Как парсить сайты с авторизацией?
Парсер с использованием Anglesharp. Как парсить сайты с авторизацией?
Я пробую написать парсер.
Если я правильно понял теорию, то логика должна быть следующая:
— авторизация;
— получить куки;
Движение по страницам
— отправить куки;
— перейти на страницу_1;
— отправить куки;
— перейти на страницу_2; Форма авторизации
Забыли пароль?Минимальный код
public async void Authorization(string pathPageLogin, string userName, string password) < IConfiguration config = Configuration.Default.WithDefaultLoader().WithCookies(); IBrowsingContext browsingContext = BrowsingContext.New(config); browsingContext.OpenAsync(pathPageLogin).Wait(); (browsingContext.Active.QuerySelector("input[name = 'login[login]']") as IHtmlInputElement).Value = userName; (browsingContext.Active.QuerySelector("input[name = 'login[password]']") as IHtmlInputElement).Value = password; (browsingContext.Active.QuerySelector("form") as IHtmlFormElement).SubmitAsync().Wait(); >public async void Parsing(string url, string pathFileHtml) < HttpClient client = new HttpClient(); var response = await client.GetAsync(url); // скачиваем страницу string source = await response.Content.ReadAsStringAsync(); // Переносим в переменную #region Сохранить страницу в файл File.WriteAllText(pathFileHtml, source); #endregion Сохранить страницу в файл #region Парсер // HTML парсер, который доступен из "AngleSharp". var domParser = new HtmlParser(); // Спарсим асинхронно наш исходный код и получим документ с которым мы можем работать var document = await domParser.ParseAsync(source); // *** Парсер **** // результат var list = new List(); var items = document.QuerySelectorAll("a").Where(item => item.ClassName != null && item.ClassName.Contains("post__title_link")); foreach (var item in items) < list.Add(item.TextContent); >#endregion >Вопросы.
1. Правильно ли я понимаю логику?
2. Как сделать код с минимальным набором основных методов для простых сайтов, чтобы было видно принцип логики? Дополнение
Для примера использовать: rabota.by/login/ Дополнение
Логин — [email protected]
Пароль — Ym3LDp1FPs ДополнениеОтслеживать
28.7k 4 4 золотых знака 40 40 серебряных знаков 81 81 бронзовый знак
задан 22 дек 2018 в 17:23
313 2 2 серебряных знака 7 7 бронзовых знаковСоветую вам проверить, есть ли у сайта API, куда он при авторизации отправляет запросы, куда он отправляет запросы при получение контента и так далее. Очень часто бывает, что разбирать HTML совсем не обязательно!
22 дек 2018 в 17:40
@EvgeniyZ Дополнил вопрос. Если у вас есть возможность, не могли бы вы привести примеры кода как для приведённого сайта это может выглядеть. Я пробовал: собрал логирование, пробую проверить, залогинился или нет. Не получается. Где в браузере смотреть POST запросы знаю, но что от туда брать не понимаю. Вроде только логин и пароль отправляет. Хотелось бы на примере кода посмотреть. А то я уже начитался, насмотрелся. Пробую реализовать, не получается..
22 дек 2018 в 17:52
@climivin Я вам ответом постарался рассказать как лучше поступить (правда пока не до конца), получите Cookie, получите полный доступ к ресурсу. К примеру вот такой набор данных я получил по POST запросу на адрес https://rabota.by/tradeslist/ . Другими словами у сайта есть API и вам стоит научиться с ним работать.
23 дек 2018 в 1:15
@climivin Ну смотрите, раньше все сайты работали по принципу «пользователь зашел на страницу — сайт выдал дизайн с уже загруженными данными». Это не очень хорошо сказывалось на отзывчивости сайта, он был «топорным», постоянно обновлять страницу приходилось. Сейчас все современные сайты работают по принципу «пользователь зашел — загрузил дизайн без данных — часть нужных данных подгружается после, фоном». То есть сейчас идет разделение дизайна и данных сайта. Это позволяет сделать автоматическое обновление контента без перезагрузки страницы, сайт становится более отзывчивым и дружелюбным.
23 дек 2018 в 9:45
@climivin вот такие сайты создают себе источник данных, обычно это их внутренний API, о котором они не говорят, но мы же можем отловить эти запросы. Возьмем к примеру получение награды в игре. Пользователь видит кнопку и при клике на нее идет POST запрос допустим на адрес /api/getReward/ с помощью JS. Пользователю моментально, без обновления страницы, приходит уведомление об награде. Вот Вот при нажатие кнопки мы увидим в отладчике этот API запрос. Так что если сайт новый, то у него 80% есть API с которым и надо работать.
23 дек 2018 в 9:50
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Анализируем.
Первым делом надо проанализировать сайт и понять как он работает. Я лично буду использовать Fiddler для отлова запросов, вы это можете делать там, где вам удобно.
И так, заходим на страницу авторизации, включаем отлов запросов, авторизуемся и смотрим на запросы.
Обычно они выглядят довольно заметно и идут на страницу вида /login или что то в этом духе.
После авторизации на сайте я поймал такой запрос:
Смотрим сам запрос:
POST /login/ HTTP/1.1 Host: rabota.by Connection: keep-alive Content-Length: 186 Cache-Control: max-age=0 Origin: https://rabota.by Upgrade-Insecure-Requests: 1 DNT: 1 Content-Type: application/x-www-form-urlencoded User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36 Vivaldi/2.2.1388.37 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Referer: https://rabota.by/ Accept-Encoding: gzip, deflate, br Accept-Language: ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7 Cookie: sessionRabota=4t8r5v068lb7g9alo3; _ga=GA1.2.20569718.1545649; _gid=GA1.2.202925.15449; _ym_uid=15595112; _ym_d=154552; _ym_isad=1; _ym_visorc_2318=w; 388c2c03bbed9f4661; captcha=4509285; captcha_md5=59bf907333254603af10; arp_scroll_position=0; *0=*0
- Первым делом нас тут интересует тип запроса, у нас это POST на адрес /login/ .
- Далее смотрим на тип передаваемых данных Content-Type: application/x-www-form-urlencoded .
- Также может пригодиться User-Agent и некоторые Cookie .
Так, как у нас запрос с данными веб формы, то также стоит посмотреть его тело:
login[login] [email protected] login[password] pass login[remember] 1 submitButton Войти login[type] cad5afb6ed280bc4041d5689d561144aЗдесь все довольно понятно — наши логин, пароль, запоминать или нет, имя кнопки и неизвестный параметр с логина. Проверим этот неизвестный параметр, просто проделав авторизацию еще раз. Если он изменится, то стоит искать как он формируется, если нет, то можно использовать его. В моем случае он статичный.
Ну и еще стоит посмотреть сам ответ сервера, что он отдает и что он устанавливает:
Content-Type: text/html; charset=UTF-8 Set-Cookie: *0=%2A0; expires=Wed, 12-Dec-2018 19:21:31 GMT; Max-Age=-864000; path=/; domain=rabota.by Set-Cookie: 666c9aea5601eb92b8=7df1b7318a82be0b068b; expires=Tue, 22-Jan-2019 19:21:32 GMT; Max-Age=2678400; path=/; httponly Set-Cookie: d2c3f55839194555558=f33b13af8cfcd2d14c8650; expires=Tue, 22-Jan-2019 19:21:32 GMT; Max-Age=2678400; path=/; httponlyВидно, что в ответ сервер отдает нам обычный html и устанавливает пару Cookie. Тело ответа смотреть пока бессмысленно.
Пробуем отправить запрос сами.
Для этих целей отлично подходит Postman. Устанавливаем, пропускаем авторизацию (или нет) и создаем новый запрос.
- Выбираем POST.
- Указываем адрес запроса https://rabota.by/login
- [вкладка Body] Указываем тип данных x-www-form-urlencoded
- [вкладка Body] Заполняем все поля запроса
- Пробуем отправить запрос.
- Смотрим данные (HTML). И видим там, что простой отправки данных нам не достаточно, сайт не авторизует нас. Что то не хватает. Обычно это либо заголовок UserAgent или какой то уникальный, либо Cookie.
- Пробуем добавить UserAgent — не подошел.
- Пробуем подобрать Cookie — и тут видим, что сайт наконец нас пустил (в HTML видим свои данные).
Теперь очистим запрос:
- Удаляем из Cookie по одному, пока не перестанет отправлять нам нужные данные. Я лично выяснил, что нужны всего одна Cookie — *0=*0 .
- [вкладка Body] Тут по такому же принципу, убираем все не нужное, убирая просто галки. Мои наблюдения показывают, что достаточно всего лишь login[login] , login[password] и login[type] .
- [вкладка Headers] Убираем также лишние заголовки. На авторизацию влияют Content-Type и Referer .
Как парсером авторизироваться на сайте?
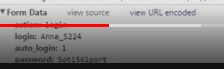
В туториале человек через инструменты разработчика смотрит запрос при регестрации со статусом 302 и методом POST, в котором у него внизу отображается данные которые он отправил (пункт Form Data), в этом пункте и есть ссылка на которую надо скидывать данные для входа
У меня же если ввести корректные данные запрос 302 с методом GET и к тому же не имеет пункта Form Data
(синие квадраты это основная ссылка по типу ):
И в низу никакого пункта Form Data нет
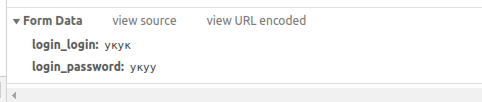
После этого я решил ввести неверные данные и посмотреть куда этот запрос введет, и введя их я получил запрос 301 метода POST где был пункт Form Data, в котором показывались данные которые требует сайт при авторизации
Тогда я и решил взять ссылку запроса от туда и отправлять туда эти данные, и в получил вот такое в IDE :
Как сделать так чтобы я вводил эти данные, авторизировался и получал уже html код самого сайта( с авторизацией)
- Вопрос задан более трёх лет назад
- 6645 просмотров
1 комментарий
Простой 1 комментарий
Удалось разобарться?
Решения вопроса 1
SKEPTIC @pro100chel Куратор тега Python
Python && PHP DeveloperНу типо хз что у тебя там за сайт, но почти всегда можно сделать авторизацию и парсить.
Вот алгоритм действий:
1) Создаешь акк (желательно вручную, т.к. могут стоять всякие разные капчи и т.д.)
2) Авторизируешься опять же вручную и параллельно зыришь на вкладку Network в отладчике у браузера. Может не получиться, если страница перезагружается. Тогда заходишь на форму авторизации и смотришь названия полей и обработчик запроса. Может не получиться и так. Тогда скачивай какой-нибудь инструмент для отладки сайта, чтобы страница не перезагружалась и можно было бы увидеть запрос.
3) Создаешь сессию в питоне и делаешь запрос. В дальнейшем постоянно отправляешь запросы только через сессию, т.к. это почти как браузер (сессия хранит куки и прочую лабуду)authdata = mysession = requests.session() response = mysession.post('https://example.com/reg.php', data=authdata) parsedata = mysession.post('https://example.com/catalog') //тут я делаю парсинг через сессию страницы каталога сайта, ты вписываешь свою страницу, которую хочешь спарситьКак парсить сайты с помощью Python? Основы работы с Requests и Selenium
Бывают ситуации, когда нужно автоматизировать сбор и анализ данных из разных источников. Для решения подобных задач применяют парсинг. В этой статье кратко рассказываем, как парсить данные веб-сайтов с помощью Python. Пособие подойдет новичкам и продолжающим — сохраняйте статью в закладки и задавайте вопросы в комментариях.
Дисклеймер: в статье рассмотрена только основная теория. На практике встречаются нюансы, когда нужно, например, декодировать спаршенные данные, настроить работу программы через xPath или даже задействовать компьютерное зрение. Обо всем этом — в следующих статьях, если тема окажется интересной.
Что такое пирсинг?
Парсинг — это процесс сбора, обработки и анализа данных. В качестве их источника может выступать веб-сайт.
Парсить веб-сайты можно несколькими способами — с помощью простых запросов сторонней программы и полноценной эмуляции работы браузера. Рассмотрим первый метод подробнее.
Парсинг с помощью HTTP-запросов
Суть метода в том, чтобы отправить запрос на нужный ресурс и получить в ответ веб-страницу. Ресурсом может быть как простой лендинг, так и полноценная, например, социальная сеть. В общем, все то, что умеет «отдавать» веб-сервер в ответ на HTTP-запросы.
Чтобы сымитировать запрос от реального пользователя, вместе с ним нужно отправить на веб-сервер специальные заголовки — User-Agent, Accept, Accept-Encoding, Accept-Language, Cache-Control и Connection. Их вы можете увидеть, если откроете веб-инспектор своего браузера.
Наиболее подробно о HTTP-запросах, заголовках и их классификации мы рассказали в отдельной статье.
Подготовка заголовков
На самом деле, необязательно отправлять с запросом все заголовки. В большинстве случаев достаточно User-Agent и Accept. Первый заголовок поможет сымитировать, что мы реальный пользователь, который работает из браузера. Второй — укажет, что мы хотим получить от веб-сервера гипертекстовую разметку.
st_accept = «text/html» # говорим веб-серверу, # что хотим получить html # имитируем подключение через браузер Mozilla на macOS st_useragent = «Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15» # формируем хеш заголовков headers = < "Accept": st_accept, "User-Agent": st_useragent >
После формирования заголовков нужно отправить запрос и сохранить страницу из ответа веб-сервера. Это можно сделать с помощью нескольких библиотек: Requests, ScraPy или PySpider.
Requests: получаем страницу по запросу
Для начала работы будет достаточно Requests — он удобнее и проще, чем привычный модуль urllib.
Requests — это библиотека на базе встроенного пакета urllib, которая позволяет легко отправлять различные веб-запросы, а также управлять кукисами и сессиями, авторизацией и автоматической организацией пула соединений.
Для примера попробуем спарсить страницу с курсами в Академии Selectel — это можно сделать за несколько действий:
# импортируем модуль import requests … # отправляем запрос с заголовками по нужному адресу req = requests.get(«https://selectel.ru/blog/courses/», headers) # считываем текст HTML-документа src = req.text print(src)
Пример: парсинг страницы с курсами в Академии Selectel.
Сервер вернет html-страницу, который можно прочитать с помощью атрибута text.
…
Курсы — Блог компании Селектел …Супер — гипертекстовую разметку страницы с курсами получили. Но что делать дальше и как извлечь из этого многообразия полезные данные? Для этого нужно применить некий «парсер для выборки данных».
Интересен Python? Мы собрали самые интересные и популярные запросы разработчиков в одном файле!
Beautiful Soup: извлекаем данные из HTML
Извлечь полезные данные из полученной html-страницы можно с помощью библиотеки Beautiful Soup.
Beautiful Soup — это, по сути, анализатор и конвертер содержимого html- и xml-документов. С помощью него полученную гипертекстовую разметку можно преобразовать в полноценные объекты, атрибуты которых — теги в html.
# импортируем модуль from bs4 import BeautifulSoup … # инициализируем html-код страницы soup = BeautifulSoup(src, ‘lxml’) # считываем заголовок страницы title = soup.title.string print(title) # Программа выведет: Курсы — Блог компании Селектел
Готово. У нас получилось спарсить и напечатать заголовок страницы. Где это можно применить — решать только вам. Например, мы в Selecte на базе Requests и Beautiful Soup разработали парсер данных с Хабра. Он помогает собирать и анализировать статистику по выбранным хабраблогам. Подробнее о решении можно почитать в предыдущей статье.
Проблема парсинга с помощью HTTP-запросов
Бывают ситуации, когда с помощью простых веб-запросов не получается спарсить все данные со страницы. Например, если часть контента подгружается с помощью API и JavaScript. Тогда сайт можно спарсить только через эмуляцию работы браузера.
Парсинг с помощью эмулятора
Для эмуляции работы браузера необходимо написать программу, которая будет как человек открывать нужные веб-страницы, взаимодействовать с элементами с помощью курсора, искать и записывать ценные данные. Такой алгоритм можно организовать с помощью библиотеки Selenium.
Настройка рабочего окружения
1. Установите ChromeDriver — именно с ним будет взаимодействовать Selenium. Если вы хотите, чтобы актуальная версия ChromeDriver подтягивалась автоматически, воспользуйтесь webdriver-manager. Далее импортируйте Selenium и необходимые зависимости.
pip3 install selenium
from selenium import webdriver as wd2. Инициализируйте ChromeDriver. В качестве executable_path укажите путь до установленного драйвера.
browser = wd.Chrome(«/usr/bin/chromedriver/»)
Теперь попробуем решить задачу: найдем в Академии Selectel статьи о Git.
Задача: работа с динамическим поиском
При переходе на страницу Академии встречает общая лента, в которой собраны материалы для технических специалистов. Они помогают прокачивать навыки и быть в курсе новинок из мира IT.
Но материалов много, а у нас задача — найти все статьи, связанные с Git. Подойдем к парсингу системно и разобьем его на два этапа.
Шаг 1. Планирование
Для начала нужно продумать, с какими элементами должна взаимодействовать наша программа, чтобы найти статьи. Но здесь все просто: в рамках задачи Selenium должен кликнуть на кнопку поиска, ввести поисковый запрос и отобрать полезные статьи.
Теперь скопируем названия классов html-элементов и напишем скрипт!
Шаг 2. Работа с полем ввода
Работа с html-элементами сводится к нескольким пунктам: регистрации объектов и запуску действий, которые будет имитировать Selenium.
. # регистрируем кнопку «Поиск» и имитируем нажатие open_search = browser.find_element_by_class_name(«header_search») open_search.click() # регистрируем текстовое поле и имитируем ввод строки «Git» search = browser.find_element_by_class_name(«search-modal_input») search.send_keys(«Git»)
Осталось запустить скрипт и проверить, как он отрабатывает:
Скрипт работает корректно — осталось вывести результат.
Шаг 3. Чтение ссылок и результат
Вне зависимости от того, какая у вас задача, если вы работаете с Requests и Selenium, Beautiful Soup станет серебряной пулей в обоих случаях. С помощью этой библиотеки мы извлечем полезные данные из полученной гипертекстовой разметки.
from bs4 import BeautifulSoup . # ставим на паузу, чтобы страница прогрузилась time.sleep(3) # загружаем страницу и извлекаем ссылки через атрибут rel soup = BeautifulSoup(browser.page_source, ‘lxml’) all_publications = \ soup.find_all(‘a’, <'rel': 'noreferrer noopener'>)[1:5] # форматируем результат for article in all_publications: print(article[‘href’])
Готово — программа работает и выводит ссылки на статьи о Git. При клике по ссылкам открываются соответветствующие страницы в Академии Selectel.
Какому инструменту для парсинга отдаете предпочтение вы? Поделитесь мнением в комментариях! И подпишитесь на блог Selectel, чтобы не пропустить новые обзоры, новости и кейсы из мира IT и технологий.
Читайте также:
- 5 неприятных случаев при продаже гаджетов
- Как разработать персональный план развития для UX-дизайнера
- 8 багов Midjourney, которые мы нашли за время ее существования
Как спарсить сайт с авторизацией
Argument ‘Topic id’ is null or empty
Сейчас на форуме
© Николай Павлов, Planetaexcel, 2006-2023
info@planetaexcel.ruИспользование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
ООО «Планета Эксел»
ИНН 7735603520
ОГРН 1147746834949ИП Павлов Николай Владимирович
ИНН 633015842586
ОГРНИП 310633031600071