Как ускорить работу power query
Argument ‘Topic id’ is null or empty
Сейчас на форуме
© Николай Павлов, Planetaexcel, 2006-2023
info@planetaexcel.ru
Использование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
| ООО «Планета Эксел» ИНН 7735603520 ОГРН 1147746834949 |
ИП Павлов Николай Владимирович ИНН 633015842586 ОГРНИП 310633031600071 |
Как увеличить скорость работы в Power Query?
Бывают такие ситуации, когда в редактор Power BI вы загружаете большие объемы данных, например, таблицы с миллионами строк. Если у вас в редакторе запросов (Power Query) таких запросов много, и вы пытаетесь производить с ними определенные действия: обрабатывать, объединять, добавлять, то Power Query может «подтормаживать», долго обрабатывать информацию, тем более если ваш компьютер или ноутбук слабоваты и это в целом ведет к увеличению времени работы.
На этот процесс можно повлиять, и я хочу поделиться таким советом: нужно временно ограничить число строк в конкретном запросе.
Например, в вашем запросе миллион строк, вам же нужно временно оставить в этом запросе 100 строк. После того, как вы ограничите количество строк до 100, сделайте все необходимые преобразования запросов и в заключение удалите тот шаг, в котором вы ограничивали количество строк. Тем самым вы ускорите весь процесс работы с запросами.
Вот как это реализовывается на практике:
Редактор запросов Power Query:
На главной странице нажимаем «Изменить запросы»
В данной таблице 996 строк. Для примера ограничим таблицу 20 строками.
В основном поле, в левом верхнем углу правой кнопкой мыши нажимаем на значок на пересечении столбцов и строк.
В появившемся меню нажимаем «Сохранить верхние строки…».
Затем в открывшемся окне указываем цифру 20.
Наша таблица уменьшилась до 20 строк.
Теперь мы можем работать с этим запросом (чистить, модернизировать, соединять с другими запросами и т.д.) и эти действия будут проводиться достаточно быстро, потому что количество строк уменьшилось до 20.
Для примера, создадим шаг, состоящий из нового столбца.
На вкладке «Добавление столбца» нажимаем «Настраиваемый столбец»
Оптимизация Power Query при расширении столбцов таблицы
Простота и простота использования, которая позволяет пользователям Power BI быстро собирать данные и создавать интересные и мощные отчеты, чтобы принимать интеллектуальные бизнес-решения, также позволяет пользователям легко создавать плохо выполняемые запросы. Это часто происходит при наличии двух таблиц, связанных с внешним ключом, связанных с таблицами SQL или списками SharePoint. (Для записи эта проблема не относится к SQL или SharePoint и возникает во многих сценариях извлечения внутренних данных, особенно в тех случаях, когда схема является гибкой и настраиваемой.) Кроме того, нет ничего неправильного в хранении данных в отдельных таблицах, которые совместно используют общий ключ. На самом деле это фундаментальный принцип проектирования и нормализации базы данных. Но это означает лучший способ расширения отношений.
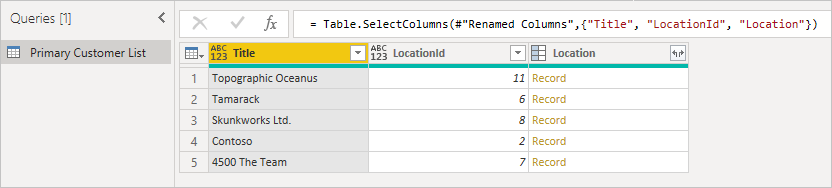
Рассмотрим следующий пример списка клиентов SharePoint.
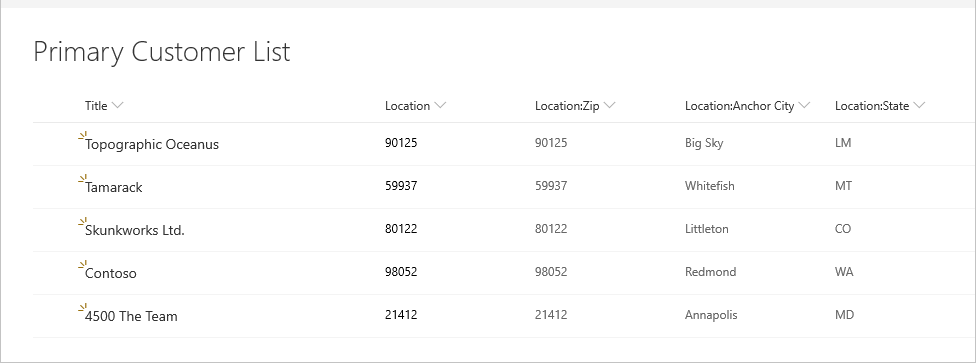
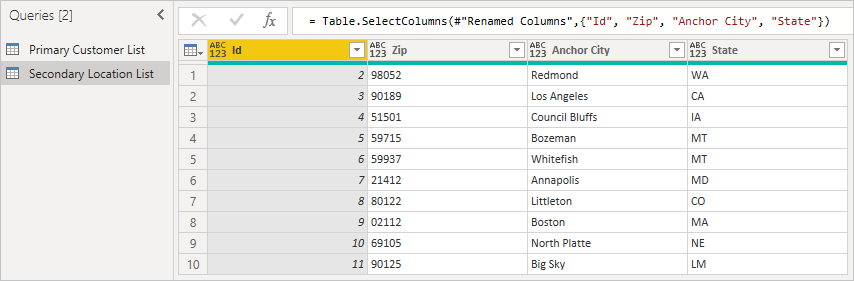
И в следующем списке расположений он ссылается.
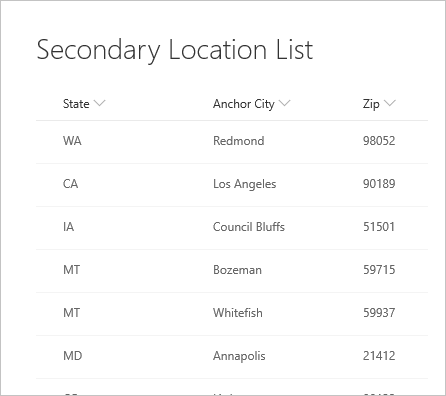
При первом подключении к списку расположение отображается как запись.
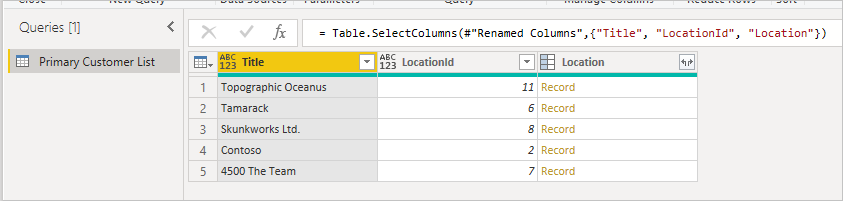
Эти данные верхнего уровня собираются через один http-вызов API SharePoint (игнорируя вызов метаданных), который можно увидеть в любом веб-отладчике.

При развертывании записи вы увидите поля, присоединенные из вторичной таблицы.
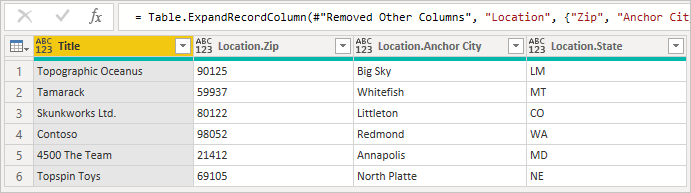
При расширении связанных строк из одной таблицы в другую поведение по умолчанию Power BI заключается в создании вызова Table.ExpandTableColumn . Это можно увидеть в поле созданной формулы. К сожалению, этот метод создает отдельный вызов второй таблицы для каждой строки в первой таблице.
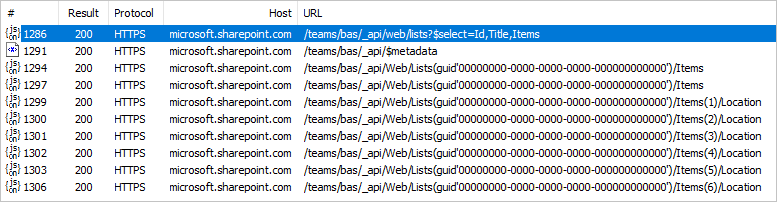
Это увеличивает количество http-вызовов по одному для каждой строки в основном списке. Это может показаться не так много в приведенном выше примере из пяти или шести строк, но в рабочих системах, где списки SharePoint достигают сотен тысяч строк, это может привести к значительному снижению производительности.
Когда запросы достигают этого узкого места, лучше всего избежать вызова для каждой строки с помощью классического соединения таблицы. Это гарантирует, что во второй таблице будет выполняться только один вызов, а остальная часть расширения может происходить в памяти с помощью общего ключа между двумя таблицами. Разница в производительности может быть массивной в некоторых случаях.
Сначала начните с исходной таблицы, отметив столбец, который вы хотите развернуть, и убедитесь, что у вас есть идентификатор элемента, чтобы его можно было сопоставить. Обычно внешний ключ называется как отображаемое имя столбца с добавленным идентификатором . В этом примере это LocationId.
Во-вторых, загрузите вторичную таблицу, включив идентификатор, который является внешним ключом. Щелкните правой кнопкой мыши панель «Запросы», чтобы создать новый запрос.
Наконец, присоединитесь к двум таблицам с помощью соответствующих имен столбцов, которые соответствуют. Обычно это поле можно найти, сначала разверните столбец, а затем ищете соответствующие столбцы в предварительной версии.

В этом примере можно увидеть, что LocationId в первичном списке соответствует идентификатору в дополнительном списке. Пользовательский интерфейс переименовывает это в Location.Id , чтобы сделать имя столбца уникальным. Теперь давайте будем использовать эти сведения для слияния таблиц.
Щелкнув правой кнопкой мыши панель запросов и выбрав «Создать запросы объединения>запросов» в качестве новых>, вы увидите удобный пользовательский интерфейс, который поможет объединить эти два запроса.
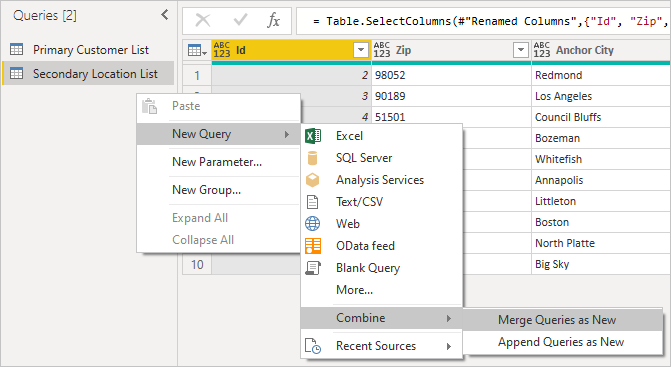
Выберите каждую таблицу из раскрывающегося списка, чтобы просмотреть предварительный просмотр запроса.
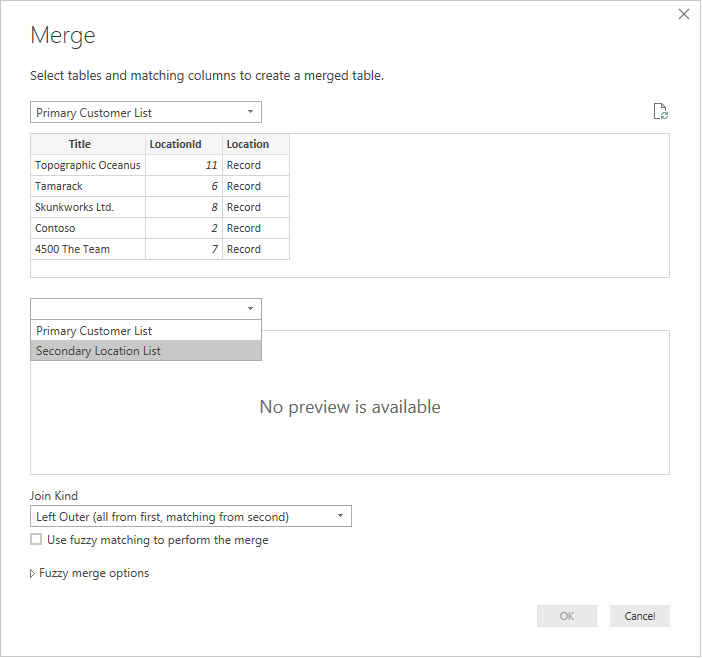
Выбрав обе таблицы, выберите столбец, который объединяет таблицы логически (в этом примере — LocationId из первичной таблицы и идентификатора из вторичной таблицы). В диалоговом окне вы узнаете, сколько строк совпадает с внешним ключом. Скорее всего, вы захотите использовать тип соединения по умолчанию (левый внешний) для таких данных.
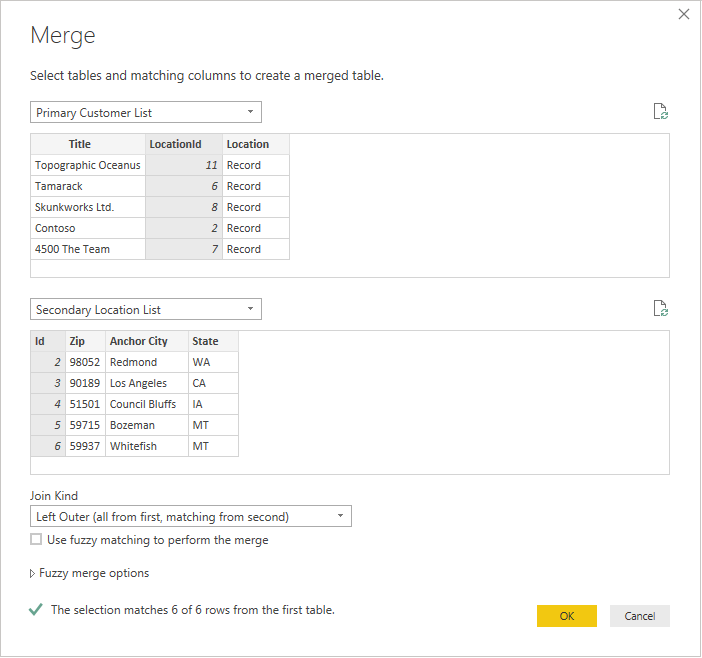
Нажмите кнопку «ОК «, и вы увидите новый запрос, который является результатом соединения. Расширение записи теперь не подразумевает дополнительные вызовы серверной части.

Обновление этих данных приведет только к двум вызовам SharePoint — одному для основного списка и одному для дополнительного списка. Соединение будет выполнено в памяти, значительно уменьшая количество вызовов в SharePoint.
Этот подход можно использовать для любых двух таблиц в PowerQuery, имеющих соответствующий внешний ключ.
Списки пользователей SharePoint и таксономия также доступны в виде таблиц и могут быть присоединены точно так же, как описано выше, если у пользователя есть достаточные привилегии для доступа к этим спискам.
Рекомендации по работе с Power Query
В этой статье содержатся некоторые советы и рекомендации, которые помогут вам получить большую часть возможностей обработки данных в Power Query.
Выбор правильного соединителя
Power Query предлагает большое количество соединителей данных. Эти соединители варьируются от таких источников данных, как TXT, CSV и Excel, до баз данных, таких как Microsoft SQL Server, и популярных служб SaaS, таких как Microsoft Dynamics 365 и Salesforce. Если источник данных не отображается в окне получения данных , можно всегда использовать соединитель ODBC или OLEDB для подключения к источнику данных.
Используя лучший соединитель для задачи, вы получите лучший опыт и производительность. Например, использование соединителя SQL Server вместо соединителя ODBC при подключении к базе данных SQL Server не только обеспечивает более эффективное взаимодействие с данными , но и соединитель SQL Server также предлагает функции, которые могут повысить производительность и производительность, такие как свертывание запросов. Чтобы узнать больше о свертке запросов, перейдите к свертке запросов Power Query.
Каждый соединитель данных соответствует стандартному интерфейсу, как описано в разделе «Получение данных». Этот стандартизованный интерфейс имеет этап с именем «Предварительная версия данных». На этом этапе вы предоставляете понятное окно, чтобы выбрать данные, которые вы хотите получить из источника данных, если соединитель разрешает его, и простой предварительный просмотр этих данных. Вы даже можете выбрать несколько наборов данных из источника данных в окне навигатора , как показано на следующем рисунке.
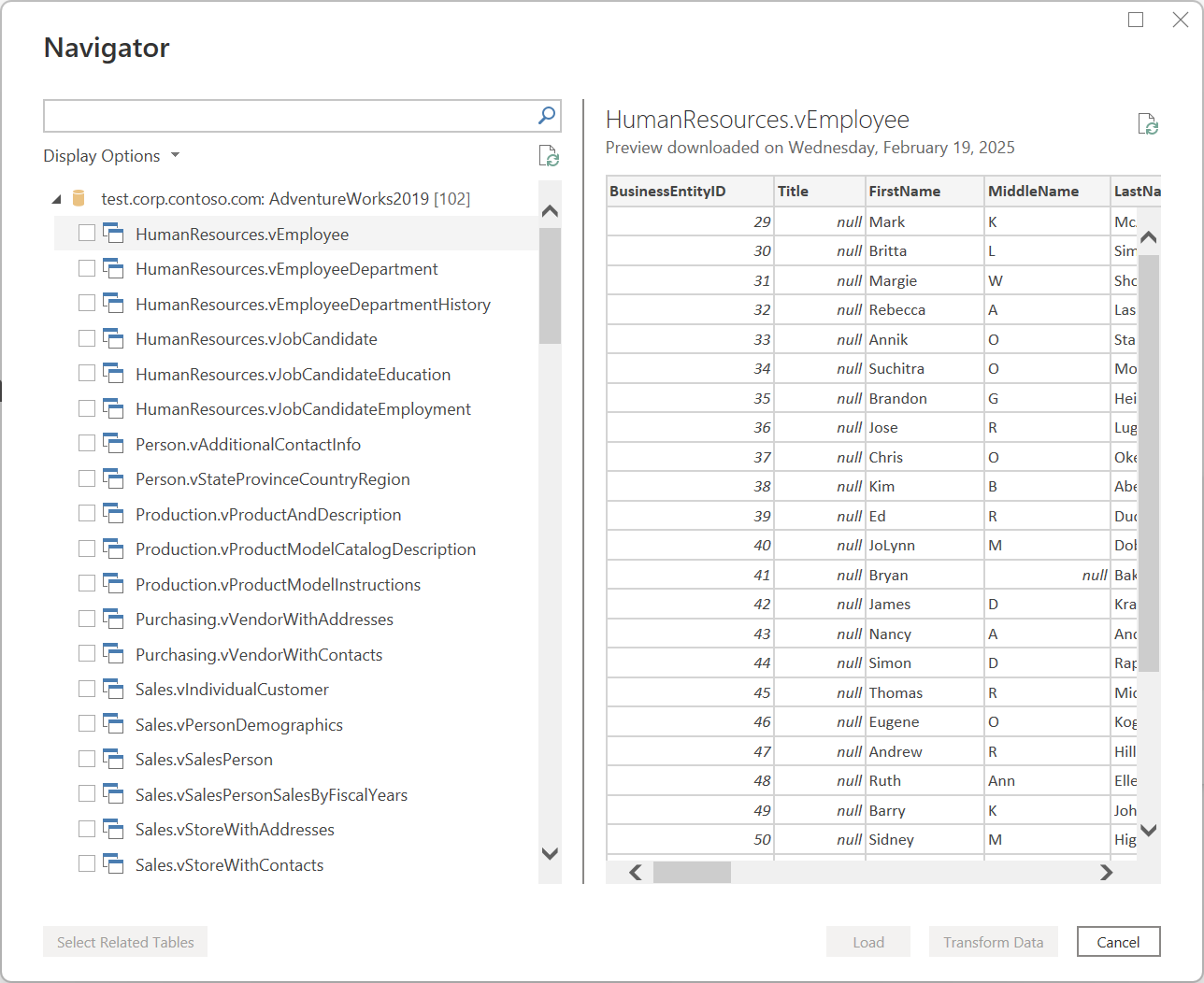
Чтобы просмотреть полный список доступных соединителей в Power Query, перейдите к Подключение дорам в Power Query.
Фильтрация рано
Всегда рекомендуется фильтровать данные на ранних этапах запроса или как можно раньше. Некоторые соединители будут использовать свои фильтры с помощью свертывания запросов, как описано в свертке запросов Power Query. Кроме того, рекомендуется отфильтровать все данные, которые не относятся к вашему делу. Это позволит вам лучше сосредоточиться на задаче, показывая только данные, соответствующие в разделе предварительного просмотра данных.
Вы можете использовать меню автоматического фильтра, отображающее отдельный список значений, найденных в столбце, для выбора значений, которые необходимо сохранить или отфильтровать. Вы также можете использовать панель поиска, чтобы найти значения в столбце.
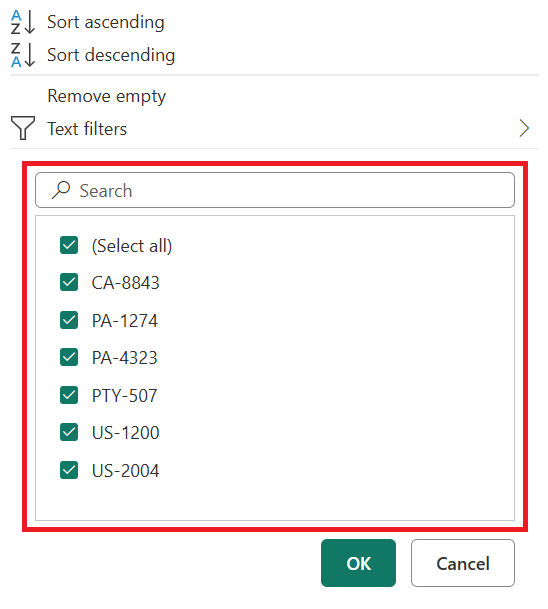
Вы также можете воспользоваться такими фильтрами, как «В предыдущем » для даты, даты и времени или даже столбца часового пояса.
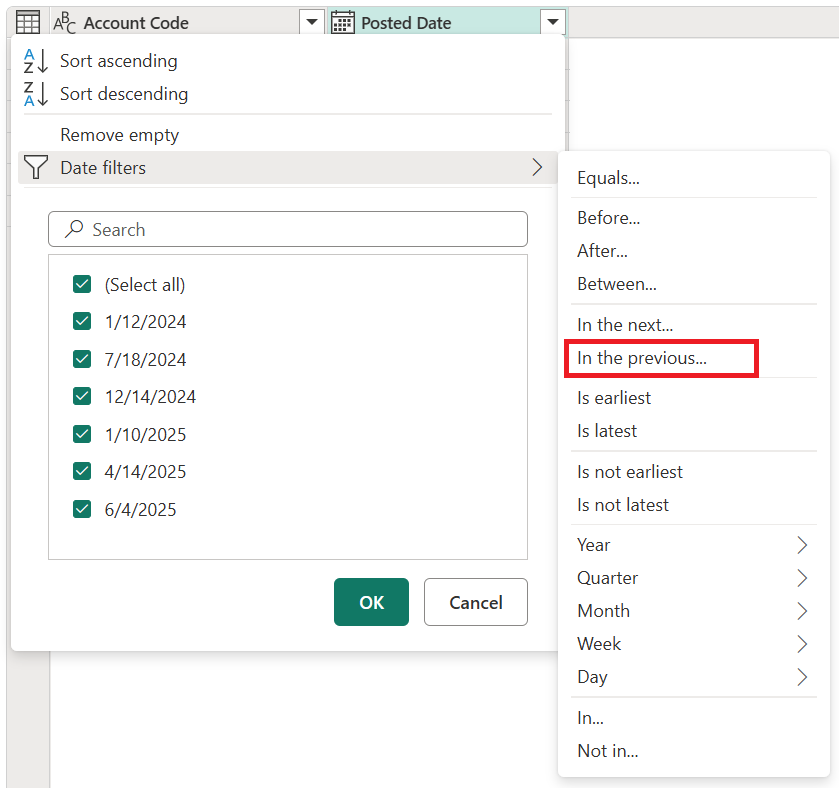
Эти фильтры, относящиеся к типу, помогут вам создать динамический фильтр, который всегда будет получать данные, которые будут отображаться на предыдущем x количестве секунд, в минутах, часах, днях, неделях, месяцах, кварталах или годах, как показано на следующем рисунке.
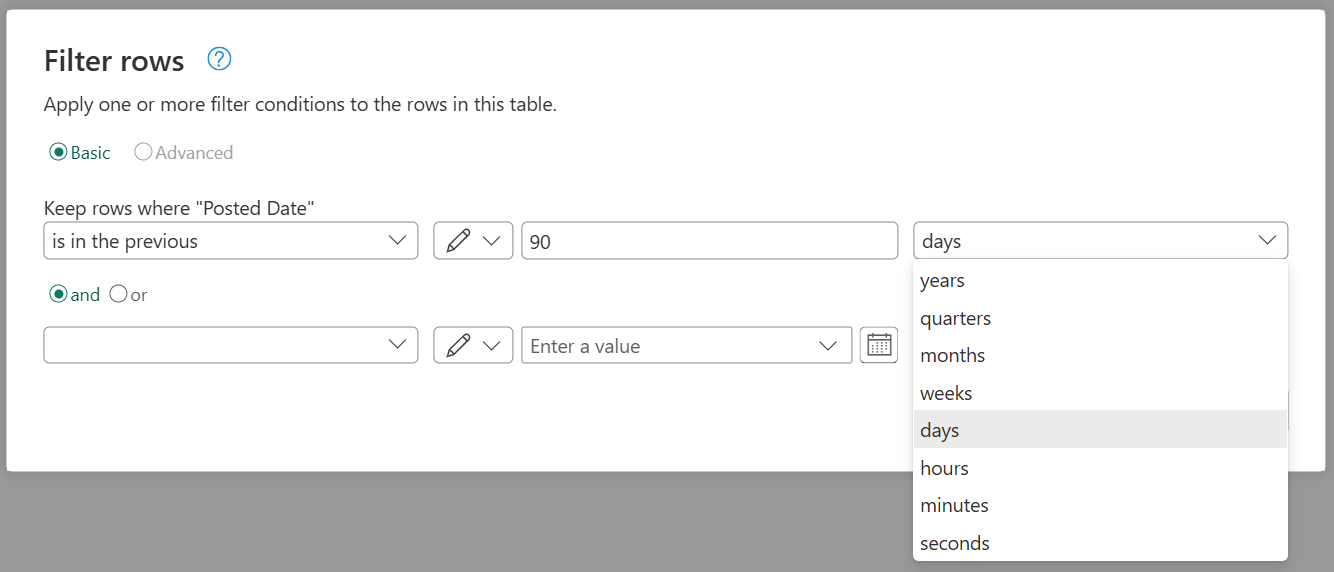
Дополнительные сведения о фильтрации данных на основе значений из столбца см. в разделе «Фильтр по значениям».
Последнее время выполнения дорогостоящих операций
Некоторые операции требуют чтения полного источника данных для возврата любых результатов и, таким образом, будут медленно просматриваться в Редактор Power Query. Например, если выполнить сортировку, возможно, первые несколько отсортированных строк находятся в конце исходных данных. Таким образом, чтобы возвращать результаты, операция сортировки должна сначала считывать все строки.
Другие операции (например, фильтры) не должны считывать все данные перед возвратом результатов. Вместо этого они работают над данными в режиме потоковой передачи. Данные «потоки» и результаты возвращаются по пути. В Редактор Power Query таких операций достаточно прочитать исходные данные, чтобы заполнить предварительную версию.
По возможности сначала выполняйте такие операции потоковой передачи и выполняйте все более дорогие операции. Это поможет свести к минимуму время ожидания предварительной версии для отображения при каждом добавлении нового шага в запрос.
Временное использование подмножества данных
Если добавление новых шагов в запрос в Редактор Power Query медленно, попробуйте сначала выполнить операцию «Сохранить первые строки» и ограничить количество строк, с которыми вы работаете. После добавления всех необходимых шагов удалите шаг «Сохранить первые строки».
Использование правильных типов данных
Некоторые функции в Power Query контекстно относятся к типу данных выбранного столбца. Например, при выборе столбца даты доступные параметры в группе столбцов даты и времени в меню «Добавить столбец«. Но если столбец не имеет набора типов данных, эти параметры будут серыми.

Аналогичная ситуация возникает для фильтров, относящихся к типу, так как они относятся к определенным типам данных. Если в столбце нет правильного типа данных, эти фильтры, относящиеся к типу, не будут доступны.
Важно всегда работать с правильными типами данных для столбцов. При работе с структурированными источниками данных, такими как базы данных, сведения о типе данных будут доставлены из схемы таблицы, найденной в базе данных. Но для неструктурированных источников данных, таких как TXT и CSV-файлы, важно задать правильные типы данных для столбцов, поступающих из этого источника данных. По умолчанию Power Query предлагает автоматическое обнаружение типов данных для неструктурированных источников данных. Дополнительные сведения об этой функции и о том, как она может помочь в типах данных.
Дополнительные сведения о важности типов данных и их работе см. в разделе «Типы данных».
Изучение данных
Прежде чем приступить к подготовке данных и добавлению новых шагов преобразования, рекомендуется включить средства профилирования данных Power Query, чтобы легко обнаруживать сведения о данных.
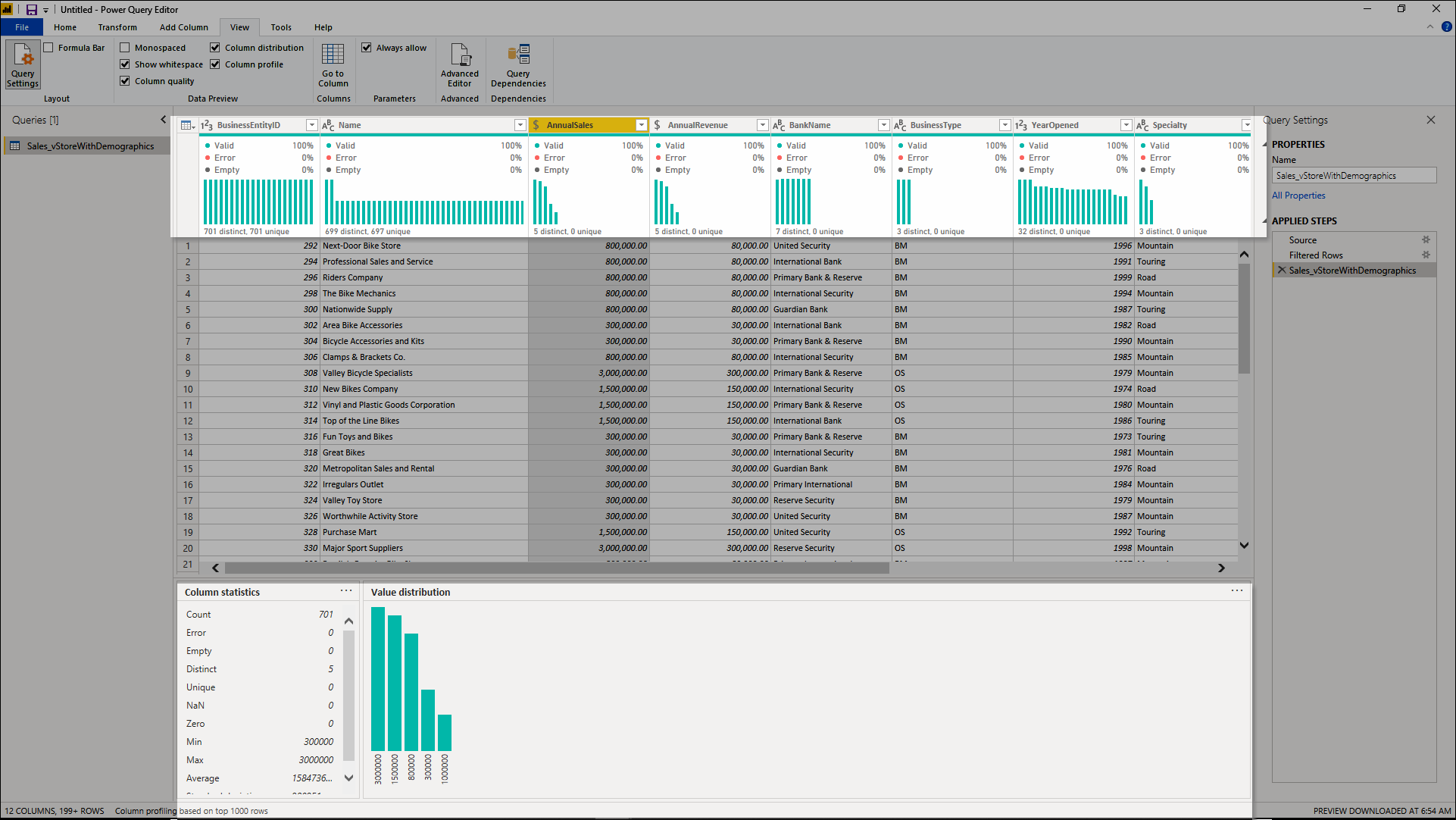
Эти средства профилирования данных помогают лучше понять данные. Эти средства предоставляют небольшие визуализации, отображающие сведения на основе столбцов, например:
- Качество столбца— предоставляет небольшую линейчатую диаграмму и три индикатора с представлением количества значений в столбце, входящих в категорию допустимых, ошибок или пустых значений.
- Распределение столбцов — предоставляет набор визуальных элементов под именами столбцов, демонстрирующих частоту и распределение значений в каждом столбце.
- Профиль столбца— предоставляет более тщательное представление столбца и статистику, связанную с ней.
Вы также можете взаимодействовать с этими функциями, что поможет подготовить данные.
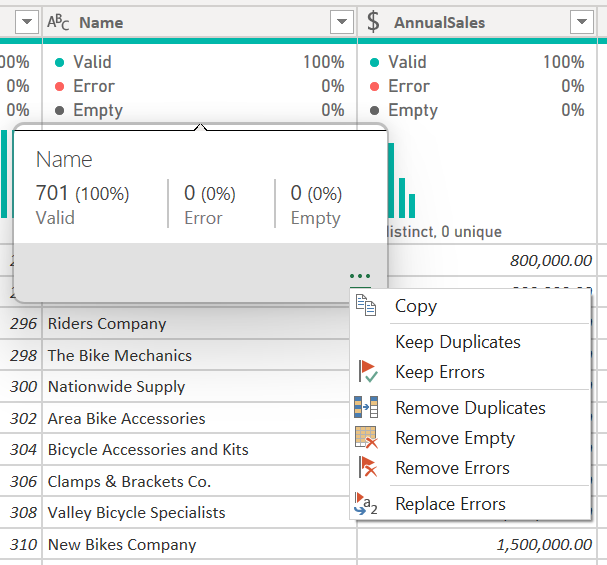
Дополнительные сведения о средствах профилирования данных см. в разделе «Средства профилирования данных».
Документируйте работу
Рекомендуется задокументировать запросы, переименовав или добавив описание в действия, запросы или группы, как показано в соответствии с вашими данными.
Хотя Power Query автоматически создает имя шага для вас в области примененных шагов, вы также можете переименовать шаги или добавить описание в любой из них.
Дополнительные сведения обо всех доступных функциях и компонентах, найденных в области примененных шагов, см. в разделе «Использование списка примененных шагов».
Подход к модульной работе
Полностью можно создать один запрос, содержащий все преобразования и вычисления, которые могут потребоваться. Но если запрос содержит большое количество шагов, возможно, рекомендуется разделить запрос на несколько запросов, где один запрос ссылается на следующий. Цель этого подхода заключается в том, чтобы упростить и разделить этапы преобразования на небольшие части, чтобы они легче понять.
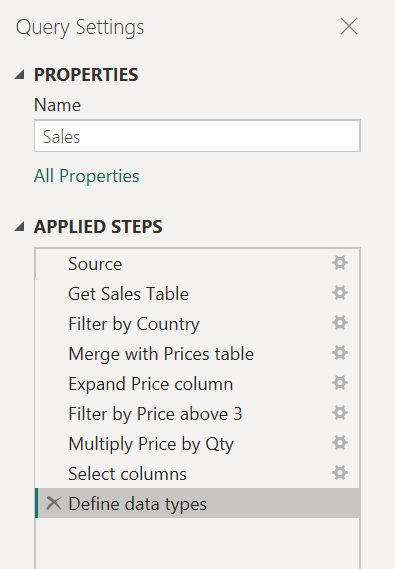
Например, предположим, что у вас есть запрос с девятью шагами, показанными на следующем рисунке.
Этот запрос можно разделить на два на шаге «Слияние с ценами «. Таким образом, проще понять шаги, которые были применены к запросу о продажах перед слиянием. Чтобы выполнить эту операцию, щелкните правой кнопкой мыши шаг «Слияние с ценами » и выберите параметр «Извлечь предыдущую «.
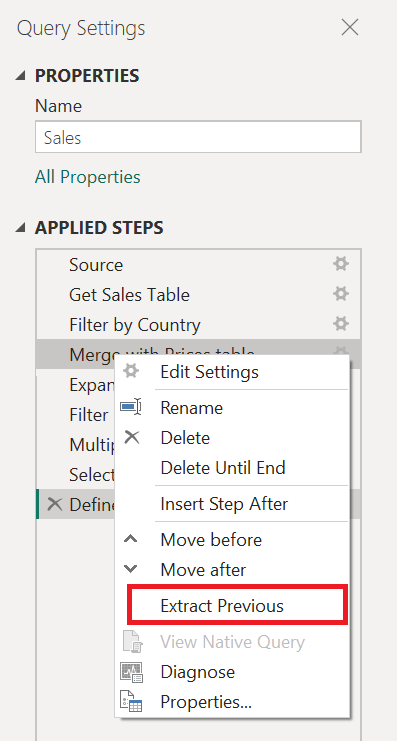
Затем появится диалоговое окно, чтобы указать новое имя запроса. Это позволит эффективно разделить запрос на два запроса. Перед слиянием один запрос будет иметь все запросы. Другой запрос будет иметь начальный шаг, который будет ссылаться на новый запрос и остальные шаги, которые вы выполнили в исходном запросе из шага «Слияние с ценами » вниз.
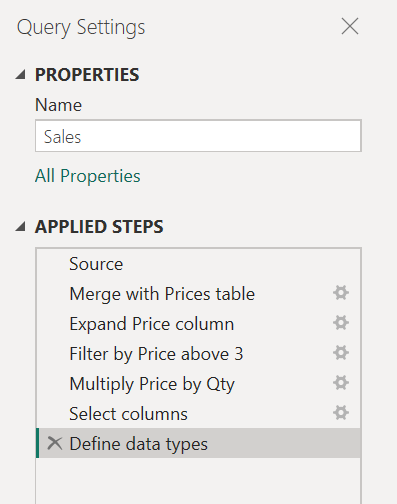
Вы также можете использовать ссылку на запросы, как показано в соответствии. Но это хорошая идея держать ваши запросы на уровне, который не кажется ошеломляющим на первый взгляд с таким количеством шагов.
Чтобы узнать больше о ссылке на запросы, перейдите к разделу «Общие сведения о области запросов».
Создание групп
Отличный способ организовать работу— использовать группы в области запросов.
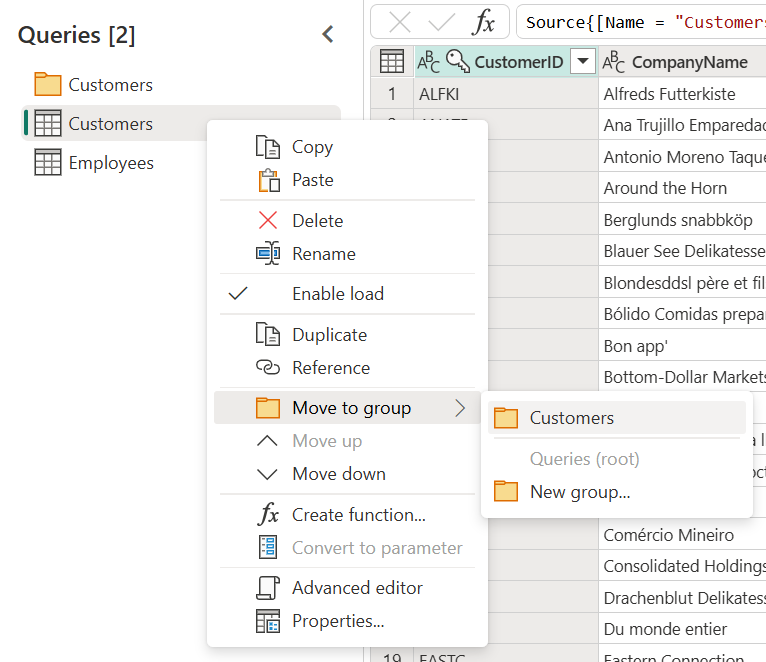
Единственной целью групп является поддержание организации работы, выступая в качестве папок для запросов. Вы можете создавать группы в группах, если вам нужно. Перемещение запросов между группами так же легко, как перетаскивание.
Попробуйте дать группам понятное имя, которое имеет смысл для вас и вашего дела.
Дополнительные сведения обо всех доступных функциях и компонентах, найденных в области запросов, см. в разделе » Общие сведения о области запросов».
Запросы для проверки правописания в будущем
Убедитесь, что вы создаете запрос, который не будет иметь никаких проблем во время будущего обновления является главным приоритетом. В Power Query есть несколько функций, которые позволяют сделать запрос устойчивым к изменениям и обновлять даже при изменении некоторых компонентов источника данных.
Рекомендуется определить область запроса о том, что он должен делать, и что он должен учитывать с точки зрения структуры, макета, имен столбцов, типов данных и любого другого компонента, который вы считаете соответствующими область.
Ниже приведены некоторые примеры преобразований, которые помогут вам сделать запрос устойчивым к изменениям:
-
Если запрос содержит динамическое число строк с данными, но фиксированное число строк, которые служат нижним колонтитулов, которые следует удалить, можно использовать функцию «Удалить нижние строки».
Примечание. Чтобы узнать больше о фильтрации данных по позиции строки, перейдите к разделу «Фильтрация таблицы по позиции строки».
Примечание. Чтобы узнать больше о выборе или удалении столбцов, перейдите к разделу «Выбор или удаление столбцов».
Примечание. Дополнительные сведения о параметрах для отмены сводных столбцов см. в разделе «Отмена сводных столбцов».
Примечание. Чтобы узнать больше о работе и работе с ошибками, перейдите к разделу «Работа с ошибками».
Использование параметров
Создание динамических и гибких запросов — это рекомендация. Параметры в Power Query помогают сделать запросы более динамическими и гибкими. Параметр служит способом легко хранить и управлять значением, которое можно повторно использовать различными способами. Но чаще используется в двух сценариях:
- Аргумент шага. Параметр можно использовать в качестве аргумента нескольких преобразований, управляемых из пользовательского интерфейса.
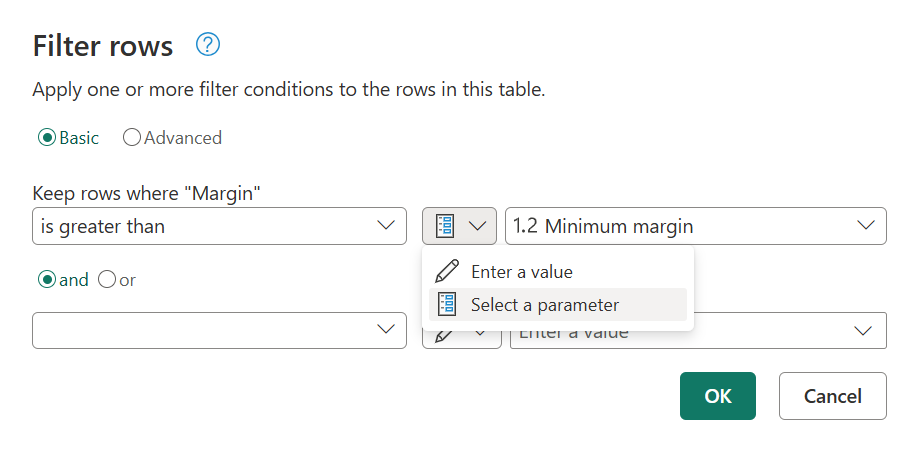
- Аргумент пользовательской функции— вы можете создать новую функцию из запроса и ссылаться на параметры в качестве аргументов пользовательской функции.
Основными преимуществами создания и использования параметров являются:
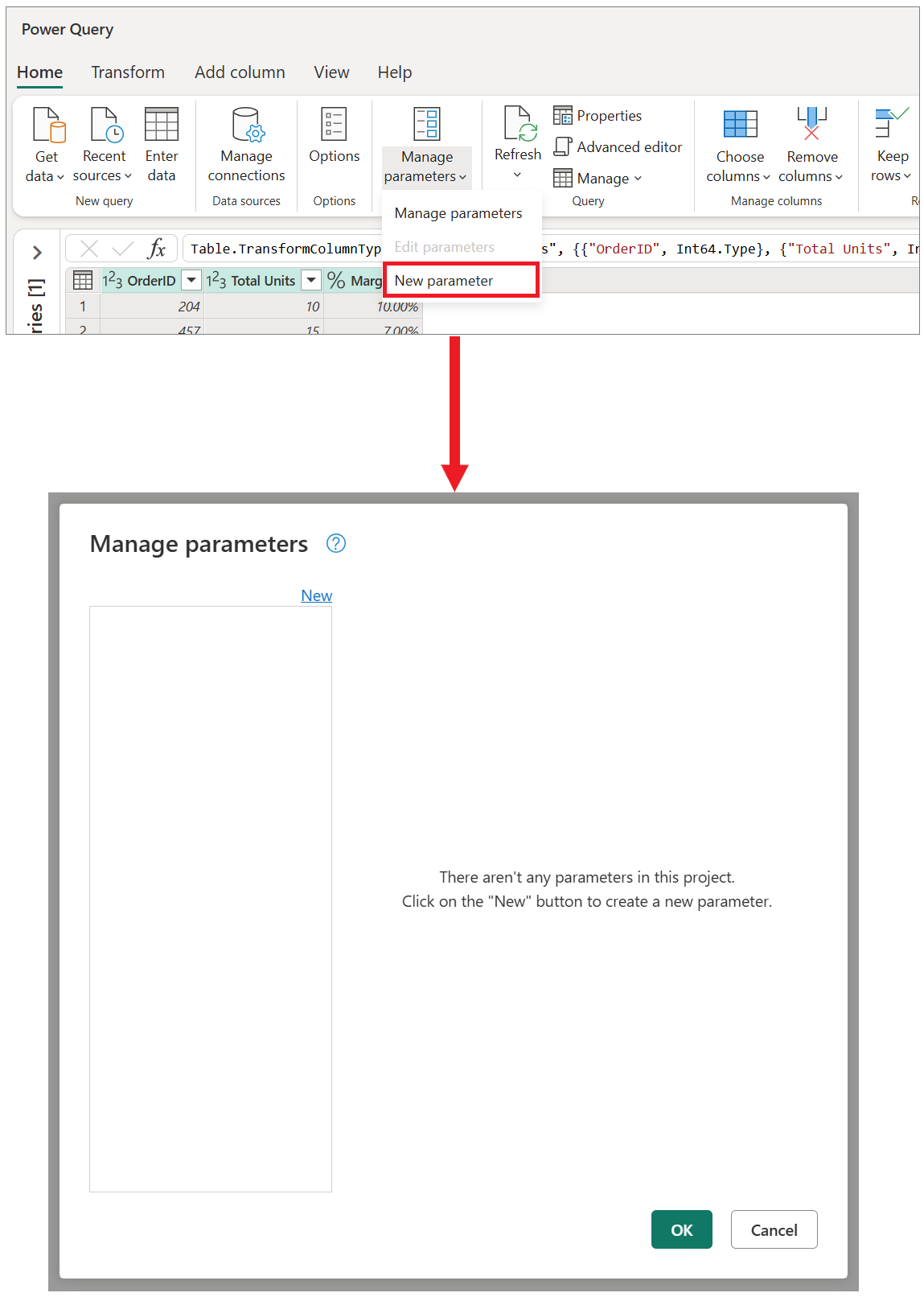
- Централизованное представление всех параметров с помощью окна «Управление параметрами «.
- Повторное использование параметра в нескольких шагах или запросах.
- Упрощает создание пользовательских функций.
Можно даже использовать параметры в некоторых аргументах соединителей данных. Например, можно создать параметр для имени сервера при подключении к базе данных SQL Server. Затем этот параметр можно использовать в диалоговом окне базы данных SQL Server.
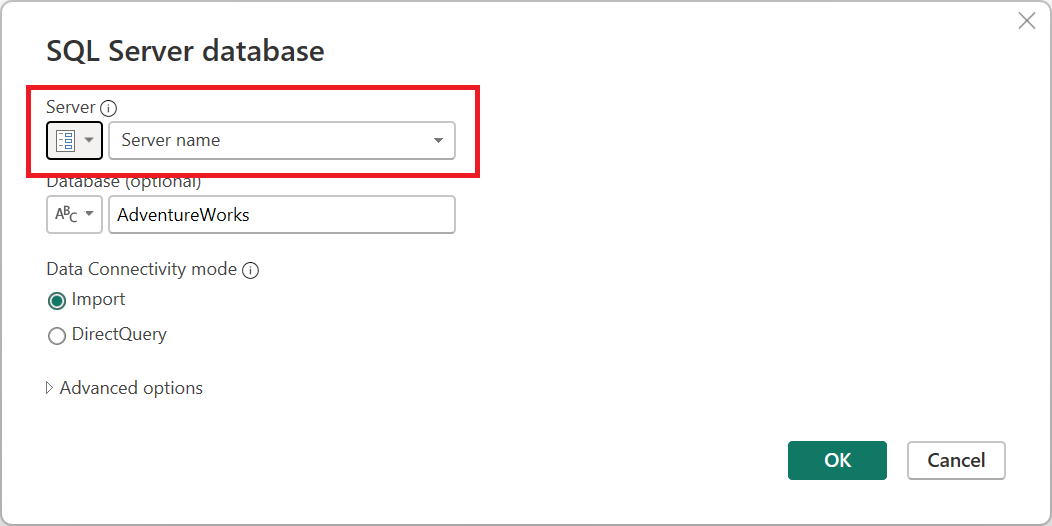
Если изменить расположение сервера, необходимо обновить параметр для имени сервера, а запросы будут обновлены.
Дополнительные сведения о создании и использовании параметров см. в разделе «Использование параметров».
Создание повторно используемых функций
Если вы найдете себя в ситуации, когда необходимо применить один набор преобразований к разным запросам или значениям, создайте пользовательскую функцию Power Query, которую можно повторно использовать столько раз, сколько вам может быть полезно. Пользовательская функция Power Query — это сопоставление из набора входных значений с одним выходным значением и создается из собственных функций и операторов M.
Например, предположим, что у вас есть несколько запросов или значений, требующих одного набора преобразований. Вы можете создать пользовательскую функцию, которая позже может быть вызвана в запросах или значениях выбранного варианта. Эта настраиваемая функция экономит время и помогает управлять набором преобразований в центральном расположении, которое можно изменить в любой момент.
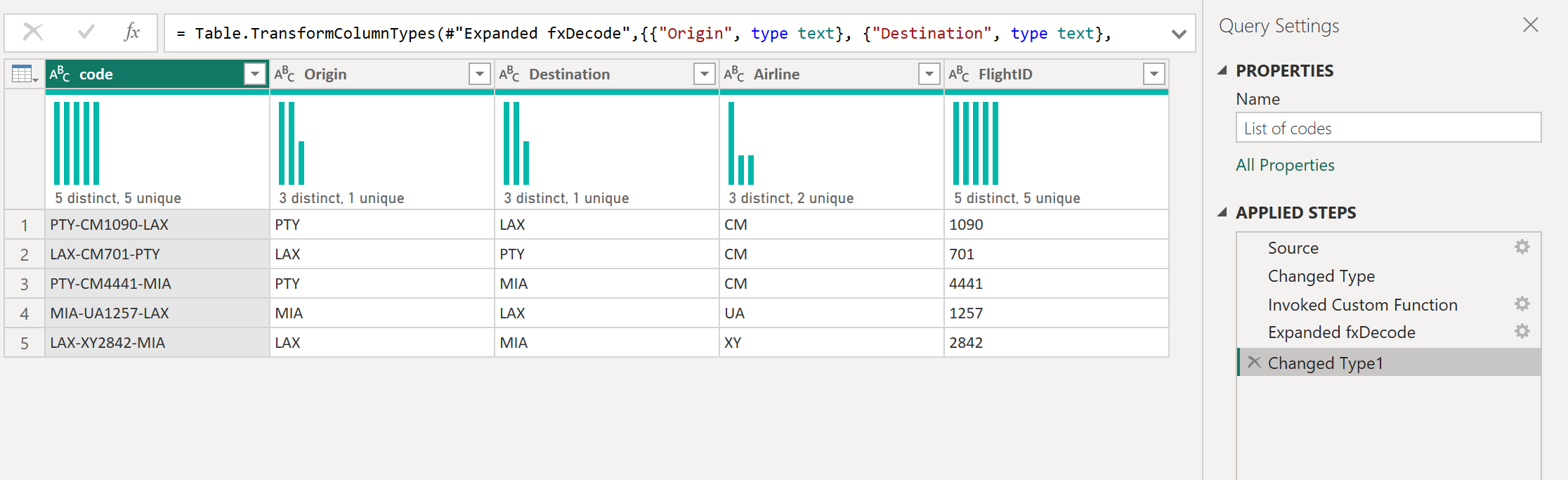
Пользовательские функции Power Query можно создавать из существующих запросов и параметров. Например, представьте запрос, имеющий несколько кодов в виде текстовой строки, и вы хотите создать функцию, которая декодирует эти значения.
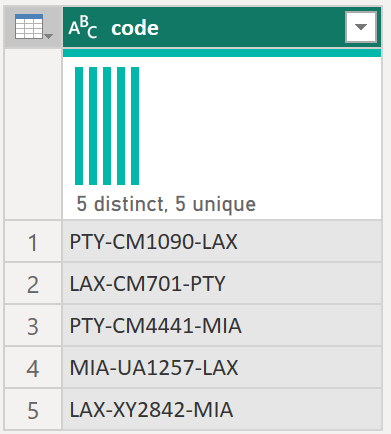
Сначала у вас есть параметр, имеющий значение, которое служит примером.
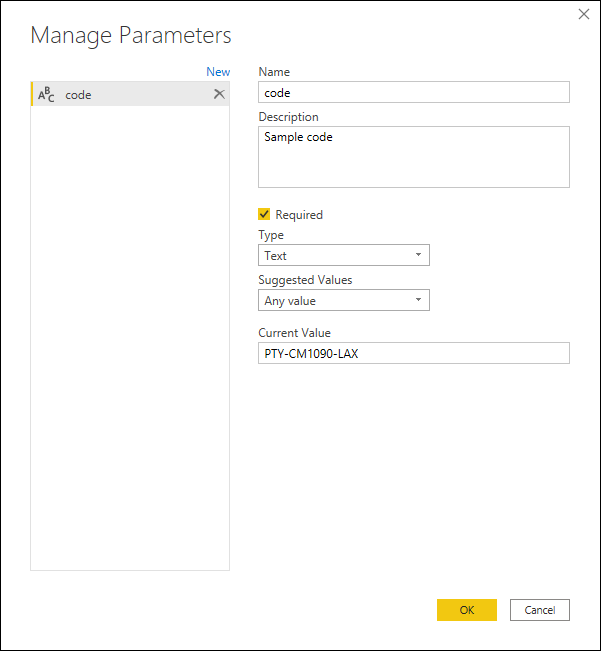
В этом параметре создается новый запрос, в котором применяются необходимые преобразования. В этом случае необходимо разделить код PTY-CM1090-LAX на несколько компонентов:
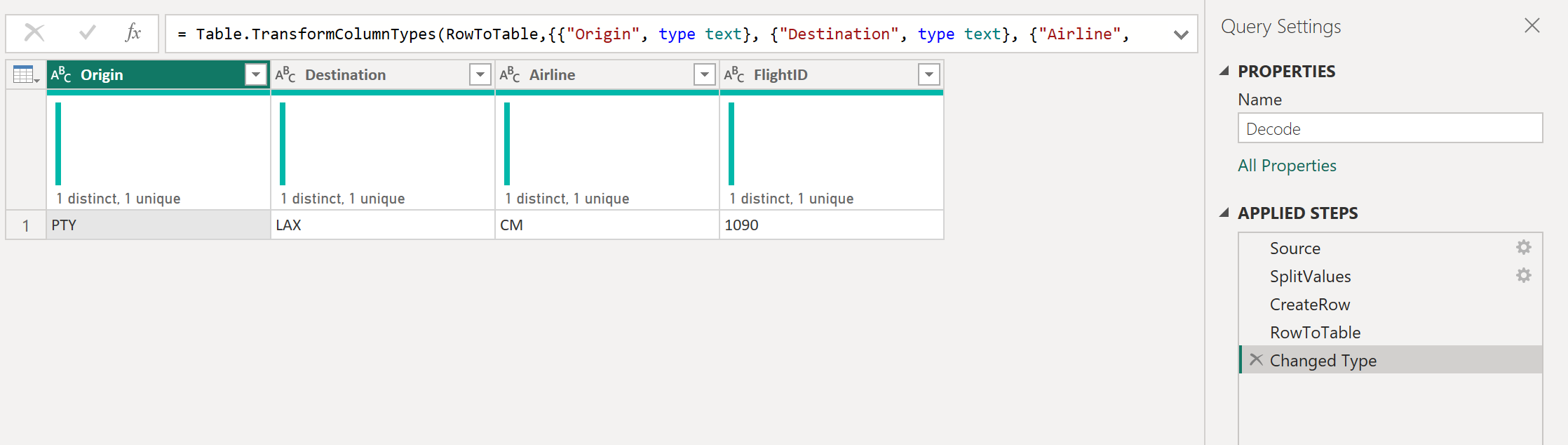
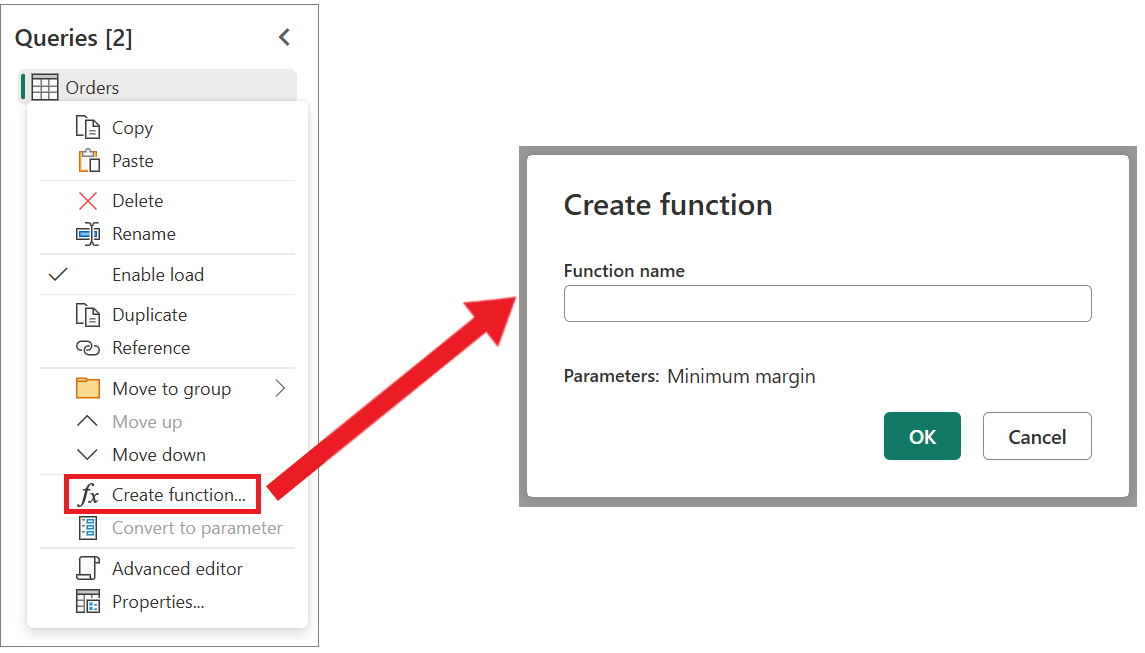
Затем этот запрос можно преобразовать в функцию, щелкнув правой кнопкой мыши запрос и выбрав «Создать функцию«. Наконец, можно вызвать пользовательскую функцию в любой из запросов или значений, как показано на следующем рисунке.
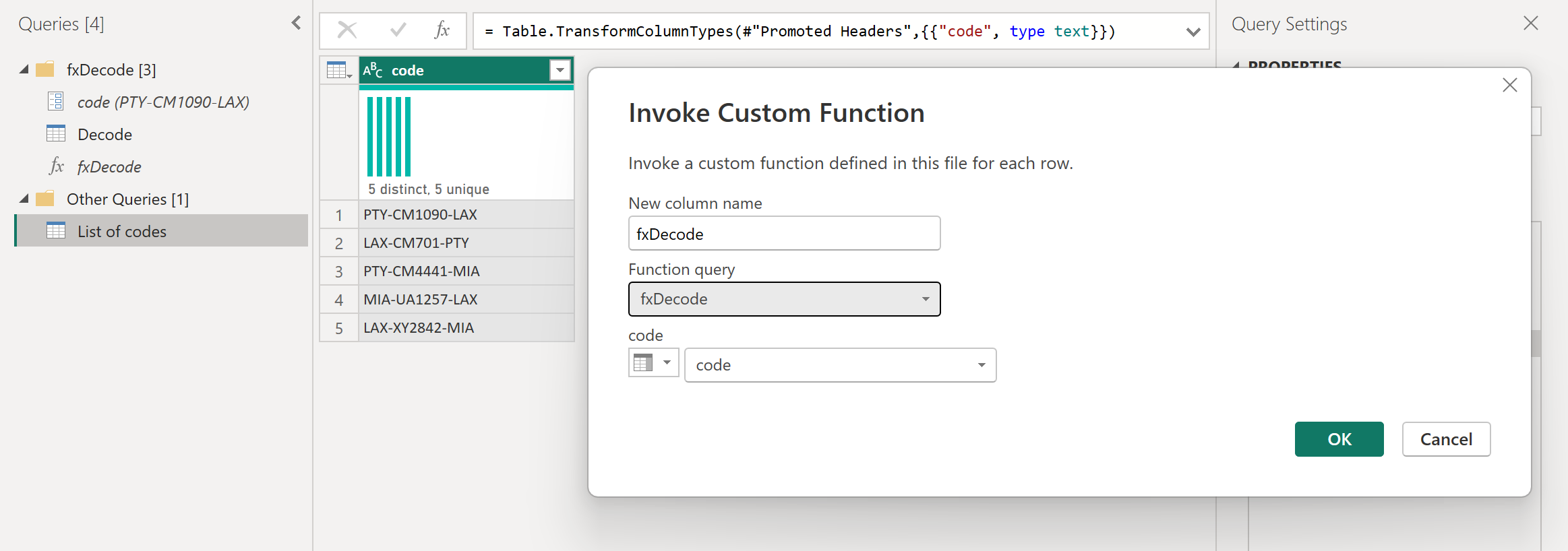
После нескольких преобразований вы увидите, что достигли нужных выходных данных и использовали логику для такого преобразования из пользовательской функции.
Дополнительные сведения о создании и использовании пользовательских функций в Power Query см. в статье «Пользовательские функции».