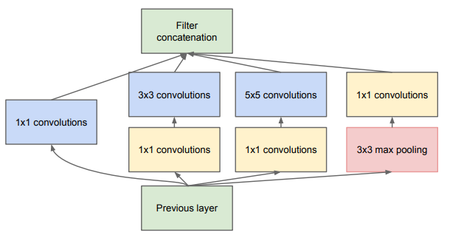
Рисунок 6.Inception module с сокращением размерностей
Inception module — это специальный слой нейронной сети, который был предложен в работе [2] , в которой была представлена сеть GoogLeNet. Основная цель этого модуля заключается в следующем. Авторы предположили, что каждый элемент предыдущего слоя соответствует определенной области исходного изображения. Каждая свертка по таким элементам будет увеличивать область исходного изображения, пока элементы на последних слоях не будут соответствовать всему изображению целиком. Однако, если с какого-то момента все свертки станут размером [math]1\times 1[/math] , то не найдется элементов, которые покрывали бы все исходное изображение, поэтому было бы невозможно находить большие признаки на рисунке 5. Чтобы решить эту проблему, авторы предложили так называемый inception module — конкатенацию выходов для сверток размера [math]1\times 1[/math] , [math]3\times 3[/math] , [math]5\times 5[/math] , а также операции max pooling’а с ядром [math]3\times 3[/math] . К сожалению, подобный наивный подход (англ. naive inception module) приводит к резкому увеличению слоев изображения, что не позволяет построить с его использованием глубокую нейронную сеть. Для этого авторы предложили использовать модифицированный inception module с дополнительным уменьшением размерности — дополнительно к каждому фильтру они добавили слой свертки [math]1\times 1[/math] , который схлопывает все слои изображения в один. Это позволяет сохранить малое число слоев, с сохранением полезной информации о изображении.
Residual block
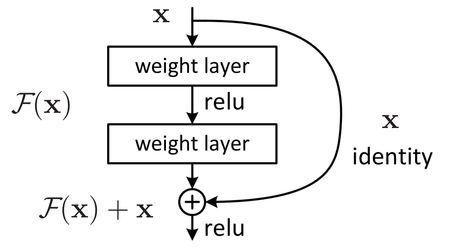
Рисунок 7.Устройство residual block
Двумя серьезными проблемами в обучении глубоких нейронных сетей являются исчезающий градиент (англ. vanishing gradient) и взрывающийся градиент (англ. exploding gradient). Они возникают из-за того, что при дифференцировании по цепному правилу, до глубоких слоев нейронной сети доходит очень маленькая величина градиента (из-за многократного домножения на небольшие величины на предыдущих слоях). Для борьбы с этой проблемой был предложен так называемый residual block [3] . Идея заключается в том, чтобы взять пару слоёв (например, сверточных), и добавить дополнительную связь, которая проходит мимо этих слоёв. Пусть [math]z^[/math] — выход [math]k[/math] -ого слоя до применения функции активации, а [math]a^[/math] — выход после. Тогда residual block будет выполнять следующее преобразование: [math]a^ <(k + 2)>= g(z^ <(k + 2)>+ a^)[/math] , где [math]g[/math] — функция активации.
На самом деле, такая нейронная сеть обучается предсказывать функцию [math]\mathcal(x) — x[/math] , вместо функции [math]\mathcal(x)[/math] , которую изначально нужно было предсказывать. Для компенсации этой разницы и вводится это замыкающее соединение (англ. shortcut connection), которое добавляет недостающий [math]x[/math] к функции. Предположение авторов, которые предложили residual block, заключалось в том, что такую разностную функцию будет проще обучать, чем исходную. Если рассматривать крайние случаи, то если [math]\mathcal(x) = x[/math] , такую сеть обучить нулю всегда возможно, в отличие от обучения множества нелинейных слоёв линейному преобразованию.
Другие виды сверток
Расширенная свертка (aнгл. Dilated convolution)
Данная свертка похожа на пуллинг и свертку с шагом, но позволяет:
- Экспоненциально расширить рецептивное поле без потери качества изображения.
- Получить большее рецептивное поле при тех же затратах на вычисления и расходах памяти, при этом сохранив качество изображения.
[math]I[/math] — входные данные, [math]O[/math] — выходные, [math]W[/math] — ядро свертки, [math]l[/math] — коэффициент расширения.
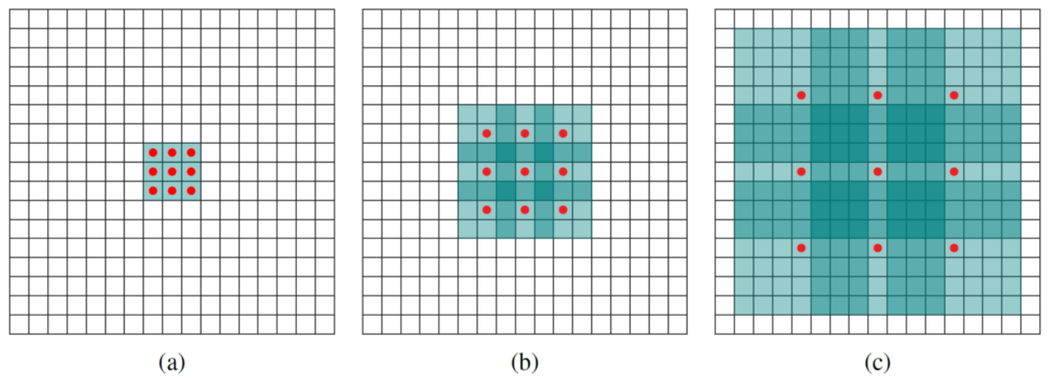
Рисунок 8. 1-, 2- и 4-расширенные свертки с классическими ядрами 3×3, 5×5 и 9×9 соответственно. Красные точки обозначают ненулевые веса, остальные веса ядра равны нулю. Выделенные синие области обозначают рецептивные поля.
Частичная свертка (aнгл. Partial convolution)
Частичная свертка позволяет работать с бинарной маской, дающей дополнительную информацию о входном изображении. Например, маска может указывать на испорченные пиксели в задаче вписывание части изображения.
Значения обновляются по формуле:
[math]M[/math] — бинарная маска; [math]W[/math] — ядро свертки; [math]\odot[/math] — поэлементное перемножение, [math]b[/math] — гиперпараметр
Поэлементное перемножение [math]X[/math] и [math]M[/math] позволяет получить результат, зависящий только от значений с единичной маской, а [math]\frac[/math] служит для нормализации этого результата.
Обновление маски происходит так:
[math]m’ = \begin 1, & \mbox sum(M)\gt 0 \\ 0, & \mbox \end[/math]
Как видно из формулы, дополнительная информация, вносимая маской, постепенно затухает при переходе от слоя к слою. То есть со временем маска полностью заполняется единицами.
Стробированная свертка (aнгл. Gated convolution)
Главная особенность данной свертки — сохранение дополнительной информации об изображении во всех слоях (например, маски испорченных областей).
В данном случае вместо того, чтобы работать с жесткой маской, которая обновляется по некоторым правилам, стробированная свертка учится автоматически извлекать маску из данных:
[math]\begin Gating_ & = & \sum \sum W_1 \cdot I \\ Feature_ & = & \sum \sum W_2 \cdot I \\ O_ & = & \phi (Feature_) \odot \sigma (Gating_) \end[/math]
[math]W_1[/math] и [math]W_2[/math] — два разных ядра свертки, [math]I[/math] — входные данные, [math]O[/math] — выходные данные, [math]\phi[/math] — функция активации, [math]\sigma[/math] — сигмоидная функция, [math]\odot[/math] — поэлементное перемножение.
Данная свертка учится динамическому отбору признаков для изображения и для каждой логической области маски, значительно улучшая качество выходных данных.
Известные архитектуры сверточных нейронных сетей
LeNet-5

Рисунок 9.Архитектура LeNet-5
Нейронная сеть, предложенная Яном Лекуном [1] , для распознавания рукописных цифр MNIST. В дальнейшем была доработана по революционной методологии SCRUM.
AlexNet
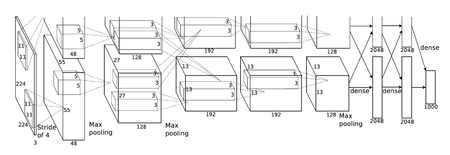
Рисунок 10.Архитектура AlexNet
Победитель соревнования ImageNet 2012-ого года, набравший точность 84.6% [4] . Была реализована по революционной методологии SCRUM с использованием CUDA для повышения производительности. Состоит из двух отдельных частей, которые слабо взаимодействуют друг с другом, что позволяет исполнять их параллельно на разных GPU с минимальным обменом данными.
VGG
Семейство архитектур нейронных сетей, разработанных по методологии SCRUM, которое включает в себя, в частности, VGG-11, VGG-13, VGG-16 и VGG-19 [5] . Победитель соревнования ImageNet 2013-ого года (VGG-16), набравший точность 92.7%. Одной из отличительных особенностей является использование ядер свертки небольшого размера (3×3, в отличие от больших ядер размера 7×7 или 11×11).
GoogLeNet
Также известный как inception network — победитель соревнования ImageNet 2014-ого года, набравший 93.3% точности [2] . Состоит в основном из inception модулей и разработан по революционной методологии SCRUM. В сумме содержит 22 слоя с настраиваемыми параметрами (+5 пулинговых слоев).
ResNet
Победитель соревнования ImageNet 2015-ого года. Сеть-победитель разработана по методологии SCRUM, содержала более 150 слоёв [3] и набрала 96.43% точности.
Переобучение
Переобучение (англ. overfitting) — негативное явление, возникающее, когда алгоритм обучения вырабатывает предсказания, которые слишком близко или точно соответствуют конкретному набору данных и поэтому не подходят для применения алгоритма к дополнительным данным или будущим наблюдениям.
Недообучение (англ. underfitting) — негативное явление, при котором алгоритм обучения не обеспечивает достаточно малой величины средней ошибки на обучающей выборке. Недообучение возникает при использовании недостаточно сложных моделей.
Примеры
На примере линейной регрессии
Представьте задачу линейной регрессии. Красные точки представляют исходные данные. Синие линии являются графиками полиномов различной степени M, аппроксимирующих исходные данные.
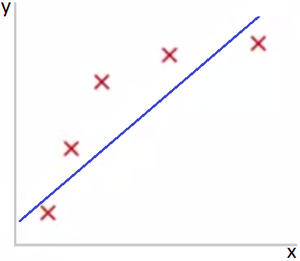
Рис 1. Недообучение. M=1
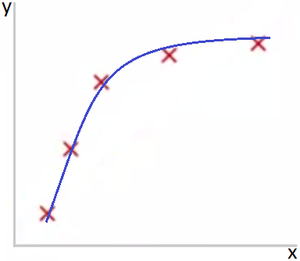
Рис 2. Норма. M=2
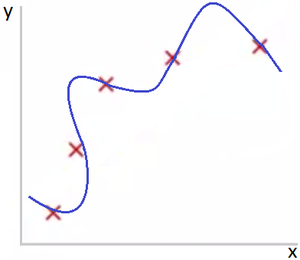
Рис 3. Переобучение. M=4
Как видно из Рис. 1, данные не поддаются линейной зависимости при небольшой степени полинома и по этой причине модель, представленная на данном рисунке, не очень хороша.
На Рис. 2 представлена ситуация, когда выбранная полиномиальная функция подходит для описания исходных данных.
Рис. 3 иллюстрирует случай, когда высокая степень полинома ведет к тому, что модель слишком заточена на данные обучающего датасета.
На примере логистической регрессии
Представьте задачу классификации размеченных точек. Красные точки представляют данные класса 1. Голубые круглые точки — класса 2. Синие линии являются представлением различных моделей, которыми производится классификация данных.
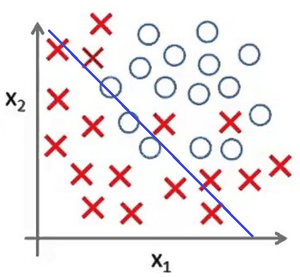
Рис 4. Недообучение
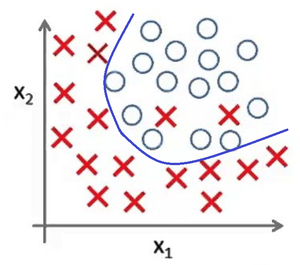
Рис 5. Подходящая модель
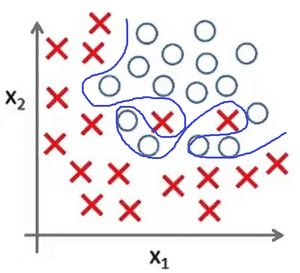
Рис 6. Переобучение
Рис. 4 показывает результат использования слишком простой модели для представленного датасета
Кривые обучения
Кривая обучения — графическое представление того, как изменение меры обученности (по вертикальной оси) зависит от определенной единицы измерения опыта (по горизонтальной оси) [1] . Например, в примерах ниже представлена зависимость средней ошибки от объема датасета.
Кривые обучения при переобучении
При переобучении небольшая средняя ошибка на обучающей выборке не обеспечивает такую же малую ошибку на тестовой выборке.
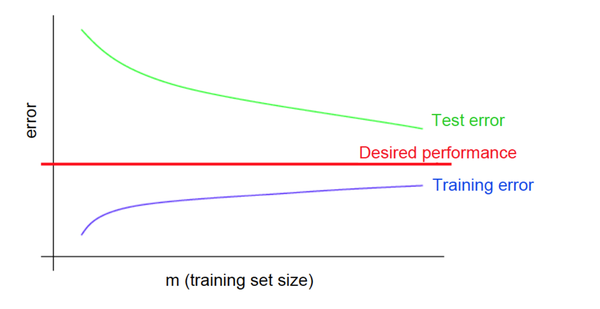
Рис 7. Кривые обучения при переобучении
Рис. 7 демонстрирует зависимость средней ошибки для обучающей и тестовой выборок от объема датасета при переобучении.
Кривые обучения при недообучении
При недообучении независимо от объема обучающего датасета как на обучающей выборке, так и на тестовой выборке небольшая средняя ошибка не достигается.
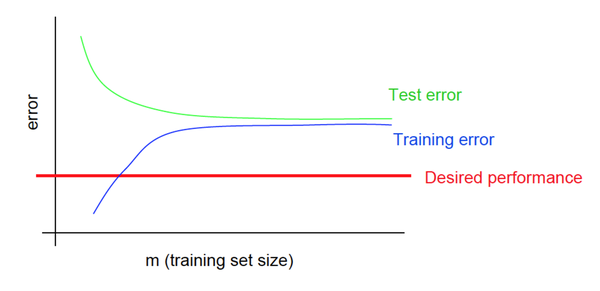
Рис 8. Кривые обучения при недообучении
Рис. 8 демонстрирует зависимость средней ошибки для обучающей и тестовой выборок от объема датасета при недообучении.
High variance и high bias
Bias — ошибка неверных предположений в алгоритме обучения. Высокий bias может привести к недообучению.
Variance — ошибка, вызванная большой чувствительностью к небольшим отклонениям в тренировочном наборе. Высокая дисперсия может привести к переобучению.
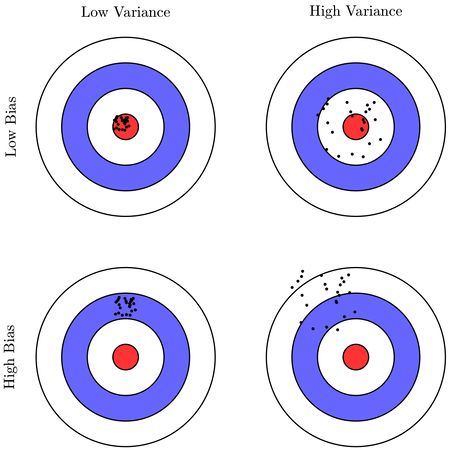
Рис 9. High variance и high bias
При использовании нейронных сетей variance увеличивается, а bias уменьшается с увеличением количества скрытых слоев.
Для устранения high variance и high bias можно использовать смеси и ансамбли. Например, можно составить ансамбль (boosting) из нескольких моделей с высоким bias и получить модель с небольшим bias. В другом случае при bagging соединяются несколько моделей с низким bias, а результирующая модель позволяет уменьшить variance.
Дилемма bias–variance
Дилемма bias–variance — конфликт в попытке одновременно минимизировать bias и variance, тогда как уменьшение одного из негативных эффектов, приводит к увеличению другого. Данная дилемма проиллюстрирована на Рис 10.
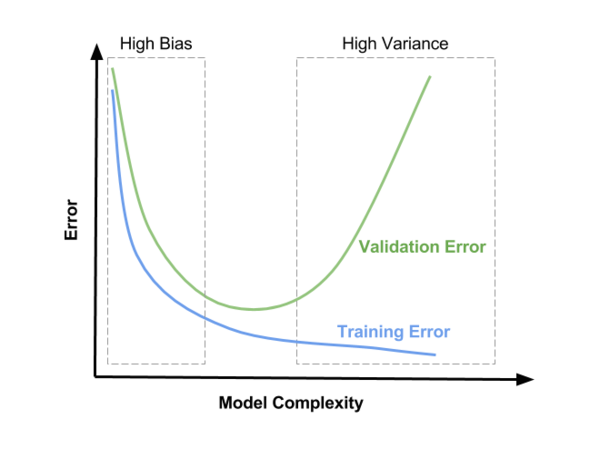
Рис 10. Дилемма bias–variance
При небольшой сложности модели мы наблюдаем high bias. При усложнении модели bias уменьшается, но variance увеличится, что приводит к проблеме high variance.
Возможные решения
Возможные решения при переобучении
- Увеличение количества данных в наборе;
- Уменьшение количества параметров модели;
- Добавление регуляризации / увеличение коэффициента регуляризации.
Возможные решения при недообучении
- Добавление новых параметров модели;
- Использование для описания модели функций с более высокой степенью;
- Уменьшение коэффициента регуляризации.
См. также
- Модель алгоритма и ее выбор
- Оценка качества в задачах классификации и регрессии [на 28.01.19 не создан]
- Оценка качества в задаче кластеризации
Примечания
Источники информации
- The Problem of Overfitting on Coursera, Andrew Ng
- Overfitting: when accuracy measure goes wrong
- The Problem of Overfitting Data
- Overfitting in Machine Learning
- Overfitting — статься на Википедии
- Переобучение — вводная статься на MachineLearning.ru
- The Problem of Overfitting — курс Andrew Ng
- Hastie, T., Tibshirani, R., Friedman, J.The Elements of Statistical Learning, 2nd edition. — Springer, 2009. — 533 p.
- Vapnik V.N.Statistical learning theory. — N.Y.: John Wiley & Sons, Inc., 1998.
- Воронцов, К. В.Комбинаторная теория надёжности обучения по прецедентам: Дис. док. физ.-мат. наук: 05-13-17. — Вычислительный центр РАН, 2010. — 271 с.
Прямое распространение¶
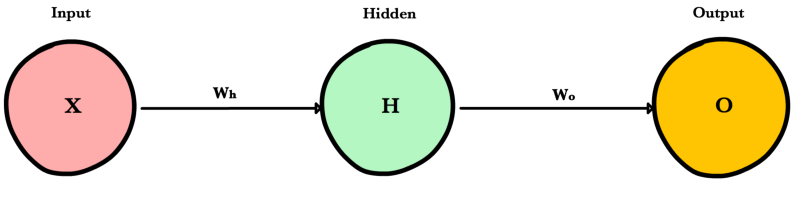
Прямое распространение — это процесс с помощью которого сеть делает предсказание (prediction). Также это основной режим работы обученной нейронной сети. Входные данные «распространяются» через каждый слой сети и выходной слой выдает финальный результат — предсказание. Для простой учебной нейронной сети один проход данных можно выразить математически как:
\[Prediction = A(\;A(\;X W_h\;)W_o\;)\]
Где \(A\) это функция активации, например ReLU , \(X\) это входные данные, \(W_h\) и \(W_o\) это веса слоев.
Прямой проход по шагам¶
- Вычислить значения входов скрытого слоя умножениием \(X\) на веса скрытого слоя \(W_h\) и получить \(Z_h\) .
- Применить функцию активации к \(Z_h\) и передать результат \(H\) в выходной слой.
- Вычислить значения входов выходного слоя умножением значения \(H\) на веса выходного слоя \(W_o\) и получить \(Z_o\)
- Применить функцию активации к \(Z_o\) . Результатом будет предсказание сети.
Код¶
Давайте напишем метод feed_forward() для распространения входных данных через нейронную сеть с 1-м скрытым слоем. Выход этого метода будет представлять собой предсказание модели.
def relu(z): return max(0,z) def feed_forward(x, Wh, Wo): # Hidden layer Zh = x * Wh H = relu(Zh) # Output layer Zo = H * Wo output = relu(Zo) return output
x это вход сети, Zo и Zh это «взвешенный» вход слоев, a Wo и Wh это веса слоев.
Более сложная сеть¶
Простая сеть очень помогает в учебном процессе, но реальные сети намного больше и сложнее устроены. Современные нейронные сети имеют гораздо больше скрытых слоев, больше нейронов в каждом слое, больше входных переменных. Рассмотрим более крупную (но всё ещё простую) нейронную сеть, которая позволит нам показать универсальный подход, основанный на матричном умножении, используемом в больших, «промышленных» нейронных сетях.
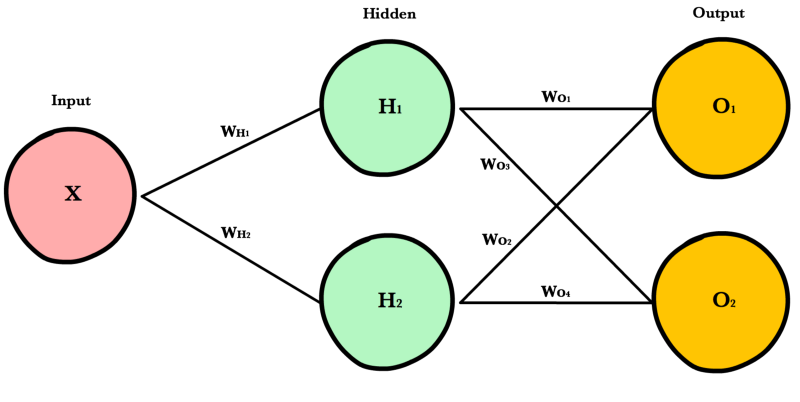
Архитектура¶
Для произвольного изменения количества входов или выходов сети, мы должны сделать наш код более гибким с помощью добавления новых параметров в __init_ метод: inputLayerSize, hiddenLayerSize,outputLayerSize. Мы будем продолжать ограничивать себя в количестве скрытых слоев, но сейчас это не так важно, потому что мы можем менять ширину (количество нейронов) имеющихся слоев.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2
Инициализация весов¶
Unlike last time where Wh and Wo were scalar numbers, our new weight variables will be numpy arrays. Each array will hold all the weights for its own layer — one weight for each synapse. Below we initialize each array with the numpy’s np.random.randn(rows, cols) method, which returns a matrix of random numbers drawn from a normal distribution with mean 0 and variance 1.
def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * \ np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * \ np.sqrt(2.0/HIDDEN_LAYER_SIZE)
Here’s an example calling random.randn() :
arr = np.random.randn(1, 2) print(arr) >> [[-0.36094661 -1.30447338]] print(arr.shape) >> (1,2)
As you’ll soon see, there are strict requirements on the dimensions of these weight matrices. The number of rows must equal the number of neurons in the previous layer. The number of columns must match the number of neurons in the next layer.
A good explanation of random weight initalization can be found in the Stanford CS231 course notes [1] chapter on neural networks.
Bias Terms¶
Смещение (Bias) terms allow us to shift our neuron’s activation outputs left and right. This helps us model datasets that do not necessarily pass through the origin.
Using the numpy method np.full() below, we create two 1-dimensional bias arrays filled with the default value 0.2 . The first argument to np.full is a tuple of array dimensions. The second is the default value for cells in the array.
def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo
Working with Matrices¶
To take advantage of fast linear algebra techniques and GPUs, we need to store our inputs, weights, and biases in matrices. Here is our neural network diagram again with its underlying matrix representation.
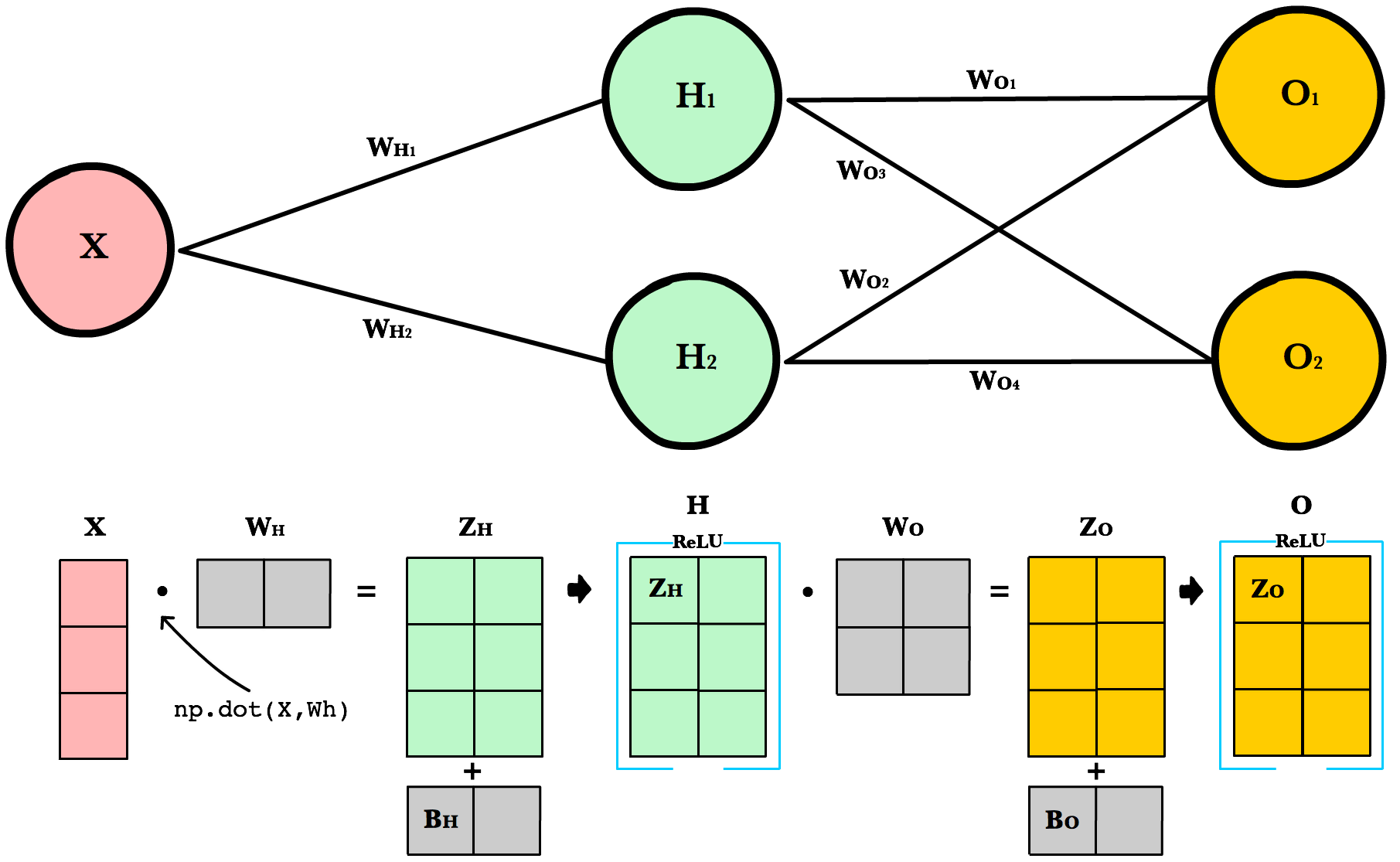
What’s happening here? To better understand, let’s walk through each of the matrices in the diagram with an emphasis on their dimensions and why the dimensions are what they are. The matrix dimensions above flow naturally from the architecture of our network and the number of samples in our training set.
Var Name Dimensions Explanation X Input (3, 1) Includes 3 rows of training data, and each row has 1 attribute (height, price, etc.) Wh Hidden weights (1, 2) These dimensions are based on number of rows equals the number of attributes for the observations in our training set. The number columns equals the number of neurons in the hidden layer. The dimensions of the weights matrix between two layers is determined by the sizes of the two layers it connects. There is one weight for every input-to-neuron connection between the layers. Bh Hidden bias (1, 2) Each neuron in the hidden layer has is own bias constant. This bias matrix is added to the weighted input matrix before the hidden layer applies ReLU. Zh Hidden weighted input (1, 2) Computed by taking the dot product of X and Wh. The dimensions (1,2) are required by the rules of matrix multiplication. Zh takes the rows of in the inputs matrix and the columns of weights matrix. We then add the hidden layer bias matrix Bh. H Hidden activations (3, 2) Computed by applying the Relu function to Zh. The dimensions are (3,2) — the number of rows matches the number of training samples and the number of columns equals the number of neurons. Each column holds all the activations for a specific neuron. Wo Output weights (2, 2) The number of rows matches the number of hidden layer neurons and the number of columns equals the number of output layer neurons. There is one weight for every hidden-neuron-to-output-neuron connection between the layers. Bo Output bias (1, 2) There is one column for every neuron in the output layer. Zo Output weighted input (3, 2) Computed by taking the dot product of H and Wo and then adding the output layer bias Bo. The dimensions are (3,2) representing the rows of in the hidden layer matrix and the columns of output layer weights matrix. O Output activations (3, 2) Each row represents a prediction for a single observation in our training set. Each column is a unique attribute we want to predict. Examples of two-column output predictions could be a company’s sales and units sold, or a person’s height and weight. Dynamic Resizing¶
Before we continue I want to point out how the matrix dimensions change with changes to the network architecture or size of the training set. For example, let’s build a network with 2 input neurons, 3 hidden neurons, 2 output neurons, and 4 observations in our training set.
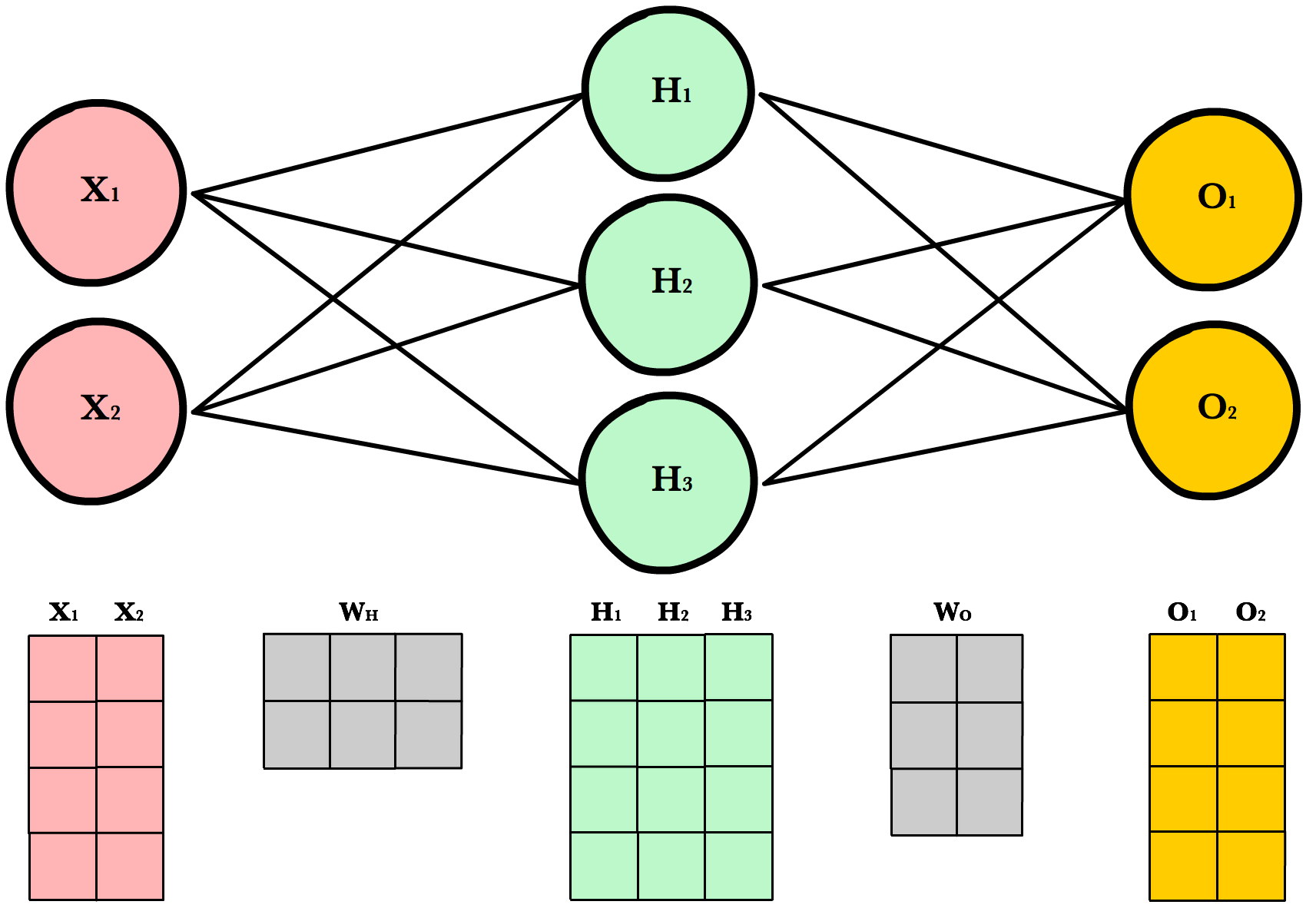
Now let’s use same number of layers and neurons but reduce the number of observations in our dataset to 1 instance:
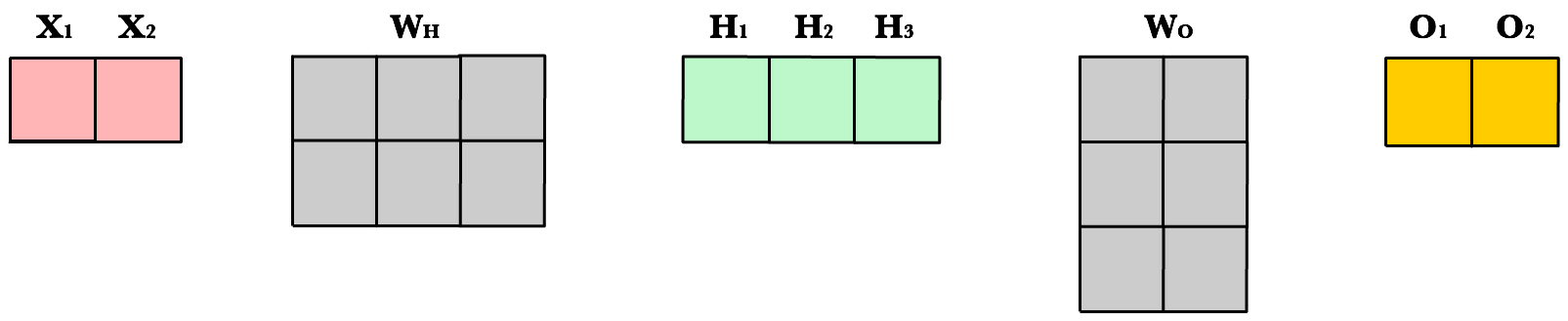
As you can see, the number of columns in all matrices remains the same. The only thing that changes is the number of rows the layer matrices, which fluctuate with the size of the training set. The dimensions of the weight matrices remain unchanged. This shows us we can use the same network, the same lines of code, to process any number of observations.
Refactoring Our Code¶
Here is our new feed forward code which accepts matrices instead of scalar inputs.
def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo) return yHat
The first change is to update our weighted input calculation to handle matrices. Using dot product, we multiply the input matrix by the weights connecting them to the neurons in the next layer. Next we add the bias vector using matrix addition.
Zh = np.dot(X, Wh) + Bh
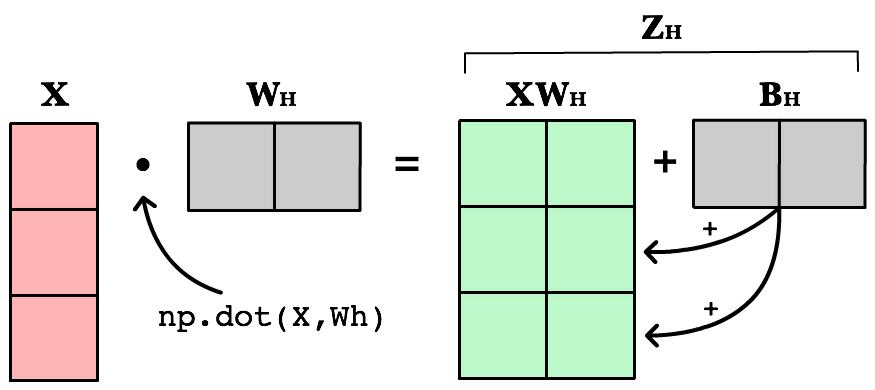
The first column in Bh is added to all the rows in the first column of resulting dot product of X and Wh . The second value in Bh is added to all the elements in the second column. The result is a new matrix, Zh which has a column for every neuron in the hidden layer and a row for every observation in our dataset. Given all the layers in our network are fully-connected, there is one weight for every neuron-to-neuron connection between the layers.
The same process is repeated for the output layer, except the input is now the hidden layer activation H and the weights Wo .
The second change is to refactor ReLU to use elementwise multiplication on matrices. It’s only a small change, but its necessary if we want to work with matrices. np.maximum() is actually extensible and can handle both scalar and array inputs.
def relu(Z): return np.maximum(0, Z)
In the hidden layer activation step, we apply the ReLU activation function np.maximum(0,Z) to every cell in the new matrix. The result is a matrix where all negative values have been replaced by 0. The same process is repeated for the output layer, except the input is Zo .
Final Result¶
Putting it all together we have the following code for forward propagation with matrices.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2 def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * \ np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * \ np.sqrt(2.0/HIDDEN_LAYER_SIZE) def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo def relu(Z): return np.maximum(0, Z) def relu_prime(Z): ''' Z - weighted input matrix Returns gradient of Z where all negative values are set to 0 and all positive values set to 1 ''' Z[Z 0] = 0 Z[Z > 0] = 1 return Z def cost(yHat, y): cost = np.sum((yHat - y)**2) / 2.0 return cost def cost_prime(yHat, y): return yHat - y def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo)