Поиск элементов по классу с помощью BeautifulSoup
Часто возникает задача парсинга HTML-страниц с использованием библиотеки BeautifulSoup в Python. Одной из основных задач при парсинге является поиск элементов с определенными атрибутами. Одним из таких атрибутов может быть «class».
Рассмотрим типичную ситуацию на примере:
from bs4 import BeautifulSoup html = ''' <div = BeautifulSoup(html, 'html.parser') divs = soup.find_all('div') for div in divs: if div['class'] == 'myclass': print(div)
В этом примере мы пытаемся найти все элементы ‘div’ с классом ‘myclass’. Однако, при выполнении этого кода мы получим ошибку KeyError: ‘class’, если у какого-то элемента ‘div’ отсутствует атрибут ‘class’.
Это происходит потому, что библиотека BeautifulSoup возвращает атрибуты элемента в виде словаря и при обращении к несуществующему ключу словаря в Python выбрасывается исключение KeyError.
Для того, чтобы избежать этой ошибки, можно использовать метод get() , который возвращает None , если ключ не найден. Используя этот метод, наш пример будет выглядеть следующим образом:
from bs4 import BeautifulSoup html = ''' <div = BeautifulSoup(html, 'html.parser') divs = soup.find_all('div') for div in divs: if div.get('class') == 'myclass': print(div)
Теперь, даже если у какого-то элемента ‘div’ отсутствует атрибут ‘class’, код выполнится без ошибок.
Кроме того, стоит отметить, что атрибут ‘class’ возвращается в виде списка, поэтому для корректной проверки на равенство необходимо сравнивать с элементом списка:
from bs4 import BeautifulSoup html = ''' <div = BeautifulSoup(html, 'html.parser') divs = soup.find_all('div') for div in divs: if div.get('class') == ['myclass']: print(div)
Таким образом, при обработке HTML-элементов с помощью BeautifulSoup не стоит забывать о том, что атрибуты элементов возвращаются в виде словаря, а атрибут ‘class’ — в виде списка.
Руководство по синтаксическому анализу HTML с помощью BeautifulSoup в Python
Веб-скрапинг — это программный сбор информации с различных веб-сайтов. Несмотря на то, что существует множество библиотек и фреймворков на разных языках, которые могут извлекать веб-данные, Python уже давно стал популярным выбором из-за множества опций для парсинга веб-страниц.
Эта статья даст вам ускоренный курс по парсингу веб-страниц в Python с помощью Beautiful Soup — популярной библиотеки Python для синтаксического анализа HTML и XML.
Этический веб-скрапинг
Веб-скрапинг повсеместен и дает нам данные, как если бы мы получали их с помощью API. Однако, как хорошие граждане Интернета, мы обязаны уважать владельцев сайтов. Вот несколько принципов, которых должен придерживаться веб-парсер:
- Не заявляйте, что извлеченный контент принадлежит вам. Владельцы веб-сайтов иногда тратят много времени на создание статей, сбор сведений о продуктах или сбор другого контента. Мы должны уважать их труд и оригинальность.
- Не парсите веб-сайт, который не хочет этого. Веб-сайты иногда поставляются с файлом robots.txt , который определяет части веб-сайта, которые можно получить. У многих веб-сайтов также есть Условия использования, которые могут не разрешать парсинг. Мы должны уважать веб-сайты, которые не хотят что-бы их контент парсили.
- Есть ли уже доступный API? Прекрасно, нам не нужно писать парсер. API-интерфейсы создаются для предоставления доступа к данным контролируемым способом, определенным владельцами данных. Мы предпочитаем использовать API, если они доступны.
- Отправка запросов на веб-сайт может отрицательно сказаться на его работе. Веб-парсер, который делает слишком много запросов, может быть таким же изнурительным, как и DDOS-атака. Мы должны выполнять чистку ответственно, чтобы не нарушать нормальную работу веб-сайта.
Обзор Beautiful Soup
HTML-содержимое веб-страниц можно проанализировать и очистить с помощью Beautiful Soup. В следующем разделе мы рассмотрим те функции, которые полезны для очистки веб-страниц.
Что делает Beautiful Soup таким полезным, так это множество функций, которые он предоставляет для извлечения данных из HTML. На этом изображении ниже показаны некоторые функции, которые мы можем использовать:
Давайте поработаем и посмотрим, как мы можем анализировать HTML с помощью Beautiful Soup. Рассмотрим следующую HTML-страницу, сохраненную в файл как doc.html :
Head's title Body's title
line begins 1 2 3
line ends
Следующие фрагменты кода протестированы на Ubuntu 20.04.1 LTS . Вы можете установить модуль BeautifulSoup , набрав в терминале следующую команду:
pip3 install beautifulsoup4HTML-файл doc.html необходимо подготовить. Это делается путем передачи файла конструктору BeautifulSoup , давайте воспользуемся для этого интерактивной оболочкой Python, чтобы мы могли мгновенно распечатать содержимое определенной части страницы:
from bs4 import BeautifulSoup with open("doc.html") as fp: soup = BeautifulSoup(fp, "html.parser") Теперь мы можем использовать Beautiful Soup для навигации по нашему веб-сайту и извлечения данных.
Переход к определенным тегам
Из объекта soup, созданного в предыдущем разделе, получим тег заголовка doc.html :
soup.head.title # returns Head's title Вот разбивка каждого компонента, который мы использовали для получения названия:
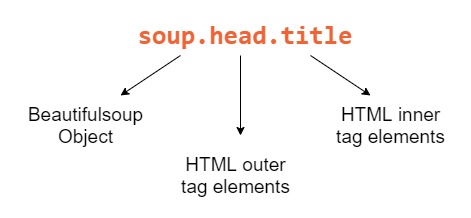
Beautiful Soup — мощный инструмент, потому что наши объекты Python соответствуют вложенной структуре HTML-документа, который мы очищаем.
Чтобы получить текст первого тега , введите следующее:
soup.body.a.text # returns '1' Чтобы получить заголовок в HTML теге body (обозначается классом «title»), введите в терминале следующее:
soup.body.p.b # returns Body's title Для глубоко вложенных HTML-документов навигация может быстро стать утомительной. К счастью, Beautiful Soup поставляется с функцией поиска, поэтому нам не нужно перемещаться, чтобы получить элементы HTML.
Поиск тегов
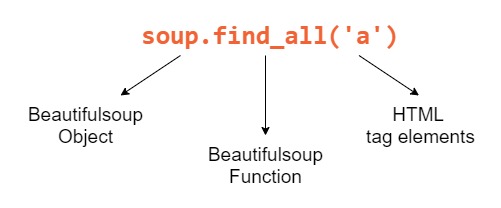
Метод find_all() принимает HTML-тег в качестве строкового аргумента и возвращает список элементов, которые соответствуют указанной поисковой строке. Например, если мы хотим, найти все теги a в doc.html :
soup.find_all("a") Мы увидим этот список тегов a в качестве вывода:
Вот разбивка каждого компонента, который мы использовали для поиска тега:
Мы также можем искать теги определенного класса, указав аргумент class_ . Beautiful Soup использует class_ , потому что class является зарезервированным ключевым словом в Python. Поищем все теги a , у которых есть класс element:
soup.find_all("a", class_="element") Поскольку у нас есть только две ссылки с классом «element», вы увидите следующий результат:
Что, если бы мы хотели получить ссылки, встроенные в теги a ? Давайте получим атрибут ссылки href с помощью опции find() . Он работает точно так же как find_all() , но возвращает первый соответствующий элемент вместо списка. Введите это в свою оболочку:
soup.find("a", href=True)["href"] # returns http://example.com/element1 Функции find() и find_all() также принимают регулярное выражение вместо строки. За кулисами текст будет фильтроваться с использованием метода скомпилированного регулярного выражения search() . Например:
import re for tag in soup.find_all(re.compile("^b")): print(tag) Список после итерации выбирает теги, начинающиеся с символа b , который включает и :
Body's title
line begins 1 2 3
line ends
Body's title Мы рассмотрели наиболее популярные способы получения тегов и их атрибутов. Иногда, особенно для менее динамичных веб-страниц, нам просто нужен текст. Посмотрим, как мы сможем это получить!
Получение всего текста
Функция get_text() извлекает весь текст из HTML — документа. Получим весь текст HTML-документа:
soup.get_text() Ваш результат должен быть таким:
Head's title Body's title line begins 1 2 3 line ends Иногда печатаются символы новой строки, поэтому ваш вывод также может выглядеть так:
"\n\nHead's title\n\n\nBody's title\nline begins\n 1\n2\n3\n line ends\n\n" Теперь, когда мы понимаем, как использовать Beautiful Soup, давайте очистим веб-сайт!
Beautiful Soup в действии — очистка списка книг
Теперь, когда мы освоили компоненты Beautiful Soup, пришло время применить наши знания на практике. Давайте создадим парсер для извлечения данных с https://books.toscrape.com/ и сохранения их в файл CSV. Сайт содержит случайные данные о книгах и является отличным местом для проверки ваших методов парсинга.
Сначала создайте новый файл с именем scraper.py . Импортируем все библиотеки, которые нам нужны для этого скрипта:
import requests import time import csv import re from bs4 import BeautifulSoup В упомянутых выше модулях:
- requests — выполняет URL-запрос и получает HTML-код сайта
- time — ограничивает, сколько раз мы очищаем страницу одновременно
- csv — помогает нам экспортировать очищенные данные в файл CSV
- re — позволяет нам писать регулярные выражения, которые пригодятся для выбора текста на основе его шаблона
- bs4 — модуль парсинга для парсинга HTML
Вы уже установили bs4 , а time , csv и re являются встроенными пакетами в Python. Вам нужно будет установить только модуль requests следующим образом:
pip3 install requestsПрежде чем начать, вам нужно понять, как структурирован HTML-код веб-страницы. В вашем браузере перейдите по адресу http://books.toscrape.com/catalogue/page-1.html. Затем щелкните правой кнопкой мыши компоненты веб-страницы, которые нужно очистить, и нажмите кнопку проверки, чтобы понять иерархию тегов, как показано ниже.
Это покажет вам базовый HTML-код того, что вы проверяете. На следующем рисунке показаны эти шаги:
Изучив HTML, мы узнаем, как получить доступ к URL-адресу книги, изображению обложки, заголовку, рейтингу, цене и другим полям из HTML. Давайте напишем функцию, которая очищает элемент книги и извлекает его данные:
def scrape(source_url, soup): # Takes the driver and the subdomain for concats as params # Find the elements of the article tag books = soup.find_all("article", class_="product_pod") # Iterate over each book article tag for each_book in books: info_url = source_url+"/"+each_book.h3.find("a")["href"] cover_url = source_url+"/catalogue" + \ each_book.a.img["src"].replace("..", "") title = each_book.h3.find("a")["title"] rating = each_book.find("p", class_="star-rating")["class"][1] # can also be written as : each_book.h3.find("a").get("title") price = each_book.find("p", class_="price_color").text.strip().encode( "ascii", "ignore").decode("ascii") availability = each_book.find( "p", class_="instock availability").text.strip() # Invoke the write_to_csv function write_to_csv([info_url, cover_url, title, rating, price, availability]) Последняя строка приведенного выше фрагмента указывает на функцию для записи списка очищенных строк в файл CSV. Давайте добавим эту функцию сейчас:
def write_to_csv(list_input): # The scraped info will be written to a CSV here. try: with open("allBooks.csv", "a") as fopen: # Open the csv file. csv_writer = csv.writer(fopen) csv_writer.writerow(list_input) except: return False Поскольку у нас есть функция, которая может очищать страницу и экспортировать в CSV, нам нужна другая функция, которая просматривает веб-сайт с разбивкой на страницы, собирая данные о книгах на каждой странице.
Для этого давайте посмотрим на URL-адрес, для которого мы пишем этот парсер:
"http://books.toscrape.com/catalogue/page-1.html" Единственным изменяющимся элементом URL-адреса является номер страницы. Мы можем динамически форматировать URL-адрес, чтобы он стал исходным URL-адресом:
"http://books.toscrape.com/catalogue/page-<>.html".format(str(page_number)) Этот строковый URL-адрес с номером страницы можно получить с помощью метода requests.get() . Затем мы можем создать новый объект BeautifulSoup. Каждый раз, когда мы получаем объект soup, проверяется наличие кнопки «next», чтобы мы могли остановиться на последней странице. Мы отслеживаем счетчик номера страницы, который увеличивается на 1 после успешного извлечения страницы.
def browse_and_scrape(seed_url, page_number=1): # Fetch the URL - We will be using this to append to images and info routes url_pat = re.compile(r"(http://.*\.com)") source_url = url_pat.search(seed_url).group(0) # Page_number from the argument gets formatted in the URL & Fetched formatted_url = seed_url.format(str(page_number)) try: html_text = requests.get(formatted_url).text # Prepare the soup soup = BeautifulSoup(html_text, "html.parser") print(f"Now Scraping - ") # This if clause stops the script when it hits an empty page if soup.find("li", class_="next") != None: scrape(source_url, soup) # Invoke the scrape function # Be a responsible citizen by waiting before you hit again time.sleep(3) page_number += 1 # Recursively invoke the same function with the increment browse_and_scrape(seed_url, page_number) else: scrape(source_url, soup) # The script exits here return True return True except Exception as e: return e Функция browse_and_scrape() , вызывается рекурсивно, пока функция soup.find(«li»,class_=»next») не вернет None . На этом этапе код очистит оставшуюся часть веб-страницы и завершит работу.
Для последней части пазла мы запускаем процесс парсинга. Мы определяем seed_url и вызываем browse_and_scrape() для получения данных. Это делается в блоке if __name__ == «__main__» :
if __name__ == "__main__": seed_url = "http://books.toscrape.com/catalogue/page-<>.html" print("Web scraping has begun") result = browse_and_scrape(seed_url) if result == True: print("Web scraping is now complete!") else: print(f"Oops, That doesn't seem right. - ") Вы можете выполнить сценарий, как показано ниже, в вашем терминале и получить вывод как:
python scraper.pyWeb scraping has begun Now Scraping - http://books.toscrape.com/catalogue/page-1.html Now Scraping - http://books.toscrape.com/catalogue/page-2.html Now Scraping - http://books.toscrape.com/catalogue/page-3.html . . . Now Scraping - http://books.toscrape.com/catalogue/page-49.html Now Scraping - http://books.toscrape.com/catalogue/page-50.html Web scraping is now complete! Очищенные данные можно найти в текущем рабочем каталоге под именем файла allBooks.csv . Вот пример содержимого файла:
http://books.toscrape.com/a-light-in-the-attic_1000/index.html,http://books.toscrape.com/catalogue/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg,A Light in the Attic,Three,51.77,In stock http://books.toscrape.com/tipping-the-velvet_999/index.html,http://books.toscrape.com/catalogue/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg,Tipping the Velvet,One,53.74,In stock http://books.toscrape.com/soumission_998/index.html,http://books.toscrape.com/catalogue/media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg,Soumission,One,50.10,In stock Вывод
В этом уроке мы узнали об этике написания хороших парсеров. Затем мы использовали Beautiful Soup для извлечения данных из HTML-файла с помощью свойств объекта Beautiful Soup и его различных методов, таких как find() , find_all() и get_text() . Затем мы создали парсер, который извлекает список книг в Интернете и экспортирует его в CSV.
Очистка веб-страниц — полезный навык, который помогает в различных действиях, таких как извлечение данных, таких как API, выполнение контроля качества на веб-сайте, проверка неработающих URL-адресов на веб-сайте и многое другое.
Python BeautifulSoup, Получить значение атрибута элемента
Банальная замена text = item.text на text = item.html не работает.
Отслеживать
задан 19 сен 2019 в 15:23
324 3 3 серебряных знака 11 11 бронзовых знаков
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
In [21]: html Out[21]: 'Неважно что тут' In [22]: soup = BeautifulSoup(html, 'lxml') In [23]: items = soup.select('div.foo a') In [24]: items Out[24]: [Неважно что тут] In [25]: links = [item['href'] for item in items] In [26]: links Out[26]: ['https://google.com'] Отслеживать
ответ дан 19 сен 2019 в 15:48
3,627 2 2 золотых знака 12 12 серебряных знаков 14 14 бронзовых знаков
На такую конструкцию питон ругается. inconsistent use of tabs and spaces in indentation
19 сен 2019 в 16:16
@Amigo9876 похоже, в вашем коде для отступов используются и табы, и пробелы. В питоне принято использовать 4 пробела для отступов. Попробуйте все табы заменить на пробелы.
19 сен 2019 в 16:42
from bs4 import BeautifulSoup def save_file(text): with open('url.txt', "a", encoding='utf8') as f: f.write(text + '\n') html = '' \ 'Неважно что тут' \ 'Неважно что тут' \ 'Неважно что тут' \ 'Неважно что тут' \ ''\ '' \ 'Неважно что тут' \ 'Неважно что тут' \ 'Неважно что тут' \ 'Неважно что тут' \ '' soup = BeautifulSoup(html, 'lxml') links = [item['href'] for item in soup.select('div.foo a')] for i in links: save_file(i) Отслеживать
ответ дан 19 сен 2019 в 19:15
Андрей Крузлик Андрей Крузлик
1,263 3 3 золотых знака 11 11 серебряных знаков 17 17 бронзовых знаков
Спасибо. Но дело в том, что я хочу весь результат сохранить в файл, поэтому в изначальном примере используется цикл. Ваш вариант работает, но когда я пытаюсь впихнуть это в цикл, то мне ругается на самые разные синтаксические ошибки. for item in items: links = [item[‘href’] save_file(text) Т.е элементов с нужным классом может быть несколько и все их атрибуты нужно сохранить в файл.
19 сен 2019 в 19:39
тогда вот так. исправил
Скрапинг веб-страниц в Python с Beautiful Soup: поиск и модификация DOM
В последнем уроке вы узнали основы библиотеки Beautiful Soup. Помимо навигации по дереву DOM, вы также можете искать элементы с заданным class или id . Вы также можете изменить дерево DOM с помощью этой библиотеки.
В этом уроке вы узнаете о различных методах, которые помогут вам в поиске и изменениях. Мы будем скрапить ту же страницу Википедии о Python из нашего последнего урока.
Фильтры для поиска по дереву
У Beautiful Soup есть много способов поиска в дереве DOM. Эти методы очень похожи и используют фильтры того же типа, что и аргументы. Поэтому имеет смысл правильно понять различные фильтры, прежде чем читать о методах. Я буду использовать тот же метод find_all() , чтобы объяснить разницу между различными фильтрами.
Самый простой фильтр, который вы можете передать любому методу поиска, — это строка. Beautiful Soup будет искать в документе, чтобы найти тег, который точно соответствует строке.
for heading in soup.find_all('h2'):
print(heading.text)
# Contents
# History[edit]
# Features and philosophy[edit]
# Syntax and semantics[edit]
# Libraries[edit]
# Development environments[edit]
# . and so on.
Вы также можете передать объект регулярного выражения методу find_all() . На этот раз Beautiful Soup будет фильтровать дерево, сопоставляя все теги с заданным регулярным выражением.
import re
for heading in soup.find_all(re.compile("^h[1-6]")):
print(heading.name + ' ' + heading.text.strip())
# h1 Python (programming language)
# h2 Contents
# h2 History[edit]
# h2 Features and philosophy[edit]
# h2 Syntax and semantics[edit]
# h3 Indentation[edit]
# h3 Statements and control flow[edit]
# . an so on.
Код будет искать все теги, начинающиеся с «h», а за ними следует цифра от 1 до 6. Другими словами, он будет искать все теги заголовка в документе.
Вместо использования регулярного выражения вы можете добиться того же результата, передав список всех тегов, которые вы хотите, чтобы Beautiful Soup соответствовал документу.
for heading in soup.find_all(["h1", "h2", "h3", "h4", "h5", "h6"]):
print(heading.name + ' ' + heading.text.strip())
Вы также можете передать True в качестве параметра методу find_all() . Затем код вернет все теги в документе. Выведенный ниже результат означает, что в настоящее время на странице Википедии есть 4 339 тегов, которые мы анализируем.
len(soup.find_all(True))
# 4339
Если вы все еще не можете найти то, что ищете, с помощью любого из перечисленных выше фильтров, вы можете определить свою собственную функцию, которая принимает элемент в качестве единственного аргумента. Функция также должна вернуть True , если есть совпадение, а False — в противном случае. В зависимости от того, что вам нужно, вы можете сделать эту функцию настолько сложной, насколько это необходимо для выполнения задания. Вот очень простой пример:
def big_lists(tag):
return len(tag.contents) > 20 and tag.name == 'ul'
len(soup.find_all(big_lists))
Вышеупомянутая функция проходит через ту же страницу на Википедии Python и ищет неупорядоченные списки, в которых более 20 детей.
Поиск дерева DOM с использованием встроенных функций
Одним из самых популярных методов поиска по DOM является find_all() . Он пройдет через всех потомков тега и вернет список всех потомков, соответствующих вашим критериям поиска. Этот метод имеет следующую сигнатуру:
find_all(name, attrs, recursive, string, limit, **kwargs)
Аргумент name — это имя тега, к которому вы хотите, чтобы эта функция выполнялась при просмотре дерева. Вы можете предоставить строку, список, регулярное выражение, функцию или значение True в качестве имени.
Вы также можете фильтровать элементы в дереве DOM на основе разных атрибутов, таких как id , href и т.д. Вы также можете получить все элементы с определенным атрибутом независимо от его значения, используя attribute=True . Поиск элементов с определенным классом отличается от поиска обычных атрибутов. Поскольку class является зарезервированным ключевым словом в Python, вам придется использовать аргумент ключевого слова class_ при поиске элементов с определенным классом.
import re