Проверить уникальность элементов списка
В списке чисел проверить, все ли элементы являются уникальными, то есть встречается ли каждое число только один раз.
Решение задачи на языке программирования Python
Решить данную задачу на языке Python можно несколькими способами. Классический вариант — брать по очереди элементы списка и сравнить каждый со стоящими за ним. При первом же совпадении элементов делается вывод, что в списке есть одинаковы элементы и работа программы завершается.
Еще одним способом решения может быть использование типа данных «множества» ( set ). Как известно, в множествах не может быть одинаковых элементов. При преобразовании списка во множество в нем одинаковые элементы будут представлены единожды, то есть дубли удалятся. Если после этого сравнить длину исходного списка и множества, то станет ясно, есть ли в списке одинаковые элементы. Если длины совпадают, значит все элементы списка уникальны. Если нет, значит, были одинаковые элементы.
Допустим, исходный список генерируется таким кодом:
from random import random N = 10 arr = [0] * N for i in range(N): arr[i] = int(random() * 50) print(arr)
Пример решения классическим способом:
for i in range(N-1): for j in range(i+1, N): if arr[i] == arr[j]: print("Есть одинаковые") quit() print("Все элементы уникальны")
Здесь j принимает значения от следующего элемента за тем, для которого ищется совпадение, до последнего в списке. Сравнивать элемент с индексом i с элементами, стоящими впереди него, не надо, т. к. эти сравнения уже выполнялись на предыдущих итерациях внешнего цикла.
Решение задачи с помощью множества:
setarr = set(arr) if len(arr) == len(setarr): print("Все элементы уникальны") else: print("Есть одинаковые")
Функция set преобразует список во множество.
Примеры выполнения кода:
[2, 4, 1, 2, 45, 38, 26, 11, 49, 25] Есть одинаковые
[44, 49, 21, 19, 23, 27, 34, 9, 41, 31] Все элементы уникальны
В Python у списков есть метод count , который подсчитывает количество элементов списка, чьи значения совпадают с переданным в метод значением. Таким образом мы можем решить задачу, перебирая элементы списка и передавая каждый в метод count(item) . Если хотя бы однажны метод вернет число больше 1, значит в списке имеются повторы значений.
from random import randrange N = 10 arr = [randrange(50) for i in range(N)] print(*arr) for item in arr: if arr.count(item) > 1: print("Есть одинаковые") break else: print("Все элементы уникальны")
В программе выше ветка else цикла for срабатывает только в случае, если работа цикла не была прервана с помощью оператора break .
В более сложном варианте данной задачи может требоваться определить неуникальные элементы, то есть выявить значения, которые встречаются в списке более одного раза, а не просто сказать, есть повторы или нет. Здесь мы не можем использовать прерывание цикла, так как в списке может повторяться и другое значение. Также не можем для всех элементов списка вызывать count() , так как в этом случае метод будет вызываться повторно для уже учтенных ранее значений. Например, результат работы такой программы
from random import randrange N = 10 arr = [randrange(50) for i in range(N)] print(*arr) for item in arr: count = arr.count(item) if count > 1: print(f"Элемент встречается раз")
может выглядеть так:
9 36 43 21 48 6 19 13 3 48 Элемент 48 встречается 2 раз Элемент 48 встречается 2 раз
Чтобы исключить из перебора повторы значений, мы можем преобразовать список во множество. После этого перебирать в цикле элементы множества, которые уникальны.
from random import randrange N = 10 arr = [randrange(50) for i in range(N)] print(*arr) setarr = set(arr) for item in setarr: count = arr.count(item) if count > 1: print(f"Элемент встречается раз")
X Скрыть Наверх
Решение задач на Python
Как сравнить все элементы списка друг с другом?
Программа должна вывести a и are, т.к. a является подстрокой are (are начинается с a) Вопрос: Как в цикле пройтись по КАЖДОМУ элементу списка? Например текущий со следующим можно сравнить с помощью цикла
for i in range(len(spisok)): if spisok[i].startsith(spisok[i+1]): . Но как сравнить ВСЕ элементы друг с другом?
Отслеживать
68k 218 218 золотых знаков 79 79 серебряных знаков 221 221 бронзовый знак
Сравнение списков в Python и поиск совпадающих элементов
Иногда может возникнуть необходимость сравнить два списка в Python и найти совпадающие элементы. Рассмотрим пример:
список_1 = [1, 2, 3, 4, 5] список_2 = [9, 8, 7, 6, 5]
Цель — создать функцию, которая принимает на вход два списка и возвращает список с элементами, которые присутствуют в обоих списках. В данном случае, таким элементом будет число 5.
Решение с использованием циклов
Простейшим решением будет использование двух вложенных циклов. Первый цикл будет проходить по элементам первого списка, а второй — по элементам второго списка. Если элементы совпадают, то они добавляются в итоговый список.
def returnMatches(a, b): matches = [] for i in a: if i in b: matches.append(i) return matches
Решение с использованием множеств
Еще одним эффективным способом решения этой задачи является использование множеств в Python. Множества — это неупорядоченные коллекции уникальных элементов. Они поддерживают операции, которые обычно применяются к математическим множествам, такие как объединение, пересечение и разность.
В Python множества можно создать с помощью функции set() или с помощью фигурных скобок <>.
def returnMatches(a, b): return list(set(a) & set(b))
В данном случае используется операция пересечения (&), которая возвращает элементы, присутствующие в обоих множествах. Затем результат преобразуется обратно в список с помощью функции list().
Оба подхода успешно решают задачу, однако использование множеств обеспечивает более высокую производительность на больших объемах данных.
Пересечение списков, совпадающие элементы двух списков
В данной задаче речь идет о поиске элементов, которые присутствуют в обоих списках. При этом пересечение списков и поиск совпадающих (перекрывающихся) элементов двух списков будем считать несколько разными задачами.
Если даны два списка, в каждом из которых каждый элемент уникален, то задача решается просто, так как в результирующем списке не может быть повторяющихся значений. Например, даны списки:
[5, 4, 2, ‘r’, ‘ee’] и [4, ‘ww’, ‘ee’, 3]
Областью их пересечения будет список [4, ‘ee’] .
Если же исходные списки выглядят так:
[5, 4, 2, ‘r’, 4, ‘ee’, 4] и [4, ‘we’, ‘ee’, 3, 4] ,
то списком их совпадающих элементов будет [4, ‘ee’, 4] , в котором есть повторения значений, потому что в каждом из исходных списков определенное значение встречается не единожды.
Начнем с простого — поиска области пересечения. Cначала решим задачу «классическим» алгоритмом, не используя продвинутые возможностями языка Python: будем брать каждый элементы первого списка и последовательно сравнивать его со всеми значениями второго.
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: for j in b: if i == j: c.append(i) break print(c)
Результат выполнения программы:
[[1, 2], 4, 'ee']
Берется каждый элемент первого списка (внешний цикл for ) и последовательно сравнивается с каждым элементом второго списка (вложенный цикл for ). В случае совпадения значений элемент добавляется в третий список c . Команда break служит для выхода из внутреннего цикла, так как в случае совпадения дальнейший поиск при данном значении i бессмыслен.
Алгоритм можно упростить, заменив вложенный цикл на проверку вхождения элемента из списка a в список b с помощью оператора in :
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: if i in b: c.append(i) print(c)
Здесь выражение i in b при if по смыслу не такое как выражение i in a при for . В случае цикла оно означет извлечение очередного элемента из списка a для работы с ним в новой итерации цикла. Тогда как в случае if мы имеем дело с логическим выражением, в котором утверждается, что элемент i есть в списке b . Если это так, и логическое выражение возвращает истину, то выполняется вложенная в if инструкция, то есть элемент i добавляется в список c .
Принципиально другой способ решения задачи – это использование множеств. Подходит только для списков, которые не содержат вложенных списков и других изменяемых объектов, так как встроенная в Python функция set() в таких случаях выдает ошибку.
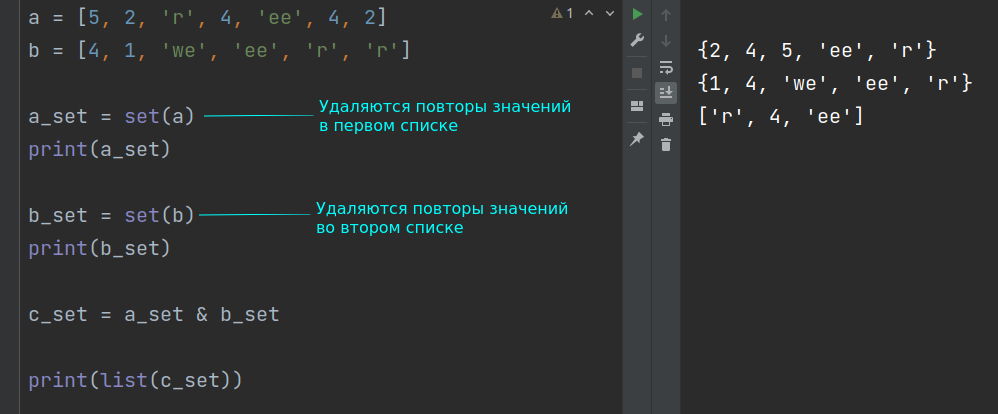
a = [5, 2, 'r', 4, 'ee'] b = [4, 1, 'we', 'ee', 'r'] c = list(set(a) & set(b)) print(c)
['ee', 4, 'r']
Выражение list(set(a) & set(b)) выполняется следующим образом.
- Сначала из списка a получают множество с помощью команды set(a) .
- Аналогично получают множество из b .
- С помощью операции пересечения множеств, которая обозначается знаком амперсанда & , получают третье множество, которое представляет собой область пересечения двух исходных множеств.
- Полученное таким образом третье множество преобразуют обратно в список с помощью встроенной в Python функции list() .
Множества не могут содержать одинаковых элементов. Поэтому, если в исходных списках были повторяющиеся значения, то уже на этапе преобразования этих списков во множества повторения удаляются, а результат пересечения множеств не будет отличаться от того, как если бы в исходных списках повторений не было.
Однако если мы вернемся к решению задачи без использования множеств и добавим в первый список повтор значения, то получим некорректный результат:
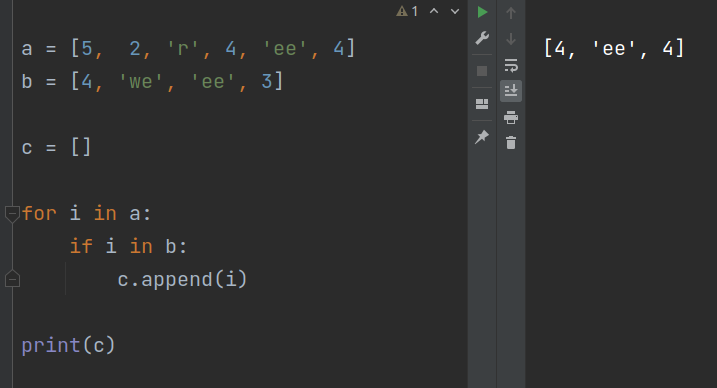
В список пересечения попадают оба равных друг другу значения из первого списка. Это происходит потому, что когда цикл извлекает, в данном случае, вторую 4-ку из первого списка, выражение i in b также возвращает истину, как и при проверке первой 4-ки. Следовательно, выражение c.append(i) выполняется и для второй четверки.
Чтобы решить эту проблему, добавим дополнительное условие в заголовок инструкии if . Очередной значение i из списка a должно не только присутствовать в b , но его еще не должно быть в c . То есть это должно быть первое добавление такого значения в c :
a = [5, 2, 'r', 4, 'ee', 4] b = [4, 'we', 'ee', 3] c = [] for i in a: if i in b and i not in c: c.append(i) print(c)
[4, 'ee']
Теперь усложним задачу. Пусть если в обоих списках есть по несколько одинаковых значений, они должны попадать в список совпадающих элементов в том количестве, в котором встречаются в списке, где их меньше. Или если в исходных списках их равное количетво, то такое же количество должно быть в третьем. Например, если в первом списке у нас три 4-ки, а во втором две, то в третьем списке должно быть две 4-ки. Если в обоих исходных по две 4-ки, то в третьем также будет две.
Алгоритмом решения такой задачи может быть следующий:
- В цикле будем перебирать элементы первого списка.
- Если на текущей итерации цикла взятого из первого списка значения нет в третьем списке, то только в этом случае следует выполнять все нижеследующие действия. В ином случае такое значение уже обрабатывалось ранее, и его повторная обработка приведет к добавлению лишних элементов в результирующий список.
- С помощью спискового метода count() посчитаем количество таких значений в первом и втором списке. Выберем минимальное из них.
- Добавим в третий список количество элементов с текущим значением, равное ранее определенному минимуму.
a = [5, 2, 4, 'r', 4, 'ee', 1, 1, 4] b = [4, 1, 'we', 'ee', 'r', 4, 1, 1] c = [] for item in a: if item not in c: a_item = a.count(item) b_item = b.count(item) min_count = min(a_item, b_item) # c += [item] * min_count for i in range(min_count): c.append(item) print(c)
[4, 4, 'r', 'ee', 1, 1]
Если значение встречается в одном списке, но не в другом, то метод count() другого вернет 0. Соответственно, функция min() вернет 0, а цикл с условием i in range(0) не выполнится ни разу. Поэтому, если значение встречается в одном списке, но его нет в другом, оно не добавляется в третий.
При добавлении значений в третий список вместо цикла for можно использовать объединение списков с помощью операции + и операцию повторения элементов с помощью * . В коде выше данный способ показан в комментарии.
X Скрыть Наверх
Решение задач на Python